这里写自定义目录标题
- elasticsearch简介
- 基本语法
- 索引
- 创建索引
- 修改索引
- 删除索引
- 查询
- 简单查询
- 精确查询
- 条件查询
- 范围查询:
- 聚合查询:
- 排序和分页:
- 参考文献:
elasticsearch简介
Elasticsearch 是一个开源的分布式搜索和分析引擎,基于 Apache Lucene 构建而成。它提供了一个快速、可扩展和分布式的全文搜索引擎,适用于各种类型的数据和用例。
以下是 Elasticsearch 的一些主要特点和功能:
-
分布式架构:Elasticsearch 使用分布式架构,可以在多个节点上存储和处理数据。它具有高可用性和容错性,可以自动处理节点故障和数据复制。
-
实时搜索和分析:Elasticsearch 提供了实时搜索和分析功能,可以快速地对大量数据进行搜索、过滤和聚合操作。它支持全文搜索、近实时的数据索引和分析,适用于日志分析、监控数据、电子商务等场景。
-
多种数据类型支持:Elasticsearch 支持多种数据类型,包括文本、数值、地理位置、日期等。它可以处理结构化和非结构化数据,并提供了丰富的查询语言和过滤器来处理不同类型的数据。
-
强大的查询语言:Elasticsearch 使用基于 JSON 的查询语言,可以进行复杂的查询和过滤操作。它支持全文搜索、模糊匹配、范围查询、聚合等功能,可以灵活地满足各种搜索需求。
-
可扩展性和高性能:Elasticsearch 具有良好的可扩展性,可以通过添加更多的节点来扩展存储和处理能力。它使用倒排索引和分布式搜索算法,提供了快速的搜索和分析性能。
-
插件生态系统:Elasticsearch 拥有丰富的插件生态系统,可以扩展其功能和集成其他工具。例如,可以使用插件来实现数据可视化、安全认证、数据同步等功能。
Elasticsearch 在许多领域都有广泛的应用,包括企业搜索、日志分析、电商推荐、监控和报告等。它易于使用、可扩展和高性能,成为了许多应用程序中的核心组件。
基本语法
Elasticsearch是一个分布式的RESTful 风格的搜索和数据分析引擎。
索引
ES的索引主要由3部分组成:
- mappings:描述索引的字段,以及字段的各种属性
- setting:描述该索引的全局配置,包括副本数、分片数等
- aliases:索引的别名。
mappings:在创建一个索引的时候,可以对 dynamic 进行设置,可以设成 false、true 或者 strict。
比如一个新的文档,这个文档包含一个字段,当 Dynamic 设置为 true 时,这个文档可以被索引进 ES,这个字段也可以被索引,也就是这个字段可以被搜索,Mapping 也同时被更新;当 dynamic 被设置为 false 时候,存在新增字段的数据写入,该数据可以被索引,但是新增字段被丢弃;当设置成 strict 模式时候,数据写入直接出错。
setting:用于定义索引的全局设置和配置,并非某一个字段的设置。
表的属性设置按是否可更改可分为:
- (static) 静态:创建后不能更改,它们只能在创建索引时或在关闭的索引上设置。
- (dynamic) 动态:创建后,可更改,可以使用 update-index-settings API 动态的在活动索引上更改它们。
主要属性如下:
| 属性名 | 类型 | 描述 |
|---|---|---|
| index.number_of_shards | 静态 | 指定索引的分片数。默认为5。 |
| index.shard.check_on_startup | 静态 | 当检查到分片损坏将禁止被打开。 |
| index.codec | 静态 | 默认值:default,是使用LZ4压缩算法,压缩存储的数据;可以设置成best_compression;它使用 DEFLATE 拥有更高的压缩比,但是存储性能将会降低。在修改压缩类型之后,在下次段合并的时候将会使用。 |
| index.routing_partition_size | 静态 | 可以路由的分片数量,同样只能在创建索引时指定,默认值为1.这个值必须小于number_of_shards(除非number_of_shards的值也是1) |
| index.load_fixed_bitset_filters_eagerly | 静态 | nestedquery的cache filter是否预加载,值为true(默认)、false |
| index.number_of_replicas | 动态 | 指定索引的副本数。默认为1。 |
| index.auto_expand_replicas | 动态 | 设置是否根据节点数量,自动扩展副本数量。 |
| index.refresh_interval | 动态 | 索引执行刷新的频率,默认30s |
alias:索引别名可以关联一个活多个索引。别名提供了一个可读性更好且易于管理的方式来引用索引,通过别名,可以在不影响应用程序的情况下,轻松切换、重命名或删除索引。
别名可以用于以下情况:
- 索引切换:可以将别名指向不同的索引,实现索引的无缝切换,而不需要修改应用程序代码。
- 索引重命名:可以通过修改别名的指向来重命名索引,而不需要重新索引数据。
- 索引删除:可以通过修改别名的指向来删除索引,而不会影响应用程序的查询。
下面通过一个例子来说明各个属性
PUT /products
{
"mappings": {
"properties": {//定义的字段属性
"title": { //有一个名字为title的字段
"type": "text", //定义该字段类型为text
"analyzer": "custom_analyzer", // 指定该title字段采用custom_analyzer分词器,
"fields": {
"keyword": { //定义了一个子字段 "keyword"
"type": "keyword" // 该子字段的类型为keyword,用于精确匹配
} // 该字段的配置含义是:可以使用 "title" 字段进行模糊搜索,使用 "title.keyword" 字段进行精确匹配查询。
}
},
"description": {
"type": "text",
"analyzer": "custom_analyzer",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"price": {
"type": "float"
},
"category": {
"type": "keyword"
},
"tags": {
"type": "keyword"
},
"created_at": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
},
"settings": {
"analysis": { //定义了索引的分析器和过滤器
"analyzer": { //定义了一个名为 "custom_analyzer" 的自定义分析器。它的类型为 "custom",表示使用自定义的分析器。
"custom_analyzer": {
"type": "custom",
"tokenizer": "standard", //使用标准分词器进行分词
"filter": ["lowercase", "my_stopwords"]
}
},
"filter": { //定义了一个名为 "my_stopwords" 的过滤器. 它的类型为 "stop",表示使用停用词过滤器。停用词过滤器用于去除常见的停用词,如 "the"、"and"、"or" 等。
"my_stopwords": {
"type": "stop",
"stopwords": ["the", "and", "or"]
}
}
}
}
}
https://www.cnblogs.com/wupeixuan/p/12514843.html
创建索引
修改索引
删除索引
查询
简单查询
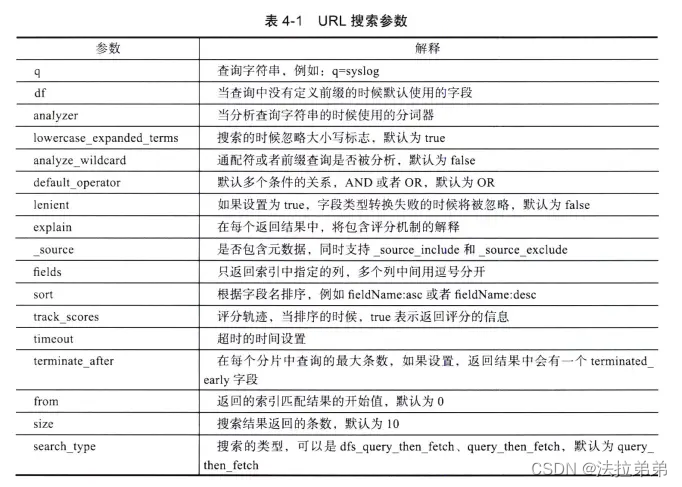
匹配所有文档:GET /index/_search
匹配指定字段的值:GET /index/_search?q=field:value
匹配多个字段的值:GET /index/_search?q=field1:value1 AND field2:value2
精确查询
在Elasticsearch中,可以使用精确查询来匹配字段的确切值。以下是几种常用的精确查询方式:
- Term Query(词项查询):用于精确匹配某个字段的确切值。
示例:GET /index/_search {“query”: {“term”: {“field”: “value”}}} - Terms Query(多词项查询):用于精确匹配某个字段的多个确切值。
示例:GET /index/_search {“query”: {“terms”: {“field”: [“value1”, “value2”]}}}
条件查询
在Elasticsearch中,条件查询是通过使用查询语句来筛选满足特定条件的文档。match查询是一种常用的全文搜索查询,用于在指定字段中匹配包含特定词项的文档。match查询会对查询词进行分词处理,并与字段中的词项进行匹配。
匹配指定字段的值:GET /index/_search {“query”: {“match”: {“field”: “value”}}}
匹配多个字段的值:
GET /index/_search
{
"query": {
"bool": {
"must": [
{"match": {"field1": "value1"}},
{"match": {"field2": "value2"}},
{"match": {"field3": "value3"}}
]
}
}
}
注意,must代表的是“与”的含义,即同时满足相应的条件。布尔查询还支持其他子句,如should(应该匹配至少一个子句)和must_not(不应该匹配任何子句)。
范围查询:
在Elasticsearch中,范围查询(Range Query)用于匹配某个字段在指定范围内的文档。范围可以是数值范围、日期范围或字符串范围。
以下是范围查询的使用示例:
- 数值范围查询:
GET /index/_search
{
"query": {
"range": {
"field": {
"gte": 10,
"lte": 100
}
}
}
}
上述示例中的范围查询会匹配字段field的值在10到100之间(包括10和100)的文档。
- 日期范围查询:
GET /index/_search
{
"query": {
"range": {
"date_field": {
"gte": "2021-01-01",
"lte": "2021-12-31"
}
}
}
}
上述示例中的范围查询会匹配字段date_field的日期值在2021年1月1日到2021年12月31日之间(包括这两个日期)的文档。
- 字符串范围查询:
GET /index/_search
{
"query": {
"range": {
"field": {
"gte": "A",
"lte": "Z"
}
}
}
}
上述示例中的范围查询会匹配字段field的字符串值在"A"到"Z"之间(包括"A"和"Z")的文档。
范围查询还支持其他参数和选项,如gt(大于)、lt(小于)、format(日期格式)等,可以根据具体需求进行配置。
需要注意的是,范围查询对于文本字段的排序和匹配是基于词项的,而不是基于整个字符串的。因此,在进行范围查询时,需要确保字段的分词和分析器设置正确。
聚合查询:
按字段分组统计:GET /index/_search {“aggs”: {“group_by_field”: {“terms”: {“field”: “field”}}}}
计算字段的平均值:GET /index/_search {“aggs”: {“avg_field”: {“avg”: {“field”: “field”}}}}
计算字段的总和:GET /index/_search {“aggs”: {“sum_field”: {“sum”: {“field”: “field”}}}}
排序和分页:
按字段排序:GET /index/_search {“sort”: [{“field”: {“order”: “asc”}}]}
分页查询:GET /index/_search {“from”: 0, “size”: 10}
参考文献:
https://xiaoxiami.gitbook.io/elasticsearch/ji-chu/35query-dsldslfang-shi-cha-8be229/354zhu-yu-ji-bie-cha-8be228-term-level-queries/range-cha-8be228-fan-wei-cha-8be229
https://cloud.tencent.com/developer/article/1947246