1. 各个激活函数的优缺点?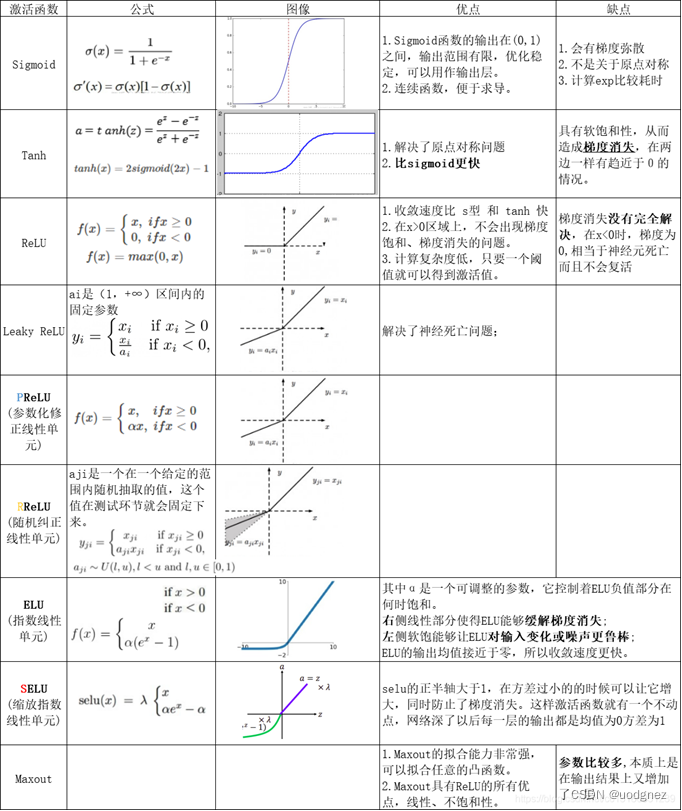
2. 为什么ReLU常用于神经网络的激活函数?
- 在前向传播和反向传播过程中,ReLU相比于Sigmoid等激活函数计算量小;
- 避免梯度消失问题。对于深层网络,Sigmoid函数反向传播时,很容易就会出现梯度消失问题(在Sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练;
- 可以缓解过拟合问题的发生。ReLU会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生;
- 相比Sigmoid函数,ReLU函数有助于随机梯度下降方法收敛。
3. 神经网络为什么会出现梯度弥散(gradient vanish)问题,梯度爆炸呢?
梯度消失:梯度趋近于0,网络权重无法更新或更新的很微小,网络训练再久也不会有效果。
梯度爆炸:梯度呈指数级增长,变得非常大,然后导致网络权重大幅更新,使网络变得不稳定。
Sigmoid导数的取值在 0~0.25 之间,而我们初始化的网络权值
w
w
w 通常都小于 1,因此,当层数增多时,小于 0 的值不断相乘,最后就导致了梯度消失的情况出现。同理,梯度爆炸的问题也就很明显了,就是当权值
w
w
w 过大时,导致
∣
σ
′
(
z
)
w
∣
>
1
|\sigma'(z) w|>1
∣σ′(z)w∣>1,最后大于1的值不断相乘,就会产生梯度爆炸。
梯度消失和梯度爆炸本质上是一样的,都是因为网络层数太深而引发的梯度反向传播中的连乘效应。
4. 梯度消失和梯度爆炸的解决方案?梯度爆炸引发的问题?

5. BN(Batch Normalization)层如何实现?作用?
实现过程:计算训练阶段 mini_batch 数量激活函数前结果的均值和方差,然后对其进行归一化,最后对其进行缩放和平移。
作用:
- List item