一个简单基础模板:
bert导入,分词,编码
from transformers import BertConfig, BertTokenizer, BertModel
import torch
from transformers import BertModel, BertTokenizer
# 指定模型文件夹路径(包含 pytorch_model.bin)
model_path = "/remote-home/cs_tcci_huangyuqian/code/bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertModel.from_pretrained(model_path)
text = "Hello, how are you doing?"
# text='I have a good time, thank you.'
# print(tokenizer.tokenize(text))
# 使用分词器将文本转换为模型的输入格式
input_ids = tokenizer.encode(text, add_special_tokens=True, return_tensors="pt")
# 使用BERT模型进行文本编码
with torch.no_grad():
outputs = model(input_ids)
# 输出结果包含了文本的编码表示
# outputs 是一个包含两个张量的元组,第一个张量是编码的输出,第二个张量是注意力掩码
encoded_text = outputs[0]
# model_path = "/remote-home/cs_tcci_huangyuqian/code/bert-base-uncased"
# config = BertConfig.from_json_file(f"{model_path}/config.json")
# tokenizer = BertTokenizer.from_pretrained(f"{model_path}/vocab.txt")
# text='I have a good time, thank you.'
# print(tokenizer.tokenize(text))
bert处理情感分类
data.txt文件
i hate you 0
i love you 1
i really like you 1
i don't like this 0
一个简单的例子,理解如何使用bert做情感分类问题。
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optimizer
from torch.utils.data import Dataset,DataLoader
from transformers import BertForSequenceClassification, BertTokenizer, BertConfig,AdamW
import torch.nn.functional as F
from torch.utils.data import Dataset
import re
from transformers import AutoTokenizer
# tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
from transformers import BertTokenizer, BertForQuestionAnswering
import torch
model_name = "/remote-home/cs_tcci_huangyuqian/code/bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
config = BertConfig.from_pretrained(model_name, num_labels=2)
model_class = BertForSequenceClassification.from_pretrained(model_name, config=config)
class Mydataset(Dataset):
def __init__(self):
f = open('/remote-home/cs_tcci_huangyuqian/code/data.txt')
x = f.readlines()
x = [re.sub(r'\n', '', i) for i in x]
x = [i.split() for i in x]
lables = []
sentences = []
for i in x:
lables.append(int(i[-1]))
sentences.append(' '.join(i[:-1]))
self.lables=lables
self.sentences=sentences
def __len__(self):
return len(self.lables)
def __getitem__(self, item):
return self.sentences[item],self.lables[item]
mydataset=Mydataset()
dataloder=DataLoader(dataset=mydataset,batch_size=1)
#查看mydataset的方法如下:
# # 创建 Mydataset 对象
# my_dataset = Mydataset()
#
# # 创建 DataLoader 对象
# batch_size = 32 # 设置批次大小
# data_loader = DataLoader(my_dataset, batch_size=batch_size, shuffle=True)
#
# # 遍历 DataLoader 以查看批次数据
# for batch in data_loader:
# sentences, labels = batch
# # 在这里你可以查看每个批次的 sentences 和 labels
# print("Sentences:", sentences)
# print("Labels:", labels)
# break
class ClassEmotion(nn.Module):
def __init__(self, model):
super().__init__()
self.bert_class = model
def forward(self, input):
out = self.bert_class(**input)
return out
classifier = ClassEmotion(model_class)
# 设置训练参数
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
classifier.to(device)
optimizer = AdamW(classifier.parameters(), lr=2e-5)
criterion = nn.CrossEntropyLoss()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
for epoch in range(20):
total_loss = 0
for batch in dataloder:
lable=batch[1]
input=tokenizer.encode_plus(" ".join(batch[0]),max_length=10,padding='max_length',return_tensors='pt',truncation=True)
optimizer.zero_grad()
logits = classifier(input)
loss = criterion(logits[0],lable)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch + 1}, Loss: {total_loss}")
x='you love apple'
x_input=tokenizer.encode_plus(x,max_length=10,padding='max_length',return_tensors='pt',truncation=True)
print(torch.argmax(classifier(x_input)[0], dim=1).item())
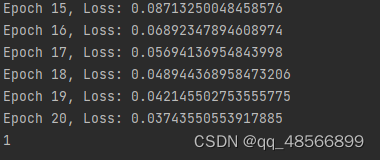
结果判断正确
bert处理问答任务
import json
from transformers import BertTokenizer, BertForQuestionAnswering
import torch
from transformers import AdamW, BertTokenizerFast, BertForQuestionAnswering
from transformers import BertConfig
# 指定预训练BERT模型的名称或文件夹路径(中文BERT模型的名称为"bert-base-chinese")
model_name = "/remote-home/cs_tcci_huangyuqian/code/bert-base-uncased"
# config = BertConfig.from_json_file("/remote-home/cs_tcci_huangyuqian/code/bert4keras-master/bert-base-chinese/config.json")
# tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForQuestionAnswering.from_pretrained(model_name)
chi_tokenizer=BertTokenizer.from_pretrained(model_name)
question = 'what is the answer of the question'
paragraph = 'the answer of question is 42'
inputs = chi_tokenizer(question, paragraph, return_tensors='pt')
output = model(**inputs, start_positions=torch.tensor([0]), end_positions=torch.tensor([16]))
print("loss: ", output.loss)
optimizer = AdamW(model.parameters(), lr=1e-4)
output.loss.backward()
optimizer.step()
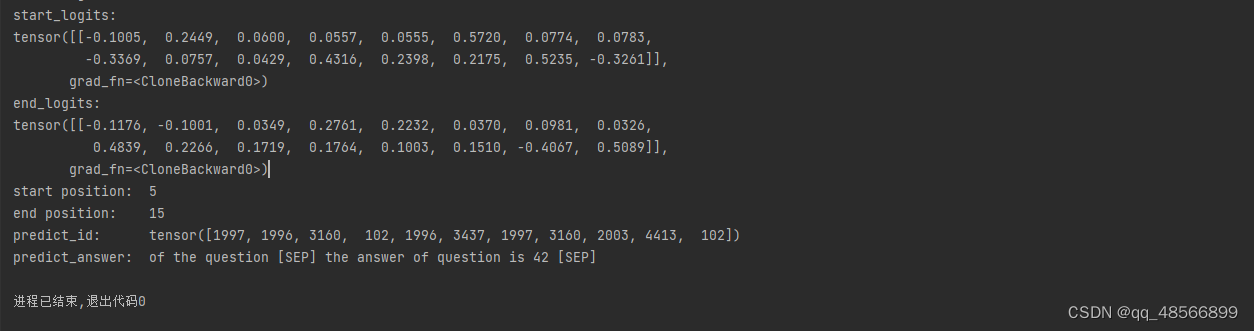
print("start_logits: ")
print(output.start_logits)
print("end_logits: ")
print(output.end_logits)
start = torch.argmax(output.start_logits) # 返回dim维度上张量最大值的索引。
end = torch.argmax(output.end_logits)
print("start position: ", start.item()) # 一个元素张量可以用x.item()得到元素值
print("end position: ", end.item())
# 获取预测的start和end的token的id
predict_id = inputs['input_ids'][0][ start:end + 1]
print("predict_id: ", predict_id)
# 根据id解码出原文
predict_answer = chi_tokenizer.decode(predict_id)
print("predict_answer: ", predict_answer)
import json
from transformers import BertTokenizer, BertForQuestionAnswering
import torch
from transformers import AdamW, BertTokenizerFast, BertForQuestionAnswering
from transformers import BertConfig
# 指定预训练BERT模型的名称或文件夹路径(中文BERT模型的名称为"bert-base-chinese")
model_name = "/remote-home/cs_tcci_huangyuqian/code/bert-base-uncased"
# config = BertConfig.from_json_file("/remote-home/cs_tcci_huangyuqian/code/bert4keras-master/bert-base-chinese/config.json")
# tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForQuestionAnswering.from_pretrained(model_name)
tokenizer=BertTokenizer.from_pretrained(model_name)
question = "How many parameters does BERT-large have?"
answer_text = "BERT-large is really big... it has 24-layers and an embedding size of 1,024, for a total of 340M parameters! Altogether it is 1.34GB, so expect it to take a couple minutes to download to your Colab instance."
# # Apply the tokenizer to the input text, treating them as a text-pair.
# # 对输入文本应用标记器(tokenizer),将它们视为文本对。
# input_ids = tokenizer.encode(question, answer_text)
#
# # print('The input has a total of {:} tokens.'.format(len(input_ids)))
# # BERT only needs the token IDs, but for the purpose of inspecting the
# # tokenizer's behavior, let's also get the token strings and display them.
# # BERT只需要tokens 的id,但是为了检查token生成器的行为,让我们也获取token的字符串并显示它们。
# tokens = tokenizer.convert_ids_to_tokens(input_ids) # 转换为字符
#
# # For each token and its id...
#
# # 在input_ids中搜索`[SEP]`标记的第一个实例。
# sep_index = input_ids.index(tokenizer.sep_token_id) # 在sep出现的位置
#
# # 段A标记的数量包括[SEP]标记本身。
# num_seg_a = sep_index + 1 # sep后面的位置
#
# # The remainder are segment B.
# num_seg_b = len(input_ids) - num_seg_a # 剩余的是B
#
# # Construct the list of 0s and 1s.
# segment_ids = [0]*num_seg_a + [1]*num_seg_b
#
# # There should be a segment_id for every input token.
# assert len(segment_ids) == len(input_ids) # 每个输入令牌都应该有一个segment_id。
# # 在模型中运行我们的示例。
# output = model(torch.tensor([input_ids]), # The tokens representing our input text.
# token_type_ids=torch.tensor([segment_ids])) # The segment IDs to differentiate question from answer_text
#
# # Find the tokens with the highest `start` and `end` scores.
# answer_start = torch.argmax(output.start_logits)
# answer_end = torch.argmax(output.end_logits)
#
# # Combine the tokens in the answer and print it out.
# answer = ' '.join(tokens[answer_start:answer_end+1])
#
# print('Answer: "' + answer + '"')
def answer_question(question, answer_text):
'''
Takes a `question` string and an `answer_text` string (which contains the
answer), and identifies the words within the `answer_text` that are the
answer. Prints them out.
设定`question`和`answer_text`(包含答案)字符串,定义单词的答案
'''
# ======== Tokenize ========
# Apply the tokenizer to the input text, treating them as a text-pair.
input_ids = tokenizer.encode(question, answer_text)
# Report how long the input sequence is.
print('Query has {:,} tokens.\n'.format(len(input_ids)))
# ======== Set Segment IDs ========
# Search the input_ids for the first instance of the `[SEP]` token.
sep_index = input_ids.index(tokenizer.sep_token_id)
# The number of segment A tokens includes the [SEP] token istelf.
num_seg_a = sep_index + 1
# The remainder are segment B.
num_seg_b = len(input_ids) - num_seg_a
# Construct the list of 0s and 1s.
segment_ids = [0] * num_seg_a + [1] * num_seg_b
# There should be a segment_id for every input token.
assert len(segment_ids) == len(input_ids)
# ======== Evaluate ========
# Run our example question through the model.
output = model(torch.tensor([input_ids]), # The tokens representing our input text.
token_type_ids=torch.tensor(
[segment_ids])) # The segment IDs to differentiate question from answer_text
start_scores, end_scores = output.start_logits, output.end_logits
# ======== Reconstruct Answer ========
# Find the tokens with the highest `start` and `end` scores.
answer_start = torch.argmax(start_scores)
answer_end = torch.argmax(end_scores)
# Get the string versions of the input tokens.
tokens = tokenizer.convert_ids_to_tokens(input_ids)
# Start with the first token.
answer = tokens[answer_start]
# Select the remaining answer tokens and join them with whitespace.
for i in range(answer_start + 1, answer_end + 1):
# If it's a subword token, then recombine it with the previous token.
if tokens[i][0:2] == '##':
answer += tokens[i][2:]
# Otherwise, add a space then the token.
else:
answer += ' ' + tokens[i]
print('Answer: "' + answer + '"')
import textwrap
# Wrap text to 80 characters.
wrapper = textwrap.TextWrapper(width=80)
bert_abstract = "We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models (Peters et al., 2018a; Radford et al., 2018), BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial taskspecific architecture modifications. BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement)."
print(wrapper.fill(bert_abstract))
question = "What does the 'B' in BERT stand for?"
answer_question(question, bert_abstract)
例子2:
model_name = 'bert-base-chinese'
# 通过词典导入分词器
tokenizer = BertTokenizer.from_pretrained(model_name)
# 导入配置文件
model_config = BertConfig.from_pretrained(model_name)
# 最终有两个输出,初始位置和结束位置
model_config.num_labels = 2
# 根据bert的 model_config 新建 BertForQuestionAnsering
model = BertForQuestionAnswering(model_config)
model.eval()
question, text = '里昂是谁?', '里昂是一个杀手。'
sen_code = tokenizer.encode_plus(question, text)
tokens_tensor = torch.tensor([sen_code['input_ids']])
segments_tensors = torch.tensor([sen_code['token_type_ids']]) # 区分两个句子的编码(上句全为0,下句全为1)
start_pos, end_pos = model(tokens_tensor, token_type_ids = segments_tensors)
# 进行逆编码,得到原始的token
all_tokens = tokenizer.convert_ids_to_tokens(sen_code['input_ids'])
print(all_tokens) # ['[CLS]', '里', '昂', '是', '谁', '[SEP]', '里', '昂', '是', '一', '个', '杀', '手', '[SEP]']
# 对输出的答案进行解码的过程
answer = ' '.join(all_tokens[torch.argmax(start_pos) : torch.argmax(end_pos) + 1])
# 每次执行的结果不一致,这里因为没有经过微调,所以效果不是很好,输出结果不佳,下面的输出是其中的一种。
print(answer) # 一 个 杀 手






![[sqoop]hive导入mysql,其中mysql的列存在默认值列](https://img-blog.csdnimg.cn/7b88c454df43430999a49c43984ea63e.png)