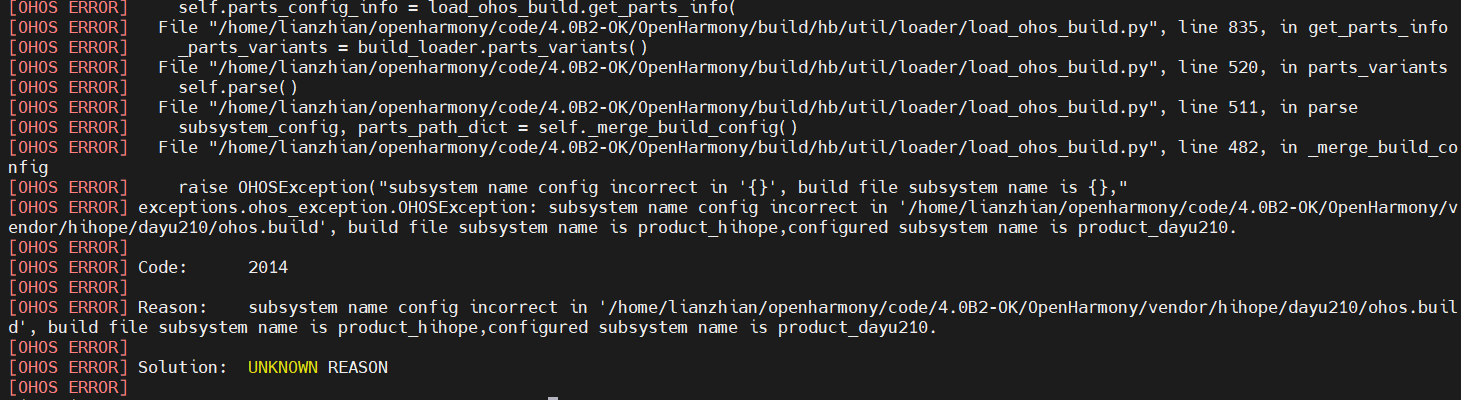
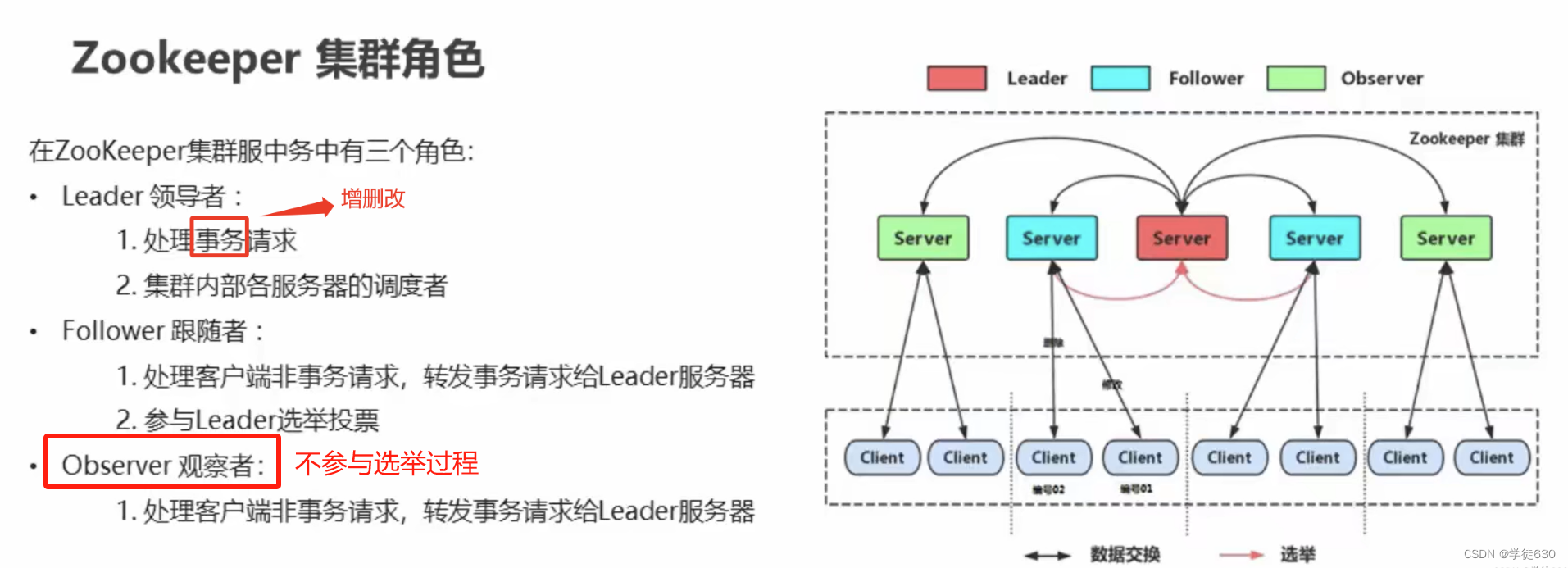
MyCat是一个开源的数据库中间件,它可以实现对MySQL数据库进行分片和负载均衡。在分片规则方面,MyCat支持以下几种常见的分片方式:
范围分片
根据指定的字段及其配置的范围与数据节点的对应情况, 来决定该数据属于哪一个分片。

配置
schema.xml逻辑表配置:
<table name="TB_ORDER" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
schema.xml
数据节点配置:
<dataNode name="dn1" dataHost="dhost1" database="db01" />
<dataNode name="dn2" dataHost="dhost2" database="db01" />
<dataNode name="dn3" dataHost="dhost3" database="db01" />
rule.xml
分片规则配置:
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
<property name="defaultNode">0</property>
</function>
分片规则配置属性含义:
|
属性
|
描述
|
|
columns
|
标识将要分片的表字段
|
|
algorithm
|
指定分片函数与
function
的对应关系
|
|
class
|
指定该分片算法对应的类
|
|
mapFile
|
对应的外部配置文件
|
|
type
|
默认值为
0 ; 0
表示
Integer , 1
表示
String
|
|
defaultNode
|
默认节点 默认节点的所用
:
枚举分片时
,
如果碰到不识别的枚举值
,
就让它路由到默认节点 ;
如果没有默认值
,
碰到不识别的则报错 。
|
在
rule.xml
中配置分片规则时,关联了一个映射配置文件
autopartition-long.txt
,该配置文
件的配置如下:
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2
含义:
0-500
万之间的值,存储在
0
号数据节点
(
数据节点的索引从
0
开始
)
;
500
万
-1000
万之间的
数据存储在
1
号数据节点 ;
1000
万
-1500
万的数据节点存储在
2号节点 ;
该分片规则,主要是针对于数字类型的字段适用。 在
MyCat
的入门程序中,我们使用的就是该分片规 则。
取模分片
根据指定的字段值与节点数量进行求模运算,根据运算结果, 来决定该数据属于哪一个分片。

配置
schema.xml逻辑表配置:
<table name="tb_log" dataNode="dn4,dn5,dn6" primaryKey="id" rule="mod-long" />
schema.xml
数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />
rule.xml
分片规则配置:
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">3</property>
</function>
分片规则属性说明如下:
|
属性
|
描述
|
|
columns
|
标识将要分片的表字段
|
|
algorithm
|
指定分片函数与
function
的对应关系
|
|
class
|
指定该分片算法对应的类
|
|
count
|
数据节点的数量
|
该分片规则,主要是针对于数字类型的字段适用。 在前面水平拆分的演示中,我们选择的就是取模分片。
一致性hash分片
所谓一致性哈希,相同的哈希因子计算值总是被划分到相同的分区表中,不会因为分区节点的增加而改变原来数据的分区位置,有效的解决了分布式数据的拓容问题。
 配置
配置
schema.xml
中逻辑表配置:
<!-- 一致性hash -->
<table name="tb_order" dataNode="dn4,dn5,dn6" rule="sharding-by-murmur" />
schema.xml
中数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />
rule.xml
中分片规则配置:
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<function name="murmur" class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">3</property>
<property name="virtualBucketTimes">160</property>
</function>
分片规则属性含义:
|
属性
|
描述
|
|
columns
|
标识将要分片的表字段
|
|
algorithm
|
指定分片函数与
function
的对应关系
|
|
class
|
指定该分片算法对应的类
|
|
seed
|
创建
murmur_hash
对象的种子,默认
0
|
|
count
|
要分片的数据库节点数量,必须指定,否则没法分片
|
|
virtualBucketTimes
|
一个实际的数据库节点被映射为这么多虚拟节点,默认是
160
倍,也就是虚拟节点数是物理节点数的160
倍
;virtualBucketTimes*count
就是虚拟结点数量
;
|
|
weightMapFile
|
节点的权重,没有指定权重的节点默认是
1
。以
properties
文件的格式填写,以从0
开始到
count-1
的整数值也就是节点索引为
key
,以节点权重值为值。所有权重值必须是正整数,否则以1
代替
|
|
bucketMapPath
|
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash
值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西
|
枚举分片
通过在配置文件中配置可能的枚举值
,
指定数据分布到不同数据节点上
,
本规则适用于按照省份、性
别、状态拆分数据等业务 。

配置
schema.xml中逻辑表配置:
<!-- 枚举 -->
<table name="tb_user" dataNode="dn4,dn5,dn6" rule="sharding-by-intfile-enumstatus"
/>schema.xml中数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />
rule.xml
中分片规则配置:
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<!-- 自己增加 tableRule -->
<tableRule name="sharding-by-intfile-enumstatus">
<rule>
<columns>status</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="defaultNode">2</property>
<property name="mapFile">partition-hash-int.txt</property>
</function>
partition-hash-int.txt
,内容如下
:
1=0
2=1
3=2
分片规则属性含义:
|
属性
|
描述
|
|
columns
|
标识将要分片的表字段
|
|
algorithm
|
指定分片函数与
function
的对应关系
|
|
class
|
指定该分片算法对应的类
|
|
mapFile
|
对应的外部配置文件
|
|
type
|
默认值为
0 ; 0
表示
Integer , 1
表示
String
|
|
defaultNode
|
默认节点
;
小于
0
标识不设置默认节点
,
大于等于
0
代表设置默认节点
; 默认节点的所用:
枚举分片时
,
如果碰到不识别的枚举值
,
就让它路由到默认节点 ;
如果没有默认值
,
碰到不识别的则报错 。
|
应用指定算法
运行阶段由应用自主决定路由到那个分片
,
直接根据字符子串(必须是数字)计算分片号。

配置
schema.xml中逻辑表配置:
<!-- 应用指定算法 -->
<table name="tb_app" dataNode="dn4,dn5,dn6" rule="sharding-by-substring" />schema.xml中数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />
rule.xml
中分片规则配置:
<tableRule name="sharding-by-substring">
<rule>
<columns>id</columns>
<algorithm>sharding-by-substring</algorithm>
</rule>
</tableRule>
<function name="sharding-by-substring"
class="io.mycat.route.function.PartitionDirectBySubString">
<property name="startIndex">0</property> <!-- zero-based -->
<property name="size">2</property>
<property name="partitionCount">3</property>
<property name="defaultPartition">0</property>
</function>
分片规则属性含义:
|
属性
|
描述
|
|
columns
|
标识将要分片的表字段
|
|
algorithm
|
指定分片函数与
function
的对应关系
|
|
class
|
指定该分片算法对应的类
|
|
startIndex
|
字符子串起始索引
|
|
size
|
字符长度
|
|
partitionCount
|
分区
(
分片
)
数量
|
|
defaultPartition
|
默认分片
(
在分片数量定义时
,
字符标示的分片编号不在分片数量内时
, 使用默认分片)
|
示例说明
:
id=05-100000002 ,
在此配置中代表根据
id
中从
startIndex=0
,开始,截取
siz=2
位数字即
05
,
05
就是获取的分区,如果没找到对应的分片则默认分配到
defaultPartition
。
固定分片hash算法
该算法类似于十进制的求模运算,但是为二进制的操作,例如,取
id
的二进制低
10
位 与
1111111111
进行位
&
运算,位与运算最小值为
0000000000
,最大值为
1111111111
,转换为十
进制,也就是位于
0-1023
之间。
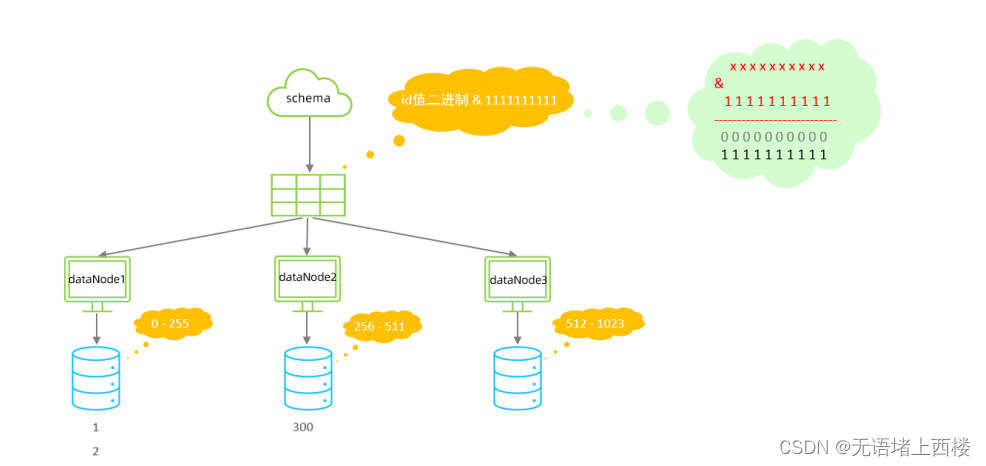
特点:
- 如果是求模,连续的值,分别分配到各个不同的分片;但是此算法会将连续的值可能分配到相同的分片,降低事务处理的难度。
- 可以均匀分配,也可以非均匀分配。
- 分片字段必须为数字类型。
配置
schema.xml
中逻辑表配置:
<!-- 固定分片hash算法 -->
<table name="tb_longhash" dataNode="dn4,dn5,dn6" rule="sharding-by-long-hash" />
schema.xml
中数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />
rule.xml
中分片规则配置:
<tableRule name="sharding-by-long-hash">
<rule>
<columns>id</columns>
<algorithm>sharding-by-long-hash</algorithm>
</rule>
</tableRule>
<!-- 分片总长度为1024,count与length数组长度必须一致; -->
<function name="sharding-by-long-hash"
class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">2,1</property>
<property name="partitionLength">256,512</property>
</function>
分片规则属性含义:
|
属性
|
描述
|
|
columns
|
标识将要分片的表字段名
|
|
algorithm
|
指定分片函数与
function
的对应关系
|
|
class
|
指定该分片算法对应的类
|
|
partitionCount
|
分片个数列表
|
|
partitionLength
|
分片范围列表
|
约束
:
- 分片长度 : 默认最大2^10 , 为 1024 ;
- count, length的数组长度必须是一致的 ;
以上分为三个分区
:0-255,256-511,512-1023
字符串hash解析算法
截取字符串中的指定位置的子字符串
,
进行
hash
算法, 算出分片。

配置
schema.xml中逻辑表配置:
<!-- 字符串hash解析算法 -->
<table name="tb_strhash" dataNode="dn4,dn5" rule="sharding-by-stringhash" />schema.xml中数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
rule.xml
中分片规则配置:
<tableRule name="sharding-by-stringhash">
<rule>
<columns>name</columns>
<algorithm>sharding-by-stringhash</algorithm>
</rule>
</tableRule>
<function name="sharding-by-stringhash"
class="io.mycat.route.function.PartitionByString">
<property name="partitionLength">512</property> <!-- zero-based -->
<property name="partitionCount">2</property>
<property name="hashSlice">0:2</property>
</function>
分片规则属性含义:
|
属性
|
描述
|
|
columns
|
标识将要分片的表字段
|
|
algorithm
|
指定分片函数与
function
的对应关系
|
|
class
|
指定该分片算法对应的类
|
|
partitionLength
|
hash
求模基数
; length*count=1024 (
出于性能考虑
)
|
|
partitionCount
|
分区数
|
|
hashSlice
|
hash
运算位
,
根据子字符串的
hash
运算
; 0
代表
str.length()
, -1
代表
str.length()-1 ,
大于
0
只代表数字自身
;
可以理解
为
substring
(
start
,
end
),
start
为
0
则只表示
0
|
按天分片算法
按照日期及对应的时间周期来分片。

配置
schema.xml中逻辑表配置:
<!-- 按天分片 -->
<table name="tb_datepart" dataNode="dn4,dn5,dn6" rule="sharding-by-date" />schema.xml中数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />
rule.xml
中分片规则配置:
<tableRule name="sharding-by-date">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-date</algorithm>
</rule>
</tableRule>
<function name="sharding-by-date"
class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2022-01-01</property>
<property name="sEndDate">2022-01-30</property>
<property name="sPartionDay">10</property>
</function>
<!--
从开始时间开始,每10天为一个分片,到达结束时间之后,会重复开始分片插入
配置表的 dataNode 的分片,必须和分片规则数量一致,例如 2022-01-01 到 2022-12-31 ,每
10天一个分片,一共需要37个分片。
-->
分片规则属性含义:
|
属性
|
描述
|
|
columns
|
标识将要分片的表字段
|
|
algorithm
|
指定分片函数与
function
的对应关系
|
|
class
|
指定该分片算法对应的类
|
|
dateFormat
|
日期格式
|
|
sBeginDate
|
开始日期
|
|
sEndDate
|
结束日期,如果配置了结束日期,则代码数据到达了这个日期的分片后,会重复从开始分片插入
|
|
sPartionDay
|
分区天数,默认值
10
,从开始日期算起,每个
10
天一个分区
|
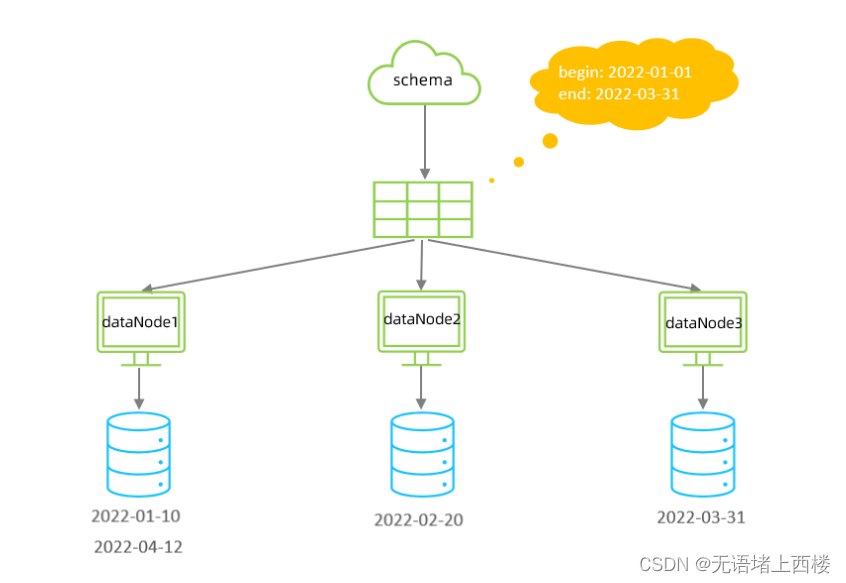
自然月分片
使用场景为按照月份来分片
,
每个自然月为一个分片。
配置
schema.xml中逻辑表配置:
<!-- 按自然月分片 -->
<table name="tb_monthpart" dataNode="dn4,dn5,dn6" rule="sharding-by-month" />schema.xml中数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />
rule.xml
中分片规则配置:
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<function name="partbymonth" class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2022-01-01</property>
<property name="sEndDate">2022-03-31</property>
</function>
<!--
从开始时间开始,一个月为一个分片,到达结束时间之后,会重复开始分片插入
配置表的 dataNode 的分片,必须和分片规则数量一致,例如 2022-01-01 到 2022-12-31 ,一
共需要12个分片。
-->
分片规则属性含义:
|
属性
|
描述
|
|
columns
|
标识将要分片的表字段
|
|
algorithm
|
指定分片函数与
function
的对应关系
|
|
class
|
指定该分片算法对应的类
|
|
dateFormat
|
日期格式
|
|
sBeginDate
|
开始日期
|
|
sEndDate
|
结束日期,如果配置了结束日期,则代码数据到达了这个日期的分片后,会重复从开始分片插入
|