鲲鹏处理器
- 一、处理器概述
- 1.Soc
- 2.Chip
- 3.DIE
- 4.Cluster
- 5.Core
- 二、体系架构
- 1.计算子系统
- 2.存储子系统
- 3.其他子系统
- 三、CPU编程模型
- 1.中断与异常
- 2.异常级别
- a.基本概念
- b.异常级别切换
- 下面为整理的内容:
- 鲲鹏处理器 架构与编程(一)处理器与服务器
- 总目录
- 一、服务器与处理器
- 1 服务器分类
- 2服务器处理器
- 高性能处理器并行组织结构,为了提供更强的计算能力。
- 1.指令流水线
- 2.多处理器系统、多计算机系统
- 3.多线程处理器
- 并行概念从指令级并行拓展至线程级并行(Thread-Level-Parallelism),快速进行线程级切换,减少垂直浪费。
- 1.2.1高性能处理器的并行组织结构
- 指令流水线:
- 多处理器系统和多计算机系统:
- 多线程处理器:
- 多核处理器(片上多处理器)
- 同异构多核处理器
- 1.2.2英特尔处理器体系结构
- 英特尔处理器发展
- 1.2.3 ARM处理器体系结构
- ARM处理器分类
- 1)ARM经典处理器
- 2)ARM Cortex应用处理器
- 3)ARM Cortex嵌入式处理器
- 4)ARM 专业处理器
- 1.3 服务器技术基础
- 1.3.1 高性能处理器的存储器组织与片上互联
- 1. 多核系统的存储结构
- 多核处理器的Cache一致性
- UMA 架构 和 NUMA 架构
- 多核处理器的核间通信机制
- 1. 总线共享Cache结构
- 2.交叉开关互联结构
- 3. 片上网络结构
- 内存顺序模型与内存屏障
- 一、 访存重排序
- 1. 指令重排序三种类型
- 2. 三种不同的存储器访问顺序
- 二、 内存一致性模型
- 1. 软件内存模型
- 2. 硬件内存模型
- a.强一致性内存模型
- b.弱一致性内存模型
- A. 顺序一致性内存模型
- B. 全存储排序内存模型
- C. 部分存储排序内存模型
- D. 宽松内存顺序内存模型
- 三、 内存屏障指令
- 1. 输入输出控制指令eieio
- 2. 同步指令sync
- 3. 同步指令isync
读过我之前的笔记的朋友一定知道我是写过一个关于鲲鹏处理器的专栏的: 鲲鹏处理器 架构与编程,质量分平均96,也是我自己开始写博客的地方,在写 DP读书 笔记时,我也搞懂了很多从前一知半解的原理。
那我开始了:
一、处理器概述
1.Soc
从狭义角度讲,Soc是信息系统核心的芯片集成,是将系统关键部件集成在一块芯片上;从广义角度讲,Soc是一个微小型系统,如果说中央处理器(CPU)是大脑,那么Soc就是包括大脑、心脏、眼睛和手的系统。
国内外学术界一般倾向将Soc定义为将微处理器、模拟IP核、数字IP核和存储器(或片外存储控制接口)集成在单一芯片上,它通常是客户定制的,或是面向特定用途的标准产品。
2.Chip
芯片(chip)就是半导体元件产品的统称。是集成电路(IC, integrated
circuit)的载体,由晶圆分割而成。硅片是一块很小的硅,内含集成电路,它是电脑或者其他电子设备的一部分。IC就是集成电路,泛指所有的电子元器件,是在硅板上集合多种电子元器件实现某种特定功能的电路模块。它是电子设备中最重要的部分,承担着运算和存储的功能。集成电路的应用范围覆盖了军工、民用几乎所有的电子设备。
3.DIE
DIE是芯片的最小物理单元,是指以半导体材料制作而成未经封装的一小块集成电路本体,该集成电路的既定功能就是在这一小片半导体上实现。通常情况下,集成电路是以大批方式,经光刻等多项步骤,制作在大片的半导体晶圆上,然后再分割成方型小片,这一小片就称为晶粒,每个晶粒就是一个集成电路的复制品。
4.Cluster
集群(Cluster)是一种较新的技术,通过集群技术,可以在付出较低成本的情况下获得在性能、可靠性、灵活性方面的相对较高的收益,其任务调度则是集群系统中的核心技术。具体来说,集群是一组相互独立的、通过高速网络互联的计算机,它们构成了一个组,并以单一系统的模式加以管理。一个客户与集群相互作用时,集群像是一个独立的服务器。这项技术主要用于提高系统的可用性和可缩放性。
5.Core
在计算机领域里,Core一般用来指代“中央处理器”(Central Processing
Unit),也就是常说的CPU。因为CPU可以看做是整个计算机系统的核心,它承担着处理数据、控制运行、存储加载等基本任务,相当于电脑的大脑。
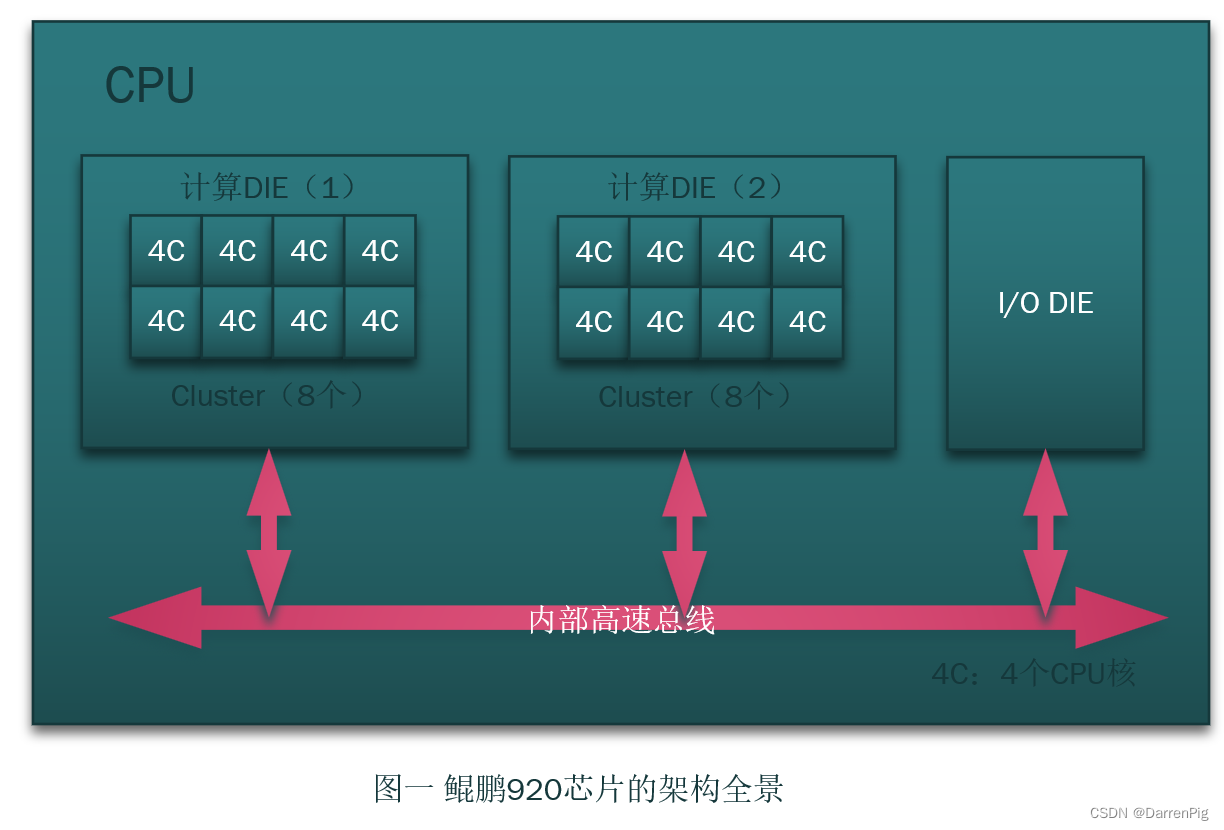
二、体系架构
1.计算子系统
计算机中进行数据运算的子系统是CPU,也就是中央处理器。中央处理器(central processing unit,简称CPU)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。CPU自产生以来,在逻辑结构、运行效率以及功能外延上取得了巨大发展。其功能主要是解释计算机指令以及处理计算机软件中的数据。CPU是计算机中负责读取指令,对指令译码并执行指令的核心部件。
2.存储子系统
计算机的存储子系统由主存(内存)、辅存(外存)和高速缓冲存储器(Cache)组成。
1. 主存(内存):CPU可直接编程访问,存放CPU当前执行所需要的指令和数据。特点是能随机访问、存取速率快、具有一定的存储容量(受地址位数制约)。
2. 辅存(外存):存放大量的后备程序和数据。特点是速度较慢、容量大。
3. 高速缓冲存储器(Cache):存放CPU在当前一小段时间内多次使用的程序和数据,以缓解CPU和主存的速度差异。特点是速度很快、容量小。
此外,物理存储器与虚拟存储器也是存储子系统的重要组成部分:
1. 物理存储器:物理形态上真实存在的存储器,简称为实存,其地址称为物理地址或实地址。
2. 虚拟存储器:虚拟存储器是一个逻辑模型,并非物理存在,基于物理存储器并靠硬件+操作系统的映射来实现。
存储子系统是计算机的重要组成部分,负责存储和管理计算机中的数据和程序,对计算机的性能和可靠性有着至关重要的影响。
3.其他子系统
除了计算子系统和存储子系统,计算机还有其他一些重要的子系统,例如:
1. 输入/输出(I/O)子系统:负责计算机与外部设备之间的通信和数据传输,包括键盘、鼠标、显示器、打印机等。
2. 网络子系统:负责计算机与其他计算机或网络之间的通信和数据传输,包括网卡、路由器、交换机等。
3. 操作系统子系统:负责管理计算机的硬件和软件资源,提供各种服务,包括进程管理、内存管理、文件系统、设备驱动等。
4. 安全子系统:负责保护计算机系统和数据的安全,包括防火墙、杀毒软件、加密技术等。
5. 应用软件子系统:负责提供各种应用程序和服务,满足用户的不同需求,包括办公软件、图像处理软件、游戏等。
这些子系统协同工作,使计算机成为一个完整的系统,满足用户的不同需求。
三、CPU编程模型
1.中断与异常
中断和异常是计算机系统中的两个重要概念,它们都是指系统、处理器在执行指令过程中突然被别的请求打断而终止当前的程序,转而去处理其他程序。待该中断处理程序处理完后回到该程序中断点继续执行之前程序。
异常表示CPU执行指令时本身出现了问题,如算数溢出,除零,或执行了陷入指令等。而中断则是CPU对系统发生的某个事件作出的一种反应,事件的发生改变了CPU的控制流。两者的区别在于,异常是由CPU执行指令时出现的问题引起的,而中断是由外部事件引起的。
为了支持CPU和设备之间的并行操作,现代操作系统引入了中断异常机制。当设备完成输入输出向CPU发送中断报告结果时,CPU会暂停正在执行的程序,保留现场后自动转去执行相应事件的处理程序,处理完成后返回断点,继续执行被打断的程序。
中断异常机制是现代操作系统的核心机制,硬件和软件相互配合而使计算机系统充分发挥能力。硬件负责中断异常响应,捕获中断请求,将处理器控制权交给特定的处理程序;软件则负责中断异常处理程序,识别类型并完成相应处理。
总的来说,中断和异常是计算机系统中非常重要的机制,它们使得计算机能够应对各种事件和错误,保证了系统的正常运行。
2.异常级别
异常级别是指计算机系统在处理异常时所采取的不同级别的响应和处理方式。
不同异常级别下,处理器能够访问的资源也不同。在PE(处理器)在某个异常级别执行的时候,PE能够访问下面的资源:可用于当前异常级别和当前安全状态的资源集;在当前的安全状态下,所有较低的异常级别上可用的资源。
a.基本概念
异常级别决定了系统在处理异常时的响应和处理方式,保证系统的正常运行。
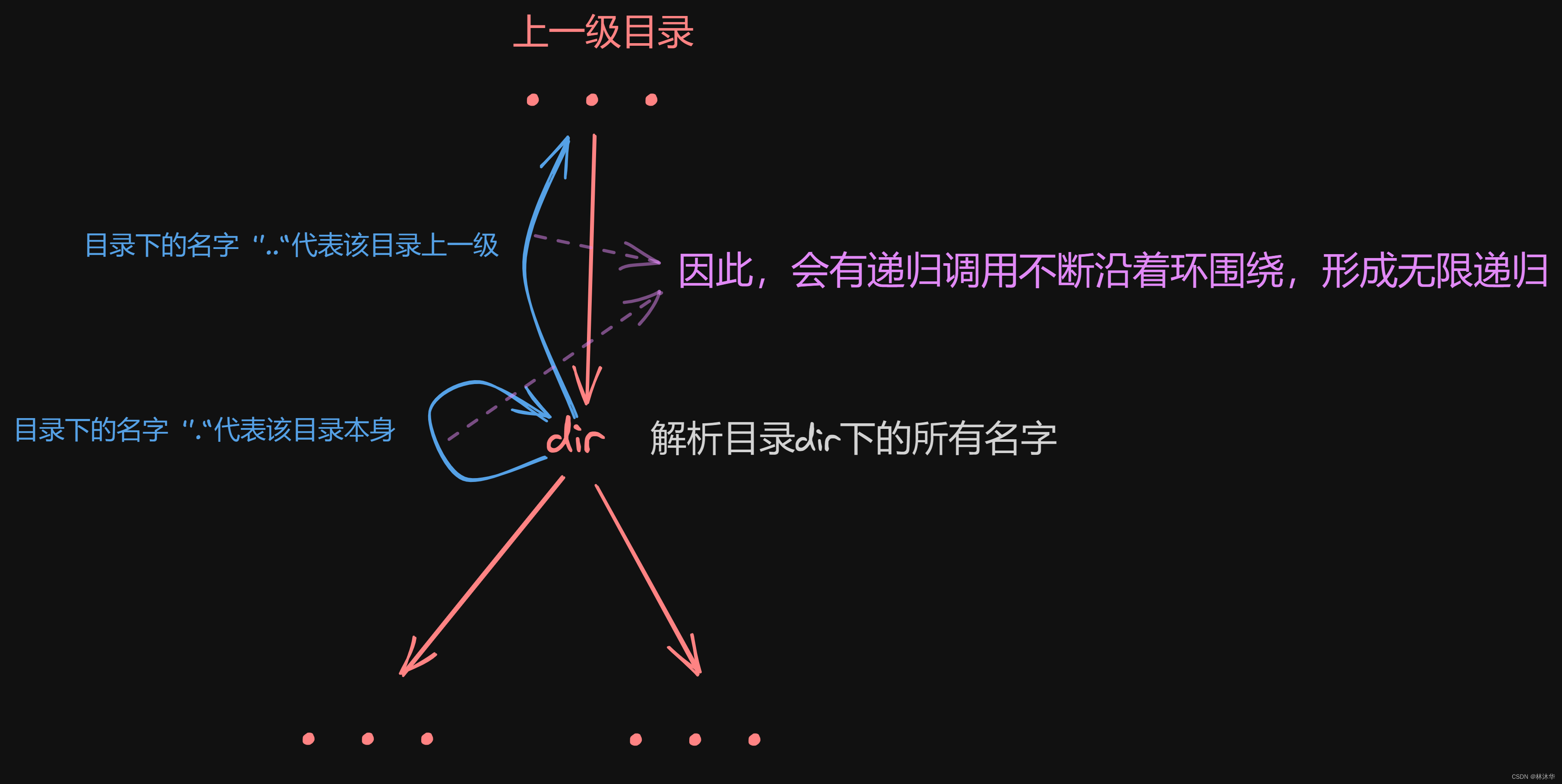
异常级别的切换只能发生在触发了异常或者异常处理返回过程中。当发生异常时,异常级别要不增加,要不保持不变;当从异常处理返回时,异常级别只能减小或者保持不变。每个异常级别都有一个明确的目标异常级别,这个目标异常级别要么是默认定义的,要么是通过系统寄存器的相应bit定义的。
在ARMv8-A系列架构中,异常级别分为EL0到EL3四个级别,其中EL0是无特权执行级别,EL1是操作系统内核执行级别,EL2提供了对虚拟化的支持,EL3提供了安全状态切换功能。随着异常级别的增加,软件的执行权限也相应的增加。
异常级别的切换是计算机系统中非常重要的机制,它使得系统能够在不同的异常级别之间切换,以应对不同的事件和错误。在ARMv8-A系列架构中,异常级别的切换只能发生在触发了异常或者异常处理返回过程中。
b.异常级别切换
当发生异常时,异常级别要不增加,要不保持不变。例如,当处理器在执行EL0级别的程序时发生异常,那么处理器的异常级别可能会升级到EL1或者更高的级别,这取决于异常的类型和处理程序的需求。当异常处理程序处理完异常后返回时,处理器的异常级别会降低到原来的级别或者更低的级别。
异常级别的切换是由系统中的硬件和软件共同完成的。硬件负责捕获异常请求,将处理器控制权交给相应的处理程序。软件则负责编写异常处理程序,识别异常类型并完成相应的处理。在异常处理程序执行完成后,处理器会返回到原来的程序执行点继续执行被打断的程序。
在异常级别切换过程中,处理器会保存当前的程序状态和执行上下文,以便在返回到原来的程序执行点时能够恢复执行。同时,处理器也会根据异常类型和目标异常级别来设置相应的寄存器和状态,以确保在新的异常级别下能够正确地执行程序。
异常级别的切换是计算机系统中非常重要的机制,它使得系统能够在不同的异常级别之间切换,以应对不同的事件和错误,保证了系统的正常运行。
########################################
下面为整理的内容:
鲲鹏处理器 架构与编程(一)处理器与服务器
未来的世界将是一个
端-云-端 的世界:
人机物融合,通过对云侧的极限计算,边缘侧的专业计算,端侧的个性计算——未来计算机体系的构成。
x86:个人向
ARM:移动计算,服务器AND物联网
RISC-V:万物互联
鲲鹏系列处理器:ARM生态
本文基于学习ARM架构,帮助理解高性能服务器处理器。
鲲鹏芯片:海思自研芯片的总称,含有鲲鹏处理器、昇腾(Ascend)、人工智能(AI)、SSD控制芯片、智能融合网络、智能管理芯片。
鲲鹏920完全兼容64位的ARMv8-A环境,完全兼容所有的ARM环境,提供一种华为创新解决方案。
对于鲲鹏处理器,其不仅满足个人服务器的处理条件,还更多的应用在服务器系统的搭建运行上。
总目录
这本书主要有四部分:
1.高性能处理器的并行架构,以及服务器体系结构,技术路径
2.ARMv8-A处理器架构逻辑
3.基于鲲鹏920片上系统的Taishan服务器优势
4.鲲鹏软件生态架构, 应用、调优工程师应该关注
附录:鲲鹏处理器、鲲鹏开发者套件、鲲鹏社区、鲲鹏开发者认证计划
一、服务器与处理器
1 服务器分类
体系结构,技术基础:Sever(服务器)是一种同时网络数据节点与枢纽为主,对于服务器功能与性能>>PC(个人电脑),与PC同属于计算机。
- SMP(对称多处理器Symmetric multi-Proceser),RAID(独立磁盘冗余阵列Rradudent Arrays of Independent Disks)冗余备份技术,热插拔远程监测技术。
应用层级:服务器大致分级以数量规模作区分
- 入门、工作组(50-)、部门级、企业级
机械结构:TS塔式(台式)[入门工作组级]、RS机架(机柜)[宽19英寸,1、2、4、8U单位,1U=1.75英寸]、BS刀片[共享高速总线,发热能耗低]
使用用途:业务服务器、存储服务器、其他专用服务器
- 人工智能架构支持异构架构,大量GPU(Graphics Processing Unit图形处理器)或FPGA(Field Programmable Gate Array,现场可编程门阵列)实现CPU加速。
处理器架构:处理器分类——CISC(Complex Instruction Set Computer,复杂指令集计算机)和RISC(Reduced Instruction Set Computer,精简指令计算机) + 架构分类——CISC、RISC、EPIC(一种特殊的RISC)
-
CISC架构服务器:Intel的Intel 64架构,AMD的AMD64和早期的IA-32,
Intel的Keon、AMD的Opteron和EPYC -
RISC架构服务器:非INTEL架构服务器 + IBM的Power,HP的Alpha和PA-RISC、SUN/Oracle的SPARC 、MIPS的NIPS
:RISC架构服务器 不同于 体系结构的RISC处理器,价格昂贵、体系封闭,Unix和专用系统为主,稳定性能强
+Power架构,Apple、IBM、摩托罗拉共同开发的微处理器架构,Power(Performance Optimized With Enhanced RISC)性能强大,价格高昂,硬件采用SMP(对称多处理器)国内IPS负责运营。
+SPARC早期由SUN开发、目前由Oracle甲骨文运营的处理器架构,SPARC(Scalable Processor ARChitecture可拓展处理器架构)
… -
EPIC架构服务器:显示并行指令计算(Explicitly Prallel Instruction Computing)IA-64的Itanium处理器,由HP和Intel开发 : 免去了在RISC中设计复杂的并行调度电路,直接应用现代编译程序进行过程性调度。
+VLIW(Very Long Insstruction Word 超长指令字)技术,提高并行性,128位指令束3*41+5,但将于2025停产
服务器测试基准:TPC、SPEC
:RASUM–>主板 控制管理IPMI规范,IPMI(Intelligent Platform Management Interface智能平台管理接口)应用BMC芯片与BIOS交互,规范描述了主板管理控制,
+ BMC监视系统状态,多接口上层网管查询
查找:Ctrl/Command + F
替换:Ctrl/Command + G
2服务器处理器
高性能处理器并行组织结构,为了提供更强的计算能力。
但是由于物理规律对半导体器件的限制,传统的单处理器系统通过提高主频提升性能的方法收到制约,不可能任沿摩尔定律预测的轨迹持续上升,且随着晶体管越来越小芯片内部的互连线延时影响越来越大,高频率不仅使能源消耗剧增,而且没有良好的散热对系统的稳定性造成剧烈影响。
并行式成为了在这种情况下更好的解决方案,成为目前能够提高系统效率的最佳方案。
1.指令流水线
执行程序的角度,并行等级可分为多级:一条指令执行的微操作之间的并行是指令内部的并行;并行执行两条或多条指令,也即指令级并行(Instruction-Level Parallelism,ILP )执行两个或两个以上任务(程序段)属于任务级并行;最高层次或作业级并行则是指2+作业或程序
对于单个处理器,时间并行技术主要体现在指令流水线。 常见的高性能处理器无一不采用指令处理器,多发射处理器将空间并行性引入了处理器。
超标量(Superscalar)采用多发射技术,处理器内部采用多条并行执行的指令流水线,通过时钟周期内向执行单元发射多条指令实现指令级并行。
2.多处理器系统、多计算机系统
Multi-processor(多处理器系统)
常见的有集群(Cluster,也称机群),集群中每台计算机一般成为节点,反应物理连接的紧密程度和交互能力的大小分为,紧耦合系统(直接耦合 系统)[总线、高速开关相连]与 松耦合系统(间接耦合系统)[通道通信线路相连]
3.多线程处理器
除了传统的指令级并行技术,多线程技术与多核技术也能提高芯片处理能力的片内并行技术。.
//当处理器访问Cache(高速缓冲存储器)缺失(Miss,不命中),则必须访问主存,这会导致执行部件长时间等待,直到Cache成功加载。
var 解决该问题的方法是片上多线程技术(On-chip Multi-threading)技术。
= '处理器中,引入硬件多线程(Hardware Multi-threading)的概念,原理相似。';
并行概念从指令级并行拓展至线程级并行(Thread-Level-Parallelism),快速进行线程级切换,减少垂直浪费。
同时多线程(Simultaneous Multi-Threading,SMT),减少水平以及垂直浪费。一个时钟周期内,不同线程的多条指令。E.g.:Intel的超线程。
一个简单的表格是这么创建的:
| 项目 | E.g. |
|---|---|
| 指令级并行 | 超标量(Superscalar) |
| 多处理器系统、多计算机系统 | 集群(Cluster,也称机群),集群中每台计算机一般成为节点 |
| 多线程处理器 | $ 并行概念从指令级并行拓展至线程级并行(Thread-Level-Parallelism) |
1.2.1高性能处理器的并行组织结构
| 并行机制 | Value |
|---|---|
| 指令流水线 | 指令级并行 |
| 多处理器系统和多计算机系统 | 直间接耦合系统 |
| 多线程处理器 | 线程级并行 |
| 多核处理器(片上多处理器) | 众核(MC)处理器 |
| 同异构多核处理器 | GPU和CPU集成 |
| 多核处理器的对称性 | (非)对称多处理 |
指令流水线:
> 指令流水线是为提高处理器执行指令的效率,把一条指令的操作分成多个细小的步骤,每个步骤由专门的电路完成的方式。这种方式允许处理器在执行完一条指令的一个步骤后,就可以立即开始执行下一条指令的一个步骤,而不是等待整个指令完全执行完毕。这种方式可以显著提高处理器的效率,因为处理器可以在多个步骤同时进行操作。
> 指令流水线可以分为三类:简单指令流水线、复杂指令流水线和超长指令字(VLIW)指令流水线。简单指令流水线只包含一个操作步骤,例如加法操作。复杂指令流水线包含多个操作步骤,例如乘法操作,需要多个时钟周期才能完成。超长指令字指令流水线将多个简单操作组合成一条长指令,可以同时执行多个操作,从而提高处理器的效率。
多处理器系统和多计算机系统:
>多处理器系统和多计算机系统是两种不同的计算机系统。
>多处理器系统是指一个计算机系统中包含两台或多台功能相近的处理器,这些处理器可以相互协作完成任务,并且共享内存、I/O设备、控制器和外部设备。多处理器系统的优点是可以提高系统的处理能力和性能,缺点是系统的设计和实现比较复杂。
>多计算机系统是指一个计算机系统由多台计算机组成,这些计算机之间通过网络相互连接,可以相互协作完成任务。多计算机系统的优点是可以提高系统的可靠性和可扩展性,缺点是系统的设计和实现比较复杂。
多线程处理器:
>多线程处理器是一种处理器,它能够同时执行多个线程,以提高处理器的利用率和效率。多线程处理器通过复制处理器上的结构状态,让多个线程同步执行并共享处理器的执行资源,从而实现宽发射、乱序的超标量处理,提高处理器运算部件的利用率,缓存和由于数据相关或Cache未命中带来的访问内存延时。
>多线程处理器主要分为两种类型:SMT和MIMD。SMT(Simultaneous Multi-Threading)是一种共享处理器时间的技术,它允许多个线程同时在一个处理器上执行。MIMD(Multiple Instruction Multiple Data)是一种并行计算模型,它允许多个处理器同时执行多个指令和数据。
>多线程处理器广泛应用于各种领域,例如计算机科学、人工智能、大数据处理等。它能够提高处理器的性能和效率,降低能耗和成本,为计算机系统的设计和实现提供了更好的解决方案。
多核处理器(片上多处理器)
多核处理器是一种具有多个处理核心的处理器,这些核心集成在同一块芯片上,相互之间通过内部总线进行通信。多核处理器的主要目的是通过并行执行多个线程来提高处理器的整体性能,解决单核处理器中存在的能效问题。多核处理器采用了多种技术来实现并行处理,例如多线程技术、超线程技术、Cache技术等。这些技术能够有效地提高处理器的利用率和效率,降低能耗和成本。
多核处理器广泛应用于各种领域,例如计算机科学、人工智能、大数据处理等。它能够提高处理器的性能和效率,降低能耗和成本,为计算机系统的设计和实现提供了更好的解决方案。
同异构多核处理器
同异构多核处理器一种具有多个处理核心的处理器,这些核心可以相同,也可以不同。同构多核处理器中的核心具有相同的架构和功能,而异构多核处理器中的核心则具有不同的架构和功能。同构多核处理器通常由多个相同的处理核心组成,每个核心都可以独立运行,类似于单核处理器。这种多核处理器适用于通用计算任务,可以并行执行多个线程,从而提高处理器的整体性能。异构多核处理器则是由不同的处理核心组成,每个核心针对不同的需求进行设计,例如通用处理器、DSP、FPGA、媒体处理器、网络处理器等。
这种多构处理器适用于特定领域的计算任务,可以进一步提高应用的计算性能或实时性能。>从软件角度来看,多核处理器的运行模式包括SMP(对称多处理)、AMP(非对称多进程)和BMP(同构多线程)等。其中,SMP是最常用的运行模式,每个核心平等地运行不同的任务;AMP则是指不同核心运行不同版本的操作系统或裸机程序;BMP则适用于同构多核处理器,每个核心运行相同的程序,但执行不同的任务。
>总之,同异构多核处理器通过将多个处理核心集成在同一块芯片上,实现了并行处理和高效计算,适用于各种领域的高性能计算需求。
多核处理器的对称性
多核处理器的对称性指的是多个核心之间的平等关系,即它们在处理任务时具有相同的优先级和资源访问权限。对称多核处理器(SMP)是一种常见的多核处理器,其核心数量从两个到多个不等。在SMP中,所有的核心都平等地共享处理器的资源,包括内存、I/O设备和其他核心。因此,在操作系统中,每个核心都被视为一个独立的处理器,可以同时执行多个线程。
在非对称多进程(AMP)中,不同核心运行不同版本的操作系统或裸机程序,它们之间没有对称性。而在同构多线程(BMP)中,虽然多个核心共享相同的程序,但它们执行不同的任务,因此也没有对称性。对称性的优点是可以提高处理器的利用率和效率,充分发挥多个核心的优势。但是,对称性的实现也需要付出额外的代价,例如核心之间的通信和同步问题,以及调度和负载均衡等问题。因此,在实际应用中,需要根据具体的需求和场景来选择是否采用对称性的多核处理器。
1.2.2英特尔处理器体系结构
| 处理器 | 架构 |
|---|---|
| IA-32 | 指令级并行 |
| 安腾架构与Intel 64架构 | 直间接耦合系统 |
| 多线程处理器 | 线程级并行 |
| 多核处理器(片上多处理器) | 众核(MC)处理器 |
| 同异构多核处理器 | GPU和CPU集成 |
| 多核处理器的对称性 | (非)对称多处理 |
英特尔处理器发展
IA-32——最常见应用最广
IA-32是Intel Architecture 32-bit的缩写,即英特尔32位体系架构。它是在英特尔公司1985年推出的80386微处理器中首先采用的。IA-32是一种32位微处理器指令集架构,它支持32位内存地址和32位指令集,适用于支持英特尔架构的处理器。
安腾架构与Intel64架构——安腾已然EOL
安腾架构和Intel64架构是两个不同的计算机体系结构,其主要区别在于指令集和使用场景。
安腾架构是64位指令集,由英特尔公司和惠普公司共同开发,适用于惠普公司的Itanium系列处理器。它主要用于高端服务器和工作站,强调处理大量的数据和提供高效的数据处理能力。
Intel64架构是32位和64位指令集的统称,包括EM64T(Extended Memory 64 Technology)扩展64位内存技术。它适用于英特尔公司的x86-64和AMD公司的AMD64系列处理器,广泛用于个人计算机、游戏机和一些专业应用领域。
Intel至强系列服务器处理器-UPI
Intel至强系列服务器处理器是英特尔公司为服务器市场开发的一系列处理器。至强系列处理器采用了多种不同的架构和技术,以满足不同类型服务器和工作负载的需求。以下是一些常见的Intel至强系列服务器处理器及其特点:
- Intel Xeon Gold:这是至强系列的高端产品,主攻高性能计算、虚拟化和数据库等领域。Gold系列处理器采用了先进的制程技术,拥有高主频和大缓存,以及更多的核心和线程。
- Intel Xeon Platinum:这是至强系列的旗舰产品,主要应用于高性能计算、云计算和数据中心等领域。Platinum系列处理器同样具备高主频、大缓存和多核心多线程等特点,且拥有更高的安全性和可靠性。
- Intel Xeon Silver:这是至强系列的中端产品,主攻网络、存储和边缘计算等领域。Silver系列处理器在价格和性能之间达到了平衡,适合用于各种不同的工作负载。
- Intel Xeon Bronze:这是至强系列的入门级产品,主要应用于低功耗和冷却受限的领域。Bronze系列处理器注重节能性能,适合用于基础服务器应用。
1.2.3 ARM处理器体系结构
1. ARM( Advanced RISC Machines Limited) 1990年由Acorn、Apple、VLSI合资成立的处理器公司,早期以IP(Intellectual Property,知识产权)授权这种商业模式,与众多半导体厂商构成合作关系。
2. ARM体系结构、指令集与ARM处理器
-
ARM体系结构(Architecture)
ARM公司定义了8种主要的ARM体系结构版本,以版本号v1~v8表示。
处理器体系结构又称架构,其定义了处理单元(Processing Element) ,简称PE的处理规范。
-
ARM体系结构的指令集(Instruction Set)
ARM(Advanced RISC Machine)是一种流行的32位微处理器指令集架构。它被广泛应用于嵌入式系统、移动设备、消费电子设备等领域。ARM指令集包括以下几种类型:
1. 数据处理指令(Data Processing Instructions):这些指令用于对寄存器中的数据进行操作,例如加法、减法、乘法、移位等。
2. 程序控制指令(Control Instructions):这些指令用于控制程序流程,例如跳转、分支、子程序调用等。
3. 加载和存储指令(Load and Store Instructions):这些指令用于从内存中加载数据到寄存器或将寄存器中的数据存储到内存中。
4. 栈操作指令(Stack Operations Instructions):这些指令用于操作堆栈,例如压栈、弹栈等。
5. 位操作指令(Bit Manipulation Instructions):这些指令用于对数据进行位操作,例如位反转、位测试、位设置等。
6. 协处理器指令(Coprocessor Instructions):这些指令用于与协处理器进行通信。
7. 异常产生指令(Exception Generation Instructions):这些指令用于产生异常,例如中断、未定义指令等。
8. ARM指令集还包括一些伪指令(Pseudo-instructions),这些指令在汇编语言中用于实现某些高级功能,例如条件语句、循环等。
ARM指令集的一个重要特点是它支持Thumb指令集,该指令集是一种16位的指令集,提供了更高的代码密度,适用于对代码大小有严格要求的系统。ARMv8版本引入了64位支持的ARM指令集(AArch64) 和 32位支持的ARM指令集(AArch32) 两种模式。
ARM指令集还有几个重要的特征:
> 1. 具有条件执行(Conditional Execution)功能,即某些指令可以根据特定条件来执行。
> 2. 具有延迟绑定(Delay Binding)功能,即某些指令的执行结果可以在其他指令的执行期间被预测,从而提高了处理器的效率。
> 3. 支持寄存器重命名(Register Renaming),以减少因数据相关引起的性能瓶颈。😁
4. ARM的微处理器内核(Processor Core)(CPU)
ARM微处理器的内核是ARM指令集体系结构的基础,它定义了处理器的基本功能和特性。以下是ARM微处理器内核的一些主要特点和分类:
- ARM7系列:这是ARM微处理器系列的早期产品,采用32位精简指令集,具有低功耗、高性能的特点,主要应用于嵌入式系统和移动设备等领域。
- ARM9系列:相对于ARM7系列,ARM9系列在性能和功能方面更加先进,采用了32位高性能ARM指令集,具有更高的处理能力和更好的多媒体性能,主要应用于智能手机、平板电脑、游戏机等领域。
- ARM11系列:这是ARM微处理器系列的中期产品,采用32位高性能ARM指令集,具有更高的处理能力和更好的功耗效率,主要应用于音频处理、图像处理、数字信号处理等领域。
- Cortex系列:这是ARM微处理器系列的最新产品,包括Cortex-A、Cortex-R和Cortex-M三个系列,分别应用于高性能、实时性和微控制器领域。Cortex系列采用了先进的体系结构和指令集,具有更高的性能和更好的功耗效率,可以满足不同领域的需求。
除了以上几个系列,ARM微处理器内核还包括其他一些特殊的产品和应用,如ARM Cortex-A78、ARM Cortex-X1、ARM
Cortex-M0+等。这些产品和应用具有各自独特的特点和优势,可以满足不同领域的需求。
5. ARM处理器(Prosseor)
ARM处理器是一种基于ARM指令集的32位微处理器。ARM指令集是一种精简指令集,具有较低的功耗和成本,同时提供了较高的性能,因此被广泛应用于移动设备、嵌入式系统、物联网、云计算等领域。
ARM处理器的体系结构是32位RISC(精简指令集计算机)架构,其指令集和寄存器都是32位的。ARM处理器具有低功耗、高性能、小体积、低成本等优点,适用于对功耗和性能要求较高的应用领域。
ARM处理器的家族主要包括ARM7、ARM9、ARM11、Cortex-A、Cortex-B、Cortex-M等系列。其中,Cortex系列是ARM公司近年来主推的系列,其A系列应用于高性能领域,B系列应用于可靠性领域,M系列应用于微控制器领域。
ARM处理器在智能手机市场上占据主导地位,全球超过90%的智能手机和平板电脑都使用ARM处理器。此外,ARM处理器还在嵌入式系统、物联网、云计算、服务器等领域得到广泛应用。
6. 基于ARM架构处理器的片上系统(Soc)
> 基于ARM架构处理器的片上系统(Soc)是一种高度集成的芯片,将多个处理器和其他功能集成在一个芯片上,形成了一个完整的系统。这种系统基于ARM指令集架构,通常包括一个或多个ARM处理器核心,以及其他相关的硬件和软件组件。
一个典型的基于ARM的Soc系统通常包括以下主要部件:
- ARM处理器核心:这是Soc系统的核心,负责执行指令和数据处理。不同的ARM处理器核心具有不同的性能和功能,可以根据应用需求进行选择。
- 内存:包括RAM和ROM,用于存储指令和数据。在Soc系统中,内存通常被集成在芯片内部。
- 外围设备:例如I/O接口、串口、USB接口、网络接口、传感器等,这些设备与处理器核心通过总线相连,扩展了系统的功能。
- 时钟和复位电路:用于提供系统时钟信号和复位信号,确保系统正常运行。
- 电源管理:用于管理芯片各个部分的电源,降低功耗,延长电池寿命。
- 软件:包括操作系统、驱动程序和应用软件等,用于控制和管理Soc系统的硬件资源和应用程序的运行。
>基于ARM的Soc系统具有高度集成、低功耗、高性能等优点,广泛应用于智能手机、平板电脑、物联网、嵌入式系统等领域。一些知名的基于ARM的Soc处理器包括Apple的A系列芯片、高通骁龙系列、华为麒麟系列等。
ARM处理器分类
1)ARM经典处理器
ARM经典处理器主要分为ARM7、ARM9、ARM11三个系列。每个系列都有不同的处理器内核,用于满足不同的性能和功耗需求。
1. ARM7系列:ARM7系列是ARM最早的处理器系列,采用32位指令集,包括ARM7TDMI、ARM7TDMIS、ARM7EJ-S等子系列。主要应用于嵌入式系统、移动设备、音频处理、网络设备等领域。
2. ARM9系列:ARM9系列采用高性能的ARMv5指令集,包括ARM920T、ARM940T、ARM966J等子系列。主要应用于微控制器、数字信号处理、网络设备、智能手机等领域。
3. ARM11系列:ARM11系列采用高性能的ARMv6指令集,包括ARM1136JS、ARM1156T2S等子系列。主要应用于高性能处理器、网络设备、移动设备等领域。
此外,ARM还推出了Cortex-A系列和Cortex-R系列处理器,以满足不同领域的需求。
2)ARM Cortex应用处理器
ARM Cortex应用处理器是ARM公司推出的高性能处理器系列,主要面向基于虚拟内存的操作系统和用户应用。这个系列处理器采用了ARMv7指令集,并分为A、R和M三类,以满足不同应用的需求。
>Cortex-A系列处理器主要包括Cortex-A5、Cortex-A7、Cortex-A8、Cortex-A9、Cortex-A15等多个子系列。这些处理器适用于Android、iOS等操作系统,以及Web应用、游戏等用户应用。
>Cortex-R系列处理器主要应用于实时系统,包括Cortex-R4、Cortex-R5、Cortex-R7等多个子系列。这些处理器适用于汽车制动系统、动力传动解决方案等实时应用。
>Cortex-M系列处理器主要应用于微控制器,包括Cortex-M0、Cortex-M0+、Cortex-M3、Cortex-M4等多个子系列。这些处理器适用于智能测量、人机接口设备、汽车和工业控制系统等嵌入式应用。
ARM Cortex应用处理器具有高性能、低功耗、可扩展等优点,适用于各种不同的应用领域。同时,ARM公司提供了完整的开发工具和支持,帮助开发者快速开发出高效的嵌入式系统。
3)ARM Cortex嵌入式处理器
ARM Cortex嵌入式处理器是ARM公司推出的适用于嵌入式系统的处理器系列。这个系列处理器采用了ARMv7指令集或者ARMv8指令集(64位),并分为Cortex-M、Cortex-R和Cortex-A三个系列,以满足不同应用的需求。
>Cortex-A系列处理器主要包括Cortex-A5、Cortex-A7、Cortex-A8、Cortex-A9、Cortex-A15等多个子系列。这些处理器适用于Android、iOS等操作系统,以及Web应用、游戏等用户应用。
>Cortex-R系列处理器主要应用于实时系统,包括Cortex-R4、Cortex-R5、Cortex-R7等多个子系列。这些处理器适用于汽车制动系统、动力传动解决方案等实时应用。
>Cortex-M系列处理器主要应用于微控制器,包括Cortex-M0、Cortex-M0+、Cortex-M3、Cortex-M4等多个子系列。这些处理器适用于智能测量、人机接口设备、汽车和工业控制系统等嵌入式应用。
ARM Cortex嵌入式处理器具有高性能、低功耗、可扩展等优点,适用于各种不同的嵌入式应用领域。同时,ARM公司提供了完整的开发工具和支持,帮助开发者快速开发出高效的嵌入式系统。
4)ARM 专业处理器
ARM 专业处理器是 ARM 处理器的一种特殊类型,专门针对特定领域的计算需求进行优化。以下是一些 ARM 专业处理器的介绍:
1. ARM Cortex-A78:这是 ARM 最新的旗舰处理器,针对高端智能手机和平板电脑设计。它基于 ARMv8.2 架构,配备 64 位指令集和 16 位可选指令集扩展,具有高性能和低功耗的特点。
2. ARM Cortex-X1:这是 ARM 推出的全新高性能处理器,针对高端智能手机、平板电脑和游戏设备。它基于 ARMv8.5 架构,配备 64 位指令集和 16 位可选指令集扩展,旨在提供更高的性能和效率。
3. ARM Cortex-A55:这是 ARM 的中端处理器,针对智能手机、平板电脑和物联网设备。它基于 ARMv8.2 架构,配备 64 位指令集和 16 位可选指令集扩展,具有高性能和低功耗的特点。
4. ARM Cortex-A35:这是 ARM 的低功耗处理器,针对物联网设备和可穿戴设备。它基于 ARMv8.2 架构,配备 64 位指令集和 16 位可选指令集扩展,旨在提供最佳能效比。
5. ARM Cortex-A73:这是 ARM 的高端处理器,针对高端智能手机和平板电脑。它基于 ARMv8.2 架构,配备 64 位指令集和 16 位可选指令集扩展,具有高性能和低功耗的特点。
ARM 专业处理器针对不同领域的需求进行优化,以满足高性能、低功耗和高效能的要求。这些处理器广泛应用于智能手机、平板电脑、物联网、汽车电子、服务器等领域。
ARM架构服务器优势:
1. 更低的综合运营成本
2. 端-边-云 全场景同构互联与重构
3. 更高并发处理效率
4. 开放的生态系统、多元化的市场供应
ARM服务器的兴起
- 亚马逊的Graviton与EC2(弹性计算云)
- Marvell/Cavium公司的ThunderX系列 服务器处理器
- Ampere公司的eMAG/Altra系列服务器处理器
- 飞腾公司FT2000+系列服务器处理器
1.3 服务器技术基础
1.3.1 高性能处理器的存储器组织与片上互联
1. 多核系统的存储结构
处理器的性能得到充分发挥就必须考虑存储器带宽,还有速度差速需要考虑,所以要进行存储结构设计。
高性能处理器采用多级存储器来解决多存储问题。
(采用二级Cache, 甚至三级Cache等效处理速度)
根据处理器Cache的配置情况,把多核处理器存储结构分为以下四种:
| 分类 | Value |
|---|---|
| 片内私有L1 Cache 结构 | L1、L2两级组成(各核私有L1 Cache):L1 I Cache(指令)、L1 D Cache(数据)。多核共享的L2 Cache 在处理器芯片外。 |
| 片内私有L2 Cache 结构 | L1 I 、D多核自行保留,L2 Cache 移至处理器片内,L2 Cache为各核私有 |
| 片内共享L2 Cache 结构 | 片内共享L2 Cache (取代私有结构),且片内访问速度更高 |
| 片内共享L3 Cache 结构 | 片内私有L2 Cache 结构的基础上增加片内多核共享L3 Cache,提升了存储系统性能 |
多核处理器的Cache一致性
Cache 一致性(Cache Coherency)
存放数据的多副本,输入输出共享Cache
维护关键点在于 跟踪每一块Cache 状态,读写操作以及总线事件。
//不一致的可能原因:
1.可写数据的共享:采用全写法以及回写法,引起其他Cache中副本内容不一样
2.输入、输出活动:输入/输出设备直接接在了系统总线上,输入/输出将会导致不同
3.核间线程迁移:核间线程迁移,把一个尚未执行完的线程调度到另一个空闲的处理器内核中执行。
多核系统中,Cache的一致性使用软件和硬件维护。
软件维护
UMA 架构 和 NUMA 架构
根据 处理器对内存储器的访问方式 将 共享存储器的计算机系统 分为两大类:
UMA(Uniform Memory Access, 统一内存访问)
和NUMA(Non Uniform Memory Access,非同一内存访问)
UMA是对称多处理器计算机采用的组织方式架构,所有的处理器访问一个统一的存储空间,常以多通道方式组织。10
在UMA中,所有的处理器共享同一块内存,每个处理器访问内存的速度相同。这种架构设计相对比较简单,且可以实现较高的吞吐量。
NUMA架构属于分布式共享存储( Disributed Shared Memory ,DSM),存储器分布在不同节点上。
需要设置线程亲和性(Affinity)来实现,注意类型应用的普遍性,CC-NUMA(Cache Coherent Non-Uniform Memory Access,缓存一致性非统一内存访问),使用专门的一硬件来保证,使多处理器在单一系统下使用对称处理器架构一样的硬件层管理。
UMA(Non-Uniform Memory Access,非统一内存访问)是一种计算机内存架构设计。在NUMA中,处理器的内存访问速度与其距离内存位置的远近有关,因此,处理器访问内存的速度不是均匀的。NUMA架构通常被用于多处理器系统,例如对称多处理机(SMP)和多线程处理器。
1.NUMA架构的主要特点是内存控制器被集成到每个处理器核心中,因此每个处理器都能够直接访问其本地内存区域。本地内存是指与处理器位于同一NUMA节点上的内存。在NUMA中,处理器可以通过互联总线(Interconnect bus)访问其他处理器节点的内存,但是访问本地内存的速度更快。
2.由于NUMA架构的内存访问速度不均匀,因此在系统设计时需要考虑平衡内存访问的延迟和带宽。一种常见的策略是在处理器附近放置更多的内存,以便每个处理器能够更快地访问其所需的内存。
3.NUMA架构的优点是可以提供更高的内存带宽和更低的内存访问延迟。缺点是需要更多的内存和芯片,因此成本更高。另外,由于内存访问速度不均匀,因此需要进行优化以避免性能瓶颈。
4.NUMA架构在某些领域,例如高性能计算和大规模数据处理,表现出色。它也被用于一些现代的计算机系统,例如服务器和工作站。
多核处理器的核间通信机制
主流片上通信方式三种:总线共享Cache结构、交叉开关互联结构、片上网络结构。
1. 总线共享Cache结构
总线共享Cache结构是指多核处理器内核共享L2 Cache或L3 Cache,片上处理器内核、输入/输出接口以及主存储器接口通过连接各处理器内核的总线进行通信。这种方式的优点是结构简单、易于设计实现、通信速度高,但缺点是总线结构的可扩展性较差,只适用于处理器核心数较少的情况。
Inter的酷睿(CORE)、IBM的Power4\Power5,
等早期多核处理器采用总线共享结构。
2.交叉开关互联结构
交叉开关(Crossbar Switch)互联结构,提高数据带宽
交叉开关互联结构是一种用于多处理器系统的互连方式,它由一组二维阵列的开关组成,将多个处理器的总线连接起来。该结构采用空间分配机制,可以将多个处理器和存储器模块互连在一起,从而实现高速通信。
与总线互连方式相比,交叉开关互连结构具有更高的带宽和更低的延迟。它能够避免总线冲突,支持更多的处理器和存储器模块连接,并且具有更高的扩展性。然而,交叉开关互连结构也具有较高的复杂性和较高的硬件成本。
在交叉开关互连结构中,每个交叉开关可以连接多个处理器和存储器模块,通过交叉开关的路由功能,可以实现任意两个处理器或存储器模块之间的通信。该结构还可以通过多路复用技术来提高带宽利用率。
交叉开关互连结构是一种高性能、高扩展性的互连方式,适用于大规模多处理器系统。
比如AMD的速龙(Athlon)X2处理器,采用交叉开关开关核心与外部同信。
3. 片上网络结构
类似于并行计算机的互联网络结构,单芯集成大量资源
片上网络(Network on a Chip,NoC; On-chip Network)是一种用于多核处理器和片上系统的先进通信架构,通过在单芯片上集成大量的计算资源和通信网络,实现多个功能模块之间的高效通信。
片上网络借鉴了并行计算机的互连网络结构,将多个功能模块连接在一起。这些功能模块可以是处理核心、缓存、内存控制器等。每个功能模块通过路由器进行数据传输,通过多个路由器和通信链路实现并行、高带宽的通信。
>片上网络的优势在于可扩展性、低延迟和高带宽。它能够满足不断增长的处理核心数量和复杂的应用需求,同时优化通信性能和功耗。
>片上网络的设计旨在提供灵活性和可扩展性,以适应不同的芯片设计和应用需求。
片上网络可以采用多种拓扑结构,以下为几种常见的
环形拓扑、网状拓扑、树状拓扑…
class MeshToplogy:
class TreeTopology:
class StarTopology:
class MeshNoCTopology:
片上网络包括计算子系统、通信子系统两部分。
计算子系统(Processing Elements,PE)和通信子系统(Communication Subsystem)组成。
计算子系统 PE(Processing Element,处理单元),PE可由处理器内核、专业硬件、存储器阵列等构成。
通信子系统由 交换(Swich)节点及节点间互联线组成,负责连接PE,实现高速通讯。
计算子系统由多个处理器核(Processor Core)和其他功能单元组成,它们被集成在一个芯片上。每个处理器核可以执行自己的指令和操作,并且可以通过通信子系统与其他处理器核进行通信。
通信子系统由多个通信节点(Communication Node)和通信链路(Communication Link)组成。每个通信节点连接多个处理器核或功能单元,并与其他通信节点进行通信。通信链路是连接通信节点的物理通道,它可以采用不同的传输介质和技术,如金属线、光缆、无线传输等。
在二维网状网络片上网络结构图中,计算子系统和通信子系统之间通过连接线相互连接,形成一个相互交织的网状结构。这种结构可以提供高带宽、低延迟的通信能力,并且具有高度并行性和可扩展性。
内存顺序模型与内存屏障
一、 访存重排序
在并行多核系统中,访问顺序不一定一致。为提升性能,编译器或硬件往往会对指令序列进行 重排序(Recording) ,从而引入乱序排序(Out-of-Order Execution) 机制
1. 指令重排序三种类型
- 编译器优化导致的指令序列重排序。不改变程序语义的情况下,对指令重新安排语义。
- 指令级并行导致的指令序列重排序。现代高性能处理器采用指令级并行处理技术增加每个时钟周期执行的指令条数,从而提高处理器性能。如超标量指令技术通过处理器动态执行机制实现指令级并行,超长指令级技术采用编译器软件静态调度实现指令级并行,EPIC技术通过软硬件协作来提高系统性能。
- 内存系统引起的指令序列重排序。除了指令执行执行程序之外,通常还存在着内存系统感知到的内存访问顺序。处理器通常会采用Cache、读写缓冲区,使得程序运行时出现多核交互让Load和Restore看起来在乱序执行。
2. 三种不同的存储器访问顺序
1.程序顺序(Program Order):程序顺序是代码在特定处理器上运行时由代码本身给出的访存顺序,代表程序员预期的时间顺序。
2.执行顺序(Execution Order):执行顺序是指在给定处理器上运行时,特定的访存指令执行顺序。
3.感知顺序(Perceived Order):也称观察顺序。特定处理器感知到访存操作的程序。由于Cache访问、存储系统优化和系统互联操作本身以及其他存储器的访存操作顺序不一定相同,且架构也不一定相同。
某些情况下,程序正确性需要依赖内存访问顺序,而必须通过内存一致性模型加以规范。
二、 内存一致性模型
共享存储器上的多核系统上运行的必须要面对并行编程的问题。其中内存访问一致性需要软硬件协同配合,也就是软件与存储器之间的协议问题。
计算机系统层次结构上来看,计算机系统逻辑上是由裸机和不同层次的虚拟机构成的。内存模型分为软件内存模型(Software Memory Model)与硬件内存模型(Hardware Memory Model)两大类。
1. 软件内存模型
软件运行模型是一套关于程序员、编程语言、运行环境三者之间的一套协议。
软件内存模型是一种用于描述和模拟计算机内存系统的抽象模型。它可以帮助程序员更好地理解程序的内存访问行为,优化程序的性能,以及解决内存相关的并发问题。
软件内存模型通常包括以下几个方面的描述:
- 内存层次结构:描述内存系统的多层次结构,包括缓存、主存、磁盘等不同的存储层次。
- 内存访问语义:描述程序在内存中读取和写入数据的行为,包括读后写、写后读、置零等不同的内存访问语义。
- 内存一致性:描述不同线程对共享内存的访问应该具有一致性,即所有线程看到的内存状态应该是一致的。
- 内存排序规则:描述如何对内存操作进行排序,以确保多线程程序的一致性和正确性。
软件内存模型对于计算机系统的设计和优化具有重要的指导作用。在实际的软件开发过程中,程序员可以根据内存模型来优化程序的内存访问性能,以及避免内存相关的并发问题。同时,软件内存模型也是并发编程语言和并行计算领域的重要研究内容。
2. 硬件内存模型
处理器层次架构的内存一致性模型,可以理解为软硬件之间的一套协议
硬件内存模型是计算机硬件设计者为了实现多处理器系统和编译器优化而建立的内存一致性和访问行为的规范。它定义了程序在内存中的行为以及内存访问的可见性。
硬件内存模型通常包括以下几个方面的描述:
- 存储器一致性:描述不同处理器对共享内存的访问应该具有一致性,即所有处理器看到的内存状态应该是一致的。
- 内存访问语义:描述程序在内存中读取和写入数据的行为,包括读后写、写后读、置零等不同的内存访问语义。
- 内存一致序:描述对共享内存的访问应该遵循一定的顺序,以确保多处理器系统的一致性和正确性。
- 内存访问延迟:描述内存访问的时间延迟,包括读延迟和写延迟等。
硬件内存模型对于计算机系统的设计和优化具有重要的指导作用。在实际的计算机系统设计中,硬件设计者需要根据内存模型来优化内存访问性能,以及避免内存相关的并发问题。同时,硬件内存模型也是并发编程语言和并行计算领域的重要研究内容。
a.强一致性内存模型
强一致性内存模型(Strong Consistency Model) 是一种严格的内存一致性模型,它要求多处理器系统中所有对共享内存的访问都必须在一个一致的状态下完成。也就是说,在任何时刻,所有线程看到的内存状态都是一致的。
强一致性内存模型具有以下特点:
1. 所有内存访问操作必须在全局的顺序下完成,这个顺序对于所有线程都是一致的。
2. 如果一个线程对共享内存进行写操作,其他线程立即就能看到这个写操作的结果。
3. 如果一个线程对共享内存进行读操作,它只能看到在全局顺序中发生在读操作之前的写操作。
强一致性内存模型可以确保多线程程序的一致性和正确性,但是它也可能会限制程序的性能。因此,在实际的系统设计中,需要根据实际情况选择合适的内存模型来平衡性能和正确性。
b.弱一致性内存模型
弱一致性内存模型(Weak Consistency Memory Model) 是一种较为宽松的内存一致性模型,它允许在对共享内存的访问上存在一定的时间延迟,并且允许不同线程看到的内存状态存在一定的不一致性。
弱一致性内存模型具有以下特点:
1. 对共享内存的访问操作可能存在一定的顺序错乱,即在一个线程看来,其他线程对共享内存的访问可能不是按照预期的顺序进行的。
2. 如果一个线程对共享内存进行写操作,其他线程可能不能立即看到这个写操作的结果,而是需要等待一段时间后才能看到。
3. 如果一个线程对共享内存进行读操作,它可能只能看到在之前某个时间点之前的写操作,而不能看到最新的写操作。
弱一致性内存模型相对于强一致性内存模型来说更加宽松,因此它可以提高系统的性能,但是它也可能会降低程序的一致性和正确性。因此,在实际的系统设计中,需要根据实际情况选择合适的内存模型来平衡性能和正确性。
也就是说,强一致性内存模型能保证所有处理器、进程对数据的读取顺序保持一致,不能保证即为弱一致性内存模型
A. 顺序一致性内存模型
**顺序一致性内存模型(Sequential Consistency Memory Model)**是一种特殊的内存一致性模型,它要求程序在执行过程中,无论多少个处理器并行执行,无论程序是否同步,所有程序看到的操作执行顺序都是一致的。
顺序一致性内存模型具有以下特点:
1. 所有线程看到的操作执行顺序都是一致的。
2. 程序的执行结果与各处理器各自轮流执行后的结果相同,且各处理器内部的执行顺序由程序决定。
3. 所有操作都是原子的,即在执行过程中不会被其他线程打断。
4. 所有操作都具有立即可见性,即在一个线程中进行的操作会立即对其他所有线程可见。
顺序一致性内存模型为程序员提供了极强的内存可见性保证,但是它也可能会限制系统的性能。因此,在实际的系统设计中,需要根据实际情况选择合适的内存模型来平衡性能和可见性保证。
Load(加载) 和store(存储)操作一致
直观简单的强一致性内存模型,有时也称强排序模型,但这种模型效率低下,不允许处理器为提升并行性乱序执行程序,所以现代高性能处理器大多硬件实现不适用这种模型。
因此在设计处理器内存模型时,多把顺序一致性内存模型作为理论参考性模型来做一定程度上的放宽,来优化模型提升性能。
最典型的放宽是对不同的加载、存储类型的放宽:
- 加载之后的加载重排序(Loads Reordered After Loads)
- 存储之后的加载重排序(Loads Reordered After Stores)
- 加载之后的存储重排序(Stores Reordered After Loads)
- 存储之后的存储重排序(Stores Reordered After Stores)
在多处理器系统中,不同的内存访问类型可能具有不同的放宽级别。其中,最典型的放宽是对不同的加载和存储类型的放宽。
加载操作(Load)是从内存中读取数据到寄存器中的操作,而存储操作(Store)是将数据从寄存器中写入内存中的操作。在多处理器系统中,加载和存储操作可能会受到不同的放宽限制。
具体而言,在某些内存一致性模型中,加载和存储操作可能会被放宽,这意味着它们可以在不同的处理器之间以不同的顺序执行,而不必保持严格的顺序。这种放宽可以提高系统的性能,但也可能导致一些并发问题。
例如,在某些内存一致性模型中,加载操作可能会被放宽到可以在存储操作之前执行,这被称为“加载优先”或“先加载后存储”模型。相反,在另一些内存一致性模型中,存储操作可能会被放宽到可以在加载操作之后执行,这被称为“存储优先”或“先存储后加载”模型。
B. 全存储排序内存模型
如果对顺序一致性模型的基础上放宽程序中的写、读操作顺序(允许写晚于相应读操作)则称为全存储(Total Store Ordering,TSO)内存模型,一般出现在处理器中增加了写缓冲区(Write Buffer,或简称Store Buffer)的情况下。
全存储排序内存模型是一种内存一致性模型,它要求在对共享内存的访问上必须遵循一定的顺序,即所有对共享内存的访问操作都必须按照一种特定的顺序进行。
全存储排序内存模型具有以下特点:
1. 所有对共享内存的访问操作都必须按照一种特定的顺序进行,这个顺序对于所有线程都是一致的。
2. 如果两个线程对共享内存进行操作,它们之间的操作顺序不能有交叉。
3. 如果一个线程对共享内存进行写操作,其他线程必须按照这个写操作所在的位置对共享内存进行读取,否则将无法获得正确的结果。
全存储排序内存模型可以确保多线程程序的一致性和正确性,但是它也可能会限制程序的性能。因此,在实际的系统设计中,需要根据实际情况选择合适的内存模型来平衡性能和正确性。
E.g.:通过Cache写回(Copy-Back)方式以批处理模式刷新写缓存区,合并多次操作,减少总线占用,但可能与Load造成 乱序执行
且 每个处理器上写缓冲区是私有的可能造成 多核一致性问题
上图:多核系统多级存储器架构
在该模型中,CPU0先收到写指令,然后再收到读指令。CPU0写入缓冲区之后,Cache缺失,但为执行完操作,写入操作结果可能未写入主存
全存储(TSO)排序模型只放写-读操作顺序,能保证所有Store指令之间的执行顺序与代码顺序一致。
C. 部分存储排序内存模型
在全存储(TSO)模型 的基础上进一步放宽写-写操作,就变为**部分存储排序(Partial Store Order,PSO)**内存模型。在这种模型中向存储区写入的指令如果存在地址相关性,仍能保持顺序执行,但不存在相关性的写写操作则允许乱序执行。
继续用这个图:
上图:多核系统多级存储器架构
连续执行两次地址不相关写操作
部分存储排序内存模型是一种内存一致性模型,它允许在对共享内存的访问上存在一定的顺序错乱,但是要求在对共享内存的访问上必须遵循一定的顺序,即所有对共享内存的访问操作都必须按照一种特定的顺序进行。
PSO中,部分存储排序内存模型具有以下特点:第一次Cache缺失。第二次写命中,都先写入缓存区,但第二次会先执行完成,第一次要等待Cache(缓存)空间被填充数据才执行完毕,因此存在数据不一致的风险。
1. 对共享内存的访问操作可能存在一定的顺序错乱,即在一个线程看来,其他线程对共享内存的访问可能不是按照预期的顺序进行的。
2. 如果两个线程对共享内存进行操作,它们之间的操作顺序不能有交叉。
3. 如果一个线程对共享内存进行写操作,其他线程必须按照这个写操作所在的位置对共享内存进行读取,否则将无法获得正确的结果。
部分存储排序内存模型相对于全存储排序内存模型来说更加宽松,因此它可以提高系统的性能,但是它也可能会降低程序的一致性和正确性。因此,在实际的系统设计中,需要根据实际情况选择合适的内存模型来平衡性能和正确性。
D. 宽松内存顺序内存模型
如果把读-写、读-读 操作也进一步放开,只要与地址无关的指令都可以乱序执行。
宽松内存顺序内存模型(Relaxed Memory Order,RMO) 是一种内存一致性模型,它允许程序员在内存访问上拥有更大的自由度,但同时也要求程序员必须显式地标记出对内存的访问操作。
宽松内存顺序内存模型具有以下特点:
- 程序员必须显式地标记出对内存的访问操作,例如使用volatile关键字或memory barrier指令。
- 内存访问操作可能会在不同的线程之间出现顺序错乱,但是它们必须遵循一种特定的顺序,即所有对共享内存的访问操作都必须按照一种特定的顺序进行。
- 如果一个线程对共享内存进行写操作,其他线程必须按照这个写操作所在的位置对共享内存进行读取,否则将无法获得正确的结果。
宽松内存顺序内存模型相对于其他内存一致性模型来说更加宽松,因此它可以提高系统的性能,但是它也可能会降低程序的一致性和正确性。因此,在实际的系统设计中,需要根据实际情况选择合适的内存模型来平衡性能和正确性。
由此可见,从 顺序一致性内存模型 到 全存储排序内存模型,再到 部分存储排序内存模型 和 宽松内存顺序内存模型。保持顺序一致性的能力是由强减弱的
很多硬件相关的强一致性顺序模型的强制禁止乱序是没有必要的
而弱一致性模型,保证其一致性的责任就落到了程序员手上。
几种主流处理器架构:
- 早期DEC公司的Alpha服务器,比较严格的硬件弱内存模型。
- 类似PowerPC、ARM和安腾(Itanium)弱内存排序(Weak Memory Ordering,WMO) 的内存模型(比Alpha增加了数据依赖性顺序)。
- 应用广泛的Intel 64 (x86-x64)架构使用过程一致性(Process Consistency )内存模型,基本属于强一致性顺序模型。
- 有些处理器架构支持多种内存一致性模型。如RISC-V处理器默认内存弱内存排序模型,也可使用全存储排序内存模型。
三、 内存屏障指令
内存屏障指令(Memory Barrier Instruction) 是一类同步屏障指令,用于确保在对内存的访问操作中,先发生的操作(包括读写操作)在后发生的操作之前执行完毕。
内存屏障指令可以保证不同线程之间的内存访问操作的顺序性,从而确保多线程程序的正确性。
现代计算机系统中,有多种类型的内存屏障指令,例如:
- 内存栅栏(Memory Barrier):是一类同步屏障指令,用于确保在对内存的随机访问操作中的一致性。
- 指令栅栏(Instruction Barrier):是一类同步屏障指令,用于确保在对内存的随机访问操作中的一致性。
- 内存栅障(Memory Barrier Primitive):是一类同步屏障指令,用于确保在对内存的随机访问操作中的一致性。
这些内存屏障指令的具体实现和使用方法因不同的计算机系统而异,需要参考相关的硬件和操作系统文档进行了解和应用。
以下用PowerPC、Power处理器的三条同步指令为例
1. 输入输出控制指令eieio
Enforce In-order Execution of Input/Output(强制按顺序执行输入/输出操作),也即在前面所有load和store指令执行完毕之后再执行后续的指令。
//下面为一段向外设发送两段数据的代码
1. while(TDRE == 0); //TDRE表示映射到另一个内存地址的状态寄存器
2. TDR = char1; //TDR表示内存空间的发送数据缓冲器
3. asm(" eieio"); //加入eieio指令会强制执行上一行再执行下一行
4. while(TDRE ==0); //取0发射器缓冲器不空
5. TDR = char2; //确保程序执行不出错
2. 同步指令sync
sync指令功能为等待所有前序操作执行完毕。
PowerPC架构中,定义了执行同步(Execution Synchronizing)概念:如果某条指令i导致指令分发暂停,并且只有当所有正在执行的所有指令都已执行完成i并报告了触发的异常时,指令才算执行完毕。
而sync指令除了执行同步,还要等待所有被挂起的内存访问结束,并且发出一个地址广播周期。可见执行这条指令的性能代价很大。
使用比如让处理器进入低功耗模式使用sync指令。(寄存器编程)
//进入低功耗模式的伪代码
1. asm(" sync");//等待所有被挂起的内存访问结束
2. //进入低功耗模式
3. asm(" sync");
3. 同步指令isync
isync指令覆盖了sync指令的功能,并且在等待所有前序指令执行完毕的同时还清空指令队列,也即按照新的处理器上下文重新加载指令队列。处理器把这种指令的操作称为指令上下文同步(Instruction Context Synchronizing)。系统调用指令、中断返回指令都需要指令上下文同步。
举例而言,当使用写操作指令激活指令 Cache 时,指令队列中可能己经存在若干指令了,此时先执行 isxne 指令就会让后续指令进人指令 Cache。
此外,Power 处理器还有两条专用于多处理器间共享资源同步指令 lwarx 和
stwcx.
> lwarx(Load Word and Reserve Index ):这个指令用于读取内存中的某个字(32位)数据,并将其存储到某个寄存器中。更重要的是,它在读取数据的同时,会在内存中的某个特定位置(通常是一个地址)设置一个"reservation"标记,表示该资源已被一个特定的处理器"预定",其他处理器在尝试读取或修改这个资源时将会失败。这个指令通常用于实现资源访问的互斥,即一次只有一个处理器可以访问或修改某个资源。
> stwcx(Store Word Conditional Index):这个指令用于将某个寄存器中的字数据写入到内存中。如果写入操作成功,且内存中的"reservation"标记仍然存在,那么这个写入操作就会失败,并且stwcx指令会设置一个条件代码,表示该资源仍然被其他处理器"预定"。这个指令通常用于检查资源是否已经被其他处理器锁定,如果已经被锁定,那么当前处理器就会停止进一步的访问操作,避免产生冲突。
每种处理器架构都有其自身定义的内在屏障指令,以支持其内存一致性模型。这对需要在不同平台之间迁移程序是个挑战。而类似Java 语言这样的软件开发环境在往限制程序员直接使用内存屏障,而是要求程序员使用互斥 原语实现同步访问。
在Java中,程序员可以使用一些内置的同步原语,如synchronized关键字和java.util.concurrent包中的各种锁和并发工具,来实现对共享资源的互斥访问。这些原语在内部使用了底层的内存屏障和其他的硬件特性来确保线程安全。
谢谢大家