本系列的第1部分讨论了影响系统级密码性能的硬件和软件变量。现在,在第2部分中,我们将重点介绍两种用于测量高级后备加速器性能的方法:1)驱动器级加速器测试以识别加速器或SoC内存带宽约束,以及2)应用程序/协议堆栈级测试,其中包括完整的数据包入口到出口路径。点击领取嵌入式物联网学习路线
加速器测量方法论
测量后备加速器性能的最常见方法是驾驶员水平基准。在此测试中,一组测试数据被加载到承载加速器的SoC的主存储器中。
在SoC的CPU上运行的软件会创建描述符,否则会导致加速器对测试数据执行加密操作。使用计时器,驱动程序级别测试通过将处理的字节数除以花费的时间来计算加速器的吞吐量。
尽管这看起来很简单,但是本文第1部分中描述的许多变量仍然可以影响结果。在评估(或创建)驱动程序级别基准时,评估者需要考虑以下事项:
数据大小。该测试是否加密一小块或大块数据?数据大小越小,加速器的内存延迟,描述符大小和执行操作必须获取的其他“非数据”上下文以及计时器精度对结果的影响就越大。
了解内存延迟和读取上下文和数据的DMA开销很重要,但是在测量对一小块数据的单个操作的性能时,计时器分辨率可能是主要变量。
迭代。在较小的数据大小测量中包括加速器DMA开销和内存延迟,同时将计时器分辨率降低为变量的一种好方法是构造测试,以使计时器在迭代1之前启动,在第n次交互之后停止,其中n相当大数。
飞思卡尔通常使用50,000次迭代测试来测量驱动程序级别的性能。迭代可以引入其他变量,例如缓存,预工作,中断和检查。
1.缓存。 测试是否使用相同的密钥和上下文重复n次对相同的数据进行加密?还是用n个唯一密钥加密n个唯一的数据块?假设加速器在SoC的缓存一致性方案内运行(如果没有,请尽情玩!),重复加密相同的数据可能导致从片上缓存存储器而不是主存储器读取数据。飞思卡尔的驱动程序基准测试在5万个唯一的数据块上重复使用相同的密钥,从而在单个隧道数据包处理场景中模仿了加速器的行为。
2.前期工作和中断。 如果高级加速器迭代地加密50K唯一数据块,则意味着软件将构建并启动50K唯一描述符。两个主要变量,尤其是在小数据包大小时,是:软件何时构建描述符,何时将其分发给加速器?
优化的基准测试方案是让软件在创建测试数据的同时构建所有这些描述符,然后在计时器启动后立即将所有描述符分派给加速器。
软件不会通过轮询或中断来监视各个描述符的完成情况。它等待来自最终描述符的中断,并在中断服务程序中停止计时器。
第二种方法“在描述符n完成之后构建并分发描述符n + 1”,它更能代表实际的数据包处理方案。“立即分派”方法提供的数据量较小,性能比“描述符n完成后构建并分派描述符n + 1”大约好四倍。
与参考驱动程序一起提供的飞思卡尔驱动程序性能测试证明了后一种方法。这更代表了将驱动程序集成到包处理应用程序中。
3.检查。 驱动程序级别测试可能会检查每个描述符的输出,或者可能会假定输出始终良好。如果测试检查输出,则可以在计时器运行时进行这些检查,或者可以等待直到最终作业完成,然后返回并检查预期结果。在驾驶员测试中进行的检查越多,结果就越少反映出加速器的原始性能。
算法或密码套件。 数据大小和迭代方法是主要变量,但是驱动程序基准测试更多地关注真实的硬件性能,则在衡量的性能方面,越占优势的算法或密码套件就变得越发重要。
一些算法,甚至是算法模式,都具有比其他算法更高的原始性能。单遍解密+消息完整性检查可能比单遍加密+消息完整性生成更快。
下面的图1提供了使用“在描述符n完成之后构建和分配描述符n + 1”方法以及使用“一次性全部分配”方法的单个AES-HMAC-SHA-1基准对密码套件的比较。点击领取嵌入式物联网学习路线
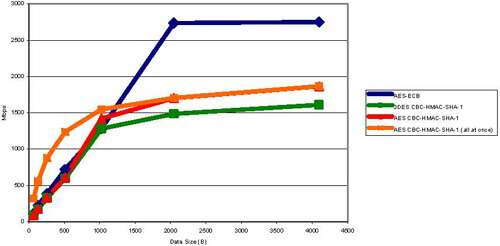
图1:驱动程序基准
图1显示,在较小的数据包大小下,所有“描述符n完成后构建和分配描述符n + 1”的结果几乎相同,因为描述符构建,调度和监视描述符完成的软件开销淹没了算法特定的性能差异。加速器。
仅在较大的数据大小时,硬件算法性能差异才成为可观察的变量。单个AES-HMAC-SHA-1测试(其中所有描述符都是预先构建的,并以加速器可以接受它们的最大速率进行分发)进行测试,在小数据量情况下,性能提高了大约四倍。但是,通过1KB数据大小,硬件的原始性能是主要变量。
对于供应商提供的基准代码的用户来说,在将结果与另一供应商的基准代码进行比较之前,了解基准代码的确切功能非常重要。
在更现实的用例中,不同的供应商可能具有不同的理念来显示几乎原始的加速器性能与加速器性能。
SoC测量方法
加速器基准测试强调加速器的性能及其通往系统内存的路径。SoC基准测试强调处理路径中所有元素的性能,包括网络接口,CPU,加速器和内存子系统。对于诸如PowerQUICC系列中的面向网络的SoC,重要的加密基准是IPsec数据包处理。
本文的第1部分描述了加密算法与完整安全协议(例如IPsec)之间的区别,以及软件变量(例如IPsec协议栈效率)和利用硬件加速的API的质量。
本节介绍了用于在同一设备上创建不同IPsec堆栈的规范化比较以及在不同设备上创建同一IPsec堆栈的比较的方法。
网络测试环境
RFC2544“网络互连设备的基准测试方法”描述了一系列用于网络系统标准化测试的方法。尽管RFC没有专门讨论IPsec,但它引入了许多重要的测试概念。
测试系统IPsec性能的最合乎逻辑的方法-被测设备(DUT)-可以将其连接到网络测试仪,如下图2所示。巧合的是,这种情况也是下面的RFC2544中的图2。
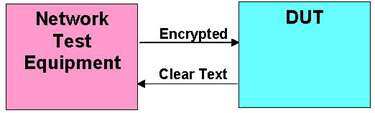
图2:IPsec测试选项1点击领取嵌入式物联网学习路线
使用此选项,测试仪将生成IPsec数据包,并将其发送到DUT,然后由DUT解密并将其发送回去。该过程也可以反向运行,以便也可以测量DUT在加密过程中的性能。
尽管这可能是衡量DUT的IPsec性能的最合乎逻辑的方法,但是由于支持高IPsec数据速率的网络测试仪的成本,这种设置很少使用。
尽管这种情况将来可能会改变,但具有加密加速功能的高级网络SoC通常具有比声称要测量它们的网络测试设备更高的IPsec性能。下面的图3(在RFC2544中也是图3)显示了测试IPsec的更好选择。

图3:IPsec测试选项2
在选项2中,在网关到网关配置中测试了IPsec。
1.网络测试仪将明文IP数据包从端口1传输到DUT 1(标记为Home)。
2. DUT 1 IPsec对数据包进行加密,然后将其发送到DUT 2(标记为Office)。3. DUT 2解密数据包,然后
4.将其转发回网络测试的端口2,从而使测试仪能够测量收到的数据包速率。
此过程可以双向运行,以便网络测试器的每个端口发送和接收明文数据包,如前面的图2所示。许多网络测试人员能够生成高速率的纯文本IP流量,从而使更多的用户可以重新创建使用此方法测得的基准。
由于所有数据包均已加密和解密,因此IPsec性能被报告为这两个操作中较慢的。还应注意,性能是根据明文数据包衡量的。
根据数据包大小,两个DUT之间的加密隧道内部测得的Mbps可能是网络测试仪报告的Mbps的近两倍。隧道内部数据包大小的增加还导致DUT之间的1 Gbps以太网链路以大约950 Mbps的速度饱和,而不是非加密以太网链路的大约990 Mbps。
IPsec测试的变化源
使用测量选项2,涵盖影响IPsec基准的所有潜在变量超出了这两个部分的范围。但是,有两个值得一提的相关测试选项:注入速率和可接受的丢失率。
注入速率是网络测试仪向DUT发送明文数据包的速率。可以将测试仪配置为淹没DUT(对于所有数据包大小,均以100%的线速传输),或者缓慢启动并逐渐增加注入速率,直到DUT开始丢弃数据包。
泛洪测试通常会产生比零丢失更好的IPsec基准,但是泛洪基准对用户的用处不大,因为大多数系统旨在实现给定的性能目标而不会丢弃大量数据包。那些零损失小包在地板上吗?
RFC2544没有可接受的丢失率的概念。零丢失测试意味着性能由DUT在一定时间间隔(通常为30-60秒)内转发数据包而不丢失任何数据包的速率定义。网络设备供应商在测试其最终系统时通常会忽略RFC2544的这一部分。
众所周知,独立的测试实验室(例如Tolly Group)使用可接受的丢包率<.001%来测量IPsec“零丢失”性能。=“” both =“” equipment =“”和=“” Embedded = “”处理器=“”供应商=“” have =“” =“ =” seen =“” to =“” report =“” loss =“”汇率=“” as =“” high =“” as =“” .1 =“” percent =“” as =“” zero =“” loss。=“”>
可接受的损失率对性能有重大影响。飞思卡尔报告了使用绝对零损耗和<.001%,=“” with =“” the =“”> <。001%=“” results =“”通常=“” 25 =“”的零损失IPsec结果。 percent =“” better =“”胜于=“” the =“”绝对=“”零=“”结果。=“”>
较高的可接受损失率会进一步改善结果。因为对于报告为零损失的基准,没有公认的可接受的损失率定义,因此在比较两个供应商提供的基准之前,准买家需要做一些额外的作业。
特定结果
现在,我们已经定义了变体和测试方法的硬件和软件来源,以帮助产生标准化的结果,本文现在着眼于飞思卡尔PowerQUICC处理器上的特定IPsec测量,以及这些结果如何说明前面讨论的一些概念。
如本系列该部分中的PowerQUICC性能图所示,系统性能受到CPU(对于小数据包)和Freescale集成安全引擎(SEC)对大数据包的限制,而内存总线性能同样会影响所有数据包大小的吞吐量。
竞争对手产品的公开性能曲线表明,它们的设备具有相同的基本原理,而PowerQUICC的出色IPsec性能(尤其是与优化的IPsec堆栈(如Mocana的NanoSec)搭配使用)是由更高性能的CPU组合而成的,效率更高单通加密加速核心以及更宽,更快,有效的流水线总线。
所有性能图均使用Smartbits SMB600作为数据包生成器和数据包计数器进行测量。Smartbits Terametrics模块以最大速率生成纯净的IPv4数据包,并将其传输到PowerQUICC板1的以太网端口之一。
PowerQUICC板1将数据包归类为IPsec会话,并使用3DES-HMAC-SHA-1执行ESP隧道封装,然后再将其转发到PowerQUICC板2的以太网端口之一。
PowerQUICC板2将数据包分类为属于要在板2上终止的IPsec ESP会话,并在将清除的IPv4数据包转发回Smartbits机器之前对数据包进行解封装/解密。
除非另有说明,否则所有显示的性能数字均反映每个PowerQUICC设备的合计双向IPsec数据包转发速率。选择3DES-HMAC-SHA-1作为此测量的密码套件,因为它仍然是最常用的IPsec密码套件。
对于SEC和其他加密加速器而言,这也是最坏情况的算法组合。在PowerQUICC中,除了最大的数据包外,3DES-HMAC-SHA-1和AES-HMAC-SHA-1之间的系统级性能差异可以忽略不计。
PowerQUICC II Pro平台上的基准测试
PowerQUICC II Pro MPC83xx系列集成通信处理器代表PowerQUICC产品线的低端产品。这些设备使用频率高达667 MHz的e300 Power Architecture处理器内核。
MPC83xx系列的某些成员使用SEC内核的简化功能版本(加速3DES,AES,HMAC MD5和SHA-1);其他的则具有功能齐全的SEC,它们还可以加速公钥,ARC-4和随机数的生成。
测量配置1。 下方的图4中显示的是第一个配置,其中包含MPC8313E PowerQUICC II Pro集成通信处理器,32位e300 Power Architecture内核,SEC 2.2和以下配置参数:
MPC8313E RDB
e300内核(333 MHz),DDR(333 MHz数据速率)和SEC(166 MHz)
OS:Linux 2.6.21
IPsec堆栈:StrongSwan,OpenSwan,Mocana NanoSec,均运行3DES-HMAC-SHA-1
该图表显示Mocana NanoSec IPsec堆栈(//mocana.com/NanoSec.html)在所有数据包大小下均具有更高的吞吐量。Mocana相对于OpenSwan的性能优势相对稳定,为1.7倍,而StrongSwan的优势始于1.6倍,但随着数据包大小的增加而增长至2.2倍。
OpenSwan和Mocana均异步运行,而StrongSwan一次处理一个数据包,并等待SEC完成处理后再继续。在较小的数据包大小时,StrongSwan的效率更高,并且由于轮询操作而避免了SEC中断,因此它的性能略优于OpenSwan,但在中等数据包大小时,OpenSwan会超过StrongSwan。
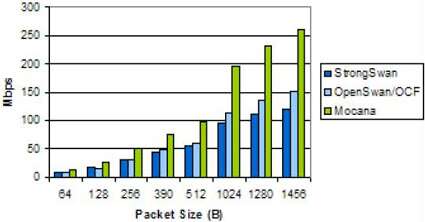
图4. MPC8313E IPsec性能点击领取嵌入式物联网学习路线
测量配置#2 。下面的图5显示了一个包含MPC8323E的测量配置平台的安全性能,该平台基于32位e300 Power Architecture内核和SEC 2.2,具有以下参数:
MPC8323E RDB
e300内核(333 MHz),DDR(266 MHz数据速率)和SEC(133 MHz)
OS:Linux 2.6.20.6
IPsec堆栈:NetKey,StrongSwan,OpenSwan,Mocana NanoSec,均运行3DES-HMAC-SHA-1
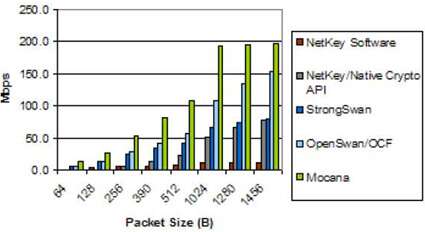
图5. MPC8323E IPsec性能
该图完整比较了最流行的开源IPsec堆栈和在同一Linux内核版本上运行的Mocana堆栈。比较中包括具有硬件和软件加密功能的Netkey性能。
与配置1中的MPC8313E一样,在所有数据包大小下,Mocana NanoSec IPsec堆栈都具有最高的吞吐量。同样,在最小的数据包大小下,StrongSwan略胜于OpenSwan,但随后落后于SEC的同步API阻止了处理器执行其他工作。
在中小型数据包大小上,与OpenSwan相比,Mocana的优势约为1.9倍。但是,在较大的数据包大小下,Mocana达到了200 Mbps的链路限制(使用两个10/100快速以太网接口进行双向测试),从而使OpenSwan看起来可以缩小差距。
在执行软件加密时,NetKey比OpenSwan效率更高。但是,Native Linux Crypto API与SEC的双通道,同步接口产生了如此高的开销,以至于具有硬件加速功能的NetKey比其他堆栈慢,甚至比具有较小数据包大小的具有软件加密的NetKey还要慢。
测量配置#3 。下图6所示为包含具有32位e300 Power Architecture内核的MPC8349A和SEC 2.4以及以下参数的配置的安全性测量性能:
MPC8349EA MDS
e300内核(666 MHz),DDR(333 MHz数据速率)和SEC(166 MHz)
OS:Linux 2.6.11
IPsec堆栈:StrongSwan,OpenSwan,Mocana,均运行3DES-HMAC-SHA-1
该图表将StrongSwan和OpenSwan与Mocana进行了比较。Mocana在所有数据包大小下均提供最高的吞吐量。与第二好的实施方案(在这种情况下为OpenSwan)相比,Mocana的性能优势约为1.3倍。
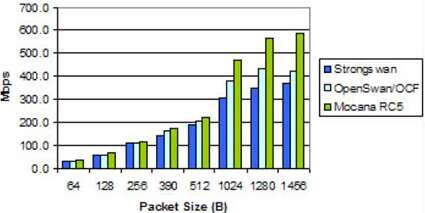
图6. MPC8349EA IPsec性能
测量配置#4 。下面的图7中显示了MPC8360E的安全性能,其中包含32位e300 Power Architecture内核和SEC 2.4。这些是参数:
MPC8360EA MDS
e300内核(666 MHz),DDR(333 MHz数据速率),QUICC Engine(500 MHz)和SEC(166 MHz)
OS:Linux 2.6.22
IPsec堆栈:StrongSwan(单向),Mocana(双向)运行3DES-HMAC-SHA-1
该图表将StrongSwan与Mocana进行了比较,并提供了CPU利用率信息。对于此特定设备,StrongSwan在最小的数据包大小上略胜于Mocana。这可能是由于测量差异(单向测试与双向测试)引起的。
对于IPv4转发,在64字节时的单向性能为142 Mbps与114 Mbps。这表明,如果双向测量StrongSwan IPsec性能,则Mocana的性能将优于StrongSwan,这与其他设备上的测量结果一致。
另一个不寻常的数据点是Mocana CPU利用率为1456字节。CPU利用率应该继续下降。CPU利用率是计算得出的数字,并且CRC或其他以太网错误可能超过.001%,从而降低了测量的吞吐量。由于在处理IPsec之后丢弃了以太网帧,因此CPU似乎比实际完成了更多的工作。

图7. MPC8360E IPsec性能
测量配置#5 。下面的图8中显示了MPC8379E PowerQUICC II Pro集成通信处理器的安全性能,该处理器包含32位e300 Power Architecture内核和SEC 3.0。这些是参数:
MPC8379E RDB
e300内核为666 MHz,DDR为333 MHz数据速率,SEC为110 MHz
操作系统:Linux 2.6.23
IPsec堆栈:OpenSwan,Mocana,均运行3DES-HMAC-SHA-1
该图表显示Mocana NanoSec IPsec堆栈在所有数据包大小下均具有更高的吞吐量。Mocana在OpenBwan上的性能优势约为64B时的1.4倍。在SEC开始成为性能限制器之前,此增量相对恒定,此时OCF弥补了这一差距。
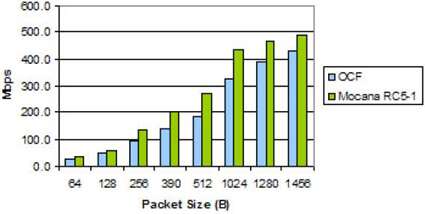
图8. MPC8379E IPsec性能点击领取嵌入式物联网学习路线
请注意,为了对OpenSwan和Mocana进行真正的“苹果到苹果”比较,使用了MPC8379RDB板,该板目前将SEC频率限制为110 MHz(与大多数其他83xx产品的166 MHz相比)。
在没有SEC频率限制的情况下,在另一块板上测量的OpenSwan数据显示,在所有数据包大小中,MPC8379E IPsec性能比图中结果提高了约13%,在大数据包大小时达到了约560 Mbps。可以合理地假设,如果SEC以166 MHz运行,那么在所有数据包大小下Mocana的结果也会好13%。
使用PowerQUICC III MBC 85xx系列进行
测量PowerQUICC III MPC85xx系列集成通信处理器代表PowerQUICC产品线的中高端。这些设备使用带有前端L2缓存的e500 Power Architecture处理器内核。e500内核的工作频率高达1.5 GHz。MPC85xx系列的所有成员都使用功能齐全的SEC。
测量配置1。 下面的图9中显示了MPC8544E和MPC8533E PowerQUICC III集成通信处理器的安全性能,这些处理器包含32位e500 Power Architecture内核和SEC 2.1。这些是参数:
MPC8544E CDS
e500内核为800 MHz,DDR为400 MHz数据速率,SEC为133 MHz
OS:Linux 2.6.23
IPsec堆栈:Mocana,运行3DES-HMAC-SHA-1
可用于MPC8544E的唯一IPsec结果来自Mocana,用于其商业NanoSec IPsec实现。请注意,MPC8544E中SEC的运行频率(相对于CPU)要低于其他85xx器件,因此,由于SEC饱和而导致的CPU利用率的降低要比其他器件更早开始。
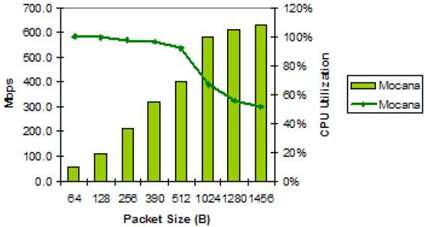
图9. MPC8544E IPsec性能
测量配置2。 下面的图10显示了MPC8555E和MPC8541E PowerQUICC III集成通信处理器的安全性能,这些处理器包含32位e500 Power Architecture内核和SEC 2.0。这些是参数:
MPC8555E CDS
e500内核(833 MHz),DDR(333 MHz数据速率)和SEC(166 MHz)
OS:StrongSwan Linux 2.4,Mocana Linux 2.6.11
IPsec堆栈:StrongSwan,Mocana,均运行3DES-HMAC-SHA-1
该图表将StrongSwan与Mocana进行了比较,并提供了CPU利用率信息。对于此特定设备,Mocana NanoSec在所有数据包大小方面均优于StrongSwan。Mocana CPU利用率随着数据包大小的增加而稳步下降,而StrongSwan由于其同步的轮询操作模式而在所有数据包大小下都消耗了100%的CPU。
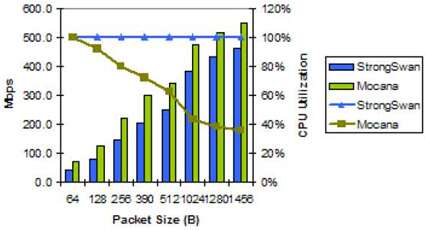
图10. MPC8555E IPsec性能
测量配置#3。 下面的图11显示了MPC8548E PowerQUICC III集成通信处理器的安全性能,该处理器包含32位e500 Power Architecture内核和SEC 2.1。这些是参数:
MPC8548E CDS
e500内核为1.33 GHz,DDR为533 MHz数据速率,SEC 2.1为266 MHz
OS:Linux 2.6.11
IPsec堆栈:Mocana,运行3DES-HMAC-SHA-1
该图表将OpenSwan与Mocana进行了比较,并添加了有关CPU利用率的信息。Mocana NanoSec在所有数据包大小下均提供最高的吞吐量,并开始以390字节的速度使SEC饱和。
随着数据包大小的增加,CPU利用率继续下降,并且在1456字节时,Mocana达到1057 Mbps,CPU利用率为38%。OpenSwan具有类似的配置文件;但是,它直到1024字节才使SEC饱和,并消耗了69%的CPU,同时在1456字节下达到了1057 Gbps。
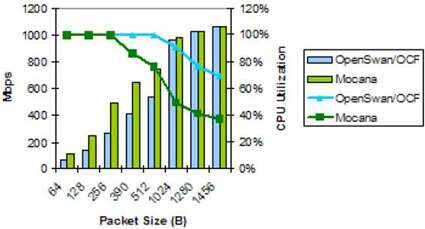
图11. MPC8548E IPsec性能
结束语
如本文中描述的示例配置所示,嵌入式通信处理器的安全性能在很大程度上取决于中小数据包大小的CPU的性能,而对于大数据包大小的加密硬件/内存总线的限制更大。
虽然此处通过各种PowerQUICC处理器家族成员的性能曲线说明了这一点,但对于使用通用CPU和后备加密加速功能的所有嵌入式通信处理器而言,都是如此。
使用更多类似NPU的处理引擎可以实现更高的性能;但是,这样做通常会导致灵活性降低,无论是绝对可编程性还是工具链支持。