3.0.概述
本章概述了系统级的Linux内存性能工具。本章将讨论这些工具可以测量的内存统计信息,以及如何使用各种工具收集这些统计结果。阅读本章后,你将能够:
- 理解系统级性能的基本指标,包括内存的使用情况。
- 明白哪些工具可以检索这些系统级性能指标。
3.1 内存性能统计信息
每一种系统级Linux性能工具都提供了不同的方式来提取类似的统计结果。虽然没有工具能显示全部的信息,但是有些工具显示的统计信息是相同的。本章开始将对这些统计数据的详细信息进行说明,之后在介绍工具时会引用这些描述。
3.1.1内存子系统和性能
在现代处理器中,与CPU执行代码或处理信息相比,向内存子系统保存信息或从中读取信息一般花费的时间更长。通常,在CPU执行指令或处理数据前,它会消耗相当多的空闲时间来等待从内存中取出指令和数据。处理器用不同层次的高速缓存(cache)来弥补这种缓慢的内存性能。工具,如oprofile,可以显示各种处理器高速缓存缺失所发生的位置。
3.1.2 内存子系统(虚拟存储器)
任何给定的Linux系统都有一定容量的RAM或物理内存。在这个物理内存中寻址时,Linux将其分成块或内存“页”。当对内存进分配或传送时,Linux操作的单位是页,而不是单个字节。在报告一些内存统计数据时,Linux内核报告的是每秒页面的数量,该值根据其运行的架构可以发生变化。清单3.1创建了一个小的应用程序来显示当前架构中每一页的字节数。
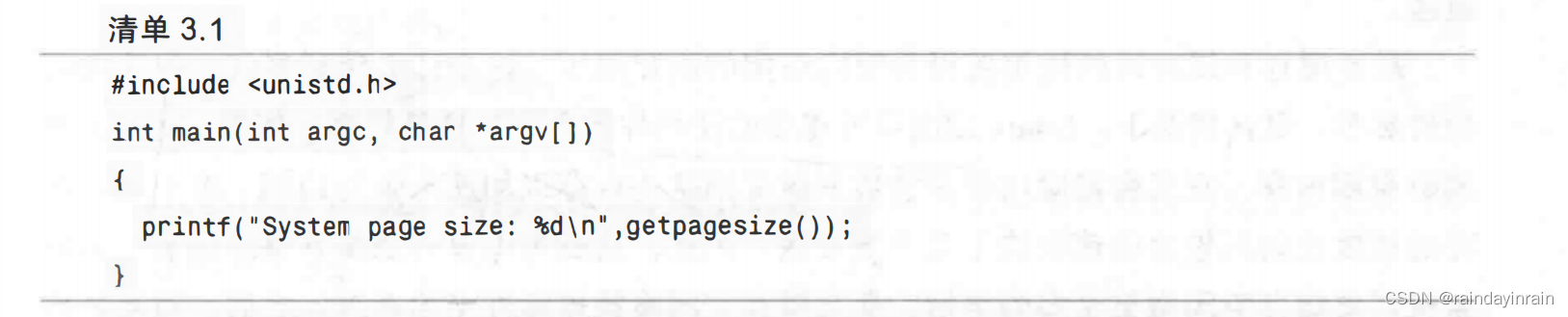
对IA32架构而言,页面大小为4KB。极少数情况下,这些页面大小的内存块会导致极高的跟踪开销,所以,内核用更大的块来操作内存,这些块被称为HugePage(大页面)。它们的容量为2048KB,而不是4KB,这大大降低了管理庞大内存的开销。某些应用,如Oracle,用这些大页面加载内存中的大量数据,同时又最小化Linux内核的管理开销。如果HugePage不能完全被填满,就会浪费相当多的内存。一个半填充的普通页面浪费2KB内存,而一个半填充的HugePage就会浪费1024KB的内存。
Linux内核可以分散收集这些物理页面,向应用程序呈现出一个精心设计的虚拟内存空间。
3.1.2.1 交换(物理内存不足)
所有系统RAM芯片的物理内存容量都是固定的。即使应用程序需要的内存容量大于可用的物理内存,Linux内核仍然允许这些程序运行。Linux内核使用硬盘作为临时存储器,这个硬盘空间被称为交换分区(swap space)。
尽管交换是让进程运行的极好的方法,但它却慢的要命。与使用物理内存相比,应用程序使用交换的速度可以慢到一千倍。如果系统性能不佳,确定系统使用了多少交换通常是有用的。
3.1.2.2缓冲区(buffer)和缓存(cache)(物理内存太多)
相反,如果你的系统物理内存容量超过了应用程序的需求,Linux就会在物理内存中缓存近期使用过的文件,这样,后续访问这些文件时就不用去访问硬盘了。对要频繁访问硬盘的应用程序来说,这可以显著加速其速度,显然,对经常启动的应用程序而言,这是特别有用的。应用程序首次启动时,它需要从硬盘读取;但是,如果应用程序留着缓存中,那它就需要从更快速的物理内存读取。这个硬盘缓存不同于前面章节提到的处理器缓存。除了oprofile、valgrind和kcachegrind之外,大多数工具在报告“缓存”的统计信息时实际指的是硬盘缓存(磁盘高速缓存)。
除了高速缓存,Linux还使用了额外的存储作为缓冲区。为了进一步优化应用程序,Linux为需要被写回硬盘的数据预留了存储空间。这些预留空间被称为缓冲区。如果应用程序要将数据写回硬盘,通常需要花费较长时间,Linux让应用程序立刻继续执行,但将文件数据保存到内存缓冲区。在之后的某个时刻,缓冲区被刷新到硬盘,而应用程序可以立即继续。
高速缓存(磁盘高速缓存)和缓冲区(内存高速缓存)的使用使得系统内空闲的内存很少,这会让人感到泄气,但这未必是件坏事。默认情况下,Linux试图尽可能多的使用你的内存。这是好事。如果Linux侦测到有空闲内存,它就会将应用程序和数据缓存到这些内存以加速未来的访问。由于访问内存的速度比访问硬盘的速度快了几个数量级,因此,这就可以显著地提升整体性能。如果系统需要缓存空间做更重要的事情,那么缓存空间将被擦除并交给系统。之后,对原来被缓存对象的访问就需要转向硬盘来满足。
3.1.2.3活跃与非活跃内存
活跃内存是指当前被进程使用的内存。不活跃内存是指已经被分配了,但暂时还未使用的内存。这两种类型的内存没有本质上的区别。需要时,Linux找出进程最近最少使用的内存页面,并将它们从活跃列表移动到不活跃列表。当要选择把哪个内存页交换到硬盘时,内核就从不活跃内存列表中进行选择。
3.1.2.4高端与低端内存
对拥有1GB或更多物理内存的32位处理器(比如IA32)来说,Linux管理内存时必须将其分为高端与低端内存。高端内存不能直接被Linux内核访问,而是必须在使用前映射到低端内存范围内。64位处理器(比如AMD64/EM6T、Alpha或Itanium)没有这个问题,因为它们可以直接寻址当前系统可用的额外内存。
3.1.2.5内核的内存使用情况(分片)
除了应用程序需要分配内存外,Linux内核也会为了记账的目的消耗一定量的内存。记账包括,比如跟踪从网络或磁盘I/O来的数据,以及跟踪哪些进程正在运行,哪些正在休眠。为了管理记账,内核有一系列缓存,包含了一个或多个内存分片。每个分片为一组对象,个数可以是一个或多个。内核消耗的内存分片数量取决于使用的是Linux内核的哪些部分,而且还可以随着机器负载类型的变化而变化。
3.2 Linux性能工具:CPU与内存
现在开始讨论性能工具,它们能使你抽取前面所述的那些内存性能信息。
3.2.1 vmstat(I)
如前所见,vmstat能提供多个不同方面的系统性能信息——尽管它的主要目的(如同下面展示的一样)是提供虚拟内存系统信息。除了前一章描述的CPU性能统计信息外,它还可以告诉你下述信息:
1.使用了多少交换分区。
2.物理内存是如何被使用的。
3.有多少空闲内存。
你可以看到,vmstat(通过其显示的统计数据)在一行文本中就提供了关于系统运行状况与性能的丰富信息。
3.2.1.1系统范围内与内存相关的系统级选项
vmstat除了提供CPU统计信息外,你还可以通过如下命令行调用vmstat来调查内存统计信息:vmstat [-a] [·S] [-m]
和前面一样,你可以在两种模式下运行vmstat:采样模式和平均模式。添加命令行选项能让你获得Linux内核使用内存的性能统计信息。表3-1给出了vmstat可接受的选项。

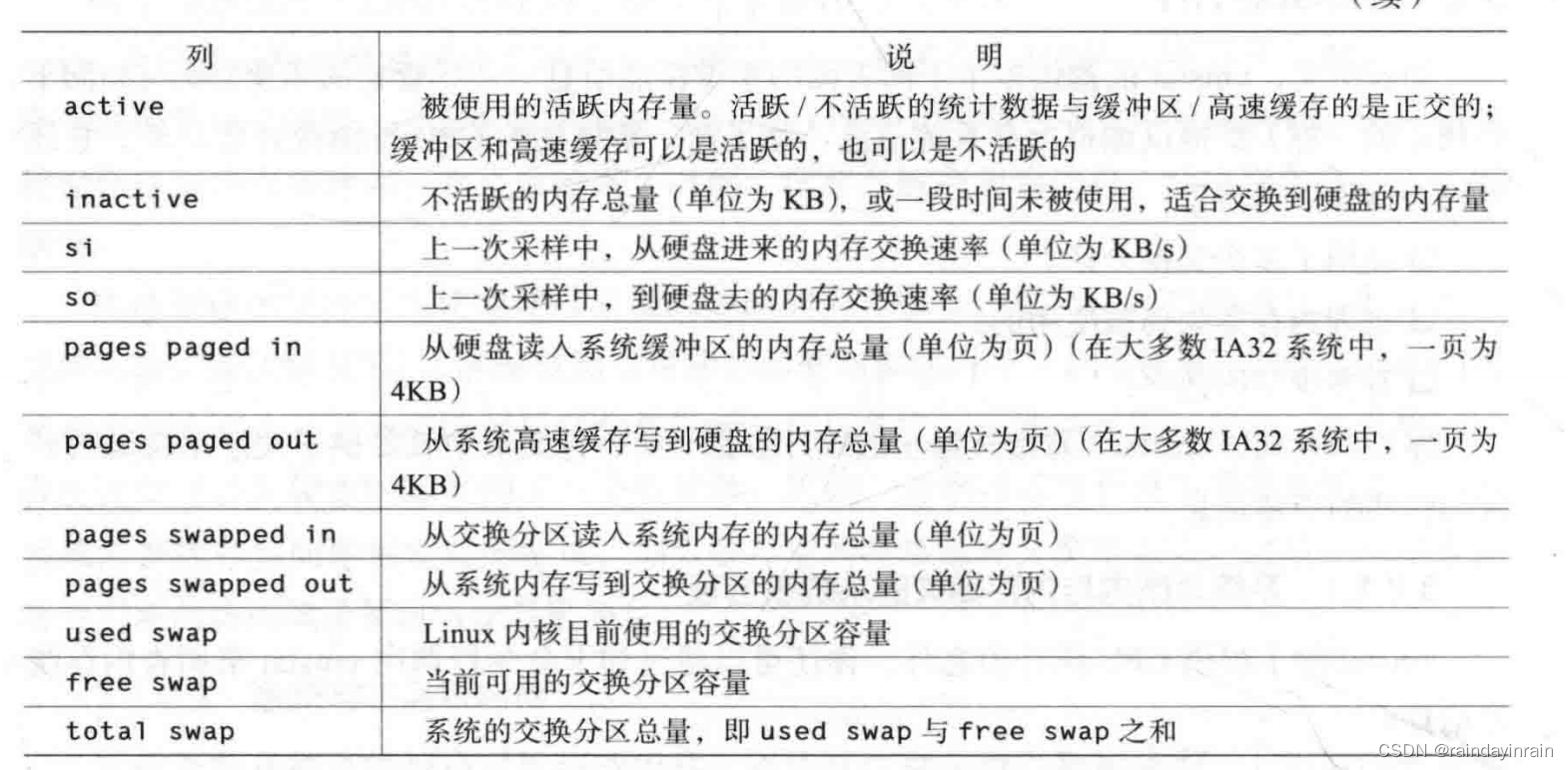
表3-2所示列表为vmstat可以提供的内存统计信息。与CPU统计信息一样,当运行于普通模式时,vmstat提供的第一行信息为所有速率统计信息(so和si)的均值以及所有数字统计信息的瞬时值(swpd、free、buff、cache、active和inactive)。

对给定机器而言,vmstat能提供其虚拟存储系统当前状态的良好概览。虽然它不会为每个可用的Linux每次性能统计数据提供一个完整且详细的列表,但它给出的简洁输出可以表明系统内存整体上是如何被使用的。
3.2.1.2用法示例
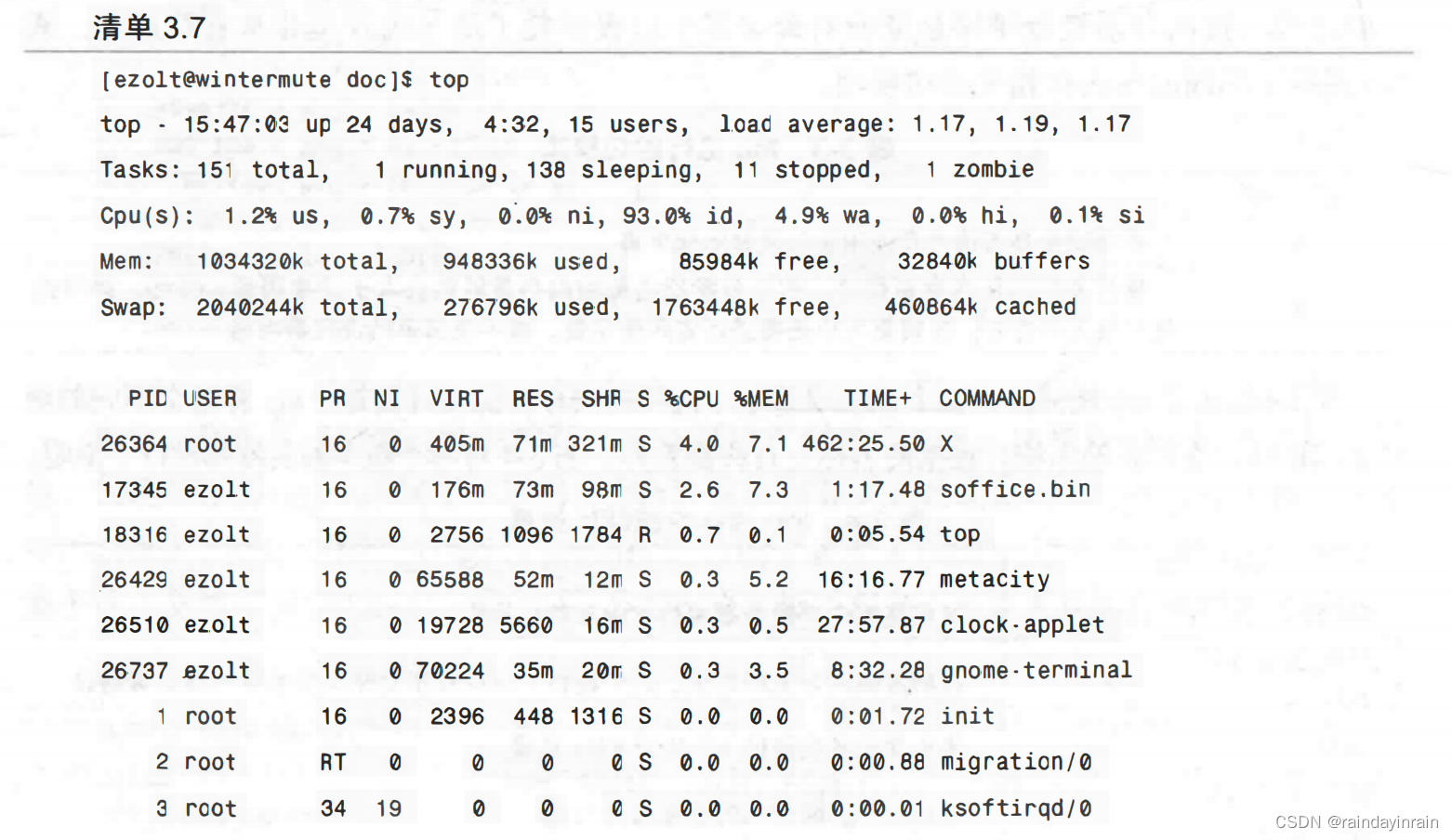
如前面章节所见,清单3.2中,如果vmstat调用时没有使用任何命令行选项,它显示的是从系统启动开始的性能统计数据的均值(si和so),以及其他统计信息的瞬时值(swpd、free、buff和cache)。本例中,我们可以看到系统已经有大约500MB的内存交换到了硬盘。约14MB系统内存是空闲的。约4MB用于缓冲区,以保存还未刷新到硬盘的数据。约627MB用于硬盘缓存,以保存过去从硬盘读取的数据。


在清单3.3中,我们要求vmstat显示活跃与非活跃页面的数量信息。非活跃页面的数量表明了有多少内存可以交换到硬盘,有多少内存是当前可用的。本例中,我们可以看到活跃内存有1310MB,只有78MB被认为是不活跃的。该机拥有大量内存,且大部分都被使用,处于活跃状态。


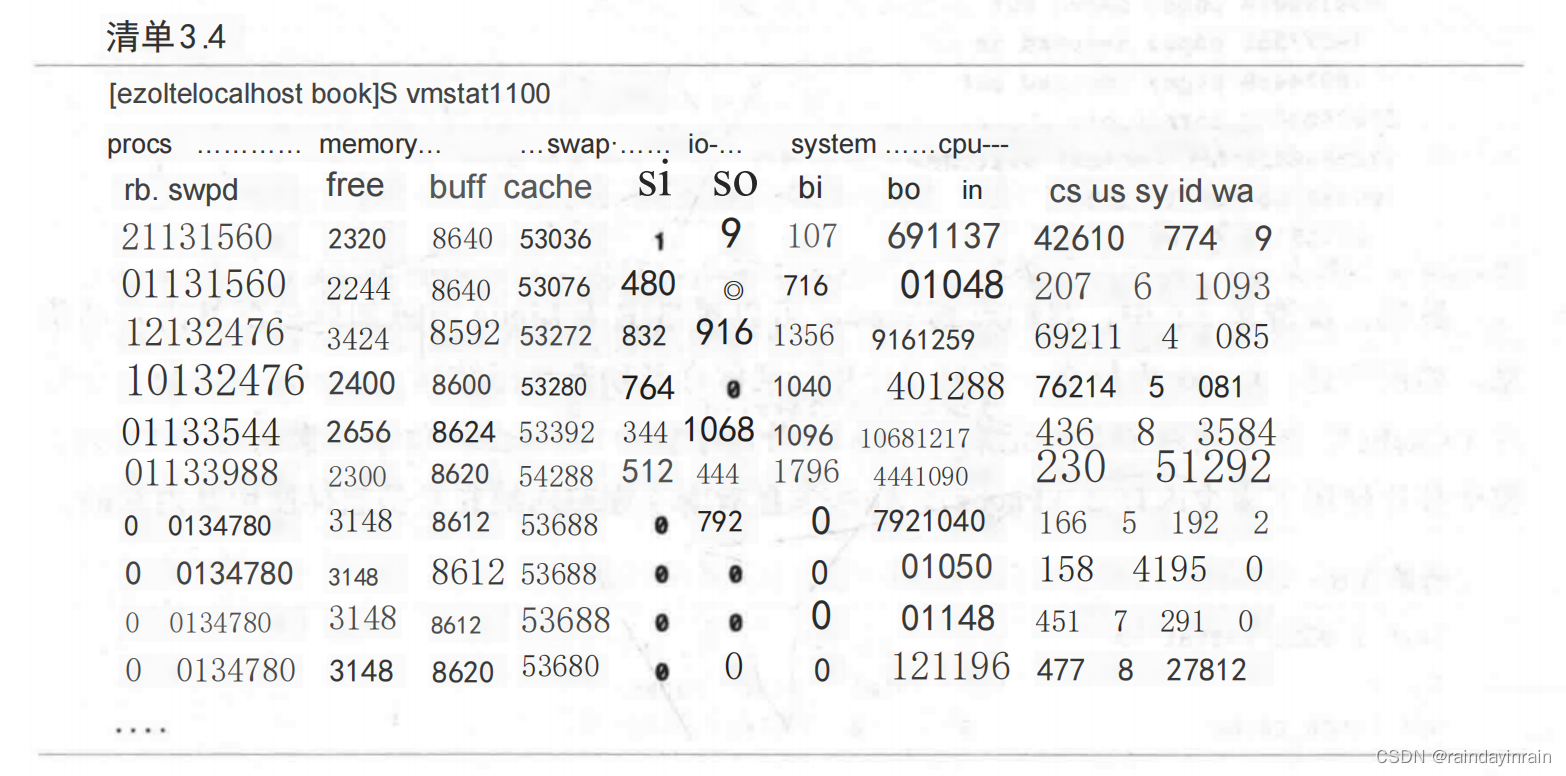
接下来,在清单3.4中,我们看到的是一个不同的系统,其内存数据交换频繁。si列显示在每个采样期间,数据的读交换率分别为480KB、832KB、764KB、344KB和512KB。so 列显示在每个采样期间,内存数据写交换率分别为9KB、0KB、916KB、0KB、1068KB、444KB和792KB。这些结果可以说明该系统没有足够的内存来处理所有的运行进程。当一个进程的内存被保存下来,以便为之前已经交换到硬盘的应用程序腾位置时,就会出现高频率的换入和换出。如果有两个运行程序需要的内存量都超过了系统可提供的量,后果就会很糟糕。比如,两个进程都在使用大量内存,且它们都试图同时运行,而每个进程都可以导致另一个的内存被写交换。当一个程序需要一块内存时,它就会把另一个程序需要的一块内存踢出去。而当另一个应用程序开始运行时,它又会把第一个程序正在使用的一块内存踢出去,并等待自己的内存块从交换分区加载进来。这可能会导致两个应用程序出现停顿,以等待它们的内存从交换分区取回,然后才能继续执行。只要一个程序进步一点点,它就会将另一个进程使用的内存交换出去,从而导致这个程序慢下来。这种情况被称为颠簸。发生颠簸时,系统会花大量的时间将内存读出或写入交换分区,系统性能就会急剧下降。
具体到这个例子,交换最终停止了,最有可能的原因是交换到硬盘的内存不是第一个进程立即需要的。这就意味着交换是有效的,不是正在使用的内存内容被写入到硬盘,然后内存就会分配给需要它的进程。

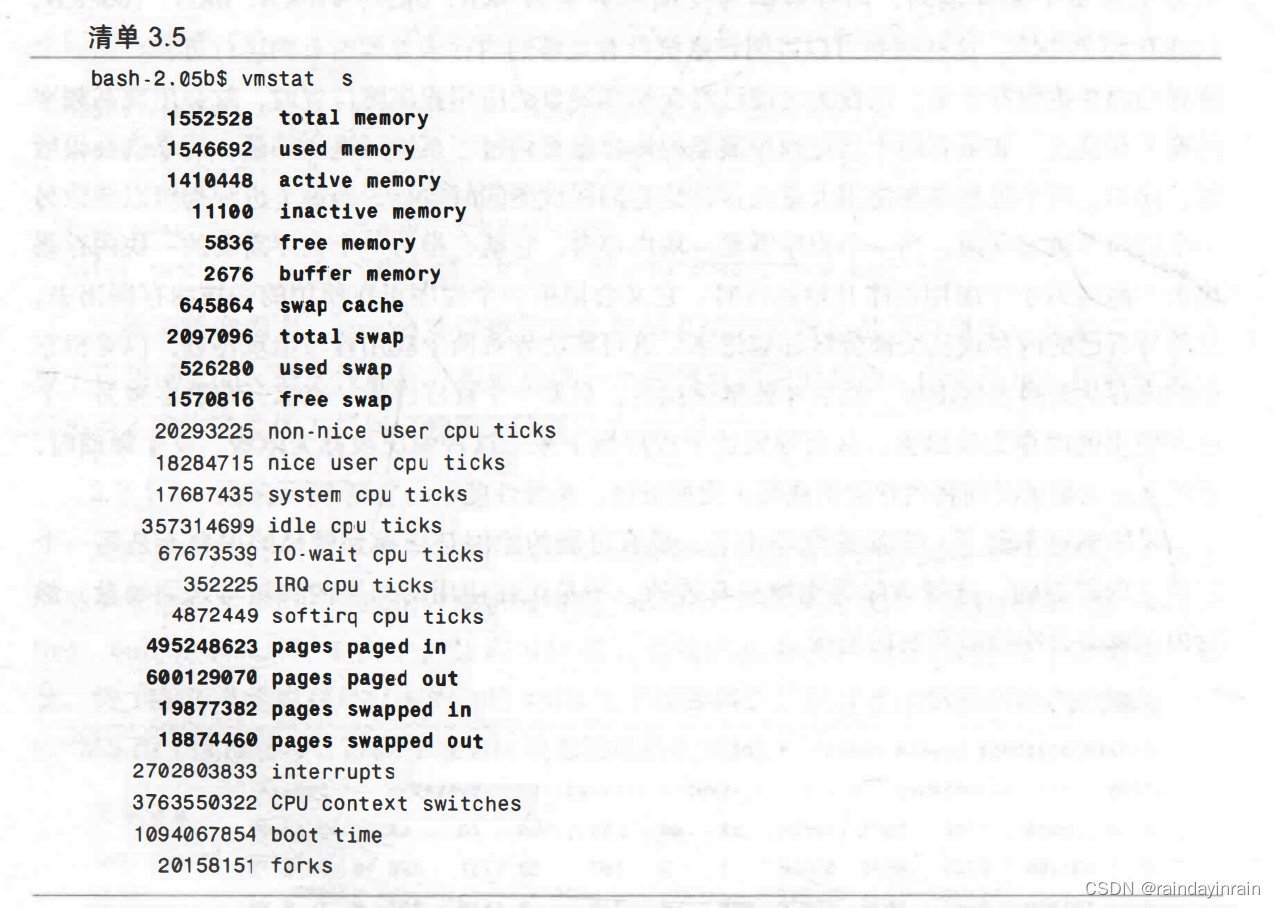
清单3.5在前面的章节已经给出了,如其所示,vmstat可以展示很多种不同的系统统计信息。现在当我们查看它时,我们可以看到一些相同的统计数据以不同的输出模式呈现,比如active、inactive、buffer、cache和used swap。但是也出现了一些新的统计信息,如total memory,该数据表示系统总共有1516MB内存;total swap,该数据表示系统总共有2048MB的交换分区。当试图确定交换分区和当前使用内存的百分比时,了解系统总量是有帮助的。另一个有趣的统计信息是pages paged in,它表示从硬盘读入的页面总数。这个统计信息包括启动应用程序读取的页面,以及该应用程序本身可以使用的页面。
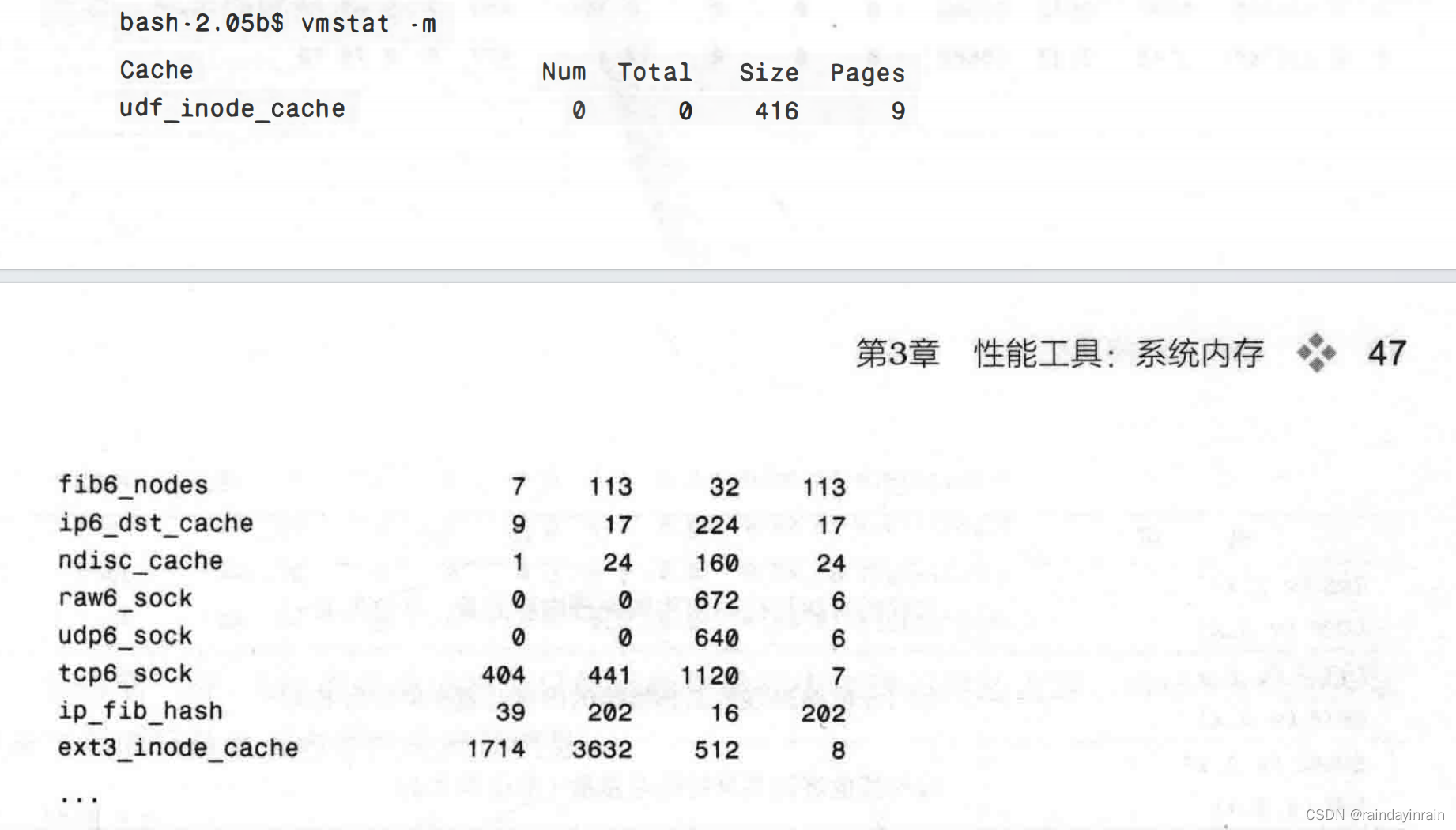
最后,在清单3.6中,我们看到vmstat可以提供关于Linux内核如何分配其内存的信息。如前所述,Linux内核有一系列“分片”来保存其动态数据结构。vmstat显示每一个分片(Cache),展示使用了多少元素(Num),分配了多少(Total),每个元素的大小(Size),整个分片使用了多少内存页(Pages)。这些信息有助于跟踪内核究竟是怎样使用其内存的。
vmstat提供了一种简便的方法来抽取大量的Linux内存子系统的信息。与默认输出界面上的其他信息结合起来,它就展示出了一个关于系统运行状况和资源使用情况的图象。
3.2.2 top(2.x和3.x)
前面章节已经讨论过,top能同时给出系统级或特定进程的性能统计信息。默认情况下,top展示的是对进程的CPU消耗量进行降序排列的列表,但它也可以调整为按内存使用总量排序,以便你能跟踪到哪个进程使用的内存最多。
3.2.2.1内存性能相关的选项
top不用任何特定命令行选项来控制其显示内存统计信息。它的调用命令行如下:top
不过,一旦开始运行,top允许你选择显示系统级内存信息,还是显示按内存使用量排序的进程。按内存消耗量排序被证明对确定哪个进程消耗了最多内存是非常有帮助的。表3-3说明了不同的与内存相关的切换项。

表3-4给出了top能提供的整个系统以及单个进程的内存性能统计数据。top有两个不同的版本2x和3.x,它们在输出统计数据的名称上有些微差异。表3-4对两个版本的名称都进行了说明。


top提供了不同运行进程的大量的内存信息。如同后续章节将会讨论的,你可以使用这些信息来确定应用程序究竟是如何分配和使用内存的。
3.2.2.2 用法示例
清单3.7与前面章节给出的top运行示例相似。不过这个例子中,请注意在缓冲区中有大约84MB是空闲的,而总的物理内存容量为1024MB。