前言:在对于c语言的学习中,我们为了持续使用一些数据,为了让我们的数据可以在程序退出后仍然保存并且可以使用,我们引入了文件的概念和操作,本文旨在为大家分享在文件操作中常用的输入输出函数的使用方式和技巧,以及分析它们之间的区别
目录
一.常用文件顺序读写函数
二.字符操作函数 fgetc 和 fputc
fgetc
fputc
三.文本行操作函数 fgets 和 fputs
fgets
fputs
四.格式化操作函数 fscanf 和 fprintf
fscanf
fprintf
五.二进制操作函数
fread
fwrite
解密二进制文件
总结与分析
一.常用文件顺序读写函数
在这里我们先给出本次分享要讲解的函数的大致声明列举
|
功能
|
函数名
|
适用于
|
|
字符输入函数
|
fgetc
|
所有输入流
|
|
字符输出函数
|
fputc
|
所有输出流
|
|
文本行输入函数
|
fgets
|
所有输入流
|
|
文本行输出函数
|
fputs
|
所有输出流
|
|
格式化输入函数
|
fscanf
|
所有输入流
|
|
格式化输出函数
|
fprintf
|
所有输出流
|
|
二进制输入
|
fread
|
文件
|
|
二进制输出
|
fwrite
|
文件
|
二.字符操作函数 fgetc 和 fputc
我们还是给出 cplusplus 官网的讲解说明:
fgetc:fgetc - C++ Reference (cplusplus.com)
fputc:fputc - C++ Reference (cplusplus.com)
fgetc
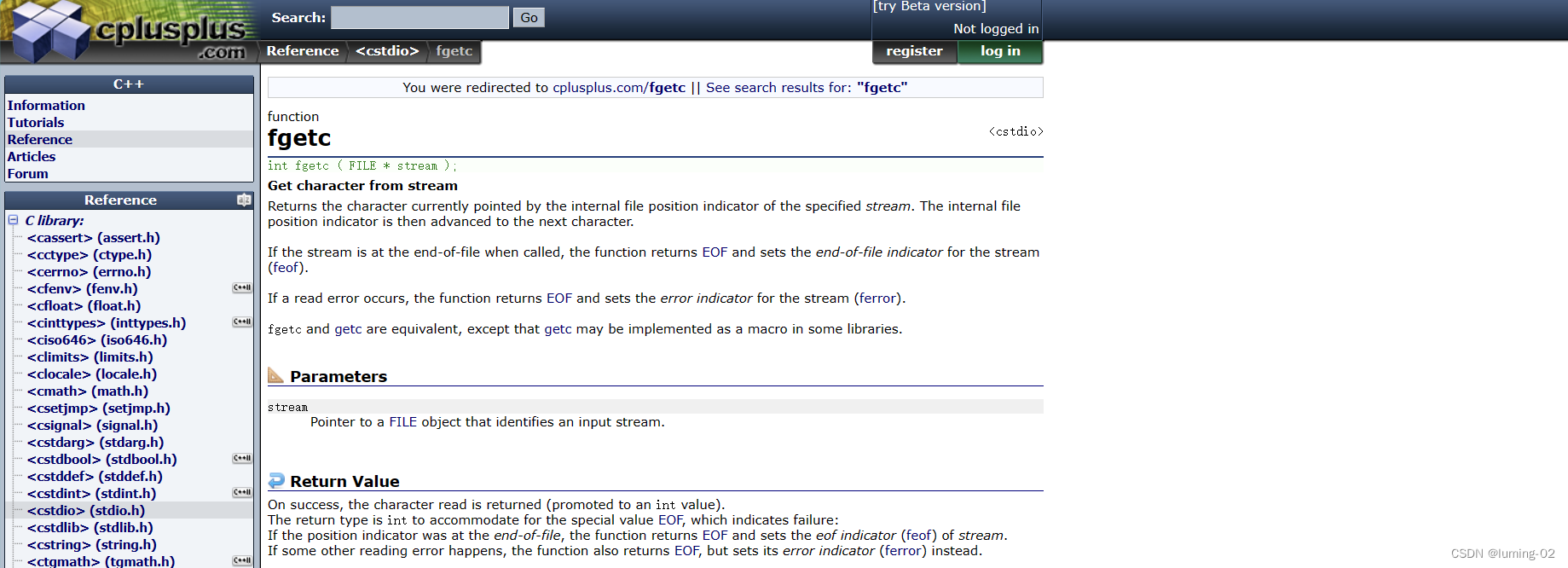
我们先来观察 fgetc 函数, 官方文本显示如下:
- 从流中获取字符
- 返回指定流的内部文件位置指示符当前指向的字符。然后将内部文件位置指示符推进到下一个字符
- 如果流在被调用时位于文件的末尾,则该函数返回 EOF 并为流设置文件结束指示器(feof)
- 如果发生读错误,该函数返回EOF并设置流的错误指示器(error)
- Fgetc 和 getc 是等价的,除了 getc 可以在某些库中作为宏实现
为了更加具体的理解,我们写出一个文件
然后我们对其进行输入
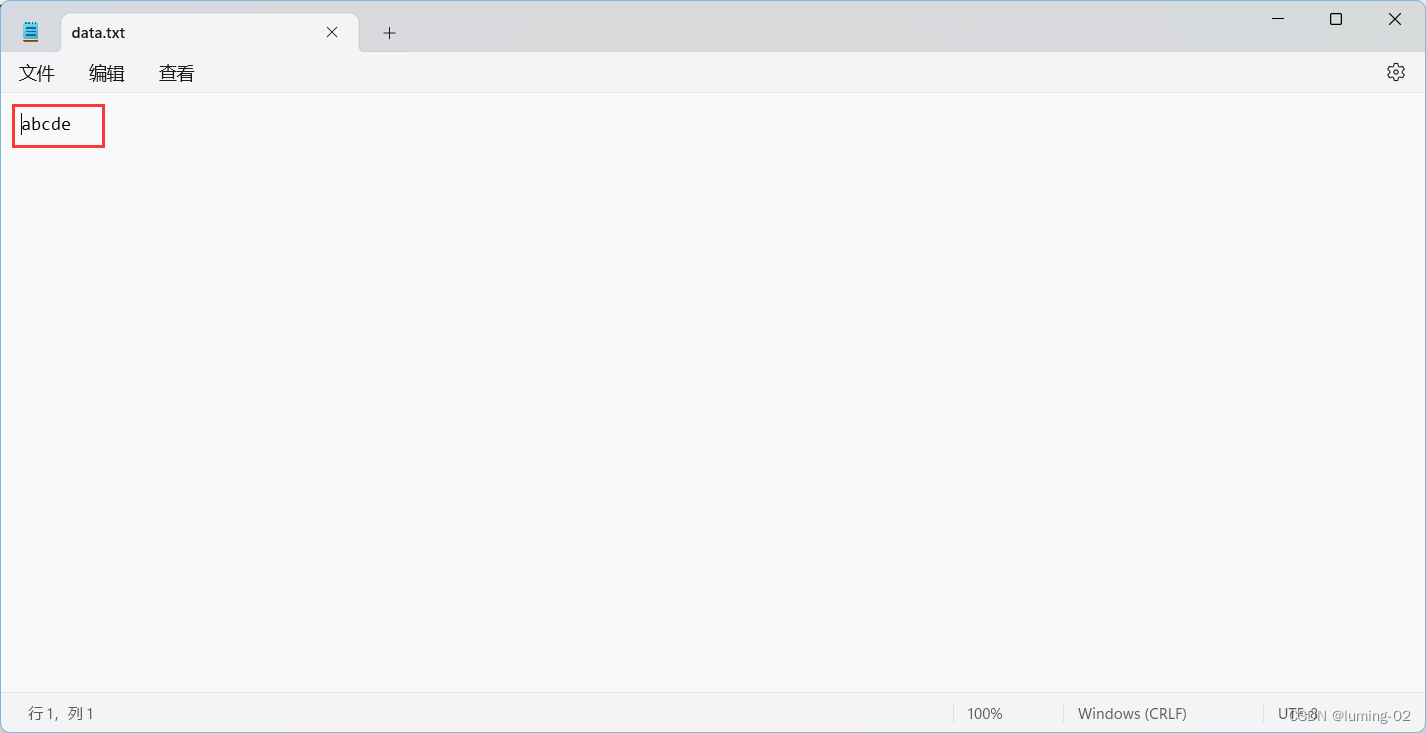
在确保了我们的文件可以有内容读取后,我们编程实现观察结果,我们以读取的方式打开文件,然后使用 ch 变量挨个读取文件中的字符并且打印
int main()
{
//打开文件
FILE* pf = fopen("data.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//读文件
int ch = fgetc(pf);
printf("%c", ch);
ch = fgetc(pf);
printf("%c", ch);
ch = fgetc(pf);
printf("%c", ch);
ch = fgetc(pf);
printf("%c", ch);
ch = fgetc(pf);
printf("%c", ch);
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}然后我们可以发现,确实可以读取到文件中的字符

- 综合上述操作,我们可以得出结论,fgetc 函数可以挨个读取文件中的字符,我们可以定义一个变量来接收 fgets 的返回值(字符的ASCII码)然后进行输出等操作
- 在使用该函数的时候,我们只需要将文件指针(流)作为参数传给函数,然后我们就可以得到一个字符的ASCII码
fputc
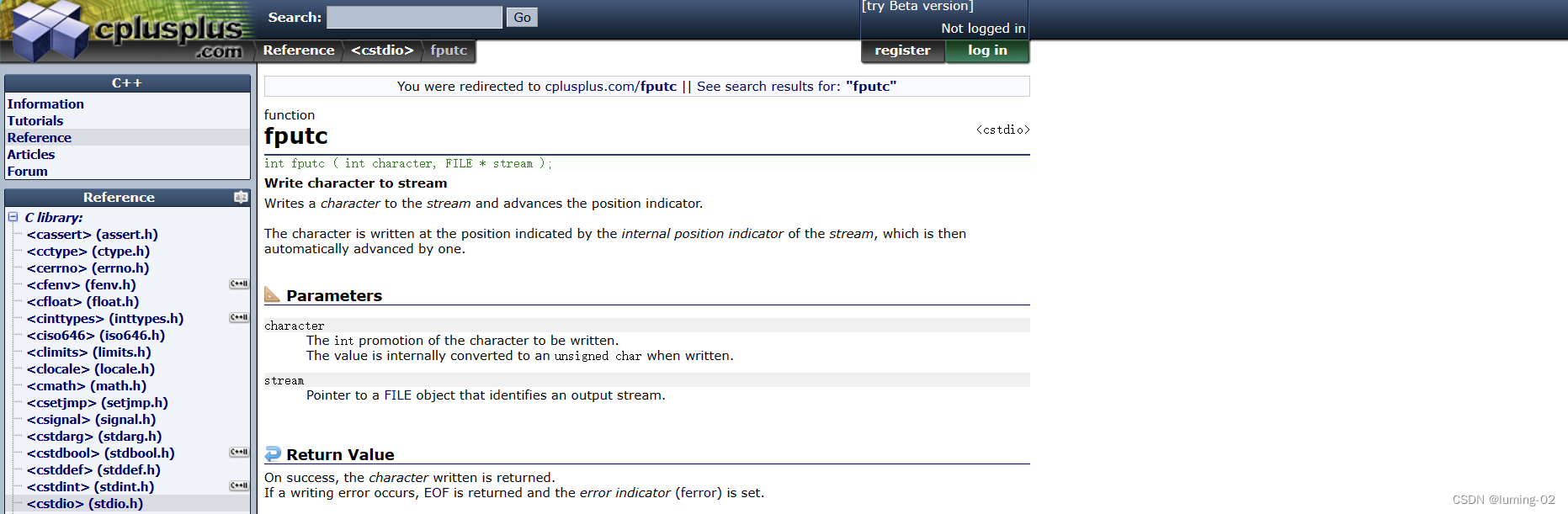
我们先来观察 fputc 函数, 官方文本显示如下:
- 将字符写入流
- 将一个字符写入流并推进位置指示器
- 字符被写入流的内部位置指示器所指示的位置,然后自动向前移动一个
我们还是用代码示例来演示,这样更方便我们理解
在演示前,我们确保文件内是空白的
int main()
{
//打开文件
FILE* pf = fopen("data.txt", "w");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//写文件
fputc('a', pf);
fputc('b', pf);
fputc('c', pf);
fputc('d', pf);
fputc('e', pf);
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}运行后:
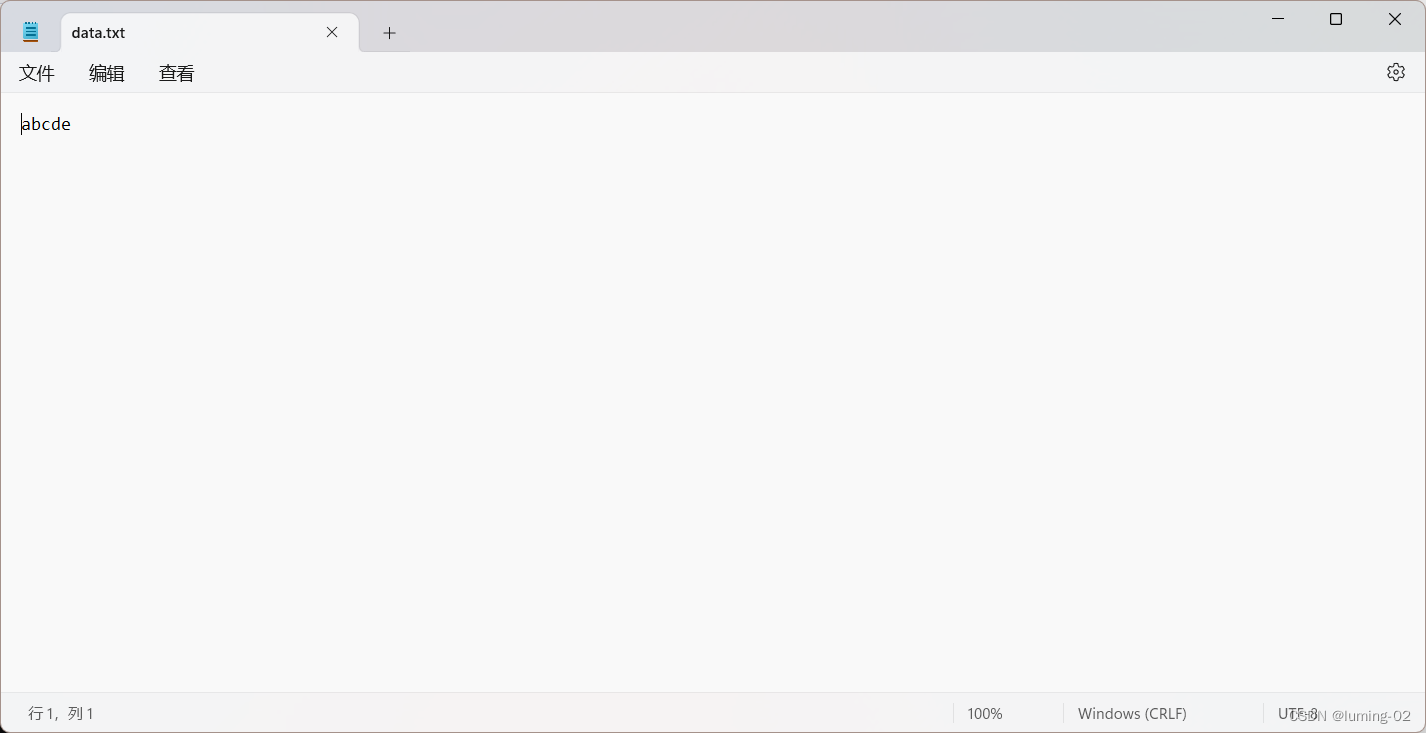
我们可以发现,通过 fputc 函数挨个对文件输入了从 ‘a’ 到 ‘e’ 的字符
综合上述操作,我们可以得出结论,fputc 函数可以挨个字符的对文件进行写入的操作,函数内部需要注意的有俩个参数
- 要写入的字符
- 要写入文件的文件指针(流)
三.文本行操作函数 fgets 和 fputs
我们还是给出 cplusplus 官网的讲解说明:
fgets:fgets - C++ Reference (cplusplus.com)
fputs:fputs - C++ Reference (cplusplus.com)
fgets
我们先来观察 fgets 函数, 官方文本显示如下:
- 从流中获取字符串
- 从流中读取字符,并将其作为C字符串存储到 str 中,直到读取 (num-1) 个字符,或者到达换行符或文件结束符,以先发生的为准
- 换行符使 fgets 停止读取,但它被函数认为是一个有效字符,并包含在复制到 str 的字符串中。
- 在复制到 str 的字符之后,将自动追加一个终止 null 字符。
- 请注意,fgets 与 gets 有很大的不同:fgets 不仅接受流参数,而且允许指定 str 的最大长度,并在字符串中包含任何结束换行符
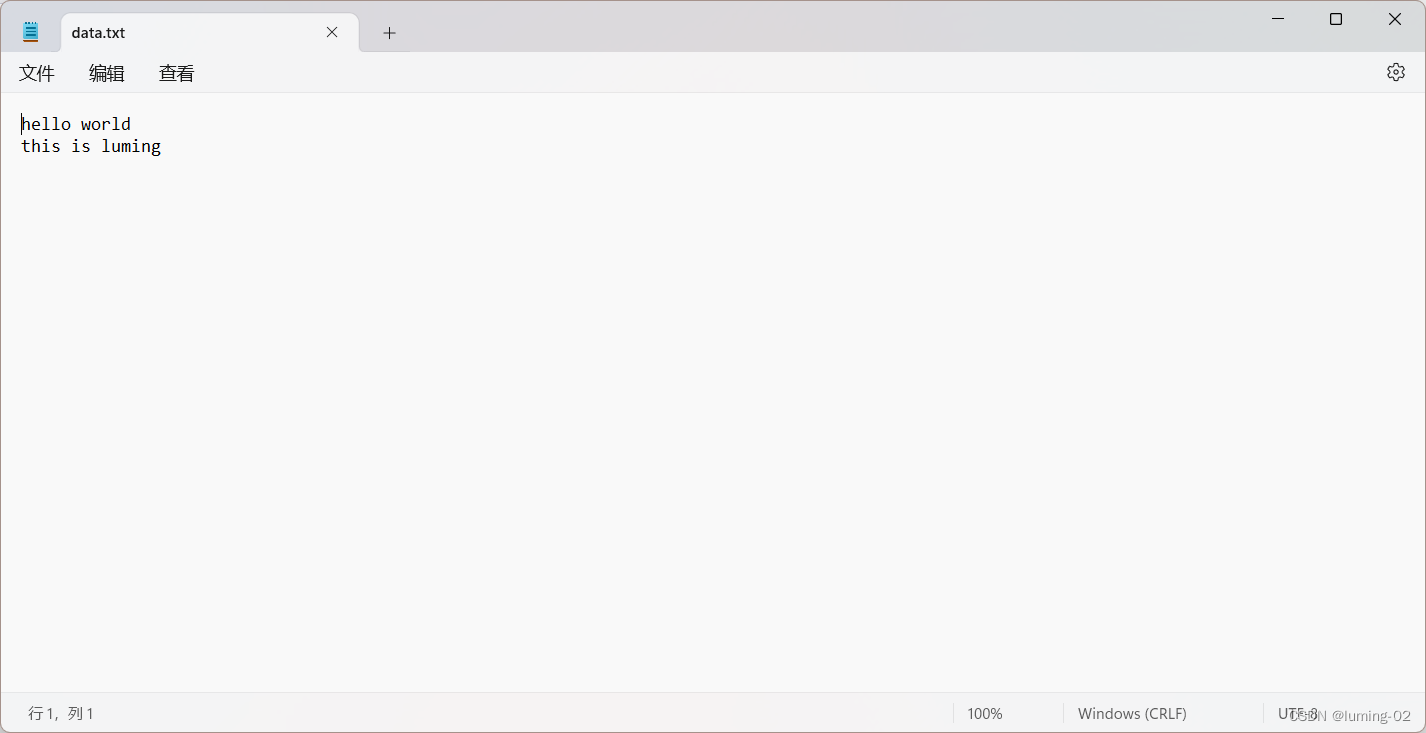
我们还是用一段示例来理解,首先有个 data.txt 的文件如下
我们给出代码如下:
int main()
{
//打开文件
FILE* pf = fopen("data.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//读文件
char arr[100] = {0};
fgets(arr, 100, pf);
printf("%s", arr);
fgets(arr, 100, pf);
printf("%s", arr);
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}输出结果:
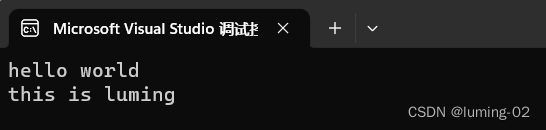
根据输出结果,我们可以发现,一条 fgets 函数可以读取一行的内容,但是在使用的时候需要注意设置一个字符数组来接收字符串,函数在使用时,一共有三个参数
- 要传入数组的地址
- 要复制到字符串中的最大字符数
- 文件指针(流)
fputs
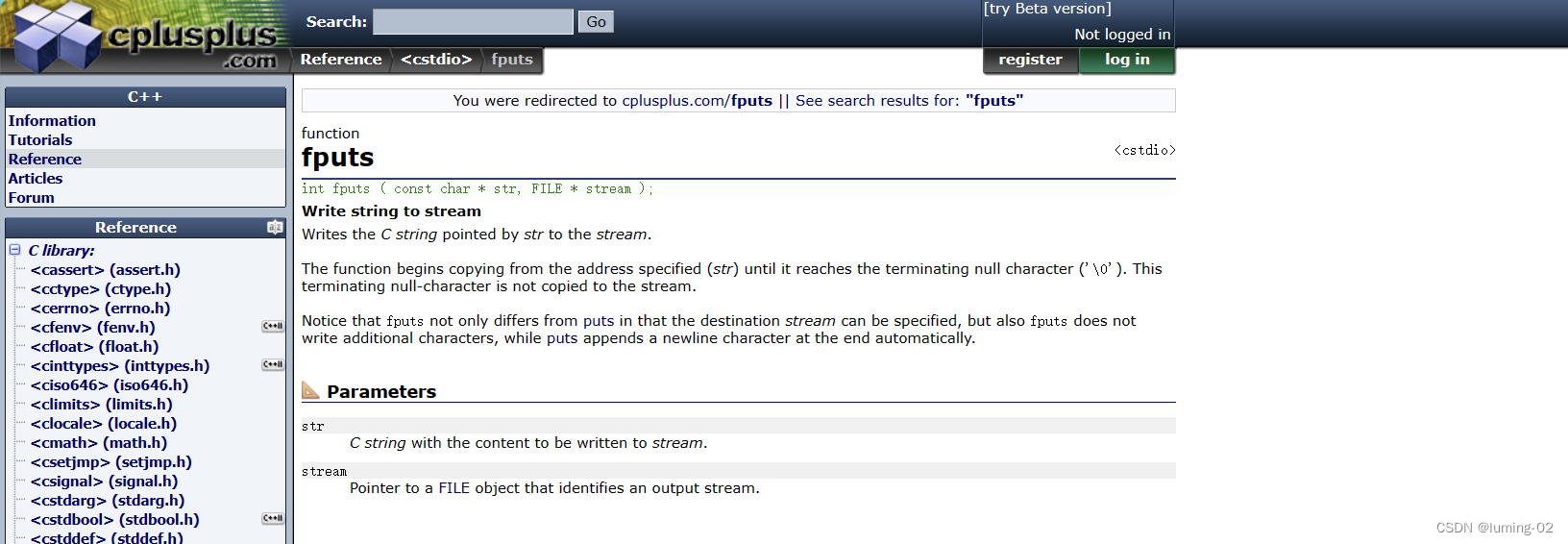
我们先来观察 fputs 函数, 官方文本显示如下:
- 将字符串写入流
- 将由 str 指向的C字符串写入流
- 函数从指定的地址 (str) 开始复制,直到到达结束的空字符 ('\0'),这个终止的空字符不会复制到流中
- 注意,fputs 与 puts 的不同之处不仅在于可以指定目标流,而且 fputs 不会写入额外的字符,而 puts 会自动在末尾附加一个换行符
我们还是用一段示例来理解,首先还是设定一个空白内容的 data.txt 的文件
我们给出代码如下:
int main()
{
//打开文件
FILE* pf = fopen("data.txt", "w");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//写文件
char arr[] = "hello";
fputs(arr, pf);
fputs("world", pf);
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}运行结果:
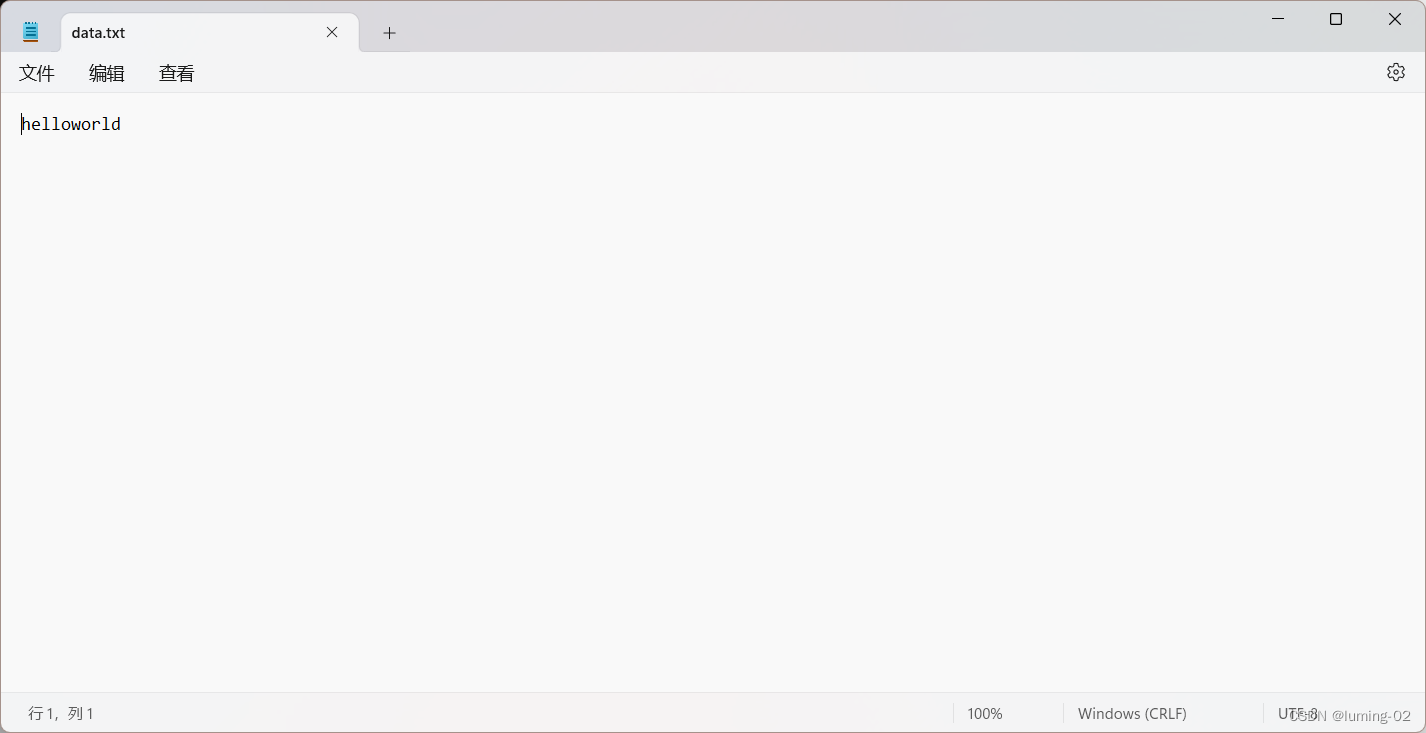
根据运行结果,我们可以判断, fputs 函数一次性可以对文件写入一行字符串,只要声明字符串的内容或者地址,都可以进行写入,它的俩个参数分别如下:
- 要写入的字符串的内容或者地址
- 要写入的文件指针(流)
四.格式化操作函数 fscanf 和 fprintf
我们还是给出 cplusplus 官网的讲解说明:
fscanf:fscanf - C++ Reference (cplusplus.com)
fprintf:fprintf - C++ Reference (cplusplus.com)
fscanf
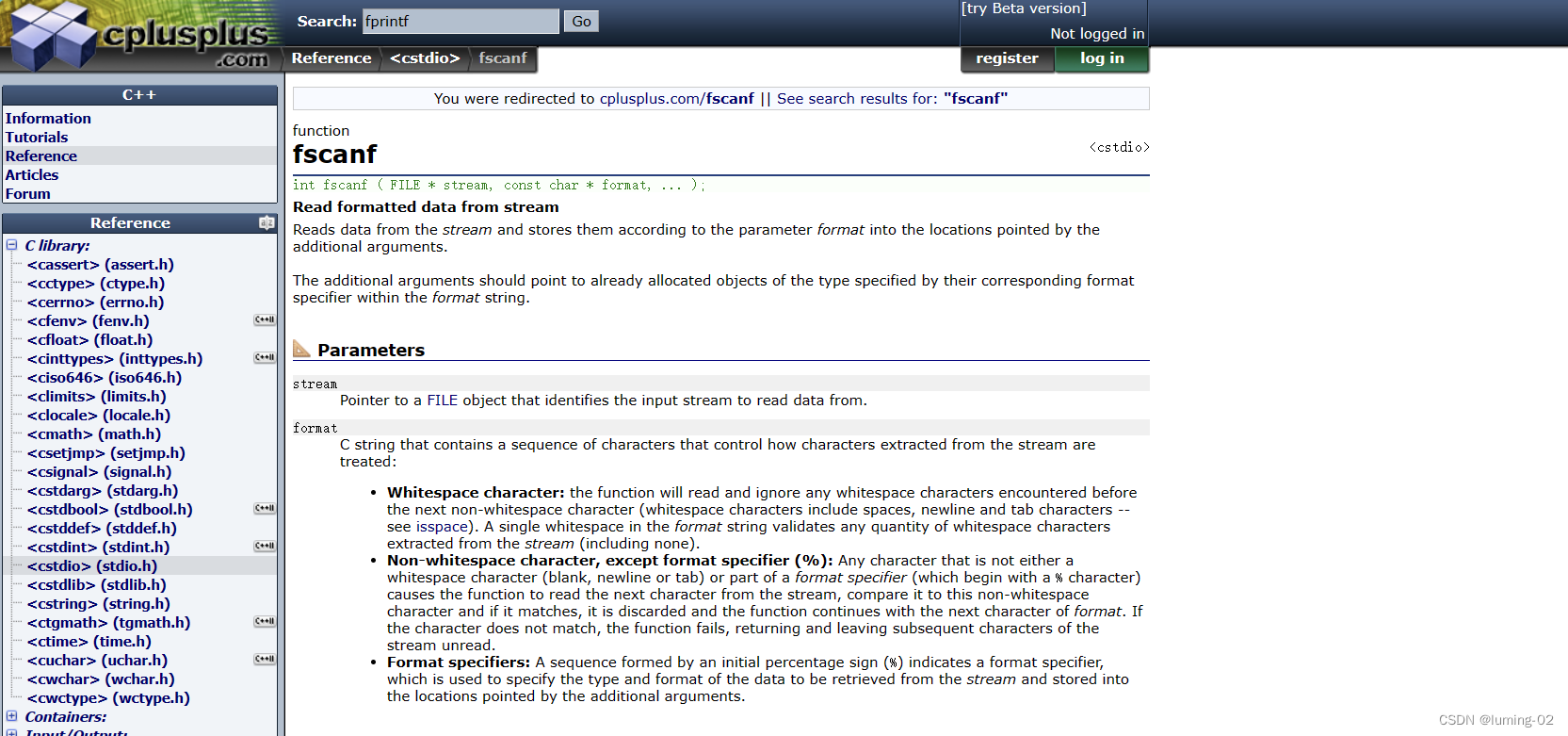
我们先来观察 fscanf 函数, 官方文本显示如下:
- 从流中读取格式化的数据
- 从流中读取数据,并根据参数格式将其存储到附加参数所指向的位置
- 额外的参数应该指向已经分配的对象,其类型由格式字符串中相应的格式说明符指定
我们还是用一段示例来理解,首先有个 data.txt 的文件如下
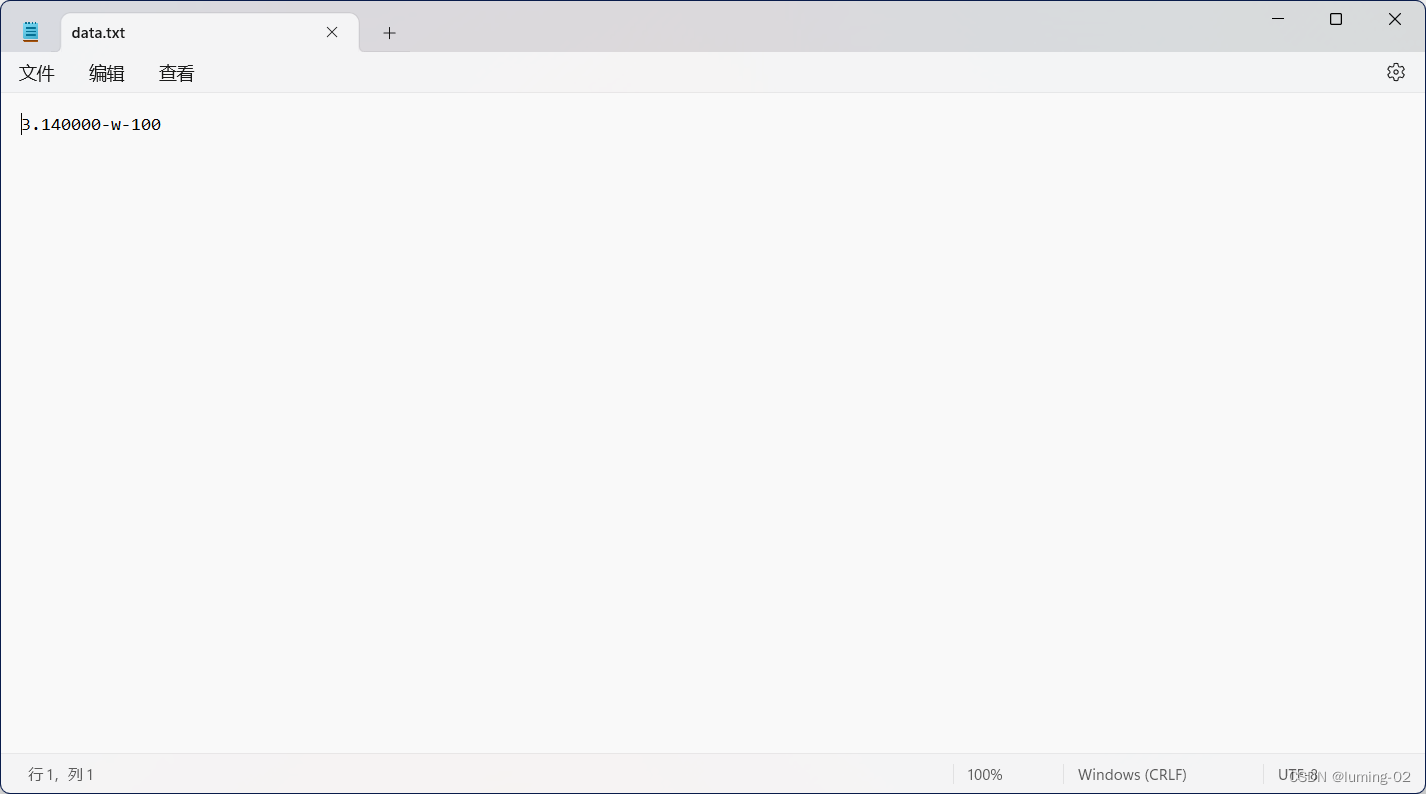
我们给出相对于的代码如下:
struct S
{
float f;
char c;
int n;
};
int main()
{
struct S s = {0};
//打开文件
FILE* pf = fopen("data.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//读文件
fscanf(pf, "%f-%c-%d", &(s.f), &(s.c), &(s.n));
printf("%f-%c-%d\n", s.f, s.c, s.n);
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}输出结果:
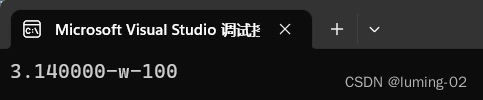
根据输出结果,我们可以发现,原本文件中的字符串,被我们以 float char int 的格式分别读到了 f,c,n 三个变量中,也就是说我们将原本的字符串变成了不同格式的数据,在使用这个函数时,注意他的参数,只比 scanf 多了一个参数,也就是文件指针(流)
fprintf
我们先来观察 fprintf 函数, 官方文本显示如下:
- 将格式化的数据写入流
- 将由 format 指向的 C字符串写入流。如果 format 包含格式说明符(以%开头的子序列),则格式化format 之后的其他参数并将其插入到结果字符串中,以替换它们各自的说明符。
- 在format 形参之后,函数期望至少与format 指定的一样多的附加参数。
我们还是用一段示例来理解,首先有个 data.txt 的空文件
我们给出代码如下:
struct S
{
float f;
char c;
int n;
};
int main()
{
struct S s = { 3.14f, 'w', 100 };
//打开文件
FILE* pf = fopen("data.txt", "w");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//写文件
fprintf(pf, "%f-%c-%d", s.f, s.c, s.n);
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}运行结果:
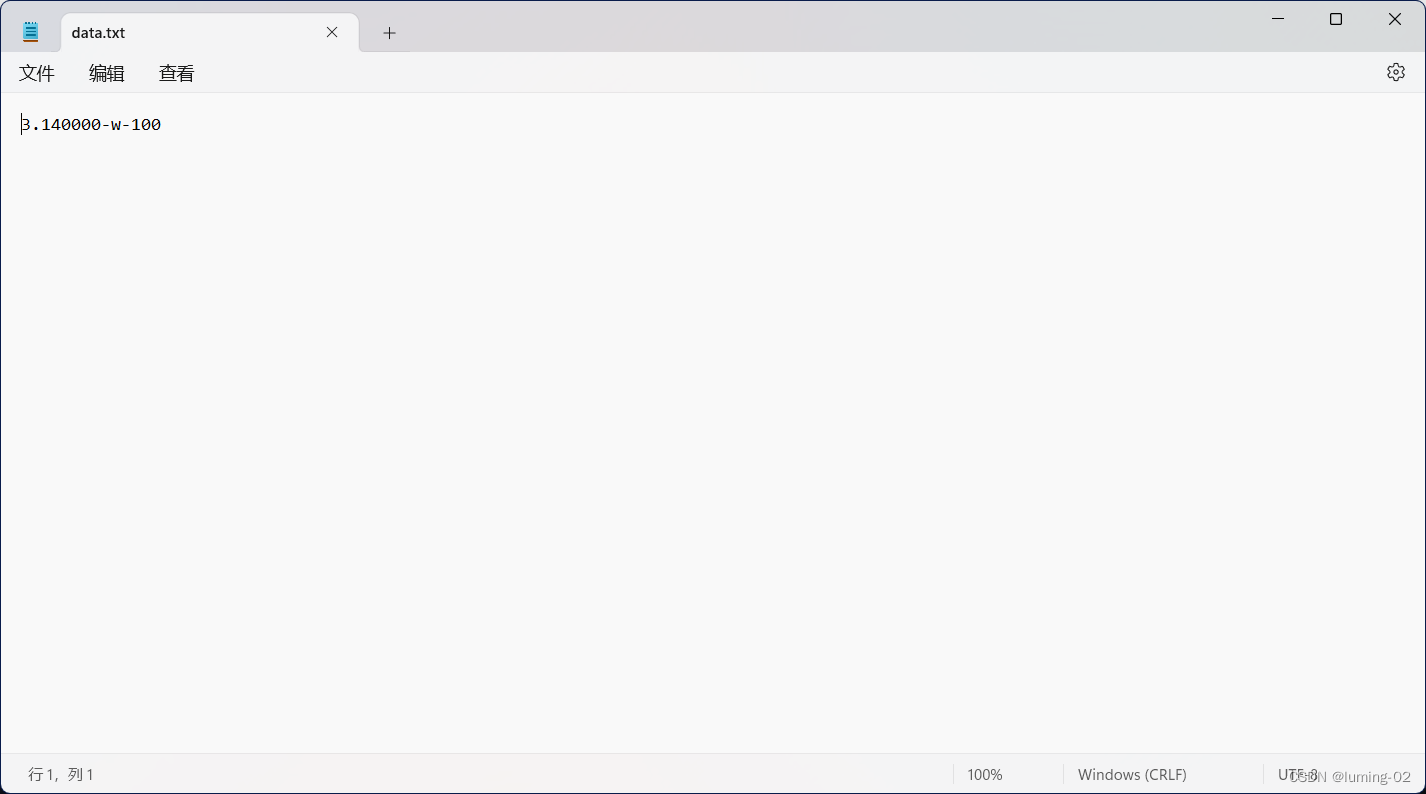
根据输出结果,我们可以发现,我们以结构体的格式,将其中 float char int 三种类型的数据写入了文件,在写入文件后,这些数据就失去了原本的格式,相当于变成了一条字符串,在使用的时候,他只比我们的 scanf 多了一个参数,也就是文件指针(流)
五.二进制操作函数
我们还是给出 cplusplus 官网的讲解说明:
fread:fread - C++ Reference (cplusplus.com)
fwrite:fwrite - C++ Reference (cplusplus.com)
fread
我们先来观察 fread 函数, 官方文本显示如下:
- 从流中读取数据块
- 从流中读取一个由 count 元素组成的数组,每个元素的大小为 size 字节,并将它们存储在 ptr 指定的内存块中
- 流的位置指示器按读取的总字节数前进
- 如果成功读取的总字节数为 (size*count)
该函数一共有 4 个参数:
size_t size:要读取的每个元素的大小(以字节为单位)size_t count:元素的数目,每个元素的大小为 size 字节FILE * stream:指向指定输入流的 FILE 对象的指针(文件指针)
为了方便理解,我们还是用一段示例来理解,首先有个 data.txt 的文件如下

然后给出代码如下:
//二进制的方式读取文件
int main()
{
int arr[10] = {0};
//写文件
FILE* pf = fopen("data.txt", "rb");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//二进制的读文件
fread(arr, sizeof(arr[0]), sizeof(arr) / sizeof(arr[0]), pf);
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}运行结果:
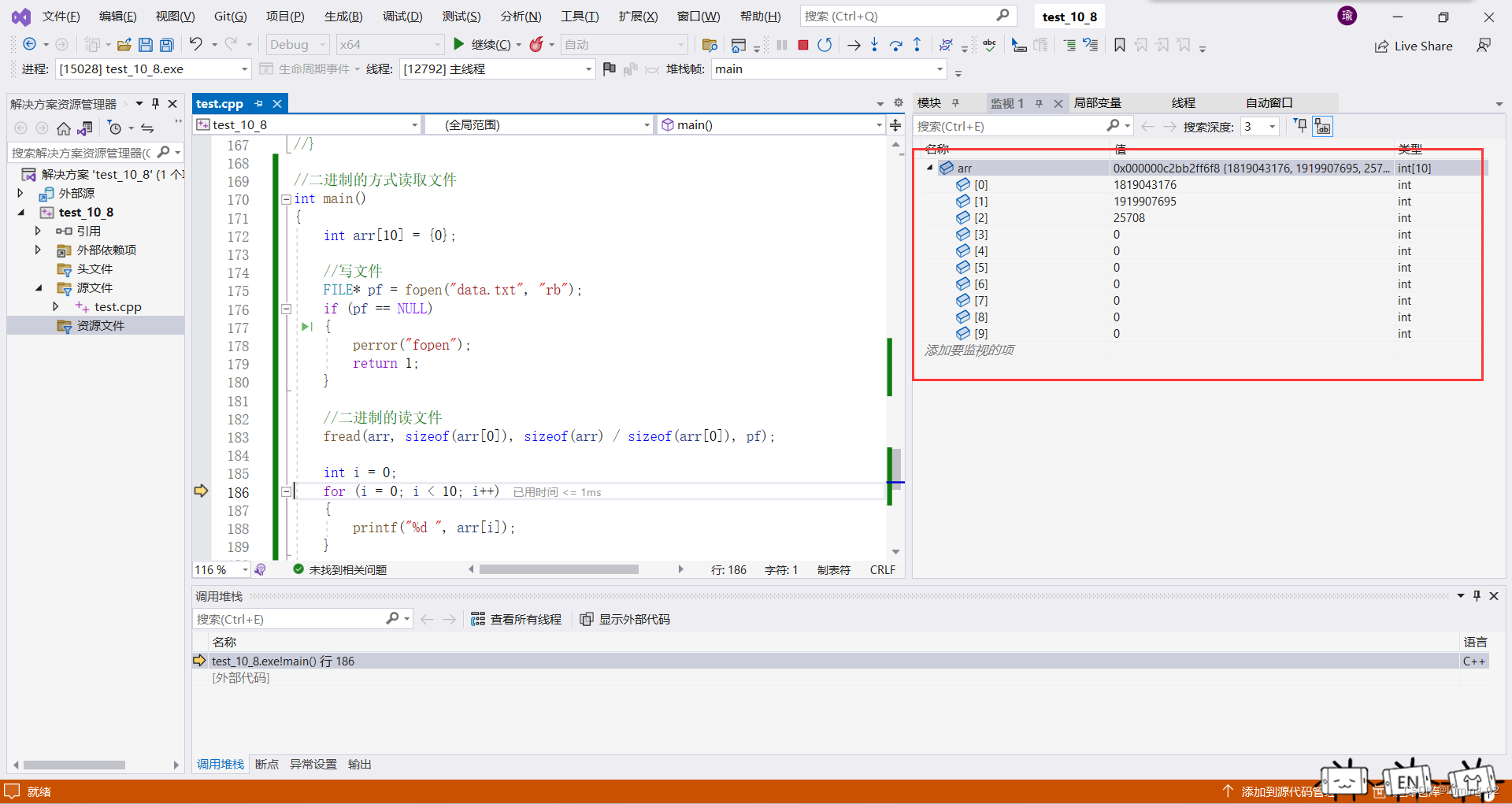
我们发现和我们预期的完全不一样,这是因为我们读取是以二进制的方式读取,打印的时候却是以十进制的方式打印,这样就相当于给数据加密了,我们无法直观的看见我们读取了什么数据,但是我们确确实实是读取到了
我们如何验证我们读到的数据就是我们想存储的那部分呢?后文在介绍fwrite的时候笔者会给大家进行验证

fwrite
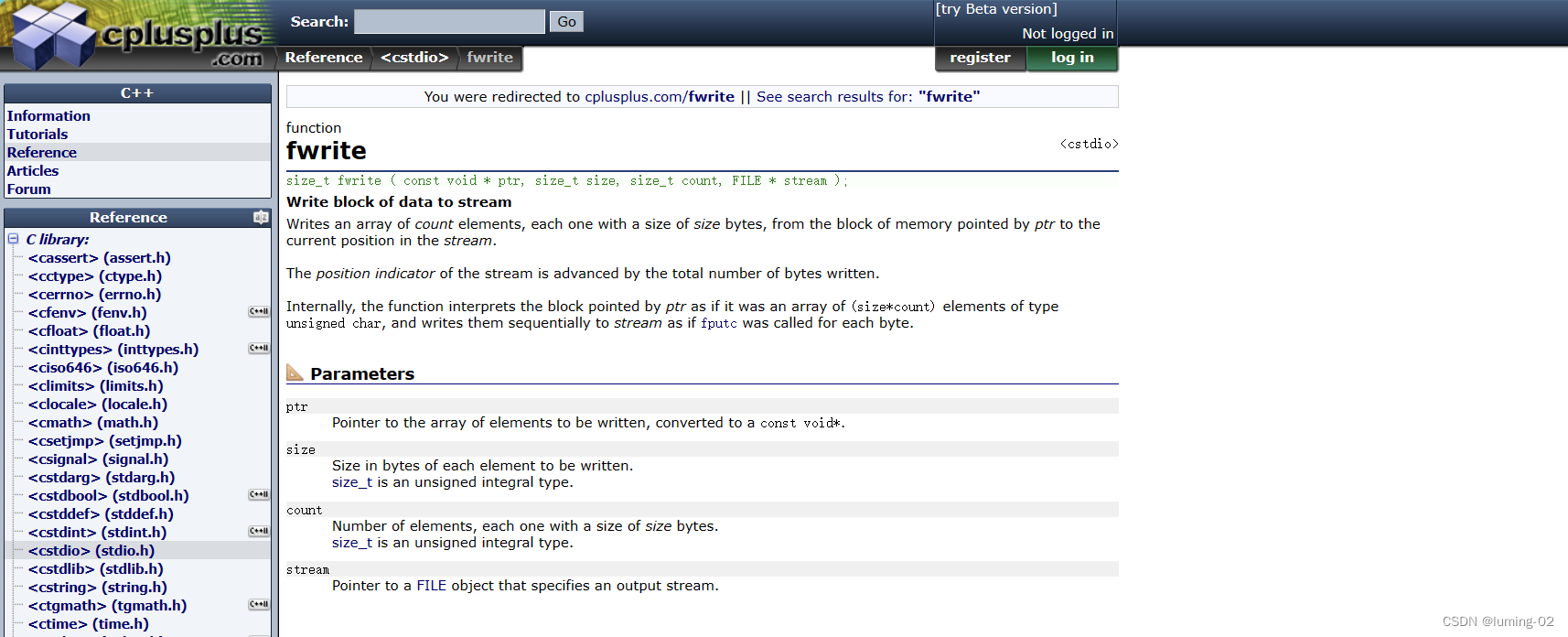
我们先来观察 fwrite 函数, 官方文本显示如下:
- 将数据块写入流
- 将由 count 元素组成的数组 (每个元素的大小为 size 字节) 从 ptr 所指向的内存块写入流中的当前位置
- 流的位置指示器按写入的总字节数前进
- 在内部,该函数将 ptr 指向的块解释为 unsigned char 类型的 (size*count) 元素数组,并将它们顺序写入流,就像对每个字节调用 fputc 一样
它也有四个参数如下:
size_t size:要写入的每个元素的大小(以字节为单位)size_t count:元素的数目,每个元素的大小为 size 字节FILE * stream:指向指定输入流的 FILE 对象的指针(文件指针)
为了方便理解,我们还是用一段示例来理解,首先有个 data.txt 的空文件
然后我们给出代码如下:
//二进制的方式写进文件
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
//写文件
FILE*pf = fopen("data.txt", "wb");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//二进制的写文件
fwrite(arr, sizeof(arr[0]), sizeof(arr)/sizeof(arr[0]), pf);
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}运行结果:
同样,我们还是无法直观的看见我们存储了什么,这是因为记事本使用的是 UTF-8 码,和我们保存的二进制并不兼容,这从十进制转到二进制再用 UTF-8 码进行显示也就相当于对文本进行了一层加密
那如何验证数据的真实性呢?我们可以使用刚才介绍的 fread 进行读取,然后观察
解密二进制文件
这里生成的data.txt 的文件我们保持不动,我们使用刚才介绍的 fread 来读取这个文件
//二进制的方式读取文件
int main()
{
int arr[10] = {0};
//写文件
FILE* pf = fopen("data.txt", "rb");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//二进制的读文件
fread(arr, sizeof(arr[0]), sizeof(arr) / sizeof(arr[0]), pf);
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}运行结果:
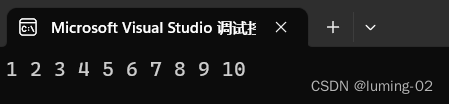
我们可以看见,我们第一次用fwrite写入的从 1到10 的数组被我们成功的读取到了,也就是说不管是 fread 还是fwrite
他们在对数据的写入和读出的时候麻豆不会影响数据的真实性,他们只是相当于对数据进行了加密,所以导致了我们无法直观的阅读数据
总结与分析
fgetc:从文件中读取单个字符
fputc:对文件写入单个字符
fgets:从文件中读取一个字符串
fputs:对文件写入一个字符串
fscanf:将文件中的字符串转换为有格式的数据并且读取出来
fprintf:将有格式的数据转换为字符串并且写入文件
fread:将文件中的内容转换为二进制然后读取出来
fwrite:将数据转换为二进制然后写入文件
本次的分享就到此为止了,感谢您的支持,如果您也不同的见解,欢迎积极提出交流