目录
1.Yolov8介绍
2.安全帽数据集介绍
3.InternImage介绍
4.训练结果分析
1.Yolov8介绍
Ultralytics YOLOv8是Ultralytics公司开发的YOLO目标检测和图像分割模型的最新版本。YOLOv8是一种尖端的、最先进的(SOTA)模型,它建立在先前YOLO成功基础上,并引入了新功能和改进,以进一步提升性能和灵活性。它可以在大型数据集上进行训练,并且能够在各种硬件平台上运行,从CPU到GPU。
具体改进如下:
-
Backbone:使用的依旧是CSP的思想,不过YOLOv5中的C3模块被替换成了C2f模块,实现了进一步的轻量化,同时YOLOv8依旧使用了YOLOv5等架构中使用的SPPF模块;
-
PAN-FPN:毫无疑问YOLOv8依旧使用了PAN的思想,不过通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8将YOLOv5中PAN-FPN上采样阶段中的卷积结构删除了,同时也将C3模块替换为了C2f模块;
-
Decoupled-Head:是不是嗅到了不一样的味道?是的,YOLOv8走向了Decoupled-Head;
-
Anchor-Free:YOLOv8抛弃了以往的Anchor-Base,使用了Anchor-Free的思想;
-
损失函数:YOLOv8使用VFL Loss作为分类损失,使用DFL Loss+CIOU Loss作为分类损失;
-
样本匹配:YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner匹配方式

框架图提供见链接:Brief summary of YOLOv8 model structure · Issue #189 · ultralytics/ultralytics · GitHub
2.安全帽数据集介绍
数据集大小3241张,train:val:test 随机分配为7:2:1,类别:hat



3.InternImage介绍

论文:https://arxiv.org/abs/2211.05778
代码:GitHub - OpenGVLab/InternImage: [CVPR 2023 Highlight] InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
理论部分参考知乎:CVPR2023 Highlight | 书生模型霸榜COCO目标检测,研究团队解读公开 - 知乎
不同于近来聚焦于大核的CNN方案,InternImage以形变卷积作为核心操作(不仅具有下游任务所需的有效感受野,同时具有输入与任务自适应空域聚合能力)。所提方案降低了传统CNN的严格归纳偏置,同时可以学习更强更鲁棒的表达能力。ImageNet、COCO以及ADE20K等任务上的实验验证了所提方案的有效性,值得一提的是:InternImage-H在COCO test-dev上取得了新的记录65.4mAP。
InternImage通过重新设计算子和模型结构提升了卷积模型的可扩展性并且缓解了归纳偏置,包括(1)DCNv3算子,基于DCNv2算子引入共享投射权重、多组机制和采样点调制。
(2)基础模块,融合先进模块作为模型构建的基本模块单元
(3)模块堆叠规则,扩展模型时规范化模型的宽度、深度、组数等超参数。

研究者基于DCNv2算子,重新设计调整并提出DCNv3算子,具体改进包括以下几个部分。
(1) 共享投射权重。与常规卷积类似,DCNv2中的不同采样点具有独立的投射权重,因此其参数大小与采样点总数呈线性关系。为了降低参数和内存复杂度,借鉴可分离卷积的思路,采用与位置无关的权重代替分组权重,在不同采样点之间共享投影权重,所有的采样位置依赖性都得以保留。
(2) 引入多组机制。多组设计最早是在分组卷积中引入,并在Transformer的多头自注意力中广泛使用,它可以与自适应空间聚合配合,有效地提高特征的多样性。受此启发,研究者将空间聚合过程分成若干组,每个组都有独立的采样偏移量。自此,单个DCNv3层的不同组拥有不同的空间聚合模式,从而产生丰富的特征多样性。
(3) 采样点调制标量归一化。为了缓解模型容量扩大时的不稳定问题,研究者将归一化模式设定为逐采样点的Softmax归一化,这不仅使大规模模型的训练过程更加稳定,而且还构建了所有采样点的连接关系。

源码详见:涨点神器:Yolov8引入CVPR2023 InternImage:注入新机制,扩展DCNv3,助力涨点,COCO新纪录65.4mAP!-CSDN博客
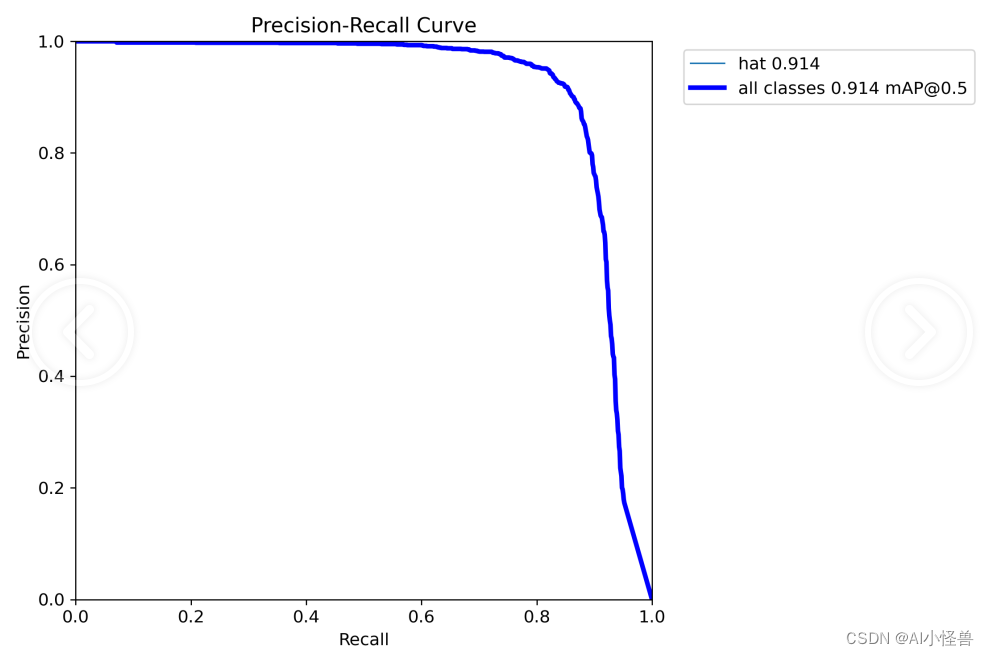
4.训练结果分析
训练结果如下:
mAP@0.5 0.897提升至0.914