目录
1.简介
2.YOLO算法
3.基于YOLOv5、YOLOv8的火灾检测
视频已上传b站
YOLOv5/YOLOv8的火灾检测(超实用项目)_哔哩哔哩_bilibili
本文为系列专栏,包括各种YOLO检测算法项目、追踪算法项目、双目视觉、深度结构光相机测距测速三维测量项目等
专栏持续更新中,有需要的小伙伴可私聊,接项目定制。

1.简介
随着科技的不断发展,人工智能技术在各个领域得到广泛应用。其中,计算机视觉是人工智能领域中的一个重要分支,它主要研究如何使机器“看”和“理解”图像或视频。在计算机视觉领域,目标检测是一个关键问题,它涉及识别图像或视频中的特定对象,并确定它们的位置。火灾检测作为目标检测的一个重要应用领域,对于及时发现火灾、减少人员伤亡和财产损失具有重要意义。
本项目旨在基于YOLOv5和YOLOv8这两个先进的目标检测模型,开展火灾检测的研究和应用。YOLO(You Only Look Once)是一种实时目标检测算法,它将目标检测任务转化为一个回归问题,通过单次前向传递神经网络即可得到图像中所有目标的类别和位置。YOLOv5是YOLO系列中的最新版本,它在精度和速度之间取得了很好的平衡,被广泛应用于各种实时目标检测任务。
在本项目中,我们将探讨火灾检测领域的挑战和需求,介绍YOLOv5和YOLOv8的基本原理和算法结构,以及在实际火灾检测场景中的应用。通过本项目的研究,我们希望能够为提高火灾检测的准确性和效率,保障人们的生命财产安全,做出积极贡献。
希望本项目能够为火灾检测领域的研究和实际应用提供有益的参考和启示,推动人工智能技术在火灾安全领域的进一步发展和应用。
2.YOLO算法
YOLO(You Only Look Once)是一种高效的实时目标检测算法,它将目标检测任务转化为一个回归问题,通过单次前向传递神经网络即可得到图像中所有目标的类别和位置。相较于传统的目标检测方法,YOLO具有更快的速度和较高的准确性,使其成为计算机视觉领域中的重要算法之一。
YOLO算法的基本思想是将输入图像划分为一个固定大小的网格(grid),每个网格负责预测图像中是否包含目标以及目标的位置和类别。与传统的滑动窗口方法不同,YOLO将目标检测任务转化为一个回归问题,同时预测所有目标的位置和类别,避免了重复计算,因此速度更快。
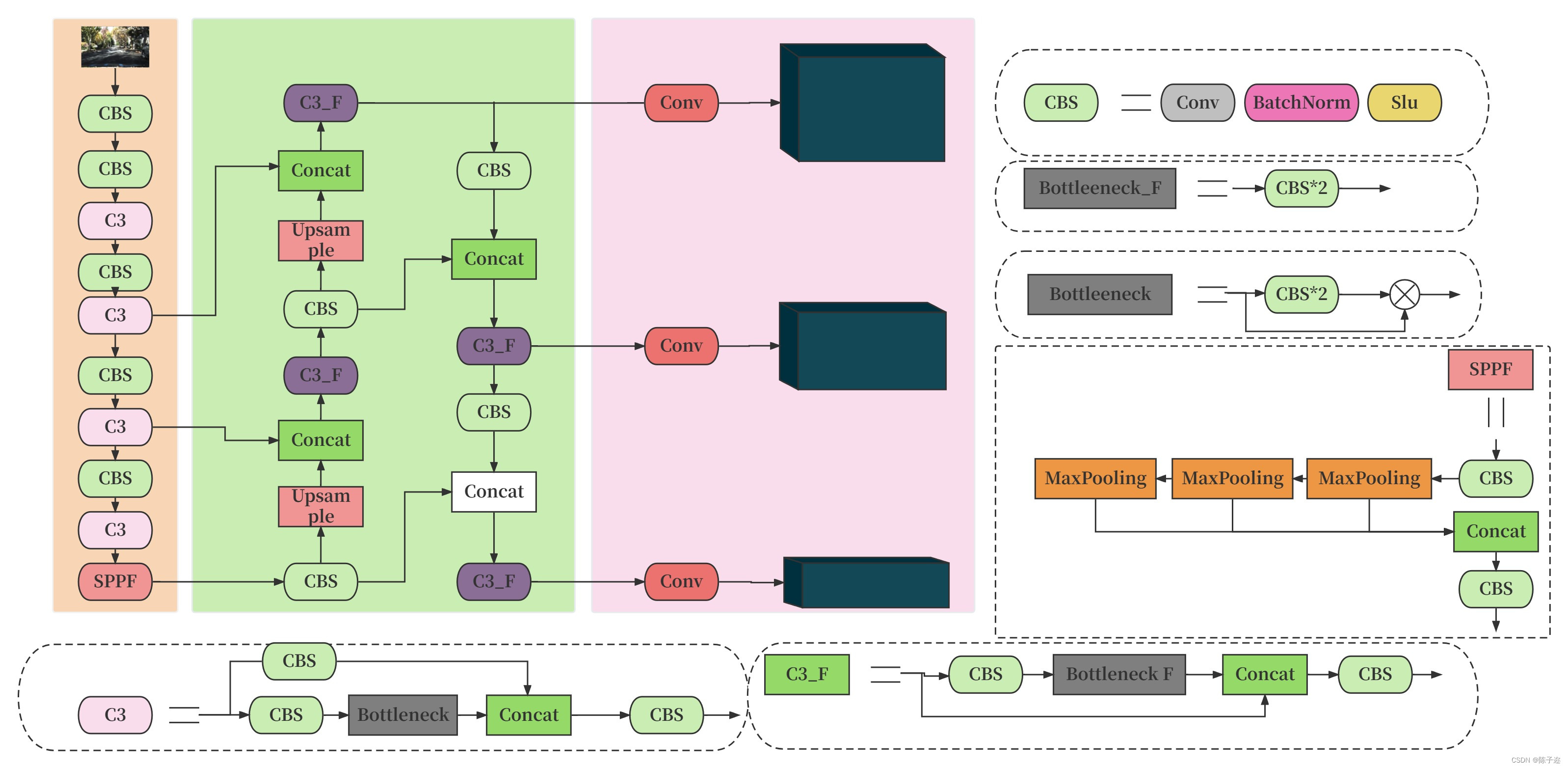
以下是YOLO算法的主要特点和步骤:
-
划分网格: 将输入图像划分为SxS个网格,每个网格负责预测该网格内是否包含目标。
-
预测框和类别: 每个网格预测B个边界框(bounding boxes)以及每个边界框的置信度(confidence)和类别概率。置信度表示边界框的准确性,类别概率表示目标属于不同类别的概率。
-
计算损失函数: YOLO使用多任务损失函数,包括边界框坐标的回归损失、置信度的损失(包括目标是否存在的损失和目标位置的精度损失)、类别概率的损失。通过最小化这些损失,网络可以学习到准确的目标位置和类别信息。
-
非极大值抑制(NMS): 在预测结果中,可能存在多个边界框对同一个目标的重复检测。为了去除这些重叠的边界框,使用NMS算法来选择具有最高置信度的边界框,并消除与其IoU(交并比)高于阈值的其他边界框。
-
输出结果: 最终,YOLO输出图像中所有目标的位置和类别信息,以及它们的置信度分数。
YOLO的优势在于它的速度和准确性,它能够实时处理高分辨率的图像,并且在不同尺度和大小的目标上具有很好的泛化能力。这使得YOLO广泛应用于实时目标检测、视频分析、自动驾驶等领域。
3.基于YOLOv5、YOLOv8的火灾检测
部分代码展示
gui界面主代码
from PyQt5.QtWidgets import QApplication, QMainWindow, QFileDialog, QMenu, QAction
from main_win.win import Ui_mainWindow
from PyQt5.QtCore import Qt, QPoint, QTimer, QThread, pyqtSignal
from PyQt5.QtGui import QImage, QPixmap, QPainter, QIcon
import sys
import os
import json
import numpy as np
import torch
import torch.backends.cudnn as cudnn
import os
import time
import cv2
from models.experimental import attempt_load
from utils.datasets import LoadImages, LoadWebcam
from utils.CustomMessageBox import MessageBox
# LoadWebcam 的最后一个返回值改为 self.cap
from utils.general import check_img_size, check_requirements, check_imshow, colorstr, non_max_suppression, \
apply_classifier, scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path, save_one_box
from utils.plots import colors, plot_one_box, plot_one_box_PIL
from utils.torch_utils import select_device, load_classifier, time_sync
from utils.capnums import Camera
from dialog.rtsp_win import Window
class DetThread(QThread):
send_img = pyqtSignal(np.ndarray)
send_raw = pyqtSignal(np.ndarray)
send_statistic = pyqtSignal(dict)
# 发送信号:正在检测/暂停/停止/检测结束/错误报告
send_msg = pyqtSignal(str)
send_percent = pyqtSignal(int)
send_fps = pyqtSignal(str)
def __init__(self):
super(DetThread, self).__init__()
self.weights = './yolov5s.pt' # 设置权重
self.current_weight = './yolov5s.pt' # 当前权重
self.source = '0' # 视频源
self.conf_thres = 0.25 # 置信度
self.iou_thres = 0.45 # iou
self.jump_out = False # 跳出循环
self.is_continue = True # 继续/暂停
self.percent_length = 1000 # 进度条
self.rate_check = True # 是否启用延时
self.rate = 100 # 延时HZ
self.save_fold = './result' # 保存文件夹
@torch.no_grad()
def run(self,
imgsz=640, # inference size (pixels)
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=True, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project='runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
):
# Initialize
try:
device = select_device(device)
half &= device.type != 'cpu' # half precision only supported on CUDA
# Load model
model = attempt_load(self.weights, map_location=device) # load FP32 model
num_params = 0
for param in model.parameters():
num_params += param.numel()
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check image size
names = model.module.names if hasattr(model, 'module') else model.names # get class names
if half:
model.half() # to FP16
# Dataloader
if self.source.isnumeric() or self.source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://')):
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadWebcam(self.source, img_size=imgsz, stride=stride)
# bs = len(dataset) # batch_size
else:
dataset = LoadImages(self.source, img_size=imgsz, stride=stride)
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
count = 0
# 跳帧检测
jump_count = 0
start_time = time.time()
dataset = iter(dataset)
while True:
# 手动停止
if self.jump_out:
self.vid_cap.release()
self.send_percent.emit(0)
self.send_msg.emit('停止')
if hasattr(self, 'out'):
self.out.release()
break
# 临时更换模型
if self.current_weight != self.weights:
# Load model
model = attempt_load(self.weights, map_location=device) # load FP32 model
num_params = 0
for param in model.parameters():
num_params += param.numel()
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check image size
names = model.module.names if hasattr(model, 'module') else model.names # get class names
if half:
model.half() # to FP16
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
self.current_weight = self.weights
# 暂停开关
if self.is_continue:
path, img, im0s, self.vid_cap = next(dataset)
# jump_count += 1
# if jump_count % 5 != 0:
# continue
count += 1
# 每三十帧刷新一次输出帧率
if count % 30 == 0 and count >= 30:
fps = int(30/(time.time()-start_time))
self.send_fps.emit('fps:'+str(fps))
start_time = time.time()
if self.vid_cap:
percent = int(count/self.vid_cap.get(cv2.CAP_PROP_FRAME_COUNT)*self.percent_length)
self.send_percent.emit(percent)
else:
percent = self.percent_length
statistic_dic = {name: 0 for name in names}
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
pred = model(img, augment=augment)[0]
# Apply NMS
pred = non_max_suppression(pred, self.conf_thres, self.iou_thres, classes, agnostic_nms, max_det=max_det)
# Process detections
for i, det in enumerate(pred): # detections per image
im0 = im0s.copy()
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Write results
for *xyxy, conf, cls in reversed(det):
c = int(cls) # integer class
statistic_dic[names[c]] += 1
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
# im0 = plot_one_box_PIL(xyxy, im0, label=label, color=colors(c, True), line_thickness=line_thickness) # 中文标签画框,但是耗时会增加
plot_one_box(xyxy, im0, label=label, color=colors(c, True),
line_thickness=line_thickness)
# 控制视频发送频率
if self.rate_check:
time.sleep(1/self.rate)
self.send_img.emit(im0)
self.send_raw.emit(im0s if isinstance(im0s, np.ndarray) else im0s[0])
self.send_statistic.emit(statistic_dic)
# 如果自动录制
if self.save_fold:
os.makedirs(self.save_fold, exist_ok=True) # 路径不存在,自动保存
# 如果输入是图片
if self.vid_cap is None:
save_path = os.path.join(self.save_fold,
time.strftime('%Y_%m_%d_%H_%M_%S',
time.localtime()) + '.jpg')
cv2.imwrite(save_path, im0)
else:
if count == 1: # 第一帧时初始化录制
# 以视频原始帧率进行录制
ori_fps = int(self.vid_cap.get(cv2.CAP_PROP_FPS))
if ori_fps == 0:
ori_fps = 25
# width = int(self.vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
# height = int(self.vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
width, height = im0.shape[1], im0.shape[0]
save_path = os.path.join(self.save_fold, time.strftime('%Y_%m_%d_%H_%M_%S', time.localtime()) + '.mp4')
self.out = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*"mp4v"), ori_fps,
(width, height))
self.out.write(im0)
if percent == self.percent_length:
print(count)
self.send_percent.emit(0)
self.send_msg.emit('检测结束')
if hasattr(self, 'out'):
self.out.release()
# 正常跳出循环
break
except Exception as e:
self.send_msg.emit('%s' % e)YOLOv5主代码
"""Train a YOLOv5 model on a custom dataset
Usage:
$ python path/to/train.py --data coco128.yaml --weights yolov5s.pt --img 640
"""
import argparse
import logging
import os
import random
import sys
import time
import warnings
from copy import deepcopy
from pathlib import Path
from threading import Thread
import math
import numpy as np
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
import torch.utils.data
import yaml
from torch.cuda import amp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdm
FILE = Path(__file__).absolute()
sys.path.append(FILE.parents[0].as_posix()) # add yolov5/ to path
import val # for end-of-epoch mAP
from models.experimental import attempt_load
from models.yolo import Model
from utils.autoanchor import check_anchors
from utils.datasets import create_dataloader
from utils.general import labels_to_class_weights, increment_path, labels_to_image_weights, init_seeds, \
strip_optimizer, get_latest_run, check_dataset, check_file, check_git_status, check_img_size, \
check_requirements, print_mutation, set_logging, one_cycle, colorstr
from utils.google_utils import attempt_download
from utils.loss import ComputeLoss
from utils.plots import plot_images, plot_labels, plot_results, plot_evolution
from utils.torch_utils import ModelEMA, select_device, intersect_dicts, torch_distributed_zero_first, de_parallel
from utils.wandb_logging.wandb_utils import WandbLogger, check_wandb_resume
from utils.metrics import fitness
LOGGER = logging.getLogger(__name__)
LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
RANK = int(os.getenv('RANK', -1))
WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
def train(hyp, # path/to/hyp.yaml or hyp dictionary
opt,
device,
):
save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, = \
opt.save_dir, opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
opt.resume, opt.noval, opt.nosave, opt.workers
# Directories
save_dir = Path(save_dir)
wdir = save_dir / 'weights'
wdir.mkdir(parents=True, exist_ok=True) # make dir
last = wdir / 'last.pt'
best = wdir / 'best.pt'
results_file = save_dir / 'results.txt'
# Hyperparameters
if isinstance(hyp, str):
with open(hyp) as f:
hyp = yaml.safe_load(f) # load hyps dict
LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
# Save run settings
with open(save_dir / 'hyp.yaml', 'w') as f:
yaml.safe_dump(hyp, f, sort_keys=False)
with open(save_dir / 'opt.yaml', 'w') as f:
yaml.safe_dump(vars(opt), f, sort_keys=False)
# Configure
plots = not evolve # create plots
cuda = device.type != 'cpu'
init_seeds(1 + RANK)
with open(data) as f:
data_dict = yaml.safe_load(f) # data dict
# Loggers
loggers = {'wandb': None, 'tb': None} # loggers dict
if RANK in [-1, 0]:
# TensorBoard
if not evolve:
prefix = colorstr('tensorboard: ')
LOGGER.info(f"{prefix}Start with 'tensorboard --logdir {opt.project}', view at http://localhost:6006/")
loggers['tb'] = SummaryWriter(str(save_dir))
# W&B
opt.hyp = hyp # add hyperparameters
run_id = torch.load(weights).get('wandb_id') if weights.endswith('.pt') and os.path.isfile(weights) else None
run_id = run_id if opt.resume else None # start fresh run if transfer learning
wandb_logger = WandbLogger(opt, save_dir.stem, run_id, data_dict)
loggers['wandb'] = wandb_logger.wandb
if loggers['wandb']:
data_dict = wandb_logger.data_dict
weights, epochs, hyp = opt.weights, opt.epochs, opt.hyp # may update weights, epochs if resuming
nc = 1 if single_cls else int(data_dict['nc']) # number of classes
names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
assert len(names) == nc, '%g names found for nc=%g dataset in %s' % (len(names), nc, data) # check
is_coco = data.endswith('coco.yaml') and nc == 80 # COCO dataset
# Model
pretrained = weights.endswith('.pt')
if pretrained:
with torch_distributed_zero_first(RANK):
weights = attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location=device) # load checkpoint
model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
state_dict = ckpt['model'].float().state_dict() # to FP32
state_dict = intersect_dicts(state_dict, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(state_dict, strict=False) # load
LOGGER.info('Transferred %g/%g items from %s' % (len(state_dict), len(model.state_dict()), weights)) # report
else:
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
with torch_distributed_zero_first(RANK):
check_dataset(data_dict) # check
train_path = data_dict['train']
val_path = data_dict['val']
# Freeze
freeze = [] # parameter names to freeze (full or partial)
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
print('freezing %s' % k)
v.requires_grad = False
# Optimizer
nbs = 64 # nominal batch size
accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
LOGGER.info(f"Scaled weight_decay = {hyp['weight_decay']}")
pg0, pg1, pg2 = [], [], [] # optimizer parameter groups
for k, v in model.named_modules():
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter):
pg2.append(v.bias) # biases
if isinstance(v, nn.BatchNorm2d):
pg0.append(v.weight) # no decay
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter):
pg1.append(v.weight) # apply decay
if opt.adam:
optimizer = optim.Adam(pg0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
else:
optimizer = optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
optimizer.add_param_group({'params': pg1, 'weight_decay': hyp['weight_decay']}) # add pg1 with weight_decay
optimizer.add_param_group({'params': pg2}) # add pg2 (biases)
LOGGER.info('Optimizer groups: %g .bias, %g conv.weight, %g other' % (len(pg2), len(pg1), len(pg0)))
del pg0, pg1, pg2
# Scheduler https://arxiv.org/pdf/1812.01187.pdf
# https://pytorch.org/docs/stable/_modules/torch/optim/lr_scheduler.html#OneCycleLR
if opt.linear_lr:
lf = lambda x: (1 - x / (epochs - 1)) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
else:
lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
# plot_lr_scheduler(optimizer, scheduler, epochs)
# EMA
ema = ModelEMA(model) if RANK in [-1, 0] else None
# Resume
start_epoch, best_fitness = 0, 0.0
if pretrained:
# Optimizer
if ckpt['optimizer'] is not None:
optimizer.load_state_dict(ckpt['optimizer'])
best_fitness = ckpt['best_fitness']
# EMA
if ema and ckpt.get('ema'):
ema.ema.load_state_dict(ckpt['ema'].float().state_dict())
ema.updates = ckpt['updates']
# Results
if ckpt.get('training_results') is not None:
results_file.write_text(ckpt['training_results']) # write results.txt
# Epochs
start_epoch = ckpt['epoch'] + 1
if resume:
assert start_epoch > 0, '%s training to %g epochs is finished, nothing to resume.' % (weights, epochs)
if epochs < start_epoch:
LOGGER.info('%s has been trained for %g epochs. Fine-tuning for %g additional epochs.' %
(weights, ckpt['epoch'], epochs))
epochs += ckpt['epoch'] # finetune additional epochs
del ckpt, state_dict
# Image sizes
gs = max(int(model.stride.max()), 32) # grid size (max stride)
nl = model.model[-1].nl # number of detection layers (used for scaling hyp['obj'])
imgsz = check_img_size(opt.imgsz, gs) # verify imgsz is gs-multiple
# DP mode
if cuda and RANK == -1 and torch.cuda.device_count() > 1:
logging.warning('DP not recommended, instead use torch.distributed.run for best DDP Multi-GPU results.\n'
'See Multi-GPU Tutorial at https://github.com/ultralytics/yolov5/issues/475 to get started.')
model = torch.nn.DataParallel(model)
# SyncBatchNorm
if opt.sync_bn and cuda and RANK != -1:
raise Exception('can not train with --sync-bn, known issue https://github.com/ultralytics/yolov5/issues/3998')
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
LOGGER.info('Using SyncBatchNorm()')
# Trainloader
train_loader, dataset = create_dataloader(train_path, imgsz, batch_size // WORLD_SIZE, gs, single_cls,
hyp=hyp, augment=True, cache=opt.cache_images, rect=opt.rect, rank=RANK,
workers=workers, image_weights=opt.image_weights, quad=opt.quad,
prefix=colorstr('train: '))
mlc = np.concatenate(dataset.labels, 0)[:, 0].max() # max label class
nb = len(train_loader) # number of batches
assert mlc < nc, 'Label class %g exceeds nc=%g in %s. Possible class labels are 0-%g' % (mlc, nc, data, nc - 1)
# Process 0
if RANK in [-1, 0]:
val_loader = create_dataloader(val_path, imgsz, batch_size // WORLD_SIZE * 2, gs, single_cls,
hyp=hyp, cache=opt.cache_images and not noval, rect=True, rank=-1,
workers=workers, pad=0.5,
prefix=colorstr('val: '))[0]
if not resume:
labels = np.concatenate(dataset.labels, 0)
# c = torch.tensor(labels[:, 0]) # classes
# cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency
# model._initialize_biases(cf.to(device))
if plots:
plot_labels(labels, names, save_dir, loggers)
# Anchors
if not opt.noautoanchor:
check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
model.half().float() # pre-reduce anchor precision
# DDP mode
if cuda and RANK != -1:
model = DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
# Model parameters
hyp['box'] *= 3. / nl # scale to layers
hyp['cls'] *= nc / 80. * 3. / nl # scale to classes and layers
hyp['obj'] *= (imgsz / 640) ** 2 * 3. / nl # scale to image size and layers
hyp['label_smoothing'] = opt.label_smoothing
model.nc = nc # attach number of classes to model
model.hyp = hyp # attach hyperparameters to model
model.gr = 1.0 # iou loss ratio (obj_loss = 1.0 or iou)
model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
model.names = names
# Start training
t0 = time.time()
nw = max(round(hyp['warmup_epochs'] * nb), 1000) # number of warmup iterations, max(3 epochs, 1k iterations)
# nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
last_opt_step = -1
maps = np.zeros(nc) # mAP per class
results = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
scheduler.last_epoch = start_epoch - 1 # do not move
scaler = amp.GradScaler(enabled=cuda)
compute_loss = ComputeLoss(model) # init loss class
LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'
f'Using {train_loader.num_workers} dataloader workers\n'
f'Logging results to {save_dir}\n'
f'Starting training for {epochs} epochs...')
for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
model.train()
# Update image weights (optional)
if opt.image_weights:
# Generate indices
if RANK in [-1, 0]:
cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
# Broadcast if DDP
if RANK != -1:
indices = (torch.tensor(dataset.indices) if RANK == 0 else torch.zeros(dataset.n)).int()
dist.broadcast(indices, 0)
if RANK != 0:
dataset.indices = indices.cpu().numpy()
# Update mosaic border
# b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
# dataset.mosaic_border = [b - imgsz, -b] # height, width borders
mloss = torch.zeros(4, device=device) # mean losses
if RANK != -1:
train_loader.sampler.set_epoch(epoch)
pbar = enumerate(train_loader)
LOGGER.info(('\n' + '%10s' * 8) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'total', 'labels', 'img_size'))
if RANK in [-1, 0]:
pbar = tqdm(pbar, total=nb) # progress bar
optimizer.zero_grad()
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
ni = i + nb * epoch # number integrated batches (since train start)
imgs = imgs.to(device, non_blocking=True).float() / 255.0 # uint8 to float32, 0-255 to 0.0-1.0
# Warmup
if ni <= nw:
xi = [0, nw] # x interp
# model.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
for j, x in enumerate(optimizer.param_groups):
# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])
if 'momentum' in x:
x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
# Multi-scale
if opt.multi_scale:
sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # size
sf = sz / max(imgs.shape[2:]) # scale factor
if sf != 1:
ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
imgs = F.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
# Forward
with amp.autocast(enabled=cuda):
pred = model(imgs) # forward
loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
if RANK != -1:
loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
if opt.quad:
loss *= 4.
# Backward
scaler.scale(loss).backward()
# Optimize
if ni - last_opt_step >= accumulate:
scaler.step(optimizer) # optimizer.step
scaler.update()
optimizer.zero_grad()
if ema:
ema.update(model)
last_opt_step = ni
# Print
if RANK in [-1, 0]:
mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
mem = '%.3gG' % (torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0) # (GB)
s = ('%10s' * 2 + '%10.4g' * 6) % (
f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1])
pbar.set_description(s)
# Plot
if plots and ni < 3:
f = save_dir / f'train_batch{ni}.jpg' # filename
Thread(target=plot_images, args=(imgs, targets, paths, f), daemon=True).start()
if loggers['tb'] and ni == 0: # TensorBoard
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress jit trace warning
loggers['tb'].add_graph(torch.jit.trace(de_parallel(model), imgs[0:1], strict=False), [])
elif plots and ni == 10 and loggers['wandb']:
wandb_logger.log({'Mosaics': [loggers['wandb'].Image(str(x), caption=x.name) for x in
save_dir.glob('train*.jpg') if x.exists()]})
# end batch ------------------------------------------------------------------------------------------------
# Scheduler
lr = [x['lr'] for x in optimizer.param_groups] # for loggers
scheduler.step()
# DDP process 0 or single-GPU
if RANK in [-1, 0]:
# mAP
ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'gr', 'names', 'stride', 'class_weights'])
final_epoch = epoch + 1 == epochs
if not noval or final_epoch: # Calculate mAP
wandb_logger.current_epoch = epoch + 1
results, maps, _ = val.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=ema.ema,
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
save_json=is_coco and final_epoch,
verbose=nc < 50 and final_epoch,
plots=plots and final_epoch,
wandb_logger=wandb_logger,
compute_loss=compute_loss)
# Write
with open(results_file, 'a') as f:
f.write(s + '%10.4g' * 7 % results + '\n') # append metrics, val_loss
# Log
tags = ['train/box_loss', 'train/obj_loss', 'train/cls_loss', # train loss
'metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95',
'val/box_loss', 'val/obj_loss', 'val/cls_loss', # val loss
'x/lr0', 'x/lr1', 'x/lr2'] # params
for x, tag in zip(list(mloss[:-1]) + list(results) + lr, tags):
if loggers['tb']:
loggers['tb'].add_scalar(tag, x, epoch) # TensorBoard
if loggers['wandb']:
wandb_logger.log({tag: x}) # W&B
# Update best mAP
fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
if fi > best_fitness:
best_fitness = fi
wandb_logger.end_epoch(best_result=best_fitness == fi)
# Save model
if (not nosave) or (final_epoch and not evolve): # if save
ckpt = {'epoch': epoch,
'best_fitness': best_fitness,
'training_results': results_file.read_text(),
'model': deepcopy(de_parallel(model)).half(),
'ema': deepcopy(ema.ema).half(),
'updates': ema.updates,
'optimizer': optimizer.state_dict(),
'wandb_id': wandb_logger.wandb_run.id if loggers['wandb'] else None}
# Save last, best and delete
torch.save(ckpt, last)
if best_fitness == fi:
torch.save(ckpt, best)
if loggers['wandb']:
if ((epoch + 1) % opt.save_period == 0 and not final_epoch) and opt.save_period != -1:
wandb_logger.log_model(last.parent, opt, epoch, fi, best_model=best_fitness == fi)
del ckpt
# end epoch ----------------------------------------------------------------------------------------------------
# end training -----------------------------------------------------------------------------------------------------
if RANK in [-1, 0]:
LOGGER.info(f'{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.\n')
if plots:
plot_results(save_dir=save_dir) # save as results.png
if loggers['wandb']:
files = ['results.png', 'confusion_matrix.png', *[f'{x}_curve.png' for x in ('F1', 'PR', 'P', 'R')]]
wandb_logger.log({"Results": [loggers['wandb'].Image(str(save_dir / f), caption=f) for f in files
if (save_dir / f).exists()]})
if not evolve:
if is_coco: # COCO dataset
for m in [last, best] if best.exists() else [last]: # speed, mAP tests
results, _, _ = val.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=attempt_load(m, device).half(),
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
save_json=True,
plots=False)
# Strip optimizers
for f in last, best:
if f.exists():
strip_optimizer(f) # strip optimizers
if loggers['wandb']: # Log the stripped model
loggers['wandb'].log_artifact(str(best if best.exists() else last), type='model',
name='run_' + wandb_logger.wandb_run.id + '_model',
aliases=['latest', 'best', 'stripped'])
wandb_logger.finish_run()
torch.cuda.empty_cache()
return results