文章目录
- 一、背景
- 二、方法
- 2.1 latent motion representation
- 2.2 latent code driven image animation
- 2.3 学习方式
- 2.4 推理
- 三、效果
- 3.1 数据集
- 3.2 训练细节
- 3.3 评估
- 3.4 定性效果
- 3.5 定量效果
- 3.6 消融实验
- 3.7 失败示例
论文:Latent Image Animator: Learning to Animate Images via Latent Space Navigation
代码:https://github.com/wyhsirius/LIA
出处:ICLR 2022
一、背景
现有的 image animation 方法一般都使用计算机图形学、语义 map、人体关键点、3D meshs、光流等,这些方法的 gt 需要提前提取出来,在实际使用中会受限。对没见过的人物表现很差。
自监督方法将原始的视频作为输入,使用预测的密集光流场来控制输入图片的运动,这样虽然能够避免对领域知识或标记 gt 的需求,能够提升在任意图像上测试的性能。但这些方法需要明确的结构表达来作为运动指引。其他的先验信息如关键点等,也会使用一个额外的网络来进行端到端训练,作为预测光流场过程的中间特征。虽然这样不需要提前提取 gt label,但也会提升复杂度。
在本文中,为了降低复杂度,作者剔除了额外的分支,而是使用隐空间。本文方法受启发于 GAN、styleGAN、BigGAN
作者提出了 LIA(Latent Image Animate),主要由自编码器构成,通过隐空间来引导对图像的驱动
作者引入了 Linear Motion Decomposition (LMD) ,通过线性组合一系列可学习的运动方向和大小,来表达隐空间中的路径。也就是将这一系列都限制为正交基,每个向量都表示一个基础的视觉变换。
且在 LIA 中,在一个 encoder-generator 结构中的 motion 和 appearance 是解耦的,没有使用分开的网络结构,这样能降低计算量。
二、方法
Self-supervised image animation 的目标将 driving video 的运动迁移到 source image 上,让 source image 按照 driving video 的运动方式动起来
如图 2 所示,本文的想法是通过隐空间来引导运动系数的建模,整个大体过程如图 2 所示
- 在训练过程中,需要同时输入 source 和 driving image,driving image 是从 video 中随机采样的。两个图像都会编码到隐空间,用于表达运动变化,training 目标是使用学习到的 motion transformation 和 source image 来重建 driving image
- 在测试过程中,driving video 中的每一帧都会顺序的被处理,来驱动 source subject
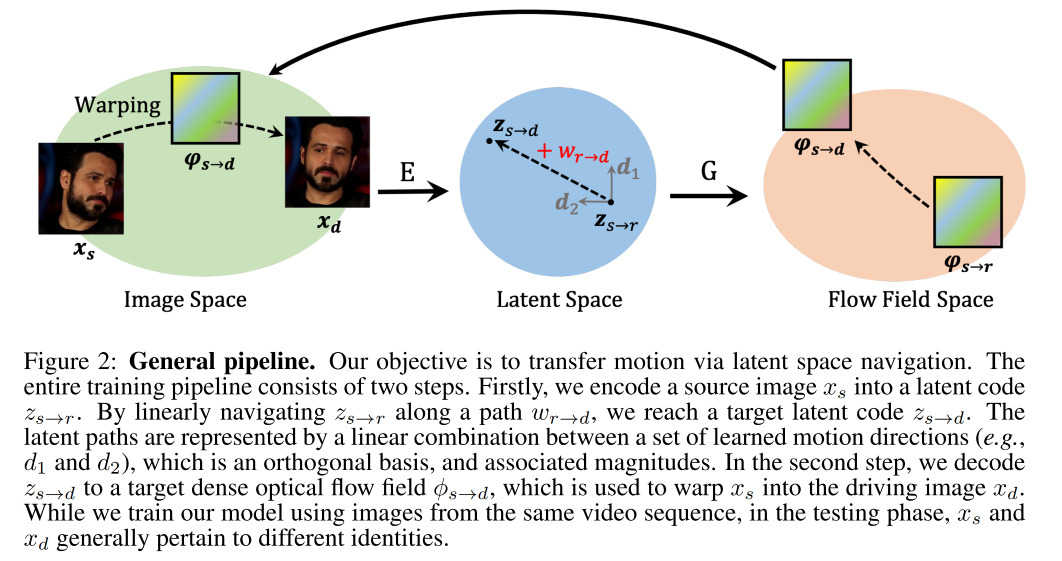
框架结构如图 3 所示,整个模型是自编码器的结构,由两个主要的网络构成
- encoder E:是第一步,也就是对 source image 和 driving image 进行编码,编码到隐空间,
- generator G:是第二步,也就是当获得了 target latent code 后,G 会 decode
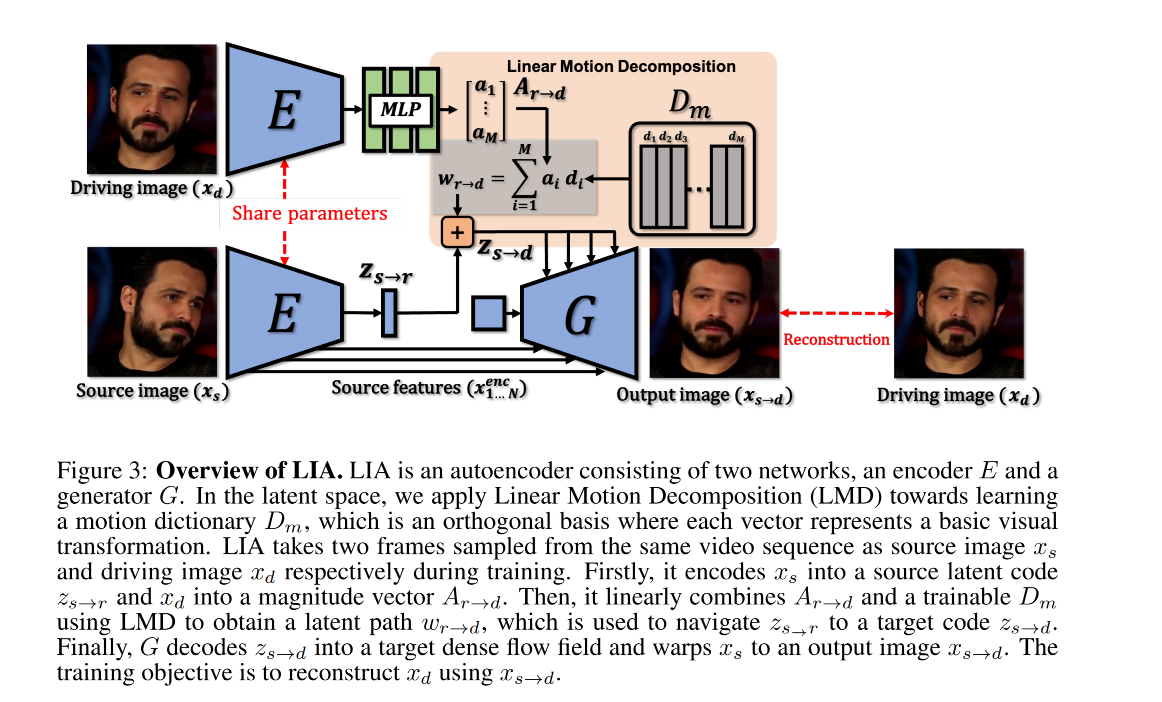
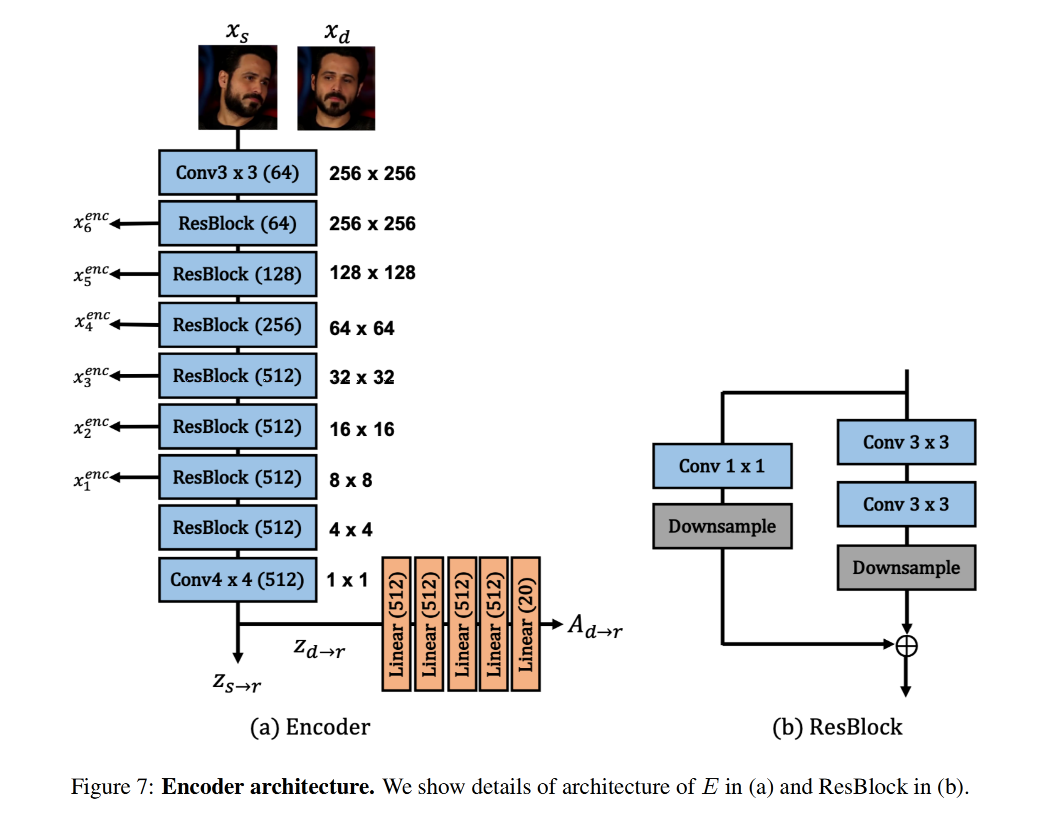
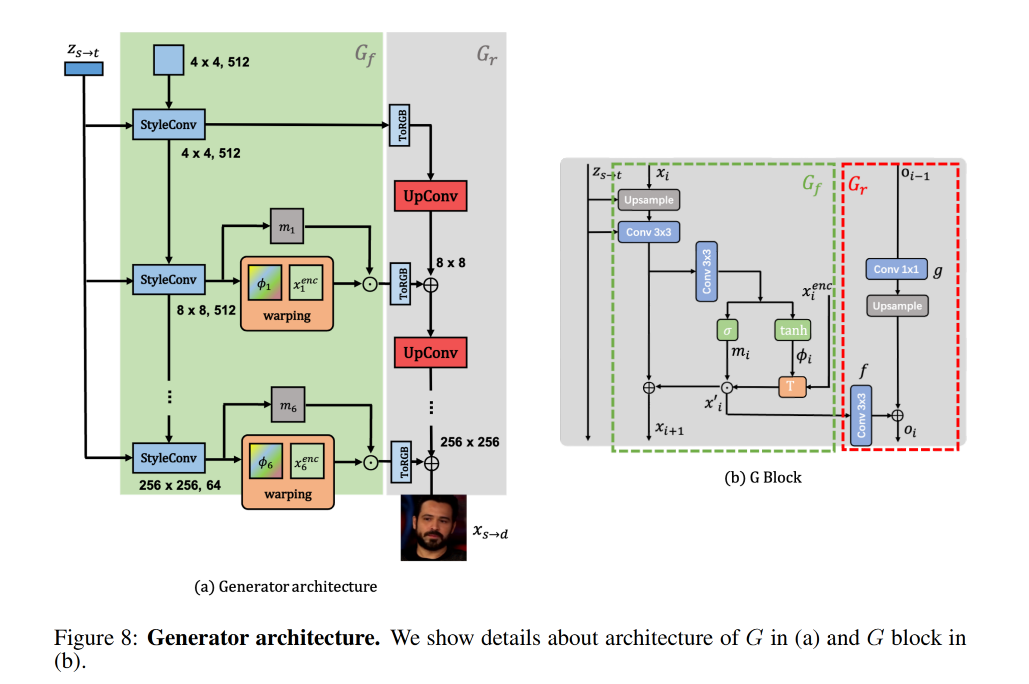
2.1 latent motion representation
给定 source image x s x_s xs 和 driving image x d x_d xd:
latent motion representation 也是整个过程的第一步:
学习一个 latent code z s → d Z ∈ R N z_{s \to d}~ Z \in R^N zs→d Z∈RN 来表达从 x s x_s xs 到 x d x_d xd 的 motion transformation,由于这两个图片都有不确定性,直接学习 z s → d z_{s \to d} zs→d 的话比较难,因为需要模型去捕捉非常复杂的运动。所以,在此处假设有一个 reference image x r x_r xr,motion transfer 的过程被建模为 x s → x r → x d x_s \to x_r \to x_d xs→xr→xd,而不是直接学习 z s → d z_{s \to d} zs→d。因此,将 z s → d z_{s \to d} zs→d 作为 latent space 的 target point,起始点为 z s → r z_{s \to r} zs→r,线性路径为 w r → d w_{r \to d} wr→d:
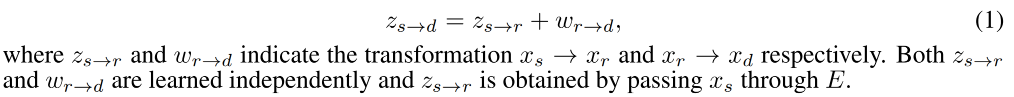
reference image 如何生成:
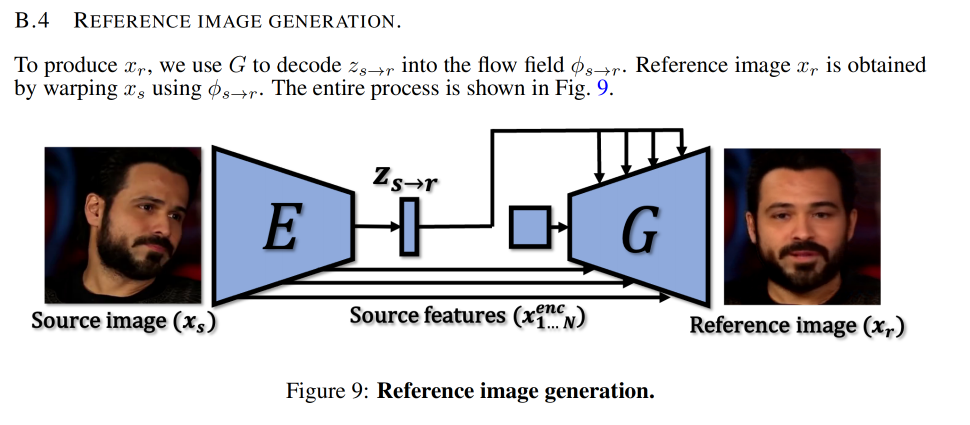
x r x_r xr 到底表达的是什么:
- 如图 5 所示, x r x_r xr 表达的是 x s x_s xs 的 canonical pose,

如何学习 w r → d w_{r \to d} wr→d:LMD(Linear Motion Decomposition)
-
首先,学习一组 motion directions D m = { d 1 , . . . , d M } D_m=\{d_1, ... , d_M\} Dm={d1,...,dM} 来在 latent space 表达任意的 path,且限制 D m D_m Dm 作为正交基,其中每个向量都表示运动方向 d i d_i di,且其中每两个向量两两之间都是正交的
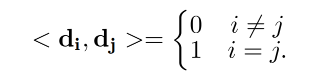
-
然后,将 D m D_m Dm 中的每个基都和向量 A r → d = { a 1 , . . . , a M } A_{r \to d}=\{a_1, ..., a_M\} Ar→d={a1,...,aM} 进行结合, a i a_i ai 表示 d i d_i di 的模值,所以在 latent 空间中的每一个 linear path 都可以使用如下的线性组合来表示,且每个 d i d_i di 都表示一个基, a i a_i ai 表示步长。 A r → d A_{r \to d} Ar→d 是通过映射 z d → r z_{d \to r} zd→r 得到的,是 x d x_d xd 经过 E 后的输出。
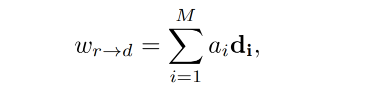
-
最后,latent motion representation 如下, D m D_m Dm 中的向量都是可学习的
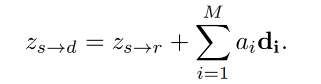
D m D_m Dm 中的方向表示什么:表示点头(d8)、眨眼(d6)、面部表情(d19、d7)等


2.2 latent code driven image animation
得到了 z s → d z_{s \to d} zs→d 后,就是第二步了,即使用 G 来解码出 flow filed ϕ s → d \phi_{s \to d} ϕs→d 并 warp x s x_s xs
G 包含两部分,且为了学习多尺度特征, G 使用了一个残差结构:
-
flow field 生成器 G f G_f Gf:包含 N 个 model 来不同 layer 的生成金字塔的 flow fields ϕ s → d = { ϕ i } 1 N \phi_{s \to d}=\{\phi_i\}_1^N ϕs→d={ϕi}1N。从 E 中会获得多尺度 source features x s e n c = { x i e n c } 1 N x_s^{enc}=\{x_i^{enc}\}_1^N xsenc={xienc}1N,然后会在 G f G_f Gf 中进行 warp
-
如果直接基于 ϕ s → d \phi_{s \to d} ϕs→d 来 warp source feature,不能很充分且精确的来重建 driving image,因为在一些位置上会有遮挡,为了更好的预测这些遮挡位置的像素,需要对 warped feature map 进行修复,所以,在 G f G_f Gf 中也根据 { ϕ i } 1 N \{\phi_i\}_1^N {ϕi}1N 预测了 multi-scale mask { m i } 1 N \{m_i\}_1^N {mi}1N,可以 mask 出需要修复的区域
-
每个残差模型中都有:
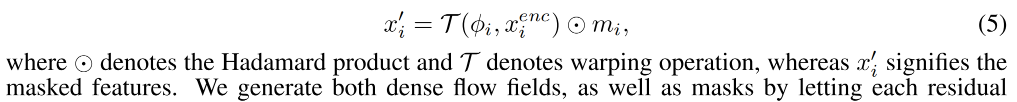 -
所以,输出共三个通道,前两个通道是 ϕ i \phi_i ϕi,最后一个通道是 m i m_i mi
-
-
refinement network G r G_r Gr:基于上面得到的修复后的 feature map f ( x i ′ ) f(x_i') f(xi′) 和上一个 G r G_r Gr 得到的上采样后的 image g ( x i − 1 ) g(x_{i-1}) g(xi−1),可以得到每个模块的 RGB 图像
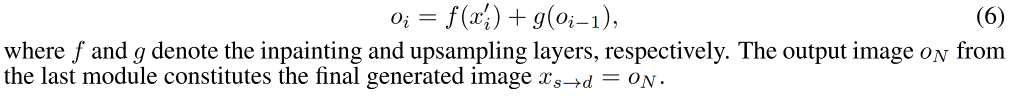
2.3 学习方式
作者使用 self-supervised 的方法来重建 x d x_d xd,使用了 3 个 loss:
-
reconstruction loss:重建 loss,用于最小化 x d x_d xd 和 x s → d x_{s \to d} xs→d 的 pixel-wise L 1 L_1 L1 距离
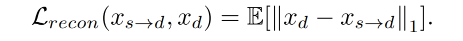
-
perceptual loss:感知 loss,用于最小化感知特征 loss,使用的是 VGG19-based L v g g L_{vgg} Lvgg,衡量 real 和 generated images 的多尺度的 feature map 的距离,尺度分别为 256/128/64/32
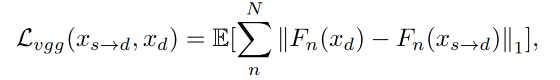
-
adversarial loss:对抗 loss,为了生成更真实的结果,作者在 x s → d x_{s \to d} xs→d 上使用了不饱和的对抗 loss L a d v L_{adv} Ladv
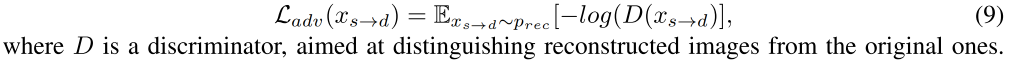
整体 loss:
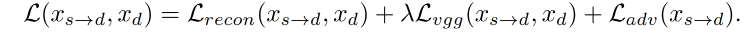
2.4 推理
在推理阶段,给定一个 driving video 序列 V d = x t 1 T V_d={x_t}_1^T Vd=xt1T,目标是将 V d V_d Vd 的运动转移到 x s x_s xs 上,生成一个新的 video V d → s = { x t → s } 1 T V_{d \to s}=\{x_{t \to s}\}_1^T Vd→s={xt→s}1T
如果 V d V_d Vd 和 x s x_s xs 来自同一个 video,则可以使用 absolute transfer 的方式来重建每帧,和训练的过程一样:
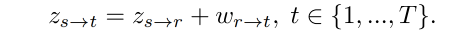
如果 V d V_d Vd 和 x s x_s xs 来自不同的 video,这个时候两个图片中的人物的外貌特征、动作、表情都是不同的,这个时候就要使用 relative transfer 来估计
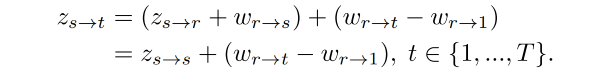
三、效果
3.1 数据集
- VoxCeleb
- TaichiHD
- TED-talk
裁剪到分辨率大小为 256x256


3.2 训练细节
- 4 个 16G NVIDIA V100 GPUs
- batch size 为 32,每张卡上 8 张图
- 学习率:0.002
- 优化器:Adam
- latent code 维度, D m D_m Dm 中的方向 都是 512
- l a m b d a lambda lambda:10
- 训练时间: 150 小时
3.3 评估
3.4 定性效果

3.5 定量效果
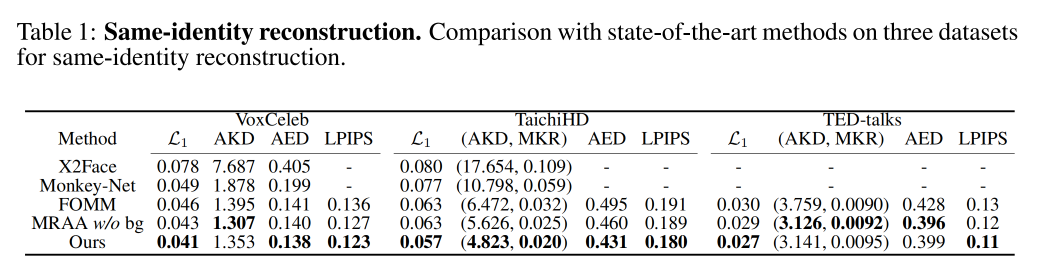
同一人物的重建:
跨视频的生成

User study:

3.6 消融实验
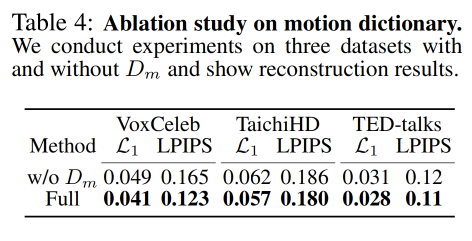
1、motion dictionary D m D_m Dm 是否有效:
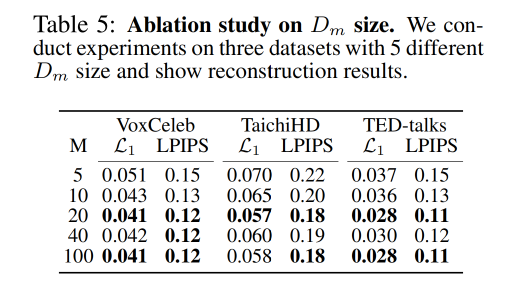
2、 D m D_m Dm 需要多少个方向:20 个最优
3.7 失败示例
- Taichi 中,身体遮挡重合(如胳膊、腿等)的部分无法很好的 transfer
- 在 TED-talks,手部动作难以 transfer