MP详解
- 一、基础使用
- 1.引入
- 2.Entry中的常用注解
- 3.BaseMapper 、IService、ServiceImpl
- 3.1BaseMapper
- 3.2IService、ServiceImpl
- 4.常用配置
- 4.1 application.yml配置
- 4.2 configuration 配置
- 5.Wrapper
- 6.分页
- 6.1使用分页方式一
- 7.自定义分页:查询指定列
- 7.1 先用MP的分页只查询出对应记录的id
- 7.2 根据第一步查询到的id,在进行定量筛查
- 8.多数据源
- 8.1引入多数据源依赖
- 8.2.applicaiton编写配置
- 8.3使用 @DS
- 二、代码自动生成
- 1.引入依赖:
- 2.编写自动生成代码
- 3.运行展示
- 三、Mybatis-plus的弊端
- 1.默认分页功能不适合做大数量的分页
- 2.默认的批量插入功能,使用的是拆解为多条insert into ,而不是使用一条insert into
- 3.当数据库字段为空时,MP可能会报空指针
- 4.数据库日期类型,当数据为空时会出现映射失败的情况
- 5.当数据列为空时,结果集会自动过滤掉为空的列,返回前端时无该列
- 6.如何写and ( a=2 or b=3) 这种条件
- 7.如何使用MP进行连接查询
- 四、可能的异常
- 1.异常:InvalidDataAccessApiUsageException: Error attempting to get column 'taskPlanEndTime' from result set. Cause: java.sql.SQLFeatureNotSupportedException
一、基础使用
mybatis-plus中最常用的应该就是他的基础功能了,比如BaseMapper、IService、ServiceImpl,使用他们三个可以快速完成大部分的增删改查需求。
1.引入
启动类支持两种声明
1.使用MapperScan注解,传入Mapper接口的包名。
2.使用ComponentScan注解,同时配合Repository注解,这样也可以实现上面的功能。
增加依赖:这里只是使用BaseMapper、IService、ServiceImpl等基础信息的依赖,若是需要做自动化或者其他功能还需要增加其他依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
<version>2.4.4</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--引入alibaba的json处理对象-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.70</version>
</dependency>
<!--引入mybatis的依赖-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.2</version>
</dependency>
<!--引入连接mysql的驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<!--引入数据源连接池依赖-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.19</version>
</dependency>
<!-- 引入mybatisplus依赖-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
若是使用必须在Springboot启动类上增加MapperScan,这个MapperScan可以帮助我们自动寻找到Mapper接口从而生成Mapper配置文件。(这里如果不加MapperScan,也可以在每个Mapper接口上增加Mapper注解)。其实这里还涉及到怎么寻找Mapper的问题,MP默认情况下把自动生成的Mapper配置文件,放在资源目录下的mapper文件夹下,若是我们手动生成,也放到这里的面是不用增加mapper文件的配置信息的
// 启动类代码
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@MapperScan(value = "com.ebbing.task.mapper")
@SpringBootApplication
public class EbbingApplication {
public static void main(String[] args) {
SpringApplication.run(EbbingApplication.class, args);
}
}
2.Entry中的常用注解
上面准备好以后就可以开始编写实体类了,实体类对应数据库表。若是表名和实体类名相同,字段名和数据库字段名也相同(数据库使用下划线,实体使用驼峰是支持自动转换的,也认为相同),且主键id就是id,则我们无需任何处理,MP可以全部帮我们进行自动对其。但有任何不同我们是都需要使用注解进行声明的。
import com.baomidou.mybatisplus.annotation.*;
import lombok.Data;
import lombok.experimental.Accessors;
import java.io.Serializable;
import java.time.LocalDateTime;
/**
* <p>
*
* </p>
*
* @author pcc
* @since 2023-08-04
*/
@Data
@TableName("tb_task")
@Accessors(chain = true)
public class TbTask implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@TableId(value = "task_id", type = IdType.AUTO)
private Long taskId;
/**
* 任务名
*/
private String taskName;
/**
* 任务描述
*/
private String taskDesc;
/**
* 任务文档链接
*/
private String taskLinkText;
/**
* 任务脑图连接
*/
private String taskLinkMap;
/**
* 任务关键程度: 1 普通,2重要,3很重要,4非常重要
*/
private Integer deep;
/**
* 创建时间
*/
private LocalDateTime createTime;
/**
* 创建人
*/
private String createBy;
/**
* 修改时间
*/
private LocalDateTime updateTime;
/**
* 修改人
*/
private String updateBy;
/**
* 状态:0:正常,1删除
*/
@TableLogic
private Integer isDeleted;
/**
* 数据版本:乐观锁
*/
@Version
private Integer version;
}
上面是自动生成的实体类,当然和我们手动写没有太大区别,总结下其中的注解
-
注解@TableName:
主要用以声明实体对应的表,此外还支持前缀等其他声明,不过基本只使用用来和表作对应,当表明和实体类名不一致时需要使用该注解,需要特别注意的是,实体类的驼峰和表名的下划线是无法完成映射的,这点和字段与属性的对应有区别。 -
注解@TableId:
value用以声明主键是哪个字段,type用以声明主键的生成规则,默认是无,也就是不填充,总共支持五种规则:①IdType.AUTO: 自增注解,对应数据库的auto_increment,②IdType.NONE:这是默认的行为,应该是需要自己去操作的。③IdType.INPUT:需要自己输入主键,若是插入时没有会报错,④IdType.ASSIGN-ID:这是雪花算法生成的id,可以用来做分布式服务的主键策略,他是支持的。**⑤IdType.**ASSIGN_UUID:这里使用UUID做为主键,这个不是一个好的选择,UUID对于数据库的BTREE索引来说不够高效,范围查询效率很低。 -
注解@TableField :
这个注解使用率也是特别高的,主要用来声明属性和列的对应关系,若只是驼峰和下划线的区别则无需声明,若是该字段无需与数据库进行映射,可以将-
exists=false,来禁止数据库的映射
-
select = false若是该字段永远不想要被select查询到,可以使用select = false
-
updateStrategy=FieldStrategy.DEFAULT 这是默认值,当执行更新策略时忽略null的场景他和NOTNULL等效,也就是说传递null不更新,如果想要更新可以更改为FieldStrategy.IGNORED意思为忽略判断直接更新,此时为null和为空都会更新,当然还有别的选择可以根据非null更新,非空更新等。
-
insertStrategy=FieldStrategy.DEFAULT,这个和上面没有区别,只不过是应用插入场景。
-
fill=FieldFill.DEFAULT 默认是不处理,如果改为FieldFill.INSERT 即表示新增时必须有值,不然报错,相当于断言,此外还有别的支持具体看源码吧
他除了value、exists、select,其他支持的功能比较多,不过基本用不到,这里不一一列举了
-
-
注解@TableLogic:
(0在使用,1已删除)这个注解被使用与逻辑删除字段上,若是遵循驼峰转下划线的规则,则无需多余声明什么,只需增加该注解在对应字段上即可。增加该注解有一个前提:数据库有该字段,且默认值为0。他有两个作用:①当增加了该注解后,调用BaseMapper的delete方法或者IService的remove方法,他们都不会去真正删除记录,而是将对应记录的逻辑删除字段更改为1.②当增加了该注解后无论是BaseMapper还是IService的查询方法默认都会增加逻辑删除字段等于0的条件。 -
注解@Version:
这个注解是用来声明乐观锁的注解,乐观锁即CAS:比较然后交换。使用它有一个前提条件,就是我们需要手动增加支持乐观锁的配置,如下:import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor; import com.baomidou.mybatisplus.extension.plugins.inner.OptimisticLockerInnerInterceptor; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; /** * @author pcc */ @Configuration public class MPConfig { @Bean public MybatisPlusInterceptor getInstance(){ MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor(); interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor()); return interceptor; } }
增加了上面的配置后,MP为自动拦截我们的sql,并为我们增加乐观锁的支持了,分页其实也需要这个,都是一个原理。然后就是@Version 有两个作用和一个注意点
* 1.增加乐观锁以后,若是我们没有传递这个信息到MP,那默认是不适用乐观锁的,所以若是使用,则必须保证前后端交互时这个字段必须传递。
* 2.只需要增加一个配置和一个注解,即可使用乐观锁,在更新数据库时,MP为自动增加乐观锁的条件,比如verison=0,满足才会更新
* 3.每次更新记录,乐观锁的值都会+1.
* 4.需要特别注意的是,乐观锁和数据版本不可混为一谈,数据版本一般只有审核流程通过才会+1,乐观锁纯粹是为了防止数据更新时出现错误而设置的,如需数据版本应从新声明。
3.BaseMapper 、IService、ServiceImpl
这三个才是MP的核心啊,只要掌握了他们三个,大部分的CRUD就都解决了。
3.1BaseMapper
有时候我们甚至直接使用BaseMapper都是可以的,因为这里已经包含了大部分我们需要的方法,直接使用他可以满足大部分的功能,不过有些需要业务处理的场景,我们还是需要写Service的。
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.ebbing.task.entity.TbDict;
/**
* <p>
* Mapper 接口
* </p>
*
* @author pcc
* @since 2023-08-04
*/
public interface TbDictMapper extends BaseMapper<TbDict> {
}
如上所示,当我们想要写一个Mapper接口时,只需要继承BaseMapper,同时声明BaseMapper的泛型类,这样我们大部分的CRUD的方法都不用写了,MP利用这个泛型类,通过反射来为我们在resource下的mapper文件夹中自动生成了Mapper的配置文件(mvn install后可以看到).这里有一个需要注意的点是:若是不在当前接口增加Mapper注解,则需要在启动类上增加MapperScan注解,同时将Mapper接口所在的文件夹进行声明,后面我们就可以直接通过autowired来进行使用这个Mapper了
3.2IService、ServiceImpl
IService是Mp提供的接口,里面同样包含了很多CRUD的方法,但是他是一个接口,所以我们不可能直接使用的,所以必须配合ServiceImpl才可以使用,ServiceImpl里面正常IService的实现类,不过ServiceImpl里面大部分方法还是调用的是BaseMapper的实现,所以ServiceImpl声明时,我们还需要传入BaseMapper的实现,也就是我们自己写的Mapper接口了。
import com.ebbing.task.entity.TbTask;
import com.baomidou.mybatisplus.extension.service.IService;
/**
* <p>
* 服务类
* </p>
*
* @author pcc
* @since 2023-08-04
*/
public interface ITbTaskService extends IService<TbTask> {
}
import com.ebbing.task.entity.TbTask;
import com.ebbing.task.mapper.TbTaskMapper;
import com.ebbing.task.service.ITbTaskService;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.springframework.stereotype.Service;
/**
* <p>
* 服务实现类
* </p>
*
* @author pcc
* @since 2023-08-04
*/
@Service
public class TbTaskServiceImpl extends ServiceImpl<TbTaskMapper, TbTask> implements ITbTaskService {
}
需要特別注意的是无论是IService还是ServiceImpl都是需要声明泛型的,且ServiceImpl是类需要去继承,而不是实现,这样就完成了所有的接口开发了,剩下我们自己写Controller就行了。
4.常用配置
4.1 application.yml配置
mybatis-plus:
# 配置Mybatis的配置文件位置,这个基本用不到,现在都是在application中配置
# config-location: classpath:mybatis-config.xml
# 下面是默认配置,如果放了下面的位置,则无需增加该配置
mapper-locations: classpath:mapper/**/*.xml
# 这个没有默认,别名包扫描,需要直接配即可
type-aliases-package: com.ebbing.task.entity
configuration:
# 默认值是true
call-setters-on-nulls: true
# 默认开启缓存,这个是二级缓存
cache-enabled: true
# 开启控制台日志打印
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
# 这个是和注解@TableLogic配合使用的,设置后删除数据会将逻辑删除字段设置为1
logic-delete-value: 1
# 这个是和注解@TableLogic配合使用的,设置后新增数据会将逻辑删除字段设置为0,且查询时会默认携带删除字段为0的条件
logic-not-delete-value: 0
db-config:
# 设置表名前缀,这个在实体类中使用,若是所有的表都有共同前缀,使用这个很方便
# table-prefix: tb_
# 这个配置是设置ID自增类型的,一般使用AUTO或者ASSIGN_ID
id-type: auto
4.2 configuration 配置
这里一般就是需要配置分页插件和乐观锁插件,因为他们都需要使用拦截器对sql执行进行拦截,然后更改sql
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.OptimisticLockerInnerInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author pcc
*/
@Configuration
public class MPConfig {
@Bean
public MybatisPlusInterceptor getInstance(){
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 拦截sql,实现分页
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
// 拦截sql,实现乐观锁
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return interceptor;
}
}
5.Wrapper
Wrapper也算是MP的一个核心类,因为大部分的查询条件都是使用Wrapper来进行拼接的,而我们上面使用的BaseMapper、IService中很多都是传入Wrapper或者Wrapper的实现类,比如
Long selectCount(@Param("ew") Wrapper<T> queryWrapper);
List<T> selectList(@Param("ew") Wrapper<T> queryWrapper);
List<Map<String, Object>> selectMaps(@Param("ew") Wrapper<T> queryWrapper);
List<Object> selectObjs(@Param("ew") Wrapper<T> queryWrapper);
从上面可以看出,只要是Wrapper我们都是可以传入的,需要特别注意泛型别漏了。
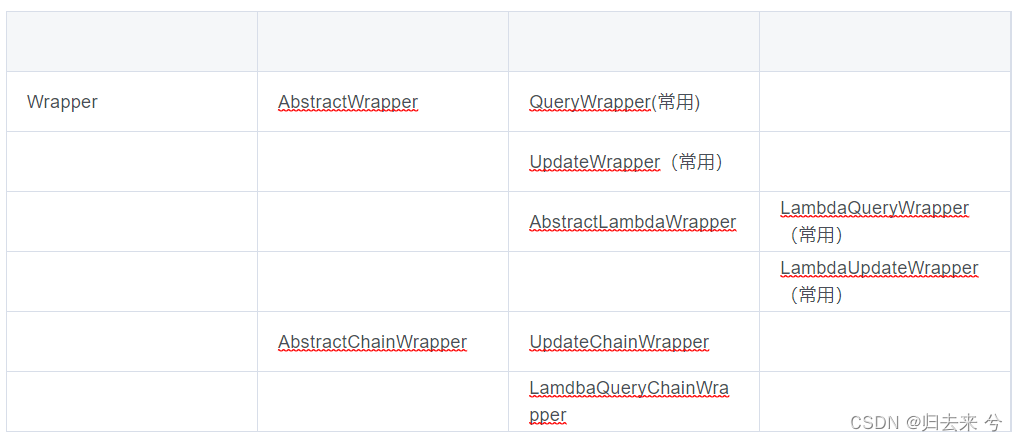
一般使用LambdaQueryWrapper比较多一些,因为书写简单,注意之类使用时不能忘了泛型。
6.分页
使用MP的分页功能无需导入多余的依赖,只需要配置下对Mybatis的sql进行拦截即可。这块代码上面其实也列过了
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.OptimisticLockerInnerInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author pcc
*/
@Configuration
public class MPConfig {
@Bean
public MybatisPlusInterceptor getInstance(){
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 拦截sql,实现分页
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
// 拦截sql,实现乐观锁
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return interceptor;
}
}
6.1使用分页方式一
在查询时直接传入page,和Wrapper,这样我们查询的分页结果会直接封装到Page里面,若是不需要对数据结构进行更改,可以直接返回。
@PostMapping("/getTaskItems")
public IPage<TbTaskItems> getTaskItems(TbTaskItemsVO tbTaskItemsVO){
Page<TbTaskItems> page = new Page<>();
page.setCurrent(tbTaskItemsVO.getPageIndex());
page.setSize(tbTaskItemsVO.getPageSize());
iTbTaskItemsService.page(page,null);
return page;
}
7.自定义分页:查询指定列
当数据列特别大时,比如上千万的表,越往后分页就会越久,倘若使用mybatis-plus提供的分页,很有可能数据会查不出来。完全可以分两步走:
7.1 先用MP的分页只查询出对应记录的id
因为id是聚簇索引不需要回表,效率会非常的高,这样可以快速帮我们定位到记录。那Mybatis-plus怎么做到只查询指定列呢?
这里实现方式很多,最方便的就是使用Wrapper来进行直接限定查询到得列:
@PostMapping("/getTaskItems")
public IPage<TbTaskItems> getTaskItems(TbTaskItemsVO tbTaskItemsVO){
Page<TbTaskItems> page = new Page<>();
page.setCurrent(tbTaskItemsVO.getPageIndex());
page.setSize(tbTaskItemsVO.getPageSize());
iTbTaskItemsService.page(page,
new LambdaQueryWrapper<TbTaskItems>().select(
TbTaskItems::getTaskId,
TbTaskItems::getItemReviewTime,
TbTaskItems::getVersion)
);
return page;
}
7.2 根据第一步查询到的id,在进行定量筛查
看起来多了一步,其实在数据量大时会提升非常多的性能,这也是大部分大数量时分页的一种方案
8.多数据源
适合读写分离时使用,使用起来也很简单:
8.1引入多数据源依赖
版本和MP保持一致即可
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
8.2.applicaiton编写配置
区别就是相比于一个数据源,多配置了一遍而已,这里的primary是配置默认数据源的,当不在使用时指定就使用该配置指定的数据源,strict配置false,默认也是false,是否强制校验数据源,强制的话数据源一旦出错就会报错,而不会使用默认的数据源
spring:
datasource:
dynamic:
primary: master #设置默认的数据源或者数据源组,默认值即为master
strict: false #是否强制校验数据源
datasource:
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.150.180:3306/ebbing?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowMultiQueries=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=Asia/Shanghai
username: root
password: super
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.150.180:3306/ebbing2?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowMultiQueries=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=Asia/Shanghai
username: root
password: super
8.3使用 @DS
使用时也很简单,直接在对应的Service的实现类或者方法上增加该注解即可,该注解只有一个属性value,声明为我们的master或者slave,就可以正常调用对应的数据源了。
二、代码自动生成
代码生成配置很简单,不过内置的是mysql5的驱动,支持5.5.45+, 5.6.26+ and 5.7.6+ ,若是换驱动还得其他配置。默认情况下,我们只需要声明url、username、password即可。
1.引入依赖:
<!-- 引入mybatis-plus依赖 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
<!-- 引入代码自动生成依赖,这个依赖必须单独引 -->
<dependency
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.1</version>
</dependency>
<!-- 官网上没说需要引入这个依赖,但是我自己测试时,缺少这个依赖运行不了,也有可能是多级依赖下载失败了 -->
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity</artifactId>
<version>1.7</version>
</dependency>
当时引入velocity时,下面的包一直进不来,所以单独引了下面的包,但是其实可以不引,因为下面的包,是上面包的依赖包,会被加载,若是加载不出来,则需要我们手动去引入:
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.3</version>
</dependency>
2.编写自动生成代码
下面是代码,我们只声明了数据库的配置信息,然后采用交互式输入作者和包名路径即可,这里的包名路径记得一定得是我们项目里的实际的包名路径,比如我的项目的根路径是com.example.demo5,我想要自动生成的代码新开一个包叫task,那我们输入包名时就应该这么写:com.example.demo5.task。后面自动生成的代码路径都是这个了:
package com.example.demo5.generage;
import com.baomidou.mybatisplus.generator.FastAutoGenerator;
import com.baomidou.mybatisplus.generator.config.DataSourceConfig;
import java.sql.SQLException;
/**
* <p>
* 快速生成
* </p>
*
* @author pcc
* @since 2023-08-04
*/
public class FastAutoGeneratorTest {
static final String URL = "jdbc:mysql://192.168.150.180:3306/ebbing";
static final String USERNAME = "root";
static final String PASSWORD = "super";
/**
* 执行 run
*/
public static void main(String[] args) throws SQLException {
FastAutoGenerator.create(
//配置数据源
new DataSourceConfig.Builder(URL, USERNAME, PASSWORD))
// 全局配置: 注意包名需要使用全路径
.globalConfig((scanner, builder) -> builder.author(scanner.apply("请输入作者名称?")).fileOverride())
// 包配置
.packageConfig((scanner, builder) -> builder.parent(scanner.apply("请输入包名?")))
// 策略配置:内部声明表名
.strategyConfig(builder -> builder.addInclude("tb_task"))
.execute();
}
}
3.运行展示
下面是运行成功的截图:
已连接到目标 VM, 地址: ''127.0.0.1:5332',传输: '套接字''
请输入作者名称?
pcc
请输入包名?
com.example.demo5.task
11:51:38.854 [main] DEBUG com.baomidou.mybatisplus.generator.AutoGenerator - ==========================准备生成文件...==========================
Fri Aug 04 11:51:39 CST 2023 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
11:51:39.529 [main] DEBUG com.baomidou.mybatisplus.generator.config.querys.MySqlQuery - 执行SQL:show table status WHERE 1=1 AND NAME IN ('tb_task')
11:51:39.545 [main] DEBUG com.baomidou.mybatisplus.generator.config.querys.MySqlQuery - 返回记录数:1,耗时(ms):14
11:51:39.563 [main] DEBUG com.baomidou.mybatisplus.generator.config.querys.MySqlQuery - 执行SQL:show full fields from `tb_task`
11:51:39.578 [main] DEBUG com.baomidou.mybatisplus.generator.config.querys.MySqlQuery - 返回记录数:11,耗时(ms):14
11:51:39.603 [main] DEBUG org.apache.velocity - CommonsLogLogChute name is 'org.apache.velocity'
11:51:39.604 [main] DEBUG org.apache.velocity - Initializing Velocity, Calling init()...
11:51:39.604 [main] DEBUG org.apache.velocity - Starting Apache Velocity v1.7 (compiled: 2010-11-19 12:14:37)
11:51:39.604 [main] DEBUG org.apache.velocity - Default Properties File: org\apache\velocity\runtime\defaults\velocity.properties
这里只展示了部分的执行成功信息,默认情况下代码会生成在D盘下面的我们声明的路径中。
三、Mybatis-plus的弊端
1.默认分页功能不适合做大数量的分页
在第一章第7节,已说过该部分
2.默认的批量插入功能,使用的是拆解为多条insert into ,而不是使用一条insert into
如果需要考虑到效率,这种需要自己写批量新增的功能,如果表数据量比较大,最好是自己写批量新增的功能,而不是使用mybatis-plus来使用他的批量新增功能
3.当数据库字段为空时,MP可能会报空指针
这里原因是因为,默认(3.5.1)情况下查询的值即使为null也会将值set到对应的实体中,若是想要禁止这种情况,有两种方案。
①:在字段上增加注解@TableField(exist=false),这样当这个配置是忽略这个字段与数据库的映射
②:全局配置增加mybatis-plus.configuration.call-setters-on-nulls=false,这是为全局的字段增加这个配置,试了不好使
4.数据库日期类型,当数据为空时会出现映射失败的情况
核心问题应该还是数据源的问题,也看到了这部分问题的解释。
解决的方法有以下几种:
1.增加针对LocalDateTime的序列化操作,试了不好使
2.更换druid数据源,试了不好使
3.升级druid,升级出现问题,操作中断
4.数据库字段使用date代替datetime,对应java里的LocalDate,试了不好使
5.增加某个jar,说是解决这个问题,试了不好使
6.取消数据库字段datetime,使用了String,最后实在没办法,用了下下策
5.当数据列为空时,结果集会自动过滤掉为空的列,返回前端时无该列
这个问题解决办法:
①。配置mybatis-plus的配置:
mybatis-plus:
configuration:
# 默认值是true,即:即使查询的值为null,也会进行set,这会导致空指针,所以改为false
call-setters-on-nulls: true
②或者使用mybatis的配置,也是这个配置
mybatis:
configuration:
call-setters-on-nulls: true
③若是以上都不行,建议换个http客户端工具:我的就是工具问题,找了半天,换了个工具正常了,离了大浦
6.如何写and ( a=2 or b=3) 这种条件
如下:
wrapper.and(i -> i.eq(T::getA, 2).or().eq(T::getB, 3));
and()方法接收一个函数式接口作为参数,在函数里我们可以写出一个完整的条件表达式。
示例中我们写了:
- i.eq(T::getA, 2) 表示 a = 2
- i.or() 表示或条件
- i.eq(T::getB, 3) 表示 b = 3
将这些条件通过or()组合起来,就可以表达一个and (a = 2 or b = 3)的条件。
and()方法会将这整个条件表达式作为一个单元进行组合。
7.如何使用MP进行连接查询
以下方法3.4.2才开始支持
wrapper.innerjoin(右表字段,左表字段)
wrapper.leftjoin(右表字段,左表字段)
四、可能的异常
1.异常:InvalidDataAccessApiUsageException: Error attempting to get column ‘taskPlanEndTime’ from result set. Cause: java.sql.SQLFeatureNotSupportedException
异常各版本:
druid:1.1.11
Mybatis-plus:3.4.1
Mysql:5.7
使用了低版本的Druid数据源。这个低版本的Druid数据源不支持JDK8中的LocalDate、LocalTime、LocalDateTime等日期类型,所以导致了异常的发生。
为了解决这个问题,你可以下载一个高于或等于1.1.21版本的Druid依赖,并将其添加到你的项目中。你可以在你的项目的pom.xml文件中添加以下依赖项:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.21</version>
</dependency>
这样,你就可以使用支持JDK8日期类型的Druid数据源,从而解决InvalidDataAccessApiUsageException异常