概述
最近工作中有用到ES ,当然少不了自己装一个服务器捣鼓。本文的ElasticSearch 的版本:
7.17.3
一、下载 ElasticSearch
点此下载
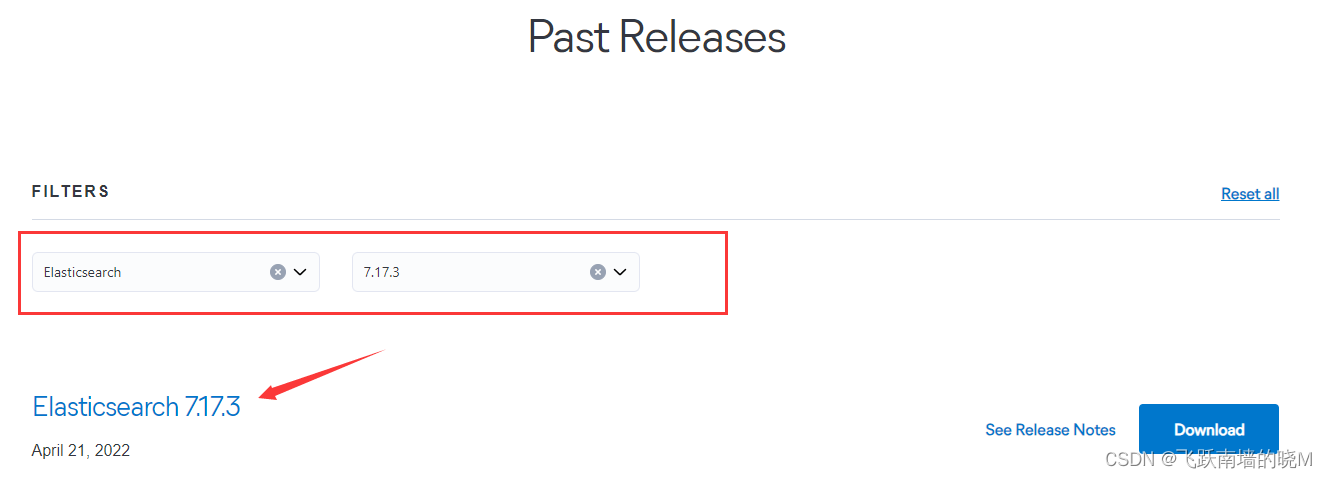

下载完成后上传至 Linux 服务器,本文演示放在: /root/ 下,进行解压:
tar -zxvf elasticsearch-7.17.3-linux-x86_64.tar.gz
二、配置 JDK 环境
ES比较耗内存,建议虚拟机4G或以上内存,jvm1g以上的内存分配。运行Elasticsearch,需安装并配置JDK。 各个版本对Java的依赖
Elasticsearch 7.0开始,内置了Java环境。ES的JDK环境变量生效的优先级配置顺序ES_JAVA_HOME>JAVA_HOME>ES_HOME :
ES_JAVA_HOME:这个环境变量用于指定Elasticsearch使用的Java运行时环境的路径。在启动Elasticsearch时,它会检查ES_JAVA_HOME环境变量并使用其中的Java路径。ES_HOME:这个环境变量指定Elasticsearch的安装路径。它用于定位Elasticsearch的配置文件、插件和其他相关资源。
设置ES_HOME环境变量可以让您在命令行中更方便地访问Elasticsearch的目录结构和文件。
vim /etc/profile
#设置ES_JAVA_HOME和ES_HOME的路径
export ES_JAVA_HOME=/root/elasticsearch-7.17.3/jdk/
export ES_HOME=/root/elasticsearch-7.17.3
# 保存并退出
#执行以下命令使配置生效
source /etc/profile
三、配置ElasticSearch
修改elasticsearch.yml配置:
cd /root/elasticsearch-7.17.3
vim config/elasticsearch.yml
#开启远程访问
network.host: 0.0.0.0
#单节点模式 初学者建议设置为此模式
discovery.type: single-node
注意:此文件为yml 格式的配置文件,键和值中间的冒号需要用英文,且中间需要用英文空格隔开,配置项的开头也要用空格隔开,否则在启动es 的时候会报错(如下)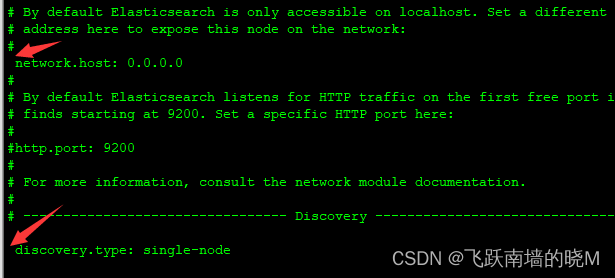
其它一些配置参考:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/important-settings.html
cluster.name
当前节点所属集群名称,多个节点如果要组成同一个集群,那么集群名称一定要配置成相同。默认值elasticsearch,生产环境建议根据ES集群的使用目的修改成合适的名字。不要在不同的环境中重用相同的集群名称,否则,节点可能会加入错误的集群。node.name
当前节点名称,默认值当前节点部署所在机器的主机名,所以如果一台机器上要起多个ES节点的话,需要通过配置该属性明确指定不同的节点名称。path.data
配置数据存储目录,比如索引数据等,默认值 $ES_HOME/data,生产环境下强烈建议部署到另外的安全目录,防止ES升级导致数据被误删除。path.logs
配置日志存储目录,比如运行日志和集群健康信息等,默认值 $ES_HOME/logs,生产环境下强烈建议部署到另外的安全目录,防止ES升级导致数据被误删除。bootstrap.memory_lock
配置ES启动时是否进行内存锁定检查,默认值true。
ES对于内存的需求比较大,一般生产环境建议配置大内存,如果内存不足,容易导致内存交换到磁盘,严重影响ES的性能。所以默认启动时进行相应大小内存的锁定,如果无法锁定则会启动失败。
非生产环境可能机器内存本身就很小,能够供给ES使用的就更小,如果该参数配置为true的话很可能导致无法锁定内存以致ES无法成功启动,此时可以修改为false。network.host
节点对外提供服务的地址以及集群内通信的ip地址,默认值为当前节点所在机器的本机回环地址127.0.0.1 和[::1],这就导致默认情况下只能通过当前节点所在主机访问当前节点。http.port
配置当前ES节点对外提供服务的http端口,默认 9200transport.port:
节点通信端口号,默认 9300discovery.seed_hosts
配置参与集群节点发现过程的主机列表,说白一点就是集群中所有节点所在的主机列表,可以是具体的IP地址,也可以是可解析的域名。cluster.initial_master_nodes
配置ES集群初始化时参与master选举的节点名称列表,必须与node.name配置的一致。ES集群首次构建完成后,应该将集群中所有节点的配置文件中的cluster.initial_master_nodes配置项移除,重启集群或者将新节点加入某个已存在的集群时切记不要设置该配置项。
四、修改 JVM 参数
修改es 目录下的 config/jvm.options 配置文件,调整 jvm 对内存大小
cd /root/elasticsearch-7.17.3
vim config/jvm.options
-Xms2g
-Xmx2g
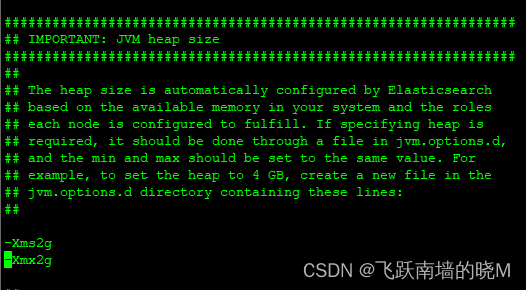
配置建议:
Xms 和 Xmx 设置成一样
Xmx 不要超过机器内存的 50%
不要超过 30GB
关于配置的说明
四、启动ElasticSearch服务
ES不允许使用root账号启动服务,如果你当前账号是root,则需要创建一个专有账户
创建 es 用户来启动es:
adduser es
passwd es
chown es:es -R /root/elasticsearch-7.17.3
# 切换用户
su es
#输入对应的密码
#启动 ElasticSearch, -d 为后台启动
bin/elasticsearch -d
五、启动ElasticSearch服务常见错误解决方案
- max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536] ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错:
#切换到root用户
vim /etc/security/limits.conf
末尾添加如下配置:
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
如下图所示: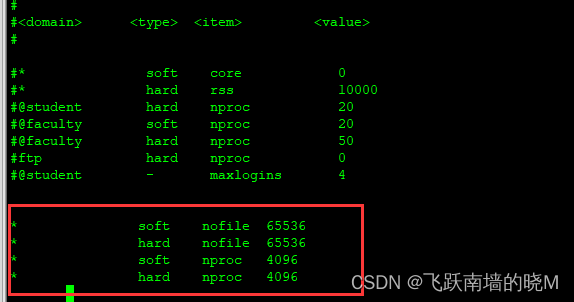
- max number of threads [1024] for user [es] is too low, increase to at least [4096] 无法创建本地线程问题,用户最大可创建线程数太小。解决办法:
vim /etc/security/limits.d/20-nproc.conf
# 改为如下配置:
* soft nproc 4096
- max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] 最大虚拟内存太小,调大系统的虚拟内存。解决办法:
vim /etc/sysctl.conf
#追加以下内容:
vm.max_map_count=262144
#保存退出之后执行如下命令:
sysctl -p
- the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured 缺少默认配置,至少需要配置discovery.seed_hosts/discovery.seed_providers/cluster.initial_master_nodes中的一个参数.
- discovery.seed_hosts: 集群主机列表
- discovery.seed_providers: 基于配置文件配置集群主机列表
- cluster.initial_master_nodes: 启动时初始化的参与选主的node,生产环境必填
解决方法:
vim config/elasticsearch.yml
#添加配置
discovery.seed_hosts: ["127.0.0.1"]
cluster.initial_master_nodes: ["node-1"]
#或者指定配置单节点(集群单节点)
discovery.type: single-node
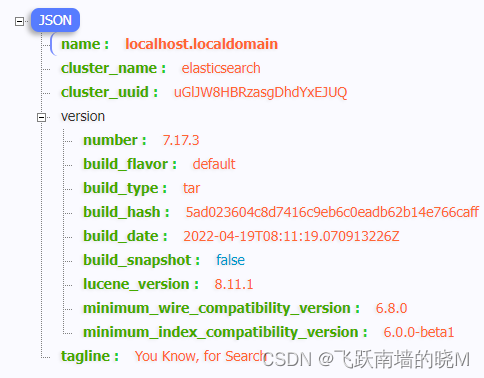
六、启动成功
使用 jps -mlvV 查看Java运行中的进程,看到ES 相关的进程,则标识启动成功!
jps -mlvV

浏览器访问:ip+端口如下: