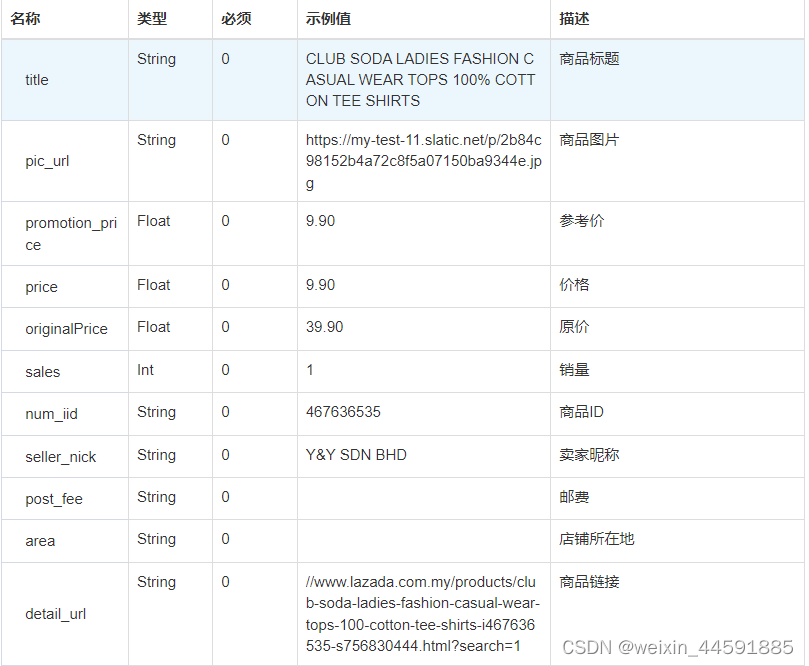
一、 简介
NoSQL数据库四大家族:列存储 Hbase,键值(Key-Value)存储 Redis,图像存储 Neo4j,基于分布式文档存储的数据库MongoDb。
MongoDB 和关系型数据库对比
| 关系型数据库 | MongoDB |
| database(库) | database(库) |
| table(表) | collection(表) |
| row(行) | document(BSON文档) |
| column(列) | field(字段) |
| index(索引) | index(地理索引、全文索引、hash索引) |
| join(主外键关联) | embedded Document (嵌套文档) |
| primary key(指定1至N个列做主键) | primary key(指定1至N个列做主键) |
BSON是一种类json的一种二进制形式的存储格式,简称Binary JSON,它和JSON一样,支持内嵌的文 档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和Binary Data类型。
二、Linux安装Mongodb
解压: tar -xvf mongodb-linux-x86_64-4.1.3.tgz
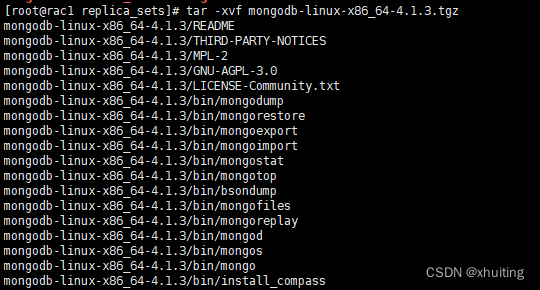
启动的两种方式:
1)默认27017的端口启动:./bin/mongod
2)指定配置文件的方式启动:./bin/mongod -f mongo_37017.conf

注意:若启动报目录缺失, 需要创建对应的目录的文件,如: mkdir -p /data/mongo/data/server1
mongo shell 的启动
启动mongo shell :./bin/mongo
指定主机和端口的方式启动 :./bin/mongo --host=主机IP --port=端口
三、MongoDb的GUI工具
NoSQLBooster是MongoDB CLI界面中非常流行的GUI工具。它正式名称为MongoBooster。
默认安装即可。

四、简单操作
查看数据库:
show dbs;
切换数据库 如果没有对应的数据库则创建:
use 数据库名;
创建集合:
db.createCollection("集合名")
查看集合:
show tables;
show collections;
删除集合:
db.集合名.drop();
删除当前数据库:
db.dropDatabase();
聚合操作:
单目的聚合操作:count() 和 distinct()
聚合管道(Aggregation Pipeline):
聚合(aggregate)主要用于统计数据(诸如统计平均值,求和等),并返回计算后的数据结果。
MapReduce 编程模型:
MapReduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结 果合并成最终结果(REDUCE)。
五、索引
1. 单键索引
2. 复合索引
3. 多键索引
4. 地理空间索引
5. 全文索引
6. 哈希索引
六、索引底层实现原理
MongoDb使用BSON格式保存数据。与mysql使用B+树不一样,MongoDb用的是B-树,所有节点都有Data域,每个节点既保存数据又保存索引,搜索时相当于二分查找。
B-树的特点: (1) 多路 非二叉树 (2) 每个节点 既保存数据 又保存索引 (3) 搜索时 相当于二分查找
B+ 树的特点: (1) 多路非二叉 (2) 只有叶子节点保存数据 (3) 搜索时 也相当于二分查找 (4) 增加了 相邻节点指针
七、高可用
7.1 主从复制架构
主从结构没有自动故障转移功能,需要指定master和slave端,不推荐在生产中使用。 mongodb4.0后不再支持主从复制!
[main] Master/slave replication is no longer supported
7.2 复制集replica sets
原理:一个复制集中Primary节点上能够完成读写操作,Secondary节点仅能用于读操作。Primary节点需要记录所有改变数据库状态的操作,这些记录保存在 oplog 中,这个文件存储在 local 数据库,各个Secondary 节点通过此 oplog 来复制数据并应用于本地,保持本地的数据与主节点的一致。oplog 具有幂等性,即无论执行几次其结果一致,这个比 mysql 的二进制日志更好用。
复制集数据同步分为初始化同步和keep复制同步。初始化同步指全量从主节点同步数据,如果Primary 节点数据量比较大同步时间会比较长。而keep复制指初始化同步过后,节点之间的实时同步一般是增量 同步。
初始化同步有以下两种情况会触发: (1) Secondary第一次加入。 (2) Secondary落后的数据量超过了oplog的大小,这样也会被全量复制。
主节点选举触发的时机:
第一次初始化一个复制集
Secondary节点权重比Primary节点高时,发起替换选举
Secondary节点发现集群中没有Primary时,发起选举 Primary节点不能访问到大部分(Majority)成员时主动降级
当触发选举时,Secondary节点尝试将自身选举为Primary。主节点选举是一个二阶段过程+多数派协议。
第一阶段: 检测自身是否有被选举的资格,如果符合资格会向其它节点发起本节点是否有选举资格的 FreshnessCheck,进行同僚仲裁
第二阶段: 发起者向集群中存活节点发送Elect(选举)请求,仲裁者收到请求的节点会执行一系列合法性检查,如果检查通过,则仲裁者(一个复制集中最多50个节点 其中只有7个具有投票权)给发起者投一票。
pv0通过30秒选举锁防止一次选举中两次投票。
pv1使用了terms(一个单调递增的选举计数器)来防止在一次选举中投两次票的情况。
多数派协议:
发起者如果获得超过半数的投票,则选举通过,自身成为Primary节点。获得低于半数选票的原因,除了常见的网络问题外,相同优先级的节点同时通过第一阶段的同僚仲裁并进入第二阶段也是一个原因。因此,当选票不足时,会sleep[0,1]秒内的随机时间,之后再次尝试选举。
7.3 环境搭建
1. 创建目录: mkdir replica_sets
2. 进到目录中,解压mongodb: tar -xvf mongodb-linux-x86_64-4.1.3.tgz
3. 确保当前没有正在运行的monodb
![]()
4. 创建,编写mogo的配置文件:vi mongo_37017.conf
![]()
# 主节点配置
dbpath=/data/mongo/data/server1
bind_ip=0.0.0.0
port=37017
fork=true
logpath=/data/mongo/logs/server1.log
replSet=lagouCluster
#从节点配置
dbpath=/data/mongo/data/server2
bind_ip=0.0.0.0
port=37018
fork=true
logpath=/data/mongo/logs/server2.log
replSet=lagouCluster
#从节点配置
dbpath=/data/mongo/data/server3
bind_ip=0.0.0.0
port=37019
fork=true
logpath=/data/mongo/logs/server3.log
replSet=lagouCluster
5. 创建缺失目录:
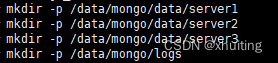
6. 根据配置文件加载启动3个节点:
./bin/mongod -f mongo_37017.conf
./bin/mongod -f mongo_37018.conf
./bin/mongod -f mongo_37019.conf
7. 初始化节点配置,进入任意一个节点比如37017节点运行如下命令:
var cfg ={"_id":"lagouCluster",
... "protocolVersion" : 1,
... "members":[
... {"_id":1,"host":"192.168.0.203:37017","priority":10},
... {"_id":2,"host":"192.168.0.203:37018"}
... ]
... }
37017初始化后,该节点由“SECONDARY”变为“PRIMARY”。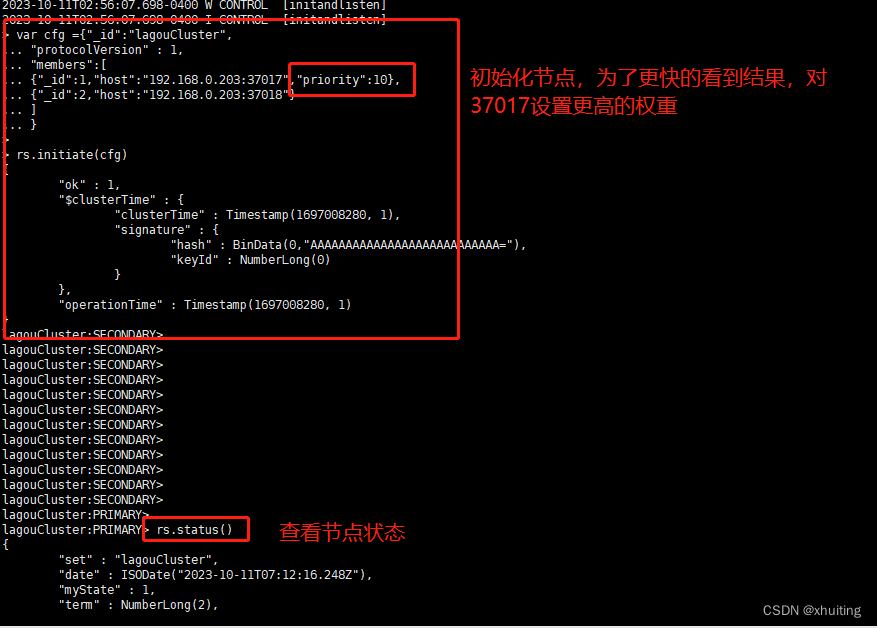

8. 主节点可以进行增删节点操作:
rs.add("192.168.0.203:37019")
rs.remove("192.168.0.203:37019")
9. 插入数据验证结果:
进入主节点 ----- 插入数据 ------ 进入从节点验证
注意:默认节点下从节点不能读取数据。调用 rs.slaveOk() 解决。
37017主节点:

37018从节点:
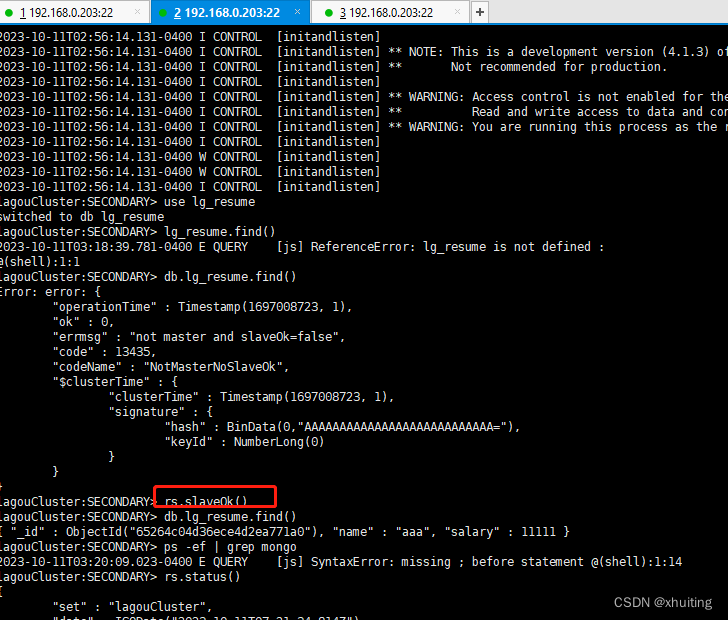
节点说明:
PRIMARY 节点: 可以查询和新增数据
SECONDARY 节点:只能查询 不能新增 基于priority 权重可以被选为主节点
ARBITER 节点: 不能查询数据 和新增数据 ,不能变成主节点