目录
题目:
示例:
分析:
代码:
题目:
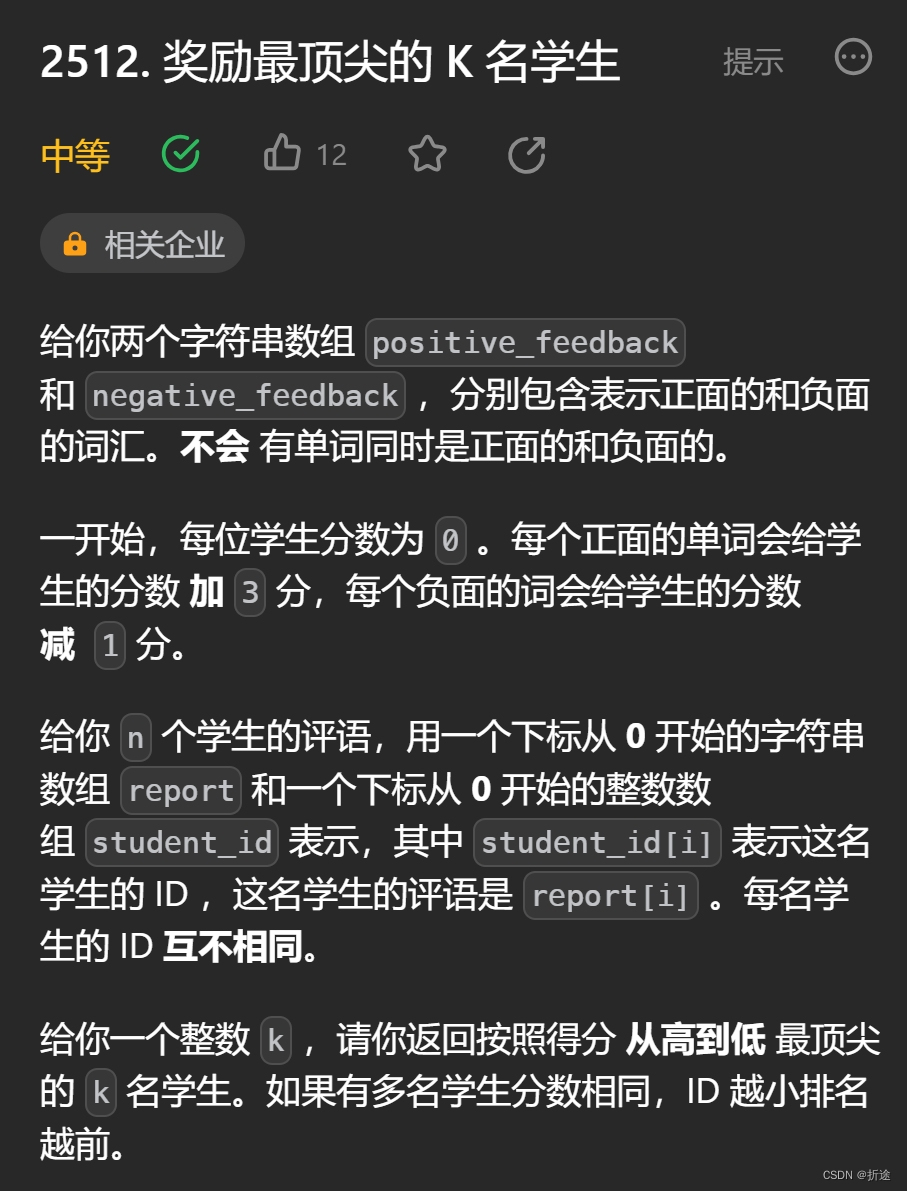
示例:

分析:
题目给我们两个字符串数组,分别表示正面评价的单词和负面评价的单词。再给我们n个学生的评语,评语中有一个正面单词我们就加3分,有一个负面单词我们就减一分。最终要我们返回分数最高的前k个学生的id,如果分数一致则优先选取id小的学生。
大体思路就是我们直接模拟就好了,把每个评语的单词提取出,然后去寻找这个单词是否属于正面评价或是负面评价,对应的加分减分,最终按照题目要求排序即可。
我们需要快速的知道某个单词是否在正面单词或是负面单词中,那么我们就可以先把两个存放单词是数组转为set来方便我们查找。
提取出评价中的单词也好办,只需要将整个字符串按照空格来分割就好。
分数统计完毕之后再按照题目要求排序,取出前k个学生即可。
下面的代码看着多,其实核心思路就是我上面这一小段,代码显得臃肿主要是我代码水平不到位,这道题其实是不难的。
代码:
class Solution {
public:
vector<int> topStudents(vector<string>& positive_feedback, vector<string>& negative_feedback, vector<string>& report, vector<int>& student_id, int k) {
//将正面和负面的单词转为set方便后续查找
unordered_set<string>good(positive_feedback.begin(),positive_feedback.end());
unordered_set<string>bad(negative_feedback.begin(),negative_feedback.end());
//map用来统计学生的分数
unordered_map<int,int>m;
vector<int>res;
int n=report.size();
for(int i=0;i<n;i++){
m[student_id[i]]=0;
string temp="";
//提取评语中的每个单词
for(char& c:report[i]){
if(c!=' ') temp+=c;
else{
//提取出单词之后和好词坏词比较,对应地加分减分
if(good.count(temp)) m[student_id[i]]+=3;
else if(bad.count(temp)) m[student_id[i]]--;
temp="";
}
}
if(good.count(temp)) m[student_id[i]]+=3;
else if(bad.count(temp)) m[student_id[i]]--;
}
vector<vector<int>>cache;
//提取出每个学生的id以及分数
for(auto& a:m){
cache.push_back({a.first,a.second});
}
//按照题目要求排序
sort(cache.begin(),cache.end(),[](auto& a,auto& b){
if(a[1]!=b[1]) return a[1]>b[1];
return a[0]<b[0];
});
//再将学生id取出
for(auto& c:cache){
//最多取出k名
if(res.size()>=k) break;
res.push_back(c[0]);
}
return res;
}
};