一、Spark WordCount运行原理

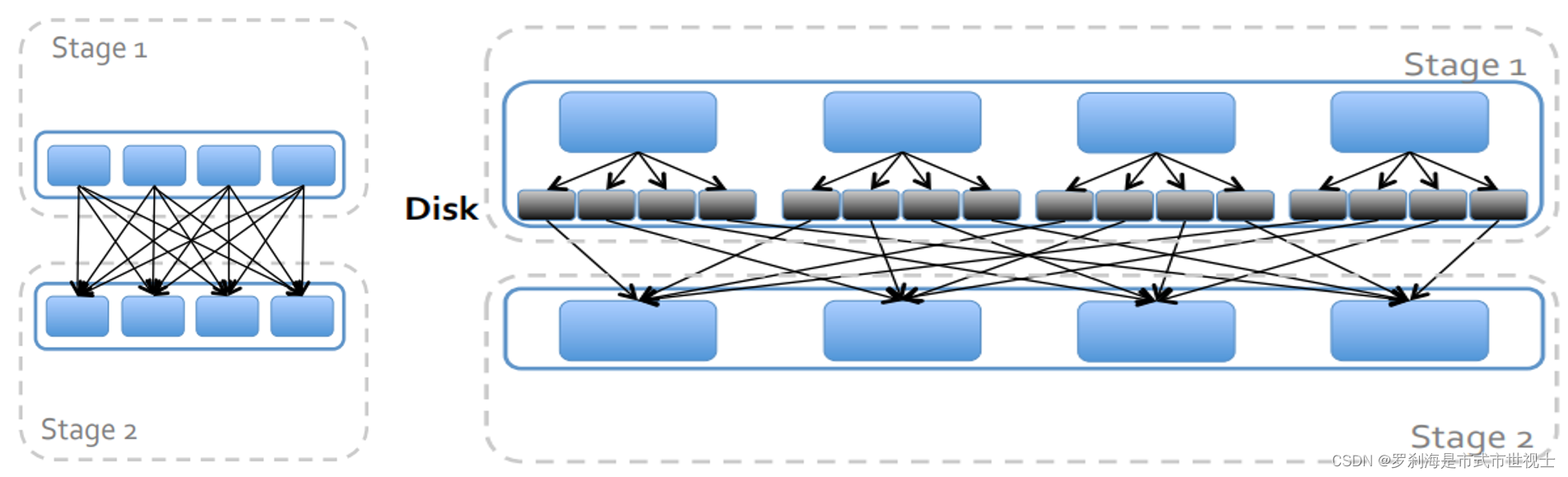
二、划分Stage
数据本地化
移动计算,而不是移动数据
保证一个Stage内不会发生数据移动
三、Spark Shuffle过程
在分区之间重新分配数据
父RDD中同一分区中的数据按照算子要求重新进入RDD的不同分区中
中间结果写入磁盘
有子RDD拉取数据,而不是由父RDD推送
默认情况下,shuffle不会改变分区数量
四、RDD的依赖关系
Lineage:血统、依赖
RDD最重要的特征之一,保存了RDD的依赖关系
RDD实现了基于Lineage的容错机制
依赖关系
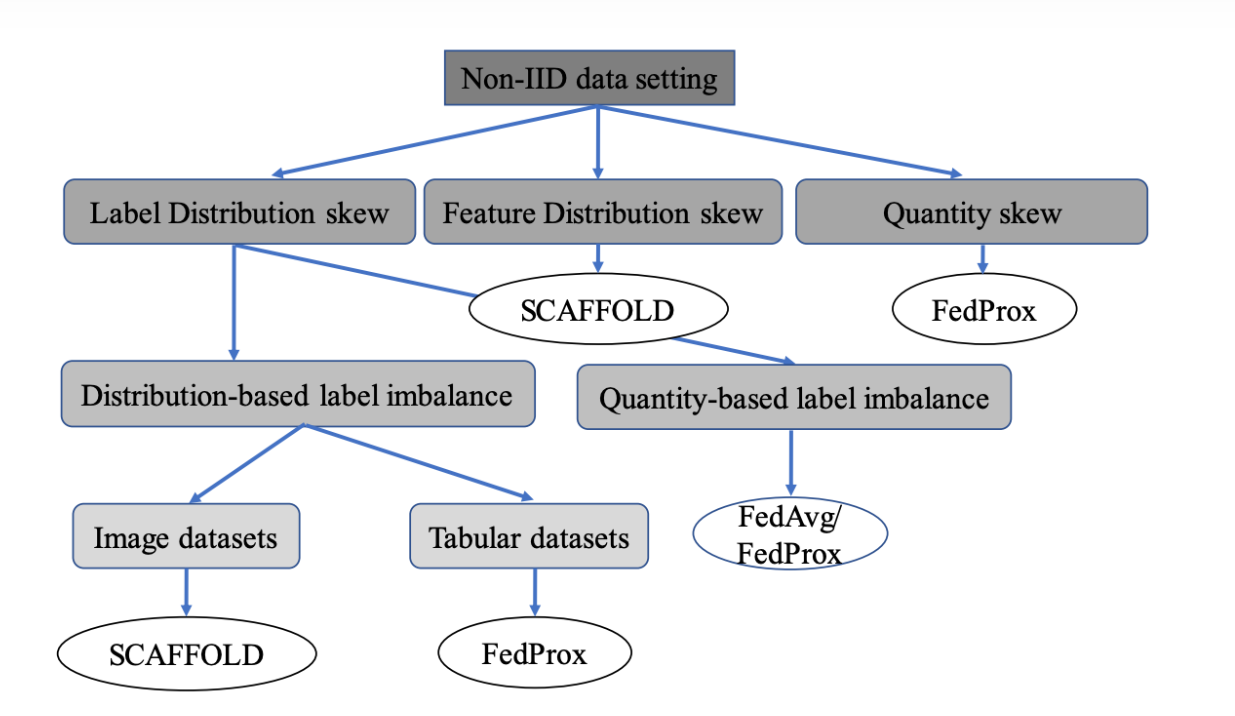
宽依赖:一个父RDD的分区被子RDD的多个分区使用
窄依赖:一个父RDD的分区被子RDD的一个分区使用
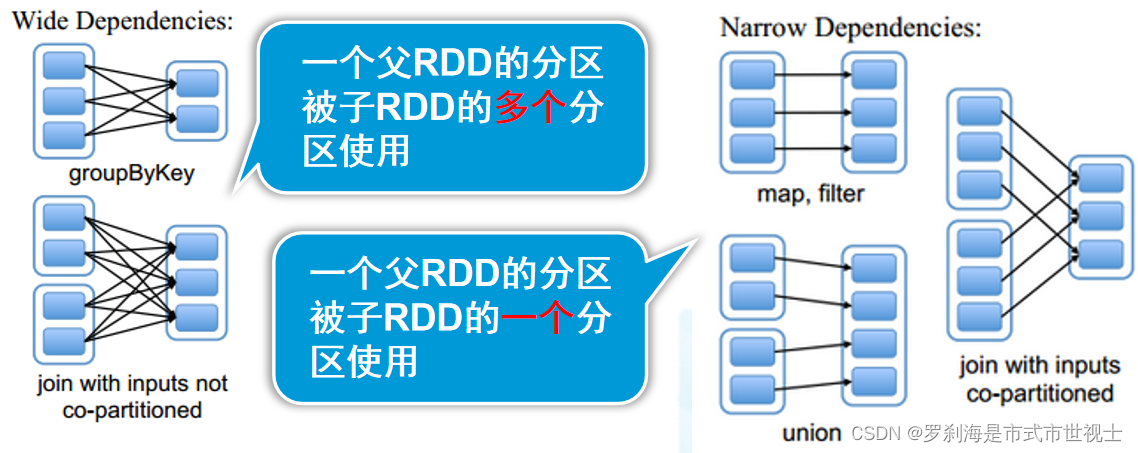
宽依赖对比窄依赖
宽依赖对应shuffle操作,需要在运行时将同一个父RDD的分区传入到不同的子RDD分区中,不同的分区可能位于不同的节点,就可能涉及多个节点间数据传输
当RDD分区丢失时,Spark会对数据进行重新计算,对于窄依赖只需要重新计算一次子RDD的父RDD分区
补:最多22个元组,元组可以套元组
| 宽依赖容错图
结论: 相比于宽依赖,窄依赖对优化更有利 |

练习:判断RDD依赖关系
Map flatMap filter distinct reduceByKey groupByKey sortByKey union join
scala> val b = sc.parallelize(Array(("hello",11),("java",12),("scala",13),("kafka",14),("sun",15)))
// b: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[2] at parallelize at <console>:24
scala> val c = sc.parallelize(Array(("hello",11),("java",12),("scala",13),("kafka",14),("sun",15)))
// c: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[3] at parallelize at <console>:24
scala> b.glom.collect
// collect collectAsync
scala> b.glom.collect
// res4: Array[Array[(String, Int)]] = Array(Array((hello,11)), Array((java,12)), Array((scala,13)), Array((kafka,14), (sun,15)))
scala> c.glom.collect
// collect collectAsync
scala> c.glom.collect
// res5: Array[Array[(String, Int)]] = Array(Array((hello,11)), Array((java,12)), Array((scala,13)), Array((kafka,14), (sun,15)))
scala> val d = a.jion(b)
// <console>:27: error: value jion is not a member of org.apache.spark.rdd.RDD[(String, Int, Int, Int)]
// val d = a.jion(b) //拼写错误
^
scala> val d = a.join(b)
// <console>:27: error: value join is not a member of org.apache.spark.rdd.RDD[(String, Int, Int, Int)]
// val d = a.join(b) //应该是bc不是ab
^
scala> val d = b.join(c) //Tab成功
// d: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[8] at join at <console>:27
scala> d.glom.collect
// collect collectAsync
scala> d.glom.collect
// res6: Array[Array[(String, (Int, Int))]] = Array(Array((sun,(15,15))), Array(), Array((scala,(13,13)), (hello,(11,11)), (java,(12,12)), (kafka,(14,14))), Array())五、DAG工作原理
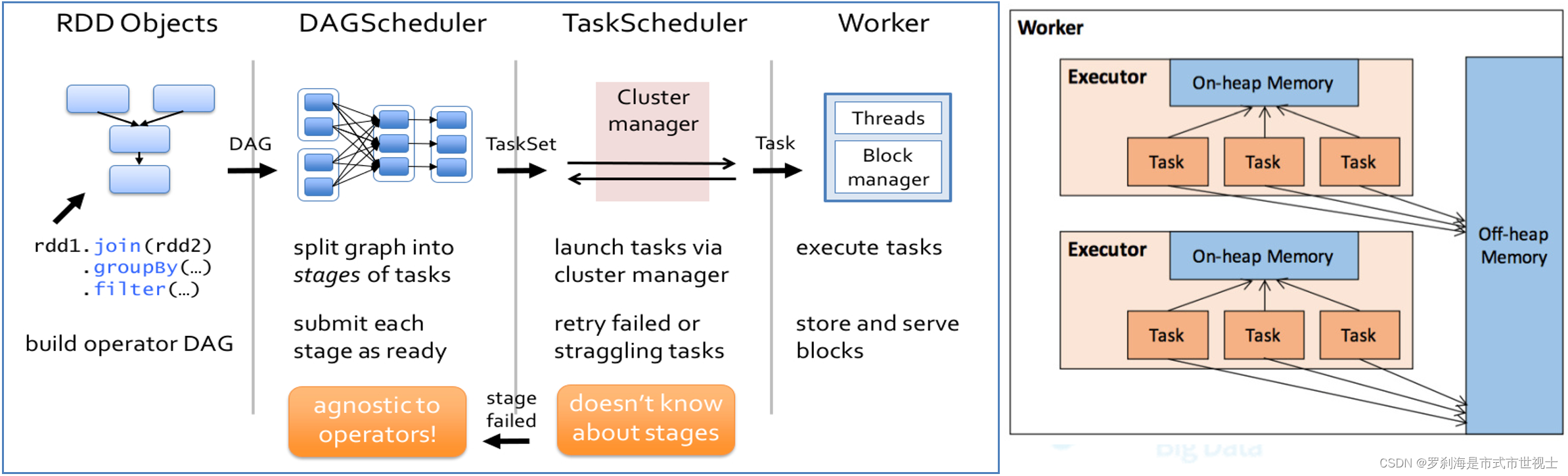
(1)根据RDD之间的依赖关系,形成一个DAG(有向无环图)
(2)DAGScheduler将DAG划分为多个Stage
划分依据:是否发生宽依赖(Shuffle)
划分规则:从后往前,遇到宽依赖切割为新的Stage
每个Stage由一组并行的Task组成的
六、Shuffle实践
最佳实践
提前部分聚合减少数据移动
尽量避免Shuffle

七、RDD优化
- RDD持久化
- RDD共享变量
- RDD分区设计
- 数据倾斜
(一)RDD持久化
(1)RDD缓存机制:缓存数据至内存/磁盘,可大幅度提升Spark应用性能
(2)缓存策略StorageLevel
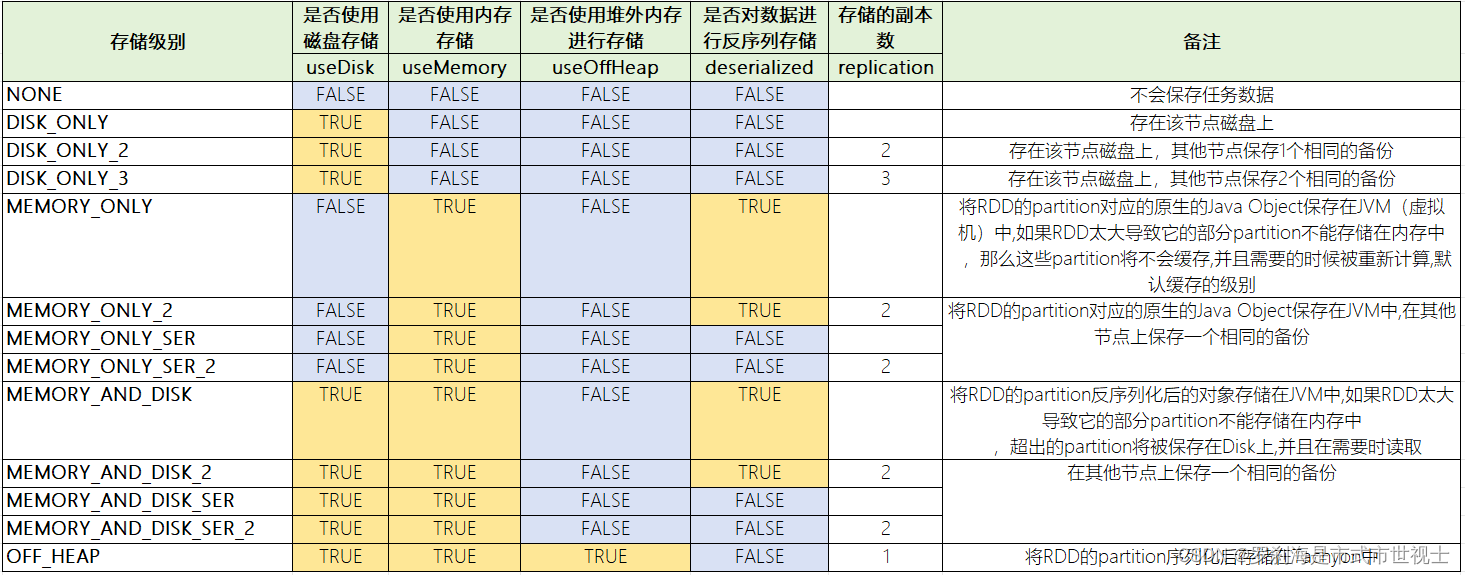
①RDD存储级别介绍(StorageLevel )
| object StorageLevel { |
②缓存应用场景
从文件加载数据之后,因为重新获取文件成本较高
经过较多的算子变换之后,重新计算成本较高
单个非常消耗资源的算子之后
③使用注意事项
Cache() 或persist() 后不能再有其他的算子
Cache() 或persist() 遇到Action算子完成后才生效
④操作
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object CacheDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("cachedemo")
val sc: SparkContext = SparkContext.getOrCreate(conf)
val rdd: RDD[String] = sc.textFile("in/users.csv")
// stack堆栈 heap栈
// rdd.cache() //设置默认缓存Memory_Only
rdd.persist(StorageLevel.MEMORY_ONLY)
val value: RDD[(String, Int)] = rdd.map(x=>(x,1))
// val start: Long = System.currentTimeMillis()
// println(value.count())
// val end: Long = System.currentTimeMillis()
// println("1:"+(end-start))
for (i<- 1 to 10){
val start: Long = System.currentTimeMillis()
println(value.count())
val end: Long = System.currentTimeMillis()
println(i+":"+(end-start))
Thread.sleep(10)
if (i>6){
rdd.unpersist()
}
}
}
}(3)检查点:类似于快照
sc.setCheckpointDir("hdfs:/checkpoint0918")
val rdd=sc.parallelize(List(('a',1), ('a',2), ('b',3), ('c',4)))
rdd.checkpoint
rdd.collect //生成快照
rdd.isCheckpointed
rdd.getCheckpointFile(4)检查点与缓存的区别
检查点会删除RDD lineage,而缓存不会
SparkContext被销毁后,检查点数据不会被删除
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object CheckPointDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("cachedemo")
val sc: SparkContext = SparkContext.getOrCreate(conf)
sc.setCheckpointDir("file://文件路径")
val rdd: RDD[Int] = sc.parallelize(1 to 20)
rdd.checkpoint()
rdd.glom().collect.foreach(x=>println(x.toList))
println(rdd.isCheckpointed)
println(rdd.getCheckpointFile)
}
}(二)RDD共享变量
(1)广播变量:允许开发者将一个只读变量(Driver)缓存到每个节点(Executor)上,而不是每个任务传递一个副本
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object BroadCastDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("cachedemo")
val sc: SparkContext = SparkContext.getOrCreate(conf)
var arr = Array("hello","hi","Come here")//一维数组
var arr2 = Array((1,"hello"),(2,"hello"),(3,"hi"))//二维数组
//广播变量
val broadcastVar: Broadcast[Array[String]] = sc.broadcast(arr)
val broadcastVar2: Broadcast[Array[(Int, String)]] = sc.broadcast(arr2)
//普通RDD
val rdd: RDD[(Int, String)] = sc.parallelize(Array((1,"leader"),(2,"teamleader"),(3,"worker")))
val rdd2: RDD[(Int, String)] = rdd.mapValues(x => {
println("value is:" + x)
// broadcastVar.value(0) + ":" + x
broadcastVar2.value(1)._2 + ":" + x
})
rdd2.collect.foreach(println)
}
}(2)累加器:只允许added操作,常用于实现计算
(三)RDD分区设计
(1)分区大小限制为2GB
(2)分区太少
不利于并发
更容易数据倾斜影响
groupBy,reduceByKey,sortByKey等内存压力增大
(3)分区过多
Shuffle开销越大
创建任务开销越大
(4)经验
每个分区大约128MB
如果分区小于但接近2000,则设置为大于2000
(四)数据倾斜
1、指分区中的数据分配不均匀,数据集中在少数分区中
严重影响性能
通常发生在groupBy,jion等之后

2、解决方案
使用新的Hash值(如对key加盐)重新分区
3、实战
[root@kb23 jars]# pwd
/opt/soft/spark312/examples/jars
[root@kb23 jars]# ls
scopt_2.12-3.7.1.jar spark-examples_2.12-3.1.2.jar
[root@kb23 sbin]# pwd
/opt/soft/spark312/sbin
[root@kb23 sbin]# start-all.sh
[root@kb23 spark312]# ./bin/spark-submit --master spark://192.168.91.11:7077 --class org.apache.spark.examples.SparkPi ./examples/jars/spark-examples_2.12-3.1.2.jar 100
Pi is roughly 3.1407527140752713
重新分区(../spark312目录)
./bin/spark-submit \
--master spark://192.168.78.131:7077
--executor-memory 6G \
--executor-cores 4 \
--driver-memory 1G \
--conf spark.default.parallelism=1000 \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.3 \
--class org.apache.spark.examples.SparkPi \
./examples/jars/spark-examples_2.12-3.1.2.jar \
1000