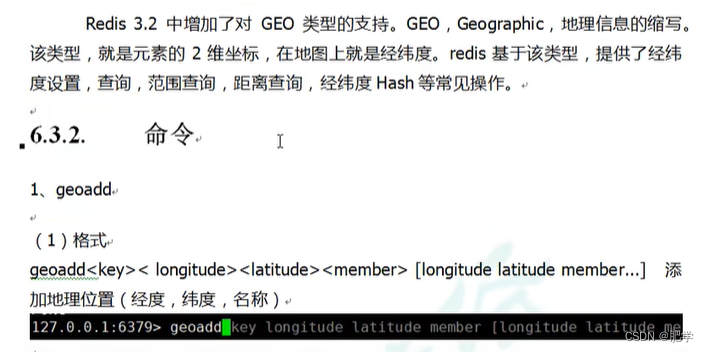
当我们走出校园,步入社会,必须得找工作,那么作为it小白你必须拥有过硬的基础应用知识,才能慢慢的适应工作的节奏,以下内容则都是基础中的基础,需要全部进行掌握,因为这里可能有你面试时需要回答的面试题。
注意:修仙秘籍是一个专栏,请按照顺序进行学习
八:IO的方式
1:BIO同步阻塞(JDK1.4之前)
线程的使用:一个连接,一个线程
建立网络连接时,需要在服务器端开启ServerSocket,完成之后在客户端开启Socket,然后在进行客户端/服务器之间的通信,在通常的情况下服务器会建立一堆的线程去等待请求,当客户端去请求服务端时,发出请求,询问服务端是否有线程响应,如果没有的话会继续等待或者是遭到服务端的拒绝,如果有的情况下,客户端的线程会等到请求结束后再继续执行。
2:NIO同步非阻塞(JDK1.4之后)
线程的使用:一个请求,一个线程
这种方式则是再BIO的基础上发展而来,主要解决了BIO的高并发问题,在使用BIO方式时,如果有不同的客户端对同一个服务器同时请求或者是客户端对不同的服务端同时进行请求时,遇到这种情况下,那么必须得通过多线程来解决这种问题了,通俗的讲就是对每个客户端请求都分配一个线程来响应客户端的请求。如果同时间的客户端请求不多,服务器一般情况下可以去处理各种的请求,但是如果同时访问服务器端的请求很多时,那么服务器会分配更多的线程去处理请求,线程会占据着内存,如果超过服务端的内存峰值,就会导致服务器瘫痪。
而NIO方式则是对有效的请求分配线程,对于无效的连接则不会分配线程去处理,极大的减少了线程的数量。同时,BIO与NIO一个比较重要的不同,是我们使用BIO的时候往往会引入多线程,每个连接一个单独的线程;而NIO则是使用单线程或者只使用少量的多线程,多个连接共用一个线程。
3:AIO异步非阻塞(JDK1.7之后)
线程的使用:一个有效的请求,一个线程
之前的两种方式都是都是在同步进行,而这种方式则是一个异步的方式,通俗的讲就是把任务分配给下属OS去干,不需要本人的进行亲历亲为,等下属完成后在启动线程去处理。进行读写操作时会直接调用API中的read和writer方法。对于读操作而言,当有流可读取时,操作系统会将可读的流传入read方法的缓冲区,并通知应用程序;对于写操作而言,当操作系统将write方法传递的流写入完毕时,操作系统主动通知应用程序。 即可以理解为,read/write方法都是异步的,完成后会主动调用回调函数。
九:反射
反射:指在程序运行中分析类的一种能力。
通俗的讲就是从一个类通过class、constructor、field、method四个方法获取一个另外一个类的各个组成部分。
Java 的动态就体现在这。通过反射我们可以实现动态装配,降低代码的耦合度;动态代理等。反射的过度使用会严重消耗系统资源
关于反射之前我的一篇文章有过仔细的讲解,感兴趣的可以查看一下Java反射讲解
十:Java序列化
Java序列化是指把Java对象转换为字节序列的过程;而Java反序列化是指把字节序列恢复为Java对象的过程。
为什么要进行序列化?
你知道微信聊天时,图片是怎么发送上去的吗?对,就是序列化,图片.文本.视频.音频等文件都是通过序列化方法进行传递,实际上就是把文件变成二进制。发送方发送内容,就会把内容序列化传递给接收方,接收方则就是会把收到的二进制进行反序列化,二进制还原则就是将数字归还成文件。
一般程序在运行时,产生对象,这些对象随着程序的停止而消失,但我们想将某些对象保存下来,这时,我们就可以通过序列化将对象保存在磁盘,需要使用的时候通过反序列化获取到。
对象序列化的最主要目的就是传递和保存对象,保存对象的完整性和可传递性。
譬如通过网络传输或者把一个对象保存成本地一个文件的时候,需要使用序列化。
关于序列化,我这里有一个非常有趣的案例,感兴趣可以查看一下案例:通过序列化的方式实现图片的上传

十一:基本数据类型和引用数据类型
基本数据类型: 整型、浮点型、字符型、布尔型,分别为byte、short、int、long、float、double、char、boolean。这些类型直接存储数据的值。
而引用数据类型则是指非基本数据类型,它们包括类、接口、数组等。引用数据类型的变量存储的是对象的引用,而不是对象本身。
两种数据类型的区别:存储位置不同
基本数据类型:属性名称和属性值是直接并定义在栈中,定义完之后属性不会发生改变。
引用基本类型:存储在栈中的内容是对象的地址,实际的对象是放在堆内存中。使用引用数据类型时,它会先到栈中去找对象的地址,然后再到堆内存中去调用对象。
比较
在前面介绍equals时,已经介绍了不同类型的值进行比较所需要使用的方法,基本的数据类型使用的是=(等号),而引用数据类型则是使用equals方法,去通过比较两个对象的地址值,去判断是否相等。
十二:克隆
通俗易懂就是给一个对象创建一个副本,不通过构造函数去克隆出一个与原始对象相同的新对象,克隆分为浅拷贝和深拷贝,通过克隆可以更好的满足在开发时的需要,在不修改原有类的基础上开发新的内容。
浅拷贝
浅拷贝:只能克隆源对象的基本数据类型,而不能克隆引用数据类型。
代码讲解:
通过代码可以这样的理解,克隆对象会将源对象的属性全部都克隆,包括属性名称,属性值,基本数据类型,和引用数据类型。通过几个地址值就可以判断出来。
但是,浅拷贝并不是完整的进行克隆,也有一部分并没有进行克隆那就是引用数据类型。前面内容也基础的讲解了两种数据类型的区别,浅拷贝,会将栈中的基本数据类型再拷贝一份,也就是说同一个属性名,但是这两个属性指的并非栈中同一个属性,而是不同的属性。但是,引用数据类型克隆,会将栈中的地址值克隆一份,但是引用数据类型的实际对象是放在堆中,所以说,克隆并不会克隆引用数据类型。两个属性对应的是同一个对象。
代码:demo2与clone完成后,修改基本数据,会发现修改的是demo2的数据clone中的数据并没有发生改变,这里可以看出来浅拷贝会克隆基本的数据类型。当修改引用数据demo1中的数据后,结果发现demo2与clone显示出来的数据是一致的,这说明引用数据指的是同一个对象。同样,这也表明浅拷贝并不能克隆引用数据类型。
案例实现
创建两个类
类一:作为引用数据类型的类
public class Clone_Demo1 {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Clone_Demo1{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
类二:被克隆的类
public class Clone_demo2 implements Cloneable{
private int id;
private String describe;
private Clone_Demo1 demo1;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getDescribe() {
return describe;
}
public void setDescribe(String describe) {
this.describe = describe;
}
public Clone_Demo1 getDemo1() {
return demo1;
}
public void setDemo1(Clone_Demo1 demo1) {
this.demo1 = demo1;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
@Override
public String toString() {
return "Clone_demo2{" +
"id=" + id +
", describe='" + describe + '\'' +
", demo1=" + demo1 +
'}';
}
}
测试类:
import com.sun.security.jgss.GSSUtil;
public class Clone_test {
public static void main(String[] args) {
Clone_Demo1 demo1 = new Clone_Demo1();
demo1.setId(1);
demo1.setName("不想睡醒的梦");
Clone_demo2 demo2 = new Clone_demo2();
demo2.setId(2);
demo2.setDescribe("青岛");
demo2.setDemo1(demo1);
try{
//克隆
Clone_demo2 clone_demo2 = (Clone_demo2)demo2.clone();
//可以通过地址值判断克隆的对象是新产生的对象
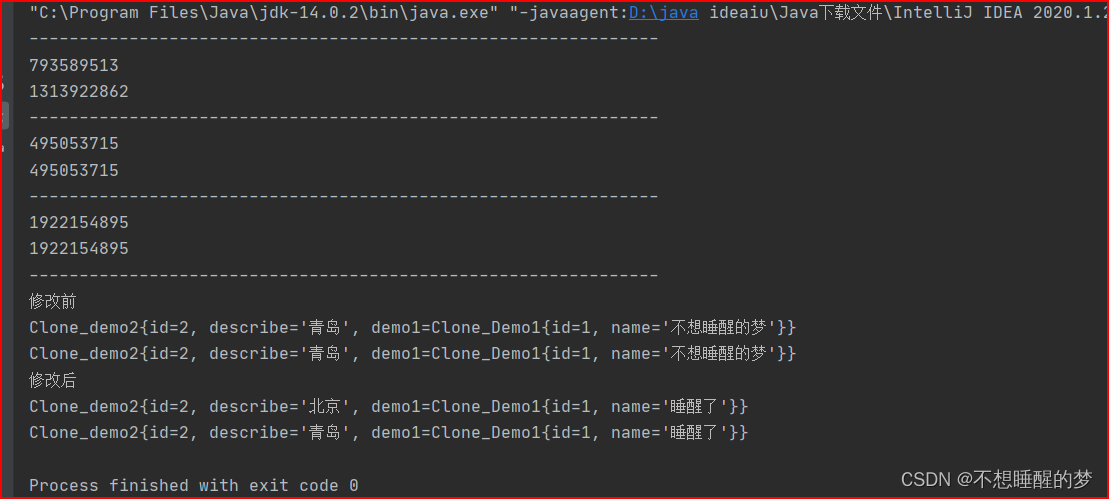
System.out.println("---------------------------------------------------------------");
System.out.println(System.identityHashCode(demo2));
System.out.println(System.identityHashCode(clone_demo2));
//判断基本数据类型内容,是否克隆成功,地址值一致则说明克隆成功
System.out.println("---------------------------------------------------------------");
System.out.println(System.identityHashCode(demo2.getId()));
System.out.println(System.identityHashCode(clone_demo2.getId()));
//判断二级对象内容
System.out.println("---------------------------------------------------------------");
System.out.println(System.identityHashCode(demo2.getDemo1().getName()));
System.out.println(System.identityHashCode(clone_demo2.getDemo1().getName()));
System.out.println("---------------------------------------------------------------");
//修改前
System.out.println("修改前");
System.out.println(demo2.toString());
System.out.println(clone_demo2.toString());
demo2.setDescribe("北京");
demo1.setName("睡醒了");
System.out.println("修改后");
System.out.println(demo2.toString());
System.out.println(clone_demo2.toString());
}
catch (Exception e){
}
}
}
输出结果:
深拷贝
注意:深拷贝则是修改重写的clone方法,并在被引用的类添加对克隆的继承
代码:
被引用的类
public class Clone_Demo1 implements Cloneable {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
@Override
public String toString() {
return "Clone_Demo1{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
被克隆的类
注意:修改原来重写的clone方法,添加对引用类的克隆
public class Clone_demo2 implements Cloneable{
private int id;
private String describe;
private Clone_Demo1 demo1;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getDescribe() {
return describe;
}
public void setDescribe(String describe) {
this.describe = describe;
}
public Clone_Demo1 getDemo1() {
return demo1;
}
public void setDemo1(Clone_Demo1 demo1) {
this.demo1 = demo1;
}
@Override
public Object clone() throws CloneNotSupportedException {
Clone_demo2 s = (Clone_demo2)super.clone();
s.demo1 = (Clone_Demo1) this.getDemo1().clone();
return s;
}
@Override
public String toString() {
return "Clone_demo2{" +
"id=" + id +
", describe='" + describe + '\'' +
", demo1=" + demo1 +
'}';
}
}
十三:throw与throws
throw:使用的方法一般在放在函数内,表示抛出了具体的异常,由方法体内的语句块进行处理,指一定抛出了异常。
throws:使用的·方法一般放在函数体外,表示抛出了异常,但是并非是具体的异常可能是某个异常的父类。
修饰符 返回值类型 方法名(参数列表) [throws 异常的类型] {
if (判断条件) {
throw new 异常对象("异常的原因");
}
}十四:final.finally和finalize的区别
final: 可以修饰类、变量、方法,修饰类表示该类不能被继承、修饰方法表示该方法不能被重写、修饰变量表示该变量是一个常量不能被重新赋值;
小结:
- final修饰的成员变量,必须在声明的同时赋值,一旦创建不可修改(常量);
- final修饰的方法,不能被子类重写;
- final类中的方法默认是final的,该类不能被继承;
- private类型的方法默认是final的;
finlly子句:与try catch语句连用,不管try catch 语句是否执行顺利,finlly语句都会被执行。
finalize:
一般情况下不需要我们实现finalize,当对象被回收的时候需要释放一些资源,比如socket链接,在对象初始化时创建,整个生命周期内有效,那么需要实现finalize方法,关闭这个链接。
但是当调用finalize方法后,并不意味着gc会立即回收该对象,所以有可能真正调用的时候,对象又不需要回收了,然后到了真正要回收的时候,因为之前调用过一次,这次又不会调用了,产生问题。所以,不推荐使用finalize方法在现代的Java版本中,更推荐使用其他机制来进行资源清理,如使用try-with-resources语句块来自动关闭资源。
十五:try....catch
public class trycatch {
public static void main(String[] args) {
// TODO Auto-generated method stub
try { //写尝试要执行的代码
int a =10 / 0;
System.out.println("a:"+a);
}catch (Exception e) { //写出现问题后的解决方案
System.out.println("出现异常错误");
}finally {
System.out.println("这yi行出现吗?");
}
System.out.println("这二行出现吗?");
}
}
--------------------------------------
输出结果:
出现异常错误
这yi行出现吗?
这er行出现吗?方式一的特点:
1:“这二行出现吗?” 这一行的输出 说明:当异常问题被解决后 会继续执行下面代码
2:finally {} 代码可以有,同样也可以没有区别在于:即使 try catch 中有没有 return finally中的语句依然被执行通过代码进行解释:
代码一:
public class trycatch {
public static void main(String[] args) {
// TODO Auto-generated method stub
try { //写尝试要执行的代码
int a =10 / 0;
System.out.println("a:"+a);
}catch (Exception e) { //写出现问题后的解决方案
System.out.println("出现异常错误");
return;
}finally {
System.out.println("这yi行出现吗?");
}
System.out.println("这二行出现吗?");
}
}
-------------------------------------------------
输出结果:
出现异常错误
这yi行出现吗?
代码二:
public class trycatch {
public static void main(String[] args) {
// TODO Auto-generated method stub
try { //写尝试要执行的代码
int a =10 /10;
System.out.println("a:"+a);
return;
}catch (Exception e) { //写出现问题后的解决方案
System.out.println("出现异常错误");
}finally {
System.out.println("这yi行出现吗?");
}
System.out.println("这er行出现吗?");
}
}
--------------------------
输出结果:
a:1
这yi行出现吗?
以上代码说明return 可以决定着语句结束后是否向下执行,当有finally语句后会执行finally语句内容但不会执行方式一语句之外的代码。解释:return 是结束语句的用语,当出现异常时会执行异常语句,如果判定没有异常就是执行try中的输出语句后,之后return ,说明代码结束,之后再执行finally语句内容。
方法一执行流程:
先执行try{}语句的内容,看是否会出现问题(异常)
没有:直接执行finally语句的内容
有:直接跳转到catch{}语句中开始执行,完成之后再执行finally{}语句中的内容。


![[UUCTF 2022 新生赛]ezpop - 反序列化(字符串逃逸)【***】](https://img-blog.csdnimg.cn/359f4593e22e4f1eb296ff45741ac968.png)