ElasticSearch 7+ELK
- 程序安装
- Docker安装
- 下载ES镜像
- 提前创建挂载文件夹
- 添加配置文件
- 创建并启动容器
- 可能出现的异常
- 安装IK分词
- 使用ElasticHD客户端工具(目前使用发现无法做增删改)
- 安装Kibana
- 软件包安装
- 安装ElasticSearch(需要JDK1.8+)
- 安装IK(下载和elasticsearch相同版本的IK)
- 安装Kibana(下载和elasticsearch相同版本)
- 安装Filebeat(可以理解为简化版的logstash)
- 实操
- ElasticSearch
- 基础操作命令
- 1. 查看节点状态
- 2、查看索引
- 3、查看节点列表
- 操作分词器命令
- 1、ES默认分词器
- 2、IK最小切分
- 3、IK最细粒度切分 全部词库的可能
- 4、创建索引时设置默认分词器,如果不设置默认就是standard分词器
- 操作索引命令
- 1、增加索引
- 2、创建带字段规则的索引 类似表字段类型
- 3、创建带字段规则+默认分词器的索引
- 4、删除索引
- POST和PUT的区别
- 操作document命令
- 1、新增document
- 2、搜索 type 全部数据
- 3、查找指定 id 的 document 数据
- 4、修改 document
- 5、删除一个 document
- 6、按条件查询(全部)
- 7、按照字段的分词查询
- 8、按照分词子属性查询
- 9、按照短语查询
- 10、模糊查询(如果分词器中没有对应分词可以使用)
- 11、查询后过滤
- 12、查询前过滤(推荐使用)
- 13、按范围过滤
- 14、排序
- 15、分页查询
- 16、指定查询的字段
- 17、聚合
- 18、高亮
- 关于Mapping
- 1、查看mapping
- 2、手动指定Mapping
- IK
- IK分词器细粒度的拆分
- 自定义ik词汇
程序安装
Docker安装
下载ES镜像
docker pull elasticsearch:7.6.1
提前创建挂载文件夹
mkdir -p /home/docker/elasticsearch/config
mkdir -p /home/docker/elasticsearch/data
mkdir -p /home/docker/elasticsearch/plugins
# 创建好之后需要给/home/docker/elasticsearch目录赋予777权限 不然启动会失败
sudo chmod -R 777 /home/docker/elasticsearch/
添加配置文件
vi /home/docker/elasticsearch/config/elasticsearch.yml
# 添加以下配置
# 集群名称
cluster.name: "docker-cluster"
# 节点名称
node.name: node1
# http端口
http.port: 9200
# 访问权限
network.host: 0.0.0.0
http.host: 0.0.0.0
创建并启动容器
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms512m -Xmx512m" \
-v /home/docker/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /home/docker/elasticsearch/data:/usr/share/elasticsearch/data \
-v /home/docker/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
--restart always
-d elasticsearch:7.6.1
说明
- -p 端口映射
- -e discovery.type=single-node 单点模式启动
- -e ES_JAVA_OPTS=“-Xms512m -Xmx512m”:设置启动占用的内存范围
- -v 目录挂载
- –restart always docker容器启动时自动启动
- -d 后台运行
可能出现的异常
1、 因虚拟内存太少导致
处理:sudo sysctl -w vm.max_map_count=655360
安装IK分词
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.6.1
# 创建目标文件夹,ES会自动读取plugins这个目录下的插件
mkdir -p /home/docker/elasticsearch/plugins/ik
# 将下载好的ik分词器放入/home/docker/elasticsearch/plugins/ik下
# 解压
unaip elasticsearch-analysis-ik-7.6.1.zip
使用ElasticHD客户端工具(目前使用发现无法做增删改)
ElasticHD轻量使用方便,在window环境下提供了一个exe程序
下载地址:https://github.com/qax-os/ElasticHD/tags
安装Kibana
1、下载镜像
docker pull kibana:7.6.1
2、创建挂载文件和目录
mkdir -p /home/docker/elasticsearch/kibana/config/
vi /home/docker/elasticsearch/kibana/config/kibana.yml
# 添加以下配置
# Default Kibana configuration for docker target
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://172.16.2.109:9200" ]
xpack.monitoring.ui.container.elasticsearch.enabled: true
i18n.locale: "zh-CN" #汉化
3、启动
docker run -d \
--name=kibana \
--restart=always \
-p 5601:5601 \
-v /home/docker/elasticsearch/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml \
kibana:7.6.1
软件包安装
百度网盘图灵资料中有
安装ElasticSearch(需要JDK1.8+)
1、Elasticsearch下载地址
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.1-linux-x86_64.tar.gz
2、解压elasticsearch-7.6.1-linux-x86_64.tar.gz到/usr/local/目录
tar -avxf elasticsearch-7.6.1-linux-x86_64.tar.gz -C /usr/local/
3、进入解压后的elasticsearch目录
(1)新建data目录:mkdir data
(2)修改config/elasticsearch.yml:vim config/elasticsearch.yml
取消下列项注释并修改:
cluster.name: my-application #集群名称
node.name: node-1 #节点名称
#数据和日志的存储目录
path.data: /usr/local/elasticsearch-7.6.1/data
path.logs: /usr/local/elasticsearch-7.6.1/logs
#设置绑定的ip,设置为0.0.0.0以后就可以让任何计算机节点访问到了
network.host: 0.0.0.0
http.port: 9200 #数据交互端口
#设置在集群中的所有节点名称,这个节点名称就是之前所修改的,当然你也可以采用默认的也行,目前是单机,放入一个节点即可
cluster.initial_master_nodes: ["node-1"]
#开启跨域访问支持,默认为false
http.cors.enabled: true
#跨域访问允许的域名地址,(允许所有域名)以上使用正则
http.cors.allow-origin: /.*/
(3)修改 ./config/jvm.options: vim config/jvm.options
-Xms200m
-Xmx200m
4、启动ES(ES不能使用root用户启动需要创建新用户)
(1)创建用户
adduser es
passwd es
(2)改一下es目录所属用户:
chown es /usr/local/elasticsearch-7.6.1/ -R
(3)vim 编辑 vim /etc/security/limits.conf,在末尾加上
es soft nofile 65536
es hard nofile 65536
es soft nproc 4096
es hard nproc 4096
(4)vim 编辑 vim /etc/security/limits.d/20-nproc.conf,将* 改为用户名(es):
es soft nproc 4096
root soft nproc unlimited
(5)vim 编辑 vim /etc/sysctl.conf,在末尾加上:
vm.max_map_count = 655360
(6)执行: sysctl -p
(7)登录刚才新建的es用户,并启动elasticsearch
su es
./bin/elasticsearch (前台启动)
./bin/elasticsearch -d(后台启动)
(8)关闭elasticsearch
kill -9 pid 直接杀掉进程
//搜索es进程pid
ps aux | grep elasticsearch
安装IK(下载和elasticsearch相同版本的IK)
1、切换目录
cd /usr/local/elasticsearch-7.6.1/plugins/
2、创建ik文件夹
mkdir ik
3、切换到ik文件夹下进行文件上传
cd ik
4、没有unzip命令的同学输入如下命令安装unzip命令
yum install -y unzip
5、对zip进行解压
unzip elasticsearch-analysis-ik-7.6.1.zip
安装Kibana(下载和elasticsearch相同版本)
1、下载kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.6.1-linux-x86_64.tar.gz
2、解压
tar -zxvf kibana-7.6.1-linux-x86_64.tar.gz kibana-7.6.1
3、修改kibana配置文件kibana.yml
vim config/kibana.yml
# 放开注释,将默认配置改成如下:
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://127.0.0.1:9200"]
server.name: "one-server" #随意
i18n.locale: "zh-CN" #汉化
4、启动kibana
./kibana --allow-root
nohup ./kibana --allow-root & (后台启动)
5、关闭kibana
kill -9 pid 直接杀掉进程
//搜索es进程pid
netstat -tunlp|grep 5601
安装Filebeat(可以理解为简化版的logstash)
1、参考资料
https://www.cnblogs.com/zsql/p/13137833.html#_label2_0
2、filebeat和logstash的关系
因为logstash是jvm跑的,资源消耗比较大,所以后来作者又用golang写了一个功能较少但是资源消耗也小的轻量级的logstash-forwarder。不过作者只是一个人,加入http://elastic.co公司以后,因为es公司本身还收购了另一个开源项目packetbeat,而这个项目专门就是用golang的,有整个团队,所以es公司干脆把logstash-forwarder的开发工作也合并到同一个golang团队来搞,于是新的项目就叫filebeat了。
3、官网下载,选择和ES相同的二进制版本
https://www.elastic.co/cn/downloads/past-releases#filebeat
4、将下载好的压缩包放入需要收集日志的服务器中并且解压
tar -xzvf filebeat-7.6.1-linux-x86_64.tar.gz

5、编写配置
# 在filebeat-7.6.1-linux-x86_64目录内新建一个配置文件
touch filebeat_log.yml
# 编辑添加需要的配置文件夹信息
vi filebeat_log.yml
#添加以下信息
# filebeat.inputs.type :输入文件类型 log:日志类型
# enabled:是否开启
# paths:日志文件目录 可以写多个
# output.elasticsearch.hosts:ES服务地址
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/mq/log/server.log.*
output.elasticsearch:
hosts: ["192.168.21.130:9200", "192.168.21.131:9200", "192.168.21.132:9200"]
6、Kibana中查看日志
1、先查看Filebeat创建索引的名称
Management->索引管理

2、配置查看这个日志
logs->设置



实操
- 1、http://note.youdao.com/noteshare?id=83ea7925e0a1ae40e037f682b98d9874&sub=07E63083340A409683C3D8B26786C549
- 2、https://note.youdao.com/ynoteshare/index.html?id=7fffae927f3bc06aab2fdc663ec5cad3&type=note&_time=1648026973975
ElasticSearch
text类型在存储数据的时候会默认进行分词,并生成索引。而keyword存储数据的时候,不会分词建立索引,显然,这样划分数据更加节省内存。
这样,我们映射了某一个字段为keyword类型之后,就不用设置任何有关分词器的事情了,该类型就是默认不分词的文本数据类型。而对于text类型,我们还可以设置它的分词类型。
基础操作命令

1. 查看节点状态
GET /_cat/health?v
前两个是时间戳,其余含义如下:
1. cluster , 集群名称
2. status, 集群状态 green代表健康;yellow代表分配了所有主分片,但至少缺少一个副本,此时集群数据仍旧完整;red代表部分主分片不可用,可能已经丢失数据。
3. node.total, 代表在线的节点总数量
4. node.data, 代表在线的数据节点的数量
5. shards, active_shards 存活的分片数量
6. pri,active_primary_shards 存活的主分片数量 正常情况下 shards的数量是pri的两倍。
7. relo, relocating_shards 迁移中的分片数量,正常情况为 0
8. init, initializing_shards 初始化中的分片数量 正常情况为 0
9. unassign, unassigned_shards 未分配的分片 正常情况为 0
10. pending_tasks, 准备中的任务,任务指迁移分片等 正常情况为 0
11. max_task_wait_time, 任务最长等待时间
12. active_shards_percent, 正常分片百分比 正常情况为 100%
2、查看索引
GET /_cat/indices?v
含义:
1. health 索引健康状态
2. status 索引的开启状态
3. index 索引名称
4. uuid 索引uuid
5. pri 索引主分片数
6. rep 索引副本分片数量
7. docs.count 索引中文档总数
8. docs.deleted 索引中删除状态的文档
9. store.size 主分片+副本分分片的大小
10. pri.store.size 主分片的大小
3、查看节点列表
GET /_cat/nodes?v

操作分词器命令
1、ES默认分词器
POST _analyze
{
"analyzer":"standard",
"text":"中国共产党"
}
2、IK最小切分
GET _analyze
{
"analyzer": "ik_smart",
"text": "中国共产党"
}
3、IK最细粒度切分 全部词库的可能
GET _analyze
{
"analyzer": "ik_max_word",
"text": "中国共产党"
}
4、创建索引时设置默认分词器,如果不设置默认就是standard分词器
# 设置分词器
PUT /myindex
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
# 查看分词器 如果自定义设置了分词器可以在索引信息中看到设置的分词器名称,如果没有使用的就是系统默认分词器
GET myindex
操作索引命令
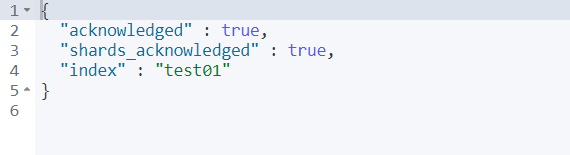
1、增加索引
PUT /test01
2、创建带字段规则的索引 类似表字段类型
PUT /test02
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "long"
},
"birthday":{
"type": "date"
},
"info":{
"type": "text",
"fields" : { # 添加一个类型 让info可以支持排序和聚合查询
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
3、创建带字段规则+默认分词器的索引
PUT /test03
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "long"
},
"birthday":{
"type": "date"
}
}
},
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
4、删除索引
DELETE /test01

POST和PUT的区别
- 1、PUT、GET、DELETE是幂等的
- 2、POST /uri 创建 PUT /uri/xxx 更新或创建
- 3、POST不用加具体的id,它是作用在一个集合资源之上的(/uri),而PUT操作是作用在一个具体资源之上的(/uri/xxx)。在ES中,如果不确定document的ID(documents具体含义见下),那么直接POST对应uri( “POST /website/blog” ),ES可以自己生成不会发生碰撞的UUID;如果确定document的ID,比如 “PUT /website/blog/123”,那么执行创建或修改(修改时_version版本号提高1)
操作document命令
1、新增document
说明: 如果之前没建过 index 或者 type,es 会自动创建。
PUT /movie_index/movie/1
{ "id":1,
"name":"operation red sea",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"zhang yi"},
{"id":2,"name":"hai qing"},
{"id":3,"name":"zhang han yu"}
]
}
PUT /movie_index/movie/2
{
"id":2,
"name":"operation meigong river",
"doubanScore":8.0,
"actorList":[
{"id":3,"name":"zhang han yu"}
]
}
PUT /movie_index/movie/3
{
"id":3,
"name":"incident red sea",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"zhang chen"}
]
}
2、搜索 type 全部数据
GET /movie_index/movie/_search
3、查找指定 id 的 document 数据
GET /movie_index/movie/1
4、修改 document
A. 整体替换
说明: 修改和新增没有区别,是做一个覆盖操作
PUT /movie_index/movie/3
{
"id":"3",
"name":"incident red sea",
"doubanScore":"8.0",
"actorList":[
{"id":"1","name":"zhang chen"}
]
}
B. 只修改某个字段
POST /movie_index/movie/3/_update
{
"doc": {
"doubanScore":"8.1"
}
}
5、删除一个 document
DELETE /movie_index/movie/3
6、按条件查询(全部)
GET /movie_index/movie/_search
{
"query": {
"match_all": {}
}
}
7、按照字段的分词查询
GET /movie_index/movie/_search
{
"query": {
"match": {
"name": "sea"
}
}
}
8、按照分词子属性查询
GET /movie_index/movie/_search
{
"query": {
"match": {
"actorList.name": "zhang"
}
}
}
9、按照短语查询
说明: 按照短语查询是指匹配某个 field 的整个内容, 不再利用分词技术
GET /movie_index/movie/_search
{
"query": {
"match_phrase": {
"name": "operation red"
}
}
}
10、模糊查询(如果分词器中没有对应分词可以使用)
说明: 校正匹配分词,当一个单词都无法准确匹配,es 通过一种算法对非常接近的单词也给与一定的评分,能够查询出来,但是消耗更多的性能。
GET /movie_index/movie/_search
{
"query": {
"fuzzy": {
"name": "red"
}
}
}
11、查询后过滤
GET /movie_index/movie/_search
{
"query": {
"match": {
"name": "red"
}
},
"post_filter": {
"term": {
"actorList.id": "3"
}
}
}
12、查询前过滤(推荐使用)
GET movie_index/movie/_search
{
"query": {
"bool": {
"filter": [
{"term":
{"actorList.id": 3}
},
{
"term":
{"actorList.id": 1}
}
],
"must":
{"match": {
"name": "red"
}}
}
}
}
13、按范围过滤
GET movie_index/movie/_search
{
"query": {
"bool": {
"filter": {
"range": {
"doubanScore": {
"gt": 5,
"lt": 9
}
}
}
}
}
}
14、排序
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red operation"}
}
,
"sort": [
{
"doubanScore": {
"order": "desc"
}
}
]
}
15、分页查询
# from 从第一条数据开始 size:查询几条
GET movie_index/movie/_search
{
"query": { "match_all": {} },
"from": 1,
"size": 1
}
16、指定查询的字段
GET movie_index/movie/_search
{
"query": { "match_all": {} },
"_source": ["name", "doubanScore"]
}
17、聚合
# 每个演员参演了多少部电影 (按名字进行计数)
GET movie_index/movie/_search
{
"aggs": {
"groupby_actor": {
"terms": {
"field": "actorList.name.keyword"
}
}
}
}
18、高亮
GET /movie_index/movie/_search
{
"query": {
"match": {
"name": "sea"
}
},
"highlight":{
"fields":{
"name":{}
}
}
}
#自定义高亮标签
GET /movie_index/movie/_search
{
"query": {
"match": {
"name": "sea"
}
},
"highlight":{
"pre_tags": "<p style='color:red'>",
"post_tags": "</p>",
"fields":{
"name":{}
}
}
}
关于Mapping
通过 Mapping 来设置和查看每个字段的数据类型.
1、查看mapping
GET movie_index/_mapping
2、手动指定Mapping
A:搭建索引
# type:字段类型
# index:是否建立倒排索引 默认值:true建立
# store:是否存储数据 默认值: true存储 如果不存储这个字段有索引能通过这个字段查询,但是获取不到这个值的内容
PUT /movie_chn?include_type_name=true
{
"mappings": {
"movie":{
"properties": {
"id":{
"type": "long",
"index": false,
"store": true
},
"name":{
"type": "text"
, "analyzer": "ik_smart"
},
"doubanScore":{
"type": "double"
},
"actorList":{
"properties": {
"id":{
"type":"long"
},
"name":{
"type":"keyword"
}
}
}
}
}
}
}
B:插入数据
PUT /movie_chn/movie/1
{ "id":1,
"name":"红海行动",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"张译"},
{"id":2,"name":"海清"},
{"id":3,"name":"张涵予"}
]
}
PUT /movie_chn/movie/2
{
"id":2,
"name":"湄公河行动",
"doubanScore":8.0,
"actorList":[
{"id":3,"name":"张涵予"}
]
}
PUT /movie_chn/movie/3
{
"id":3,
"name":"红海事件",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"张晨"}
]
}
C:查询
GET /movie_chn/movie/_search
{
"query": {
"match": {
"name": "红海"
}
}
}
GET /movie_chn/movie/_search
{
"query": {
"term": {
"actorList.name": "张"
}
}
}
IK
IK分词器细粒度的拆分
1、ik_smart:会将文本做最粗粒度的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、国歌」
2、ik_max_word:会将文本做最细粒度的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、中华人民、中华、华人、人民共和国、人民、人、民、共和国、共和、和、国国、国歌」,会穷尽各种可能的组合
GET _analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国国歌"
}
GET _analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国国歌"
}
自定义ik词汇
1、进入elasticsearch/plugins/ik/config目录
2、新建一个myDict.dic文件,编辑内容(以utf8无bom保存, 如果不行加一些换行或者空出第一行)
3、修改IKAnalyzer.cfg.xml(在ik/config目录下)

4、重启es