目录
1. 数组名的理解
2. 使⽤指针访问数组
3. ⼀维数组传参的本质
4. 冒泡排序
5. ⼆级指针
6. 指针数组
7. 指针数组模拟⼆维数组
1. 数组名的理解
首先先看一个代码
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("arr = %p\n", arr);
return 0;
} 
打印结果如下,发现打印的两个地址其实是相同的。所以数组名其实就是数组的首元素的地址(但并不是全部的数组名都是数组首元素的地址)。
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("%d\n", sizeof(arr));
return 0;
}这串代码打印出的arr则是 40 这就是特例!!!!总共有两个特例
sizeof(数组名),这里的数组名表示整个数组而不是首元素地址。计算得出的40是整个数组所占的字节。
&数组名,这里的数组名
#include <stdio.h> int main() { int arr[10] = { 1,2,3,4,5,6,7,8,9,10 }; printf("&arr[0] = %p\n", &arr[0]); printf("&arr[0]+1 = %p\n", &arr[0]+1); printf("arr = %p\n", arr); printf("arr+1 = %p\n", arr+1); printf("&arr = %p\n", &arr); printf("&arr+1 = %p\n", &arr+1); return 0; }表示取的是整个数组的地址。(整个数组的地址如果加一则跳过整个数组,如果只是首元素的地址,那加一只是到下一个元素的地址。)
这里的三个打印结果都一样,但是和上面结论一样,其实12 和 3 是不同的。在看下面的这一串代码。
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("&arr[0]+1 = %p\n", &arr[0]+1);
printf("arr = %p\n", arr);
printf("arr+1 = %p\n", arr+1);
printf("&arr = %p\n", &arr);
printf("&arr+1 = %p\n", &arr+1);
return 0;
}结果如下
&arr[ 0 ] = 0077F 820&arr[ 0 ]+ 1 = 0077F 824arr = 0077F 820arr+ 1 = 0077F 824&arr = 0077F 820&arr+ 1 = 0077F 848
第一个printf 打印的是首元素的地址
第二个 printf 打印的是首元素地址加一的地址,发现只是加4 所以只是跳过了4个字节一个整型。
第三个 也是打印首元素的地址。(不是特殊情况下数组名就是数组首元素地址)
第四个和 第二个同理。
第5个 printf &arr 是特殊情况 它取得是整个数组的地址。但就算它指向是整个数组,他也是得从第一个元素的地址开始指。所以和1 3 相同。
第6个 printf 就不同了,他加了40个字节(16进制数字),所以如果代表的是整个数组的地址的话加一会跳过整个数组。
2. 使⽤指针访问数组
int main()
{
int arr[10] = { 0 };
//输⼊
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
//输⼊
int* p = arr;
for (i = 0; i < sz; i++)
{
scanf("%d", p + i);
//scanf("%d", arr+i);//也可以这样写
}
//输出
for (i = 0; i < sz; i++)
{
printf("%d ", *(p + i));
}
return 0;
}观察这个代码。
我们用指针p 变量 = arr,这里的arr代表的是数组首元素的地址。所以 p 指针中存放的就是数组首元素的地址。之后通过scanf 和 for循环 让p + i 的地址 输入数据。
最后打印 ,这里打印可以用p的地址 也可以用arr地址。打印出来的结果是一样的,说明指针可以访问数组。
3. ⼀维数组传参的本质
#include <stdio.h>
void test(int arr[])
{
int sz2 = sizeof(arr)/sizeof(arr[0]);
printf("sz2 = %d\n", sz2);
}
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int sz1 = sizeof(arr)/sizeof(arr[0]);
printf("sz1 = %d\n", sz1);
test(arr);
return 0;
}
这串代码打印出来后 sz1 = 10,sz =1;
数组传参本质就是,传数组名就是传数组首元素的地址,所以sz2 =1,但 sz1求得是函数外的数组大小所以 = 10.
sizeof(arr)计算的是一个地址的字节大小,而不是数组的大小。所以在函数内部求不出数组的元素个数。(用指针可以)。
void test(int arr[])//参数写成数组形式,本质上还是指针
{
printf("%d\n", sizeof(arr));
}
void test(int* arr)//参数写成指针形式
{
printf("%d\n", sizeof(arr));//计算⼀个指针变量的⼤⼩
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
test(arr);
return 0;
}这里用两个函数来查看数组大小。结果发现 第一个test 打印出来是 2,第二个 是 10.
说明用指针来接收数组名,其实是可以计算出数组大小的,因为指针指向的是数组首元素的地址,所以间接就可以计算元素个数。
4. 冒泡排序
void bubble_sort(int arr[], int sz)//参数接收数组元素个数
{
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
for (j = 0; j < sz - i - 1; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[] = { 3,1,7,5,8,9,0,2,4,6 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}详情可看我的另一篇博客冒泡排序(升序版),普通思路和优化思路,降序也是同理!-CSDN博客
5. ⼆级指针
指针变量也是变量,那说明也是可以被接收的,那怎么接收呢?
就是用到二级指针的内容

6. 指针数组
指针数组,就是指针的数组,一个数组用来存放指针
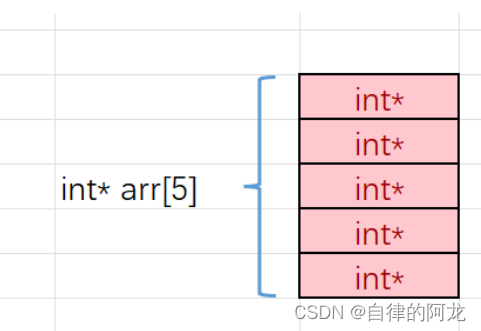
指针数组的每个元素都是一个指针指向一个区域,代表的又是不一样的东西。
7. 指针数组模拟⼆维数组
int main()
{
int arr1[] = { 1,2,3,4,5 };
int arr2[] = { 2,3,4,5,6 };
int arr3[] = { 3,4,5,6,7 };
//数组名是数组⾸元素的地址,类型是int*的,就可以存放在parr数组中
int* parr[3] = { arr1, arr2, arr3 };
int i = 0;
int j = 0;
for (i = 0; i < 3; i++)
{
for (j = 0; j < 5; j++)
{
printf("%d ", parr[i][j]);
}
printf("\n");
}
return 0;
}很简单,先定义几个你想要的数组。
再用一个指针的数组接收他们,其中接收的都是他们首元素的地址。
再用 两层for 循环 一个个打印出即可,arr1 存的是 int* parr【0】里,arr2 ,arr3 同理。
在下面for循环打印中parr【i】表示取出的是第几个数组的首元素地址。parr【i】【j】就是取出这个数组中的全部元素并打印出来。parr[i][j] 的原型就是 *(*(parr+i)+j ),先取出parr+i 的元素 再取出 parr +i + j 的元素。即可