星光下的赶路人star的个人主页
你生而真实,而非完美
文章目录
- 1、Flink SQL
- 1.1 SQL-Client准备
- 1.1.1 基于yarn-session模式
- 1.1.2 常用配置
- 1.2 流处理中的表
- 1.2.1 动态表和持续查询
- 1.2.2 将流转换为动态表
- 1.2.3 用SQL持续查询
- 1.2.4 将动态表转换为流
- 1.3 时间属性
- 1.3.1 事件时间
- 1.3.2 处理时间
- 1.4 DDL(Data Definition Language)数据定义
- 1.4.1 数据库
- 1.4.2 表
1、Flink SQL
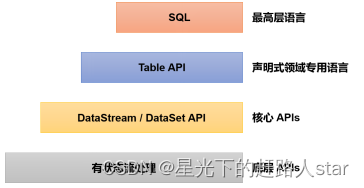
Table API和SQL是最上层的API,在Flink中这两种API被集成在一起,SQL执行的对象也是Flink中的表(Table),所以我们一般会认为它们是一体的。Flink是批流统一的处理框架,无论是批处理(DataSet API)还是流处理(DataStream API),在上层应用中都可以直接使用Table API或者SQL来实现;这两种API对于一张表执行相同的查询操作,得到的结果是完全一样的。我们主要还是以流处理应用为例进行讲解。
需要说明的是,Table API和SQL最初并不完善,在Flink 1.9版本合并阿里巴巴内部版本Blink之后发生了非常大的改变,此后也一直处在快速开发和完善的过程中,直到Flink 1.12版本才基本上做到了功能上的完善。而即使是在目前最新的1.17版本中,Table API和SQL也依然不算稳定,接口用法还在不停调整和更新。所以这部分希望大家重在理解原理和基本用法,具体的API调用可以随时关注官网的更新变化。
SQL API 是基于 SQL 标准的 Apache Calcite 框架实现的,可通过纯 SQL 来开发和运行一个Flink 任务。
1.1 SQL-Client准备
为了方便演示Flink SQL语法,主要使用Flink提供的sql-client进行操作。
1.1.1 基于yarn-session模式
1、启动Flink
/opt/module/flink-1.17.0/bin/yarn-session.sh -d
2、启动Flink的sql-client
/opt/module/flink-1.17.0/bin/sql-client.sh embedded -s yarn-session
1.1.2 常用配置
1、结果显示模式
#默认table,还可以设置为tableau、changelog
SET sql-client.execution.result-mode=tableau;
2、执行环境
SET execution.runtime-mode=streaming; #默认streaming,也可以设置batch
3、默认并行度
SET parallelism.default=1;
4、设置状态TTL
SET table.exec.state.ttl=1000;
5、通过sql文件初始化
(1)创建sql文件
vim conf/sql-client-init.sql
SET sql-client.execution.result-mode=tableau;
CREATE DATABASE mydatabase;
(2)启动时,指定sql文件
/opt/module/flink-1.17.0/bin/sql-client.sh embedded -s yarn-session -i conf/sql-client-init.sql
1.2 流处理中的表
我们可以将关系型表/SQL与流处理做一个对比,如表所示。
| 关系型表/SQL | 流处理 | |
|---|---|---|
| 处理的数据对象 | 字段元组的有界集合 | 字段元组的无限序列 |
| 查询(Query)对数据的访问 | 可以访问到完整的数据输入 | 无法访问到所有数据,必须“持续”等待流式输入 |
| 查询终止条件 | 生成固定大小的结果集后终止 | 永不停止,根据持续收到的数据不断更新查询结果 |
可以看到,其实关系型表和SQL,主要就是针对批处理设计的,这和流处理有着天生的隔阂。接下来我们就来深入探讨一下流处理中表的概念。
1.2.1 动态表和持续查询
流处理面对的数据是连续不断的,这导致了流处理中的“表”跟我们熟悉的关系型数据库中的表完全不同;而基于表执行的查询操作,也就有了新的含义。
1、动态表(Dynamic Tables)
当流中有新数据到来,初始的表中会插入一行;而基于这个表定义的SQL查询,就应该在之前的基础上更新结果。这样得到的表就会不断地动态变化,被称为“动态表”(Dynamic Tables)。
动态表是Flink在Table API和SQL中的核心概念,它为流数据处理提供了表和SQL支持。我们所熟悉的表一般用来做批处理,面向的是固定的数据集,可以认为是“静态表”;而动态表则完全不同,它里面的数据会随时间变化。
2、持续查询(Continuous Query)
动态表可以像静态的批处理表一样进行查询操作。由于数据在不断变化,因此基于它定义的SQL查询也不可能执行一次就得到最终结果。这样一来,我们对动态表的查询也就永远不会停止,一直在随着新数据的到来而继续执行。这样的查询就被称作“持续查询”(Continuous Query)。对动态表定义的查询操作,都是持续查询;而持续查询的结果也会是一个动态表。
由于每次数据到来都会触发查询操作,因此可以认为一次查询面对的数据集,就是当前输入动态表中收到的所有数据。这相当于是对输入动态表做了一个“快照”(snapshot),当作有限数据集进行批处理;流式数据的到来会触发连续不断的快照查询,像动画一样连贯起来,就构成了“持续查询”。

持续查询的步骤如下:
(1)流(stream)被转换为动态表(dynamic table);
(2)对动态表进行持续查询(continuous query),生成新的动态表;
(3)生成的动态表被转换成流。
这样,只要API将流和动态表的转换封装起来,我们就可以直接在数据流上执行SQL查询,用处理表的方式来做流处理了。
1.2.2 将流转换为动态表
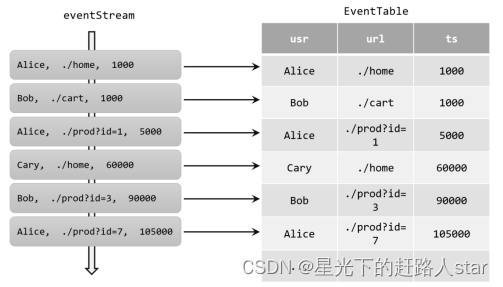
如果把流看作一张表,那么流中每个数据的到来,都应该看作是对表的一次插入(Insert)操作,会在表的末尾添加一行数据。因为流是连续不断的,而且之前的输出结果无法改变、只能在后面追加;所以我们其实是通过一个只有插入操作(insert-only)的更新日志(changelog)流,来构建一个表。
例如,当用户点击事件到来时,就对应着动态表中的一次插入(Insert)操作,每条数据就是表中的一行;随着插入更多的点击事件,得到的动态表将不断增长。
1.2.3 用SQL持续查询
1、更新(Update)查询
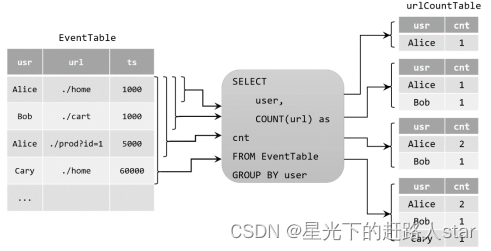
我们在代码中定义了一个SQL查询。
Table urlCountTable = tableEnv.sqlQuery("SELECT user, COUNT(url) as cnt FROM EventTable GROUP BY user");
当原始动态表不停地插入新的数据时,查询得到的urlCountTable会持续地进行更改。由于count数量可能会叠加增长,因此这里的更改操作可以是简单的插入(Insert),也可以是对之前数据的更新(Update)。这种持续查询被称为更新查询(Update Query),更新查询得到的结果表如果想要转换成DataStream,必须调用toChangelogStream()方法。
2、追加(Append)查询
上面的例子中,查询过程用到了分组聚合,结果表中就会产生更新操作。如果我们执行一个简单的条件查询,结果表中就会像原始表EventTable一样,只有插入(Insert)操作了。
Table aliceVisitTable = tableEnv.sqlQuery("SELECT url, user FROM EventTable WHERE user = 'Cary'");
这样的持续查询,就被称为追加查询(Append Query),它定义的结果表的更新日志(changelog)流中只有INSERT操作。
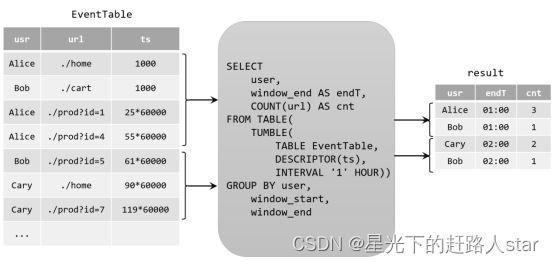
由于窗口的统计结果是一次性写入结果表的,所以结果表的更新日志流中只会包含插入INSERT操作,而没有更新UPDATE操作。所以这里的持续查询,依然是一个追加(Append)查询。结果表result如果转换成DataStream,可以直接调用toDataStream()方法。
1.2.4 将动态表转换为流
与关系型数据库中的表一样,动态表也可以通过插入(Insert)、更新(Update)和删除(Delete)操作,进行持续的更改。将动态表转换为流或将其写入外部系统时,就需要对这些更改操作进行编码,通过发送编码消息的方式告诉外部系统要执行的操作。在Flink中,Table API和SQL支持三种编码方式:
-
仅追加(Append-only)流
仅通过插入(Insert)更改来修改的动态表,可以直接转换为“仅追加”流。这个流中发出的数据,其实就是动态表中新增的每一行。 -
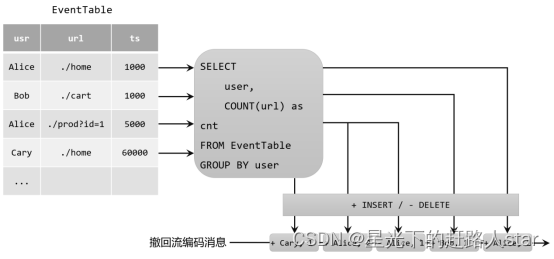
撤回(Retract)流
撤回流是包含两类消息的流,添加(add)消息和撤回(retract)消息。
具体的编码规则是:INSERT插入操作编码为add消息;DELETE删除操作编码为retract消息;而UPDATE更新操作则编码为被更改行的retract消息,和更新后行(新行)的add消息。这样,我们可以通过编码后的消息指明所有的增删改操作,一个动态表就可以转换为撤回流了。
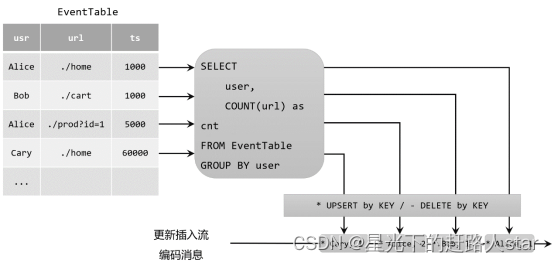
- 更新插入(Upsert)流
更新插入流中只包含两种类型的消息:更新插入(upsert)消息和删除(delete)消息。
所谓的“upsert”其实是“update”和“insert”的合成词,所以对于更新插入流来说,INSERT插入操作和UPDATE更新操作,统一被编码为upsert消息;而DELETE删除操作则被编码为delete消息。
需要注意的是,在代码里将动态表转换为DataStream时,只支持仅追加(append-only)和撤回(retract)流,我们调用toChangelogStream()得到的其实就是撤回流。而连接到外部系统时,则可以支持不同的编码方法,这取决于外部系统本身的特性。
1.3 时间属性
基于时间的操作(比如时间窗口),需要定义相关的时间语义和时间数据来源的信息。在Table API和SQL中,会给表单独提供一个逻辑上的时间字段,专门用来在表处理程序中指示时间。
所以所谓的时间属性(time attributes),其实就是每个表模式结构(schema)的一部分。它可以在创建表的DDL里直接定义为一个字段,也可以在DataStream转换成表时定义。一旦定义了时间属性,它就可以作为一个普通字段引用,并且可以在基于时间的操作中使用。
时间属性的数据类型必须为TIMESTAMP,它的行为类似于常规时间戳,可以直接访问并且进行计算。
按照时间语义的不同,可以把时间属性的定义分成事件时间(event time)和处理时间(processing time)两种情况。
1.3.1 事件时间
事件时间属性可以在创建表DDL中定义,增加一个字段,通过WATERMARK语句来定义事件时间属性。具体定义方式如下:
CREATE TABLE EventTable(
user STRING,
url STRING,
ts TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
...
);
这里我们把ts字段定义为事件时间属性,而且基于ts设置了5秒的水位线延迟。
时间戳类型必须是 TIMESTAMP 或者TIMESTAMP_LTZ 类型。但是时间戳一般都是秒或者是毫秒(BIGINT 类型),这种情况可以通过如下方式转换
ts BIGINT,
time_ltz AS TO_TIMESTAMP_LTZ(ts, 3),
1.3.2 处理时间
在定义处理时间属性时,必须要额外声明一个字段,专门用来保存当前的处理时间。
在创建表的DDL(CREATE TABLE语句)中,可以增加一个额外的字段,通过调用系统内置的PROCTIME()函数来指定当前的处理时间属性。
CREATE TABLE EventTable(
user STRING,
url STRING,
ts AS PROCTIME()
) WITH (
...
);
1.4 DDL(Data Definition Language)数据定义
1.4.1 数据库
1、创建数据库
(1)语法
CREATE DATABASE [IF NOT EXISTS] [catalog_name.]db_name
[COMMENT database_comment]
WITH (key1=val1, key2=val2, ...)
(2)案例
CREATE DATABASE db_flink;
2、查询数据库
(1)查询所有数据库
SHOW DATABASES
(2)查询当前数据库
SHOW CURRENT DATABASE
3、修改数据库
ALTER DATABASE [catalog_name.]db_name SET (key1=val1, key2=val2, ...)
4、删除数据库
DROP DATABASE [IF EXISTS] [catalog_name.]db_name [ (RESTRICT | CASCADE) ]
- RESTRICT:删除非空数据库会触发异常。默认启用
- CASCADE:删除非空数据库也会删除所有相关的表和函数。
DROP DATABASE db_flink2;
5、切换当前数据库
USE database_name;
1.4.2 表
1、创建表
(1)语法
CREATE TABLE [IF NOT EXISTS] [catalog_name.][db_name.]table_name
(
{ <physical_column_definition> | <metadata_column_definition> | <computed_column_definition> }[ , ...n]
[ <watermark_definition> ]
[ <table_constraint> ][ , ...n]
)
[COMMENT table_comment]
[PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
WITH (key1=val1, key2=val2, ...)
[ LIKE source_table [( <like_options> )] | AS select_query ]
① physical_column_definition
物理列是数据库中所说的常规列。其定义了物理介质中存储的数据中字段的名称、类型和顺序。其他类型的列可以在物理列之间声明,但不会影响最终的物理列的读取。
② metadata_column_definition
元数据列是 SQL 标准的扩展,允许访问数据源本身具有的一些元数据。元数据列由 METADATA 关键字标识。例如,我们可以使用元数据列从Kafka记录中读取和写入时间戳,用于基于时间的操作(这个时间戳不是数据中的某个时间戳字段,而是数据写入 Kafka 时,Kafka 引擎给这条数据打上的时间戳标记)。connector和format文档列出了每个组件可用的元数据字段。
CREATE TABLE MyTable (
`user_id` BIGINT,
`name` STRING,
`record_time` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka'
...
);
如果自定义的列名称和 Connector 中定义 metadata 字段的名称一样, FROM xxx 子句可省略
CREATE TABLE MyTable (
`user_id` BIGINT,
`name` STRING,
`timestamp` TIMESTAMP_LTZ(3) METADATA
) WITH (
'connector' = 'kafka'
...
);
如果自定义列的数据类型和 Connector 中定义的 metadata 字段的数据类型不一致,程序运行时会自动 cast强转,但是这要求两种数据类型是可以强转的。
CREATE TABLE MyTable (
`user_id` BIGINT,
`name` STRING,
-- 将时间戳强转为 BIGINT
`timestamp` BIGINT METADATA
) WITH (
'connector' = 'kafka'
...
);
默认情况下,Flink SQL planner 认为 metadata 列可以读取和写入。然而,在许多情况下,外部系统提供的只读元数据字段比可写字段多。因此,可以使用VIRTUAL关键字排除元数据列的持久化(表示只读)。
CREATE TABLE MyTable (
`timestamp` BIGINT METADATA,
`offset` BIGINT METADATA VIRTUAL,
`user_id` BIGINT,
`name` STRING,
) WITH (
'connector' = 'kafka'
...
);
③ computed_column_definition
计算列是使用语法column_name AS computed_column_expression生成的虚拟列。
计算列就是拿已有的一些列经过一些自定义的运算生成的新列,在物理上并不存储在表中,只能读不能写。列的数据类型从给定的表达式自动派生,无需手动声明。
CREATE TABLE MyTable (
`user_id` BIGINT,
`price` DOUBLE,
`quantity` DOUBLE,
`cost` AS price * quanitity
) WITH (
'connector' = 'kafka'
...
);
④ 定义Watermark
Flink SQL 提供了几种 WATERMARK 生产策略:
-
严格升序:WATERMARK FOR rowtime_column AS rowtime_column。
Flink 任务认为时间戳只会越来越大,也不存在相等的情况,只要相等或者小于之前的,就认为是迟到的数据。 -
递增:WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL ‘0.001’ SECOND 。
一般基本不用这种方式。如果设置此类,则允许有相同的时间戳出现。 -
有界无序: WATERMARK FOR rowtime_column AS rowtime_column – INTERVAL ‘string’ timeUnit 。
此类策略就可以用于设置最大乱序时间,假如设置为 WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL ‘5’ SECOND ,则生成的是运行 5s 延迟的Watermark。一般都用这种 Watermark 生成策略,此类 Watermark 生成策略通常用于有数据乱序的场景中,而对应到实际的场景中,数据都是会存在乱序的,所以基本都使用此类策略。
⑤ PRIMARY KEY
主键约束表明表中的一列或一组列是唯一的,并且它们不包含NULL值。主键唯一地标识表中的一行,只支持 not enforced。
CREATE TABLE MyTable (
`user_id` BIGINT,
`name` STRING,
PARYMARY KEY(user_id) not enforced
) WITH (
'connector' = 'kafka'
...
);
⑥ PARTITIONED BY
创建分区表
⑦ with语句
用于创建表的表属性,用于指定外部存储系统的元数据信息。配置属性时,表达式key1=val1的键和值都应该是字符串字面值。如下是Kafka的映射表:
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`name` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)
一般 with 中的配置项由 Flink SQL 的 Connector(链接外部存储的连接器) 来定义,每种 Connector 提供的with 配置项都是不同的。
⑧ LIKE
用于基于现有表的定义创建表。此外,用户可以扩展原始表或排除表的某些部分。
可以使用该子句重用(可能还会覆盖)某些连接器属性,或者向外部定义的表添加水印。
CREATE TABLE Orders (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3)
) WITH (
'connector' = 'kafka',
'scan.startup.mode' = 'earliest-offset'
);
CREATE TABLE Orders_with_watermark (
-- Add watermark definition
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
-- Overwrite the startup-mode
'scan.startup.mode' = 'latest-offset'
)
LIKE Orders;
⑨ AS select_statement(CTAS)
在一个create-table-as-select (CTAS)语句中,还可以通过查询的结果创建和填充表。CTAS是使用单个命令创建数据并向表中插入数据的最简单、最快速的方法。
CREATE TABLE my_ctas_table
WITH (
'connector' = 'kafka',
...
)
AS SELECT id, name, age FROM source_table WHERE mod(id, 10) = 0;
注意:CTAS有以下限制:
- 暂不支持创建临时表。
- 目前还不支持指定显式列。
- 还不支持指定显式水印。
- 目前还不支持创建分区表。
- 目前还不支持指定主键约束。
(2)简单建表示例
CREATE TABLE test(
id INT,
ts BIGINT,
vc INT
) WITH (
'connector' = 'print'
);
CREATE TABLE test1 (
`value` STRING
)
LIKE test;
2、查看表
(1)查看所有表
SHOW TABLES [ ( FROM | IN ) [catalog_name.]database_name ] [ [NOT] LIKE <sql_like_pattern> ]
如果没有指定数据库,则从当前数据库返回表。
LIKE子句中sql pattern的语法与MySQL方言的语法相同:
- %匹配任意数量的字符,甚至零字符,%匹配一个’%'字符。
- 只匹配一个字符,_只匹配一个’'字符
(2)查看表信息
{ DESCRIBE | DESC } [catalog_name.][db_name.]table_name
3、修改表
(1)修改表名
ALTER TABLE [catalog_name.][db_name.]table_name RENAME TO new_table_name
(2)修改属性
ALTER TABLE [catalog_name.][db_name.]table_name SET (key1=val1, key2=val2, ...)
4、删除表
DROP [TEMPORARY] TABLE [IF EXISTS] [catalog_name.][db_name.]table_name
![]()
您的支持是我创作的无限动力
![]()
希望我能为您的未来尽绵薄之力
![]()
如有错误,谢谢指正;若有收获,谢谢赞美