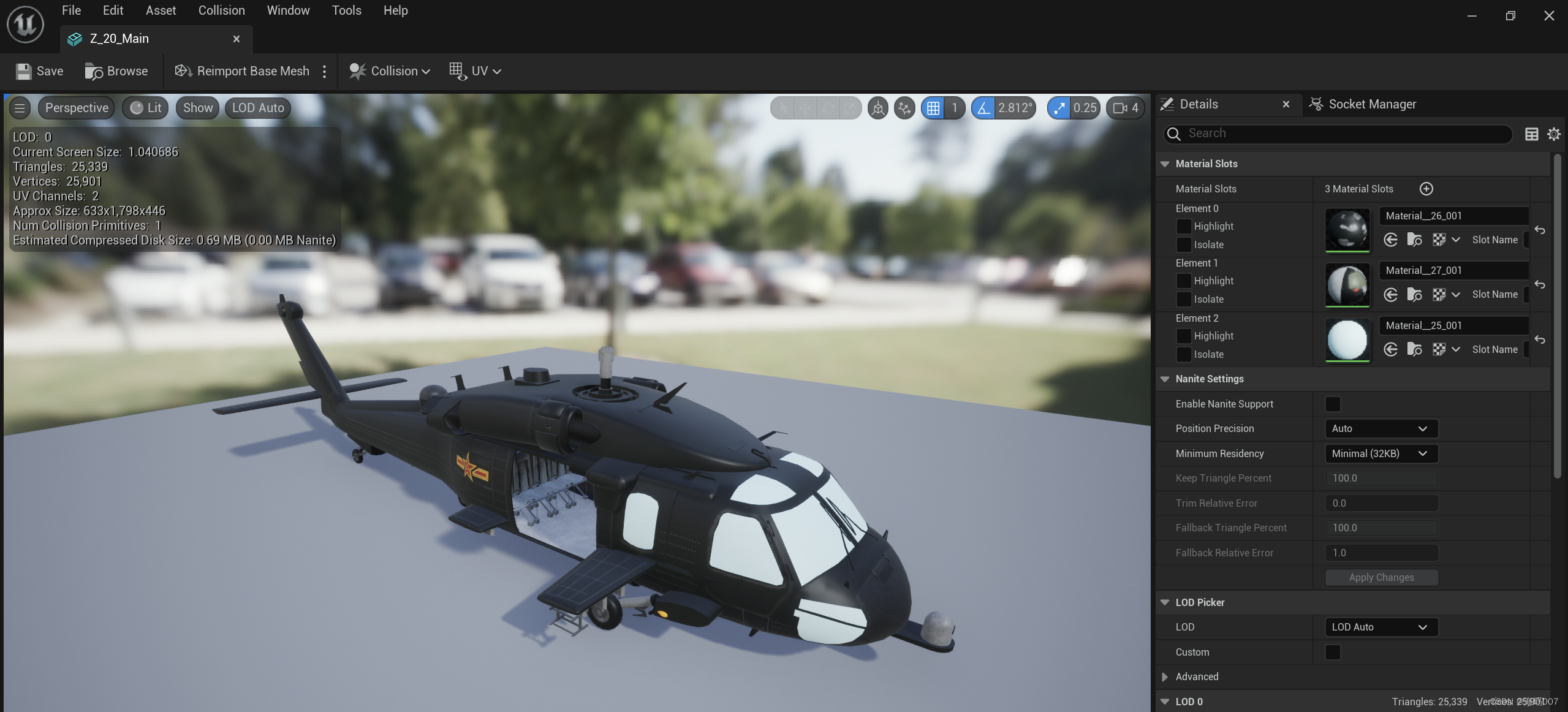
ConvNextV2
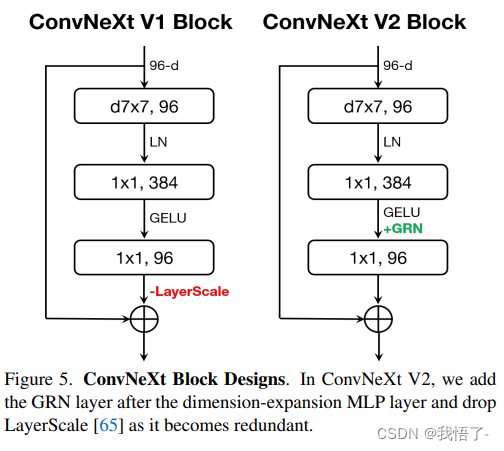
受掩码自编码机制的启发,本文在 ConvNeXt 的架构基础上延伸出了一个完全卷积掩码自编码器框架——ConvNeXt V2,同时作者设计了一个全新的全局响应归一化(Global Response Normalization, GRN)层以增强原始 ConvNeXt 模块通道间的特征竞争,从而捕获更具有判别力的通道特征。
ConvNeXt V2 最终在各种识别基准上的性能,包括 ImageNet 分类、COCO 检测和 ADE20K 分割任务上均取得了极具竞争力的结果,其中最小的模型仅 3.7M 参数可获取 76.7% top-1 准确率,而最大的模型约 650M 参数则能达到 88.9% 准确率。
原文地址:ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders

代码实现
ConvNextV2定义
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from timm.models.layers import trunc_normal_, DropPath
__all__ = ['convnextv2_atto', 'convnextv2_femto', 'convnextv2_pico', 'convnextv2_nano', 'convnextv2_tiny', 'convnextv2_base', 'convnextv2_large', 'convnextv2_huge']
class LayerNorm(nn.Module):
""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
with shape (batch_size, channels, height, width).
"""
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class GRN(nn.Module):
""" GRN (Global Response Normalization) layer
"""
def __init__(self, dim):
super().__init__()
self.gamma = nn.Parameter(torch.zeros(1, 1, 1, dim))
self.beta = nn.Parameter(torch.zeros(1, 1, 1, dim))
def forward(self, x):
Gx = torch.norm(x, p=2, dim=(1,2), keepdim=True)
Nx = Gx / (Gx.mean(dim=-1, keepdim=True) + 1e-6)
return self.gamma * (x * Nx) + self.beta + x
class Block(nn.Module):
""" ConvNeXtV2 Block.
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
"""
def __init__(self, dim, drop_path=0.):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.grn = GRN(4 * dim)
self.pwconv2 = nn.Linear(4 * dim, dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.grn(x)
x = self.pwconv2(x)
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
class ConvNeXtV2(nn.Module):
""" ConvNeXt V2
Args:
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]
dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768]
drop_path_rate (float): Stochastic depth rate. Default: 0.
head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1.
"""
def __init__(self, in_chans=3, num_classes=1000,
depths=[3, 3, 9, 3], dims=[96, 192, 384, 768],
drop_path_rate=0., head_init_scale=1.
):
super().__init__()
self.depths = depths
self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocks
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
for i in range(4):
stage = nn.Sequential(
*[Block(dim=dims[i], drop_path=dp_rates[cur + j]) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layer
self.head = nn.Linear(dims[-1], num_classes)
self.apply(self._init_weights)
self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def forward(self, x):
res = []
for i in range(4):
x = self.downsample_layers[i](x)
x = self.stages[i](x)
res.append(x)
return res
def update_weight(model_dict, weight_dict):
idx, temp_dict = 0, {}
for k, v in weight_dict.items():
if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):
temp_dict[k] = v
idx += 1
model_dict.update(temp_dict)
print(f'loading weights... {idx}/{len(model_dict)} items')
return model_dict
def convnextv2_atto(weights='', **kwargs):
model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[40, 80, 160, 320], **kwargs)
if weights:
model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))
return model
def convnextv2_femto(weights='', **kwargs):
model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[48, 96, 192, 384], **kwargs)
if weights:
model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))
return model
def convnextv2_pico(weights='', **kwargs):
model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[64, 128, 256, 512], **kwargs)
if weights:
model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))
return model
def convnextv2_nano(weights='', **kwargs):
model = ConvNeXtV2(depths=[2, 2, 8, 2], dims=[80, 160, 320, 640], **kwargs)
if weights:
model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))
return model
def convnextv2_tiny(weights='', **kwargs):
model = ConvNeXtV2(depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], **kwargs)
if weights:
model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))
return model
def convnextv2_base(weights='', **kwargs):
model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[128, 256, 512, 1024], **kwargs)
if weights:
model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))
return model
def convnextv2_large(weights='', **kwargs):
model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[192, 384, 768, 1536], **kwargs)
if weights:
model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))
return model
def convnextv2_huge(weights='', **kwargs):
model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[352, 704, 1408, 2816], **kwargs)
if weights:
model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))
return model
Backbone替换
yolo.py参数修改:(1)def parse_model部分 (2)def _forward_once部分
def parse_model(d, ch): # model_dict, input_channels(3)
# Parse a YOLOv5 model.yaml dictionary
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')
if act:
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
LOGGER.info(f"{colorstr('activation:')} {act}") # print
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
is_backbone = False
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
try:
t = m
m = eval(m) if isinstance(m, str) else m # eval strings
except:
pass
for j, a in enumerate(args):
with contextlib.suppress(NameError):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
args[j] = a
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in {
Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
# TODO: channel, gw, gd
elif m in {Detect, Segment}:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
if m is Segment:
args[3] = make_divisible(args[3] * gw, 8)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
elif isinstance(m, str):
t = m
m = timm.create_model(m, pretrained=args[0], features_only=True)
c2 = m.feature_info.channels()
elif m in {convnextv2_tiny}: #可添加更多Backbone
m = m(*args)
c2 = m.channel
else:
c2 = ch[f]
if isinstance(c2, list):
is_backbone = True
m_ = m
m_.backbone = True
else:
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type, m_.np = i + 4 if is_backbone else i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
save.extend(x % (i + 4 if is_backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
if isinstance(c2, list):
ch.extend(c2)
for _ in range(5 - len(ch)):
ch.insert(0, 0)
else:
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
def _forward_once(self, x, profile=False, visualize=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if hasattr(m, 'backbone'):
x = m(x)
for _ in range(5 - len(x)):
x.insert(0, None)
for i_idx, i in enumerate(x):
if i_idx in self.save:
y.append(i)
else:
y.append(None)
x = x[-1]
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x
def _forward_once(self, x, profile=False, visualize=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if hasattr(m, 'backbone'):
x = m(x)
for _ in range(5 - len(x)):
x.insert(0, None)
for i_idx, i in enumerate(x):
if i_idx in self.save:
y.append(i)
else:
y.append(None)
x = x[-1]
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x
.yaml配置文件修改
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, convnextv2_tiny, [False]], # 4
[-1, 1, SPPF, [1024, 5]], # 5
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 6
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 7
[[-1, 3], 1, Concat, [1]], # cat backbone P4 8
[-1, 3, C3, [512, False]], # 9
[-1, 1, Conv, [256, 1, 1]], # 10
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 11
[[-1, 2], 1, Concat, [1]], # cat backbone P3 12
[-1, 3, C3, [256, False]], # 13 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]], # 14
[[-1, 10], 1, Concat, [1]], # cat head P4 15
[-1, 3, C3, [512, False]], # 16 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]], # 17
[[-1, 5], 1, Concat, [1]], # cat head P5 18
[-1, 3, C3, [1024, False]], # 19 (P5/32-large)
[[13, 16, 19], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]