多个项目,自己有自己的环境,装的模块属于自己的
- 一般放在项目路径下:venv文件夹
- lib文件夹- - - 》site- package- - 》虚拟环境装的模块,都会放在这里
- scripts- - 》python,pip命令
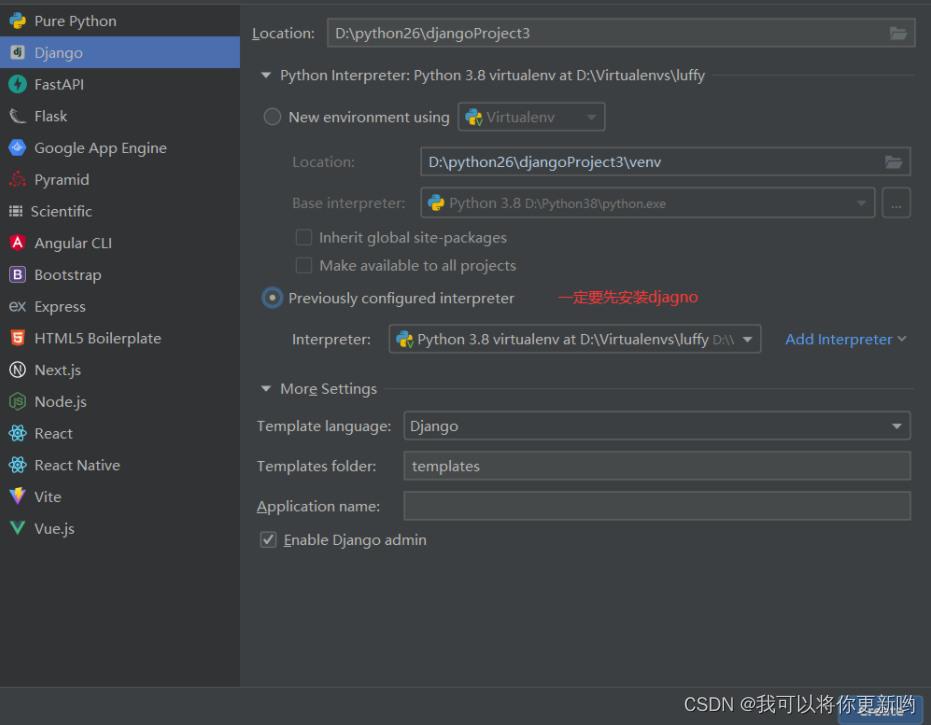
- pycharm- - - 》解释器- - 》添加本地解释器- - - 》找到python. exe- - - > 关联上即可
pip3 install virtualenv
- virtualenv. exe
pip3 install virtualenvwrapper- win
- virtualenvwrapper. bat
- virtualenvwrapper. sh
- 在d盘跟路径创建一个文件夹:D: \Virtualenvs
- 配置环境变量:
WORKON_HOME: D: \Virtualenvs
- - mkvirtualenv 虚拟环境名称
- - mkvirtualenv - p python2. 7 虚拟环境名称
- - mkvirtualenv - p python38 虚拟环境名称
- - workon
- - workon 虚拟环境名称
- - python | exit( )
- - pip或pip3 install 模块名
- - deactivate
- - rmvirtualenv 虚拟环境名称 或者直接删文件夹是一样的
【2 】Pipenv(官方工具):
Pipenv是Python官方推荐的虚拟环境管理工具,它集成了pip、venv和其他功能,并提供更便捷的方式来创建和管理虚拟环境。
以下是使用Pipenv创建虚拟环境的步骤:
安装Pipenv:您可以使用pip来安装Pipenv,命令如下:
pip install pipenv
创建虚拟环境:在项目文件夹中,使用下面的命令创建并激活虚拟环境:
pipenv shell
安装依赖包:在激活的虚拟环境中,可以使用Pipenv来安装项目所需的依赖包。例如:
pipenv install django== 3.0
注意:
Pipenv会自动将依赖包保存到Pipfile文件中,并生成一个对应的Pipfile. lock文件来锁定依赖包的版本。
退出虚拟环境:您可以使用以下命令退出虚拟环境:
exit
【3 】总结:
无论是使用Virtualenv还是Pipenv,都可以解决多项目不同Python版本和依赖包的隔离问题。
Virtualenv是第三方库,使用广泛且成熟稳定;
而Pipenv是Python官方推荐的工具,提供更便捷的方式来管理虚拟环境和依赖包
mkvirtualenv - p python38 luffy
pip install django== 3.1 .12
django- admin startproject luffy_api
"""
├── luffy_api
├── logs/ # 项目运行时/开发时日志目录 - 包
├── manage.py # 脚本文件
├── luffy_api/ # 项目主应用,开发时的代码保存 - 包
├── apps/ # 开发者的代码保存目录,以模块[子应用]为目录保存 - 包
├── libs/ # 第三方类库的保存目录[第三方组件、模块] - 包
├── settings/ # 配置目录 - 包
├── dev.py # 项目开发时的本地配置
└── prod.py # 项目上线时的运行配置
├── urls.py # 总路由
└── utils/ # 多个模块[子应用]的公共函数类库[自己开发的组件]
└── scripts/ # 保存项目运营时的脚本文件 - 文件夹
"""
- django项目运行,要先加载settings. py(dev. py)
- 运行时,执行的是 python manage. py runserver
- 修改manage. py 中 os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'luffy_api.settings.dev' )
- 命令行中运行,肯定不会报错
- pycharm运行,可能会报错
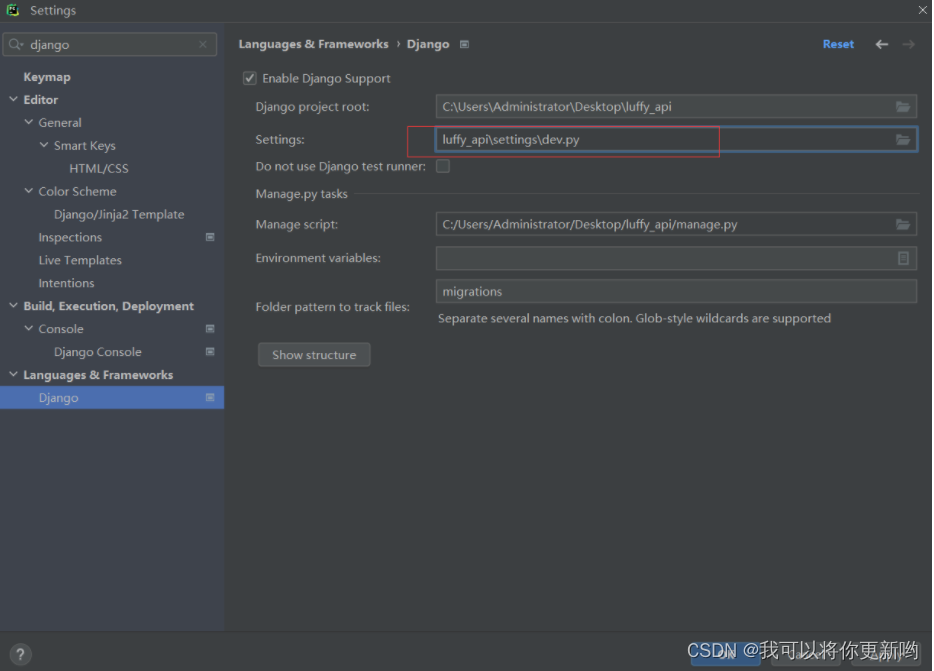
- 删除之前的django- server,再创建一个,它会自动关联撒花姑娘
- 配置文件中,找到django,指定配置文件(入下图)
python manage. py startapp home
切到apps目录下,创建app即可
python . . / . . / manage. py startapp home
- 在INSTALLED_APPS 直接写app的名字,会报错,报模块找不到的错误- - - 》
- 只需要把apps路径加入到环境变量即可
sys. path. insert( 0 , str ( BASE_DIR) )
sys. path. insert( 0 , os. path. join( BASE_DIR, 'apps' ) )
- 以后不要再用print 输出了,都用日志输出
- print 输出,上线也会有输出,如果用日志,日志有级别,上线后把级别调高,你开发阶段的输出就不再打印了
- 1 复制日志配置到dev. py中
LOGGING = {
'version' : 1 ,
'disable_existing_loggers' : False ,
'formatters' : {
'verbose' : {
'format' : '%(levelname)s %(asctime)s %(module)s %(lineno)d %(message)s'
} ,
'simple' : {
'format' : '%(levelname)s %(module)s %(lineno)d %(message)s'
} ,
} ,
'filters' : {
'require_debug_true' : {
'()' : 'django.utils.log.RequireDebugTrue' ,
} ,
} ,
'handlers' : {
'console' : {
'level' : 'DEBUG' ,
'filters' : [ 'require_debug_true' ] ,
'class' : 'logging.StreamHandler' ,
'formatter' : 'simple'
} ,
'file' : {
'level' : 'INFO' ,
'class' : 'logging.handlers.RotatingFileHandler' ,
'filename' : os. path. join( os. path. dirname( BASE_DIR) , "logs" , "luffy.log" ) ,
'maxBytes' : 300 * 1024 * 1024 ,
'backupCount' : 10 ,
'formatter' : 'verbose' ,
'encoding' : 'utf-8'
} ,
} ,
'loggers' : {
'django' : {
'handlers' : [ 'console' , 'file' ] ,
'propagate' : True ,
} ,
}
}
- 2 在utils下新建 common_logger. py
import logging
logger = logging. getLogger( 'django' )
- 3 在想使用日志的位置,导入直接使用即可,日志有级别,控制台和文件中打印的日志级别是不一样的
from utils. common_logger import logger
class LoggerView ( APIView) :
def get ( self, request) :
logger. info( 'info级别' )
logger. warn( 'warn级别' )
logger. warning( 'warning级别' )
logger. error( 'error级别' )
logger. critical( 'critical级别' )
logger. debug( 'debug级别' )
return Response( '看到我了' )
from rest_framework. views import exception_handler
from rest_framework. response import Response
from utils. common_logger import logger
def common_exception_handler ( exc, context) :
res = exception_handler( exc, context)
if res:
err = res. data. get( 'detail' ) or res. data or '未知错误,请联系系统管理员'
response = Response( { 'code' : 888 , 'msg' : '请求异常-drf:%s' % err} )
else :
response = Response( { 'code' : 999 , 'msg' : '请求异常-其他:%s' % str ( exc) } )
request = context. get( 'request' )
path = request. get_full_path( )
method = request. method
ip = request. META. get( 'REMOTE_ADDR' )
user_id = request. user. pk or '未登录用户'
err = str ( exc)
view = str ( context. get( 'view' ) )
logger. error(
'请求错误:请求地址是:%s,请求方式是:%s,请求用户ip地址是:%s,用户id是:%s,错误是:%s,执行的视图函数是:%s' % (
path, method, ip, user_id, err, view) )
return response
REST_FRAMEWORK = {
'EXCEPTION_HANDLER' : 'utils.common_excepitons.common_exception_handler' ,
}
return Response( data= { code: 100 , msg: 成功, result: [ { } , { } ] } )
return Response( data= { code: 100 , msg: 成功, token: asdasd, username: lqz} )
return APIResponse( ) - - - 》{ code: 100 , msg: 成功}
return APIResponse( result= [ { } , { } ] )
return APIResponse( token= afasfd, username= lqz)
from rest_framework. response import Response
class APIResponse ( Response) :
def __init__ ( self, code= 100 , msg= '成功' , status= None ,
template_name= None , headers= None ,
exception= False , content_type= None , ** kwargs) :
data = { 'code' : code, 'msg' : msg}
if kwargs:
data. update( kwargs)
super ( ) . __init__( data= data, status= status, headers= headers, template_name= template_name, exception= exception,
content_type= content_type)
- mysql在win上安装步骤:https: // zhuanlan. zhihu. com/ p/ 571585588
- 如果使用root用户,一旦密码泄露,所有库都不安全了
- 如果新建一个luffy用户,只授予luffy库的权限,即便泄露了密码,只是这个库不安全了
- 查看用户:select user, host, authentication_string from mysql. user;
- 创建用户:
grant all privileges on luffy. * to 'luffy' @'%' identified by 'Luffy123?' ;
grant all privileges on luffy. * to 'luffy' @'localhost' identified by 'Luffy123?' ;
flush privileges;
DATABASES = {
'default' : {
'ENGINE' : 'django.db.backends.mysql' ,
'NAME' : 'luffy' ,
'HOST' : '127.0.0.1' ,
'PORT' : 3306 ,
'USER' : 'luffy' ,
'PASSWORD' : 'Luffy123?'
}
}
- 解决方式一:直接安装myslqclient - - - 》win平台看人品,mac基本装不上,linux需要单独处理
- 解决方式二:使用pymysql
- 安装,在配置文件中加入:
import pymysql
pymysql. install_as_MySQLdb( )
user= os. environ. get( 'LUFFY_USER' , 'luffy' )
password= os. environ. get( 'LUFFY_PWD' , 'Luffy123?' )
print ( user)
DATABASES = {
'default' : {
'ENGINE' : 'django.db.backends.mysql' ,
'NAME' : 'luffy' ,
'HOST' : '127.0.0.1' ,
'PORT' : 3306 ,
'USER' : user,
'PASSWORD' : password
}
}