用 pandas 读取 csv 的常见方法:
import pandas as pd
df = pd.read_csv("your_csv_file.csv")但对于大型的 csv 文件,直接读取可能会报错 numpy.core._exceptions._ArrayMemoryError
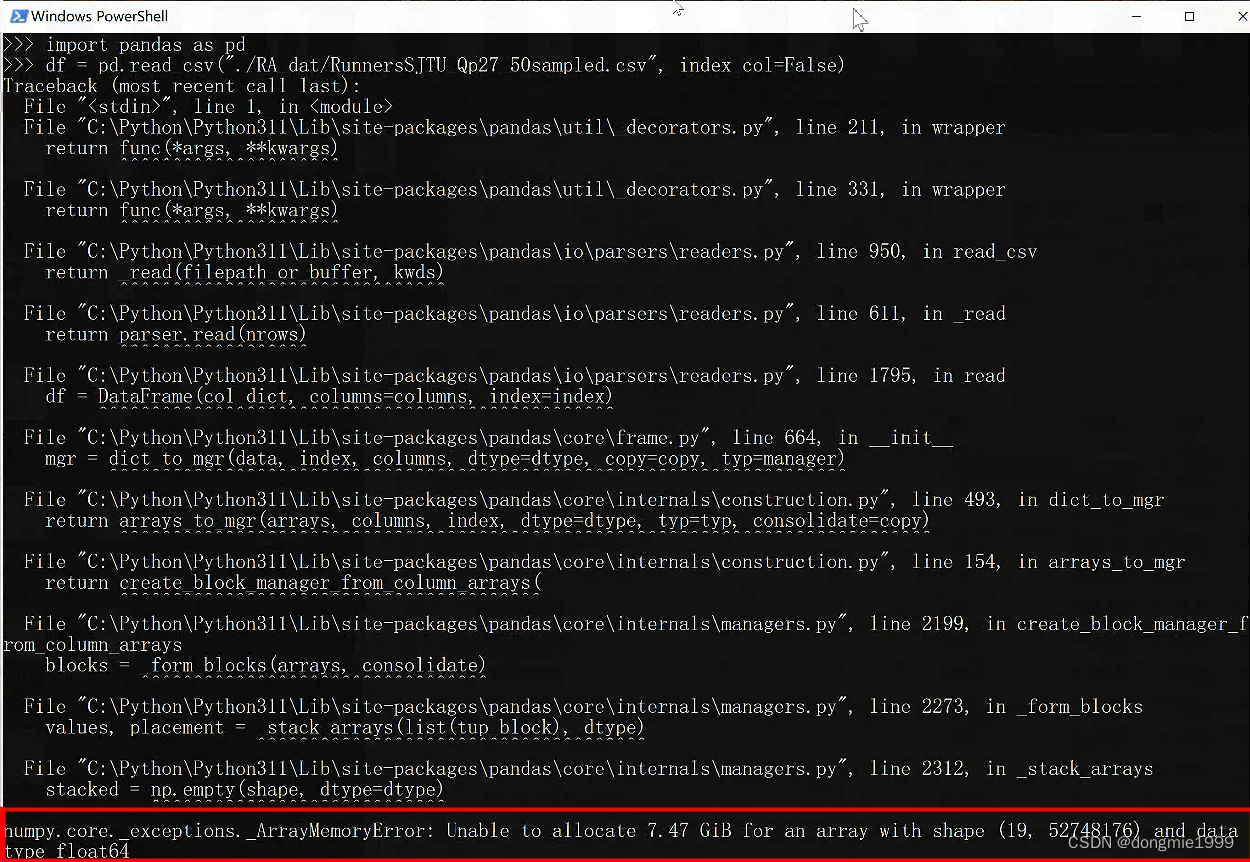
我的机器是 24G 内存,直接读大概只允许单个最大 4G 左右的 csv 文件;
而且 pandas 处理比较慢,看到内存一点点慢慢涨上去,到大概 97% 的时候就报错退出了;
用 chunk 分板块读取 csv 文件:
import pandas as pd
import random
import os
# 统计指定文件夹下的所有csv文件
csv_path = './your_dir_here/'
all_csv = []
for file in os.listdir(csv_path):
if file.endswith(".csv"):
all_csv.append(file)
all_csv.reverse()
for csv in all_csv:
# 一块块读取大csv文件,随机采样50%并输出到新csv文件
output_file = csv + '_50sampled.csv'
# 打开输入文件和输出文件
with open(csv, 'r') as infile, open(output_file, 'w') as outfile:
header = next(infile) # 读取CSV文件的头部
outfile.write(header) # 写入输出文件的头部
chunk_size = 10000 # 设置每次读取的行数,根据内存状况定
for chunk in pd.read_csv(infile, chunksize=chunk_size):
sampled_chunk = chunk.sample(frac=0.5) # 随机采样50%的行
sampled_chunk.to_csv(outfile, index=False, header=False, mode='a') # 追加到输出文件