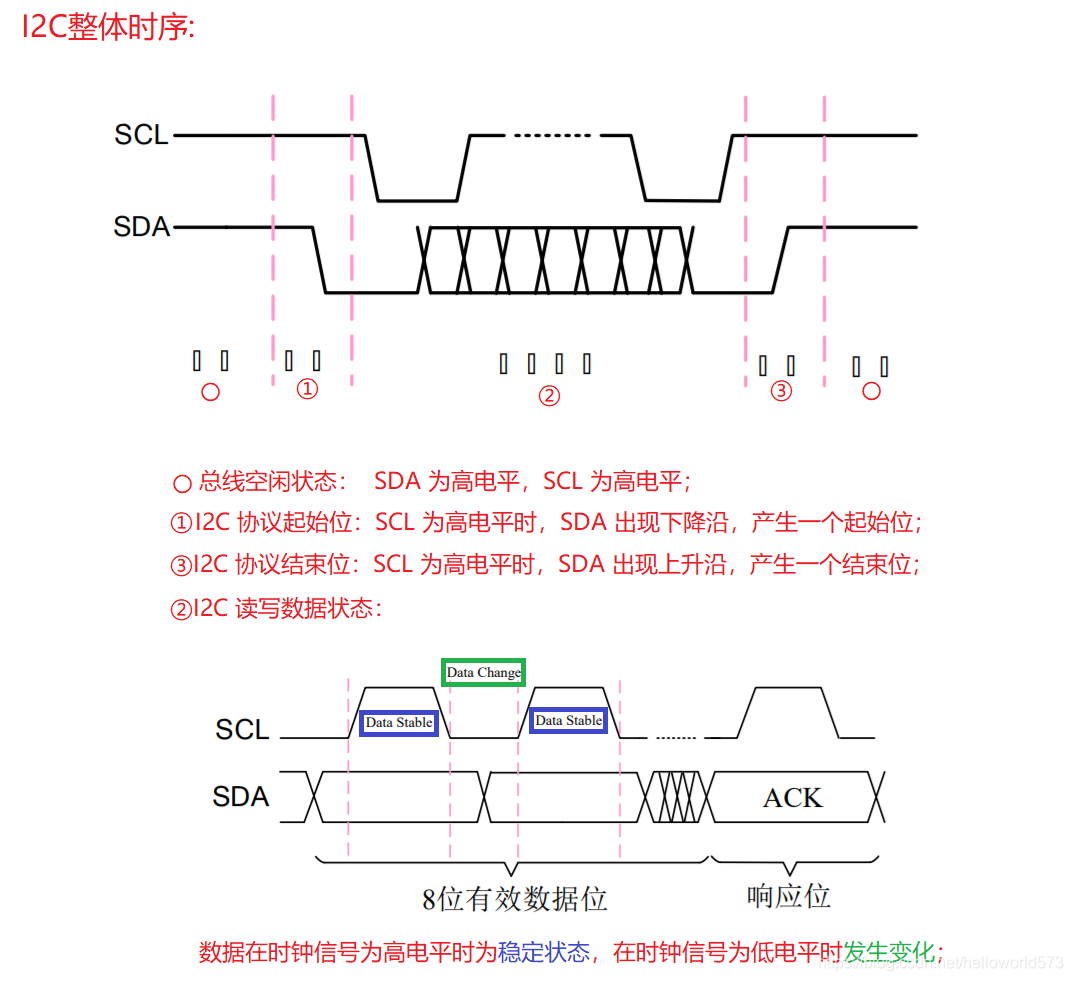
目录
写在开头
汇编语言和本地代码的关系
汇编语言的源代码
伪指令
汇编的基本语法
常见的汇编指令
mov
push和pop
函数的使用机制
函数的调用
函数参数的传递与返回值
全局变量
局部变量
程序的流程控制
循环语句
条件分支
通过汇编语言了解程序运行方式的必要性
结尾
写在开头
本文继续阅读总结《程序是怎样跑起来的》这本书(作者:矢泽久雄),也是关于这本书的最后一篇读书笔记。前三篇博客介绍了这本书的阅读感受,并分别对第一章CPU、第四章内存相关、第五章磁盘、第八章程序的知识进行了总结。详情见:
【计算机组成原理】读书笔记第一期:对程序员来说CPU是什么-CSDN博客
【计算机组成原理】读书笔记第二期:使用有棱有角的内存_Bossfrank的博客-CSDN博客
【计算机组成原理】读书笔记第三期:内存和磁盘的关系-CSDN博客
【计算机组成原理】读书笔记第四期:从源文件到可执行文件_Bossfrank的博客-CSDN博客

本篇博客将介绍本书的第十章:通过汇编语言了解程序的实际构成,将从汇编语言和本地代码的关系、汇编语言的源代码(伪指令、栈的机制、函数的调用机制、局部变量/全局变量、程序的流程控制等)两个角度进行介绍。本章是非常重点硬核的内容,了解汇编语言,是了解程序运行过程中各寄存器的存储情况、程序的执行顺序、函数的调用栈等知识的基础。了解底层的汇编语言,也对我们学习编写、调试高级程序语言大有裨益。
汇编语言和本地代码的关系
一言以蔽之,汇编语言和本地代码是一一对应的。本节内容较少,重点读者能回答以下几个问题就算知道重点了。
汇编语言存在的意义是什么?
用来直观的展现本地代码。CPU只能执行本地代码,通过调查本地代码的内容,可以了解程序最终是以何种形式来运行的。但是,如果直接打开本地代码来看的话,只能看到二进制数值的罗列。因而通过在各本地代码中,附带上表示其功能的英语单词缩写(助记符),就可以表示本地代码了,这样就有助于程序员了解程序的本质了。
汇编语言能直接运行吗?
不能!即使是用汇编语言编写的源代码,最终也必须要转换成本地代码才能运行。负责转换工作的程序称为汇编器,转换这一处理本身称为汇编。 不过用汇编语言编写的.asm源代码,和本地代码是一一对应的。因而,本地代码也可以反过来转换成汇编语言的源代码。持有该功能的逆变换程序称为反汇编程序,逆变换这一处理本身称为反汇编。

C语言等高级程序语言与本地代码是啥关系?与汇编语言又是啥关系?
C语言等高级语言最后必须转换为本地代码才能被CPU执行,但要注意,像C语言这样的高级程序设计语言与本地代码不是一一对应的,因此和汇编语言也不是一一对应的,因此反编译会比较困难(从汇编语言转换回C语言)。不过大部分C语言编译器,都可以把利用C语言编写的源代码转换成汇编语言的源代码。
汇编语言的源代码
本节内容比较多,通过代码举例说明。假设有如下C语言编写的的sample.c源代码 :
//代码10-1 C语言实例源代码sample.c
// 返回两个参数值之和的函数
int AddNum(int a, int b)
{
return a + b;
}
// 调用AddNum 函数的函数
void MyFunc()
{
int c;
c = AddNum(123, 456);
}这个C语言片段言简意赅,接下来的小节将通过对这段C语言代码的汇编代码进行说明。注意由于没有main函数,这段代码是没办法运行的,仅仅是学习汇编需要。通过使用编译器的汇编功能,生成对应汇编代码sample.asm如下:
;代码10-2,源代码sample.c转换的汇编代码sample.asm
_TEXT segment dword public use32 'CODE'
_TEXT ends
_DATA segment dword public use32 'DATA'
_DATA ends
_BSS segment dword public use32 'BSS'
_BSS ends
DGROUP group _BSS,_DATA
_TEXT segment dword public use32 'CODE'
_AddNum proc near
;
; int AddNum(int a, int b)
;
push ebp
mov ebp,esp
;
; {
; return a + b;
;
mov eax,dword ptr [ebp+8]
add eax,dword ptr [ebp+12]
;
; }
;
pop ebp
ret
_AddNum endp
_MyFunc proc near
;
; void MyFunc()
;
push ebp
mov ebp,esp
;
; {
; int c;
; c = AddNum(123, 456);
;
push 456
push 123
call _AddNum
add esp,8
;
; }
;
pop ebp
ret
_MyFunc endp
_TEXT ends
end
可以发现,C 语言的源代码和转换成汇编语言的源代码是交叉显示的。而这也为我们对两者进行比较学习提供了绝好的教材。在该汇编语言代码中,分号(;)以后是注释。由于C语言的源代码变成了注释,因此就可以直接对Sample.asm 进行汇编并将其转换成本地代码了 。刚刚看到汇编语言的源代码可能感觉一头雾水,莫慌,下面我们将逐一进行讲解。
伪指令
汇编语言的源代码,是由转换成本地代码的指令(后面讲述的操作码)和针对汇编器的伪指令构成的。伪指令负责把程序的构造及汇编的方法指示给汇编器(转换程序)。不过伪指令本身是无法汇编转换成本地代码的。也就是说,伪指令没有对应的本地代码。把代码10-2 中用到的伪指令部分摘出,如代码10-3 所示。
_TEXT segment dword public use32 'CODE'
_TEXT ends
_DATA segment dword public use32 'DATA'
_DATA ends
_BSS segment dword public use32 'BSS'
_BSS ends
DGROUP group _BSS,_DATA
_TEXT segment dword public use32 'CODE'
_AddNum proc near
_AddNum endp
_MyFunc proc near
_MyFunc endp
_TEXT ends
end
由伪指令segment 和ends围起来的部分,是给构成程序的命令和数据的集合体加上一个名字而得到的,称为段定义。在程序中,段定义指的是命令和数据等程序的集合体的意思。一个程序由多个段定义构成。
源代码的开始位置,定义了3 个名称分别为_TEXT、_DATA、_BSS的段定义。_TEXT 是指令的段定义,_DATA 是被初始化(有初始值)的数据的段定义,_BSS 是尚未初始化的数据的段定义。类似于这种段定义的名称及划分方法是由Borland C++的编译器自动分配的。因而程序段定义的配置顺序就成了_TEXT、_DATA、_BSS,这样也确保了内存的连续性。group 这一伪指令,表示的是把_BSS 和_DATA 这两个段定义汇总为名为DGROUP 的组。此外,栈和堆的内存空间会在程序运行时生成。
围起_AddNum 和_MyFun 的_TEXT segment 和_TEXT ends, 表示_AddNum 和_MyFunc 是属于_TEXT 这一段定义的。因此,即使在源代码中指令和数据是混杂编写的,经过编译或者汇编后,也会转换成段定义划分整齐的本地代码。
_AddNum proc 和_AddNum endp 围起来的部分, 以及_MyFuncproc 和MyFunc endp 围起来的部分, 分别表示AddNum 函数和MyFunc 函数的范围。编译后在函数名前附带上下划线(_), 是编译器Borland C++ 的规定。在C 语言中编写的AddNum 函数,在内部是以_AddNum 这个名称被处理的。伪指令proc 和endp 围起来的部分,表示的是过程(procedure)的范围。在汇编语言中,这种相当于C语言的函数的形式称为过程。
末尾的end 伪指令,表示的是源代码的结束。
汇编的基本语法
简单的讲,汇编语言的语法就是操作码 + 操作数 。在汇编语言中,类似于mov 这样的指令称为“操作码”(opcode),能够使用何种形式的操作码,是由CPU的种类决定的,表10-1给出了前面的示例代码10-2中用到的操作数,这些都是32 位x86系列CPU用的操作码;作为指令对象的内存地址及寄存器等称为“操作数”(operand),操作数中指定了寄存器名、内存地址、常数等。当汇编语句中存在多个操作数的时候,要用逗号','进行分隔。
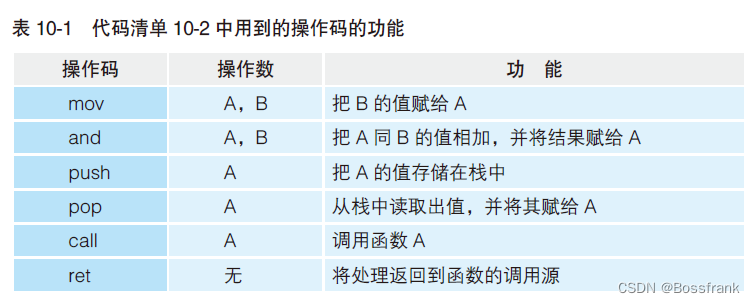
注:本地代码加载到内存后才能运行。内存中存储着构成本地代码的指令和数据。程序运行时,CPU会从内存中把指令和数据读出,然后再将其存储在CPU内部的寄存器中进行处理(图10-2)
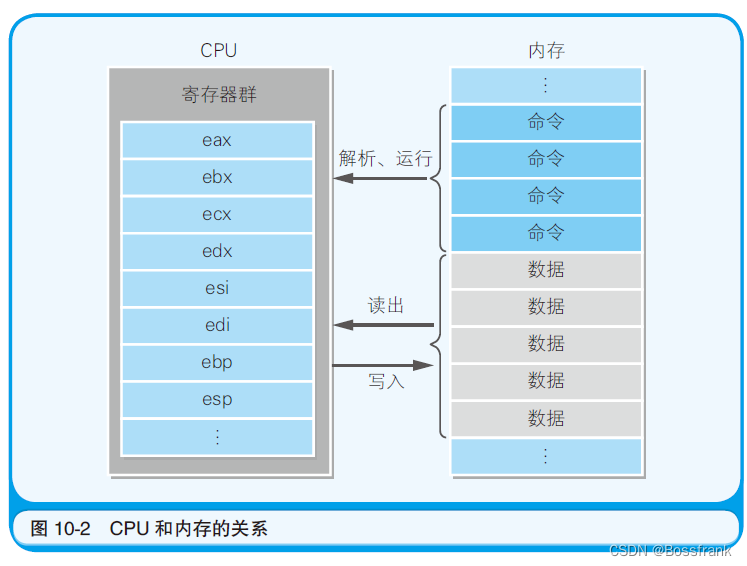
寄存器是CPU中的存储区域。不过,寄存器并不仅仅具有存储指令和数据的功能,也有运算功能。x86 系列CPU的寄存器的主要种类和角色如表10-2 所示(表中寄存器名都是以字母e开头,e是extended扩展的意思,32位寄存器正是由16位寄存器扩展得到)。寄存器的名称会通过汇编语言的源代码指定给操作数。内存中的存储区域是用地址编号来区分的。CPU内的寄存器是用eax及ebx这些名称来区分的。此外,CPU内部也有程序员无法直接操作的寄存器。例如,表示运算结果正负及溢出状态的标志寄存器及操作系统专用的寄存器等,都无法通过程序员编写的程序直接进行操作。

常见的汇编指令
汇编语言中,汇编语言的语法就是操作码 + 操作数 ,常见的操作码有对寄存器和内存进行数据存储的 mov 指令。对栈进行压栈和弹栈的push和pop指令、用于累加的add指令、函数调用相关的call和ret等等。本文将依据代码10-2中涉及到的操作码指令,进行逐一讲解。
mov
mov指令非常常见,用于对寄存器和内存进行数据存储。mov 指令的两个操作数,分别用来指定数据的存储地和读出源。操作数中可以指定寄存器、常数、标签(附加在地址前),以及用方括号([])围起来的这些内容。如果指定了没有用方括号围起来的内容,就表示对该值进行处理;如果指定了用方括号围起来的内容,方括号中的值则会被解释为内存地址,然后就会对该内存地址对应的值进行读写操作。下面举例说明。
代码:
mov ebp,esp
mov eax,dword ptr [ebp+8]解释:mov ebp,esp 中,esp寄存器中的值被直接存储在了ebp寄存器中。esp寄存器的值是100时ebp寄存器的值也是100。而在mov eax,dwordptr [ebp+8] 的情况下, ebp 寄存器的值加8后得到的值会被解释为内存地址。如果ebp 寄存器的值是100的话,那么eax 寄存器中存储的就是100 + 8 = 108地址的数据。dword ptr(double word pointer)表示的是从指定内存地址读出4字节的数据。像这样,有时也会在汇编语言的操作数前附带dword ptr 这样的修饰语。
push和pop
程序运行时,会在内存上申请分配一个称为栈(stack)的数据空间。数据在栈中存储时是从内存的下层(大的地址编号)逐渐往上层(小的地址编号)累积,读出时则是按照从上往下的顺利进行(图10-3)的。
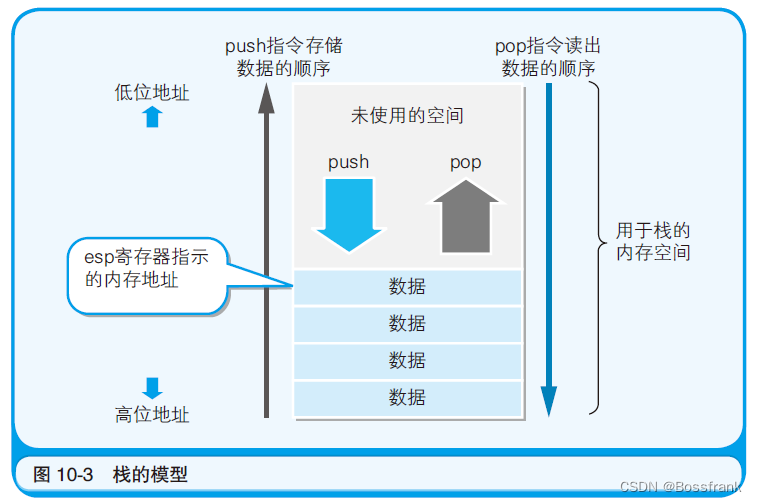
栈是存储临时数据的区域,它的特点是通过push 指令和pop 指令进行数据的存储和读出。往栈中存储数据称为“入栈”,从栈中读出数据称为“出栈”。32 位x86 系列的CPU中,进行1次push或pop,即可处理32位(4 字节)的数据。push指令和pop指令中只有一个操作数。该操作数表示的是“push(压栈哪个数据)的是什么及pop(弹栈后的结果存储到哪里)的是什么”,而不需要指定“对哪一个地址编号的内存进行push或pop” 。这是因为,对栈进行读写的内存地址是由esp寄存器(栈指针)进行管理的。push指令和pop指令运行后, esp 寄存器的值会自动进行更新(push指令是-4,pop命令是+4),因而程序员就没有必要指定内存地址了。
函数的使用机制
函数的调用
本节从MyFunc函数调用AddNum函数的汇编语言部分开始,来对函数的调用机制进行说明。MyFunc函数的处理内容如下:
;代码10-4函数调用相关的汇编代码
_MyFunc proc near
push ebp ; 将ebp 寄存器的值存入栈中 (1)
mov ebp,esp ; 将ebp 寄存器的值存入ebp 寄存器 (2)
push 456 ; 456 入栈 (3)
push 123 ; 123 入栈 (4)
call _AddNum ; 调用AddNum 函数 (5)
add ebp,8 ; esp 寄存器的值加8 (6)
pop ebp ; 读出栈中的数值存入ebp寄存器 (7)
ret ; 结束MyFunc 函数,返回到调用源 (8)
_MyFunc endp
(1)、(2)、(7)、(8)的处理适用于C 语言中所有的函数,会在后面展示AddNum 函数处理内容时进行说明。 在函数的入口处把寄存器ebp 的值入栈保存(1),在函数的出口处出栈(代码清单10-4(7),这是C语言编译器的规定。这样做是为了确保函数调用前后ebp 寄存器的值不发生变化。
(3)~(6)部分是函数调用机制的核心。(3)和(4)表示的是将传递给AddNum 函数的参数通过push入栈。在C语言的源代码中,虽然记述为函数AddNum(123,456),但入栈时则会按照456、123 这样的顺序,也就是位于后面的数值先入栈。这是C语言的规定。(5)的call 指令,把程序流程跳转到了操作数中指定的AddNum函数所在的内存地址处。在汇编语言中,函数名表示的是函数所在的内存地址。AddNum 函数处理完毕后,程序流程必须要返回到编号(6)这一行。call 指令运行后,call 指令的下一行(6)的内存地址(调用函数完毕后要返回的内存地址)会自动地push入栈。该值会在AddNum函数处理的最后通过ret指令pop出栈,然后程序流程就会返回到(6)这一行。
(6)部分会把栈中存储的两个参数(456 和123)进行销毁处理,也就是在上篇博客第5章提到的栈清理处理。虽然通过使用两次pop指令也可以实现,不过采用esp寄存器加8的方式会更有效率(处理1次即可)。对栈进行数值的输入输出时,数值的单位是4字节(32位)。因此,通过在负责栈地址管理的esp寄存器中加上4的2倍,也就是8,就可以达到和运行两次pop命令同样的效果。虽然内存中的数据实际上还残留着,但只要把esp寄存器的值更新为数据存储地址前面的数据位置,该数据也就相当于被销毁了(这是因为esp寄存器的值表示栈顶元素,即栈中最高位数据的内存地址,esp + 8就相当于把栈顶的位置向栈底方向移动了2个数据单位)。
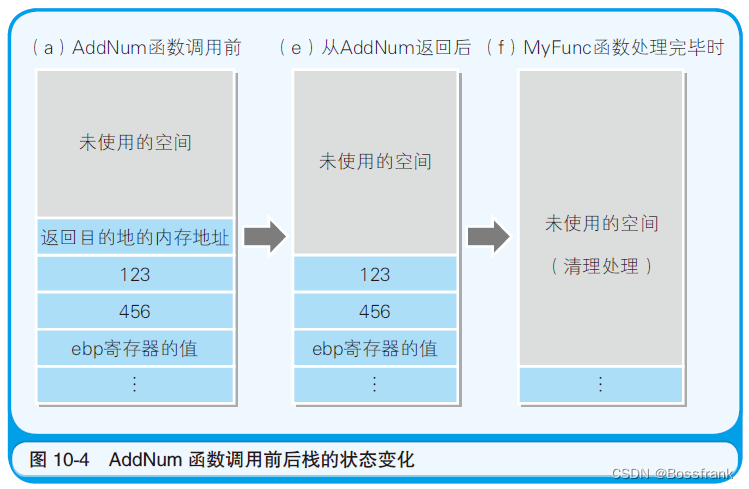
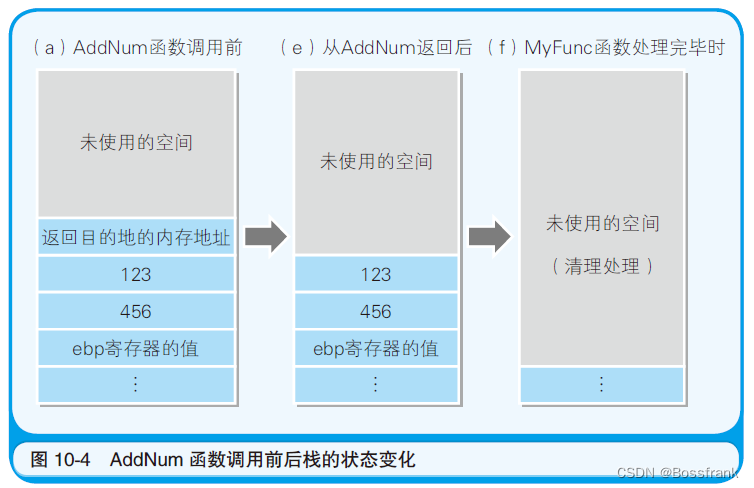
push指令和pop指令必须以4字节为单位对数据进行入栈和出栈处理。因此,AddNum函数调用前和调用后栈的状态变化就如图10-4所示。长度小与4字节的123和456这些值在存储时,也会占用4字节的栈区域。
顺道一提,在代码10-1中,有c = AddNum(123, 456);这样的语句,表示把AddNum函数的返回值赋值给了变量c,但在汇编语言中,却找不到c相关的汇编代码,这是因为编译器有最优化功能,目的是让编译后的程序运行速度更快、文件更小。由于存储着AddNum 函数返回值的变量c在后面没有被用到,因此编译器就会认为“该处理没有意义”,进而也就没有生成与之对应的汇编语言代码。
函数参数的传递与返回值
下面通过AddNum函数的源代码部分,来介绍参数的接收、返回值的返回等机制(代码10-5)。
;代码10-5 函数内部的处理
_AddNum proc near
push ebp (1)
mov ebp,esp (2)
mov eax,dword ptr [ebp+8] (3)
add eax,dword ptr [ebp+12] (4)
pop ebp (5)
ret (6)
_AddNum endp
ebp 寄存器的值在(1)中入栈,在(5)中出栈。这主要是为了把函数中用到的ebp寄存器的内容,恢复到函数调用前的状态。在进入函数处理之前,无法确定ebp寄存器用到了什么地方,但由于函数内部也会用到ebp寄存器,所以就暂时将该值保存了起来。
(2)中把负责管理栈地址的esp寄存器的值赋值到了ebp 寄存器中。这是因为,在mov 指令中方括号内的参数,是不允许指定esp寄存器的。因此,这里就采用了不直接通过esp,而是用ebp寄存器来读写栈内容的方法。
(3)是用[ebp+8] 指定栈中存储的第1个参数123,并将其读出到eax 寄存器中(eax是负责运算的累加寄存器)。这也可以看出,读取栈中的内容并非只能通过pop(pop只能读取栈顶的内容,而且会弹栈,此时[ebp+4]表示的就是栈顶的内存地址,也就是之前压入的进入函数之前的ebp的值)。
通过(4)的add 指令,把当前eax 寄存器的值同第2个参数相加后的结果存储在eax寄存器中。[ebp+12] 是用来指定第2个参数456的。在C语言中,函数的返回值必须通过eax寄存器返回,这也是规定。不过,和ebp寄存器不同的是,eax寄存器的值不用还原到原始状态(因为eax寄存器并不相当于指针,后续再用到的时候里面先前存储的值就被覆盖掉了,无需特别清除)。(6)中ret 指令运行后,函数返回目的地的内存地址会自动出栈,据此,程序流程就会跳转返回到代码清单10-4的(6)。本节的核心就是函数的参数是通过栈来传递,返回值是通过寄存器来返回的。
AddNum 函数入口和出口处栈的状态变化,就如图10-5 所示。将图10-4 和图10-5 按照(a)(b)(c)(d)(e)(f)的顺序来看的话,函数调用处理时栈的状态变化就会很清楚了。由于(a)状态时处理跳转到AddNum 函数,因此(a)和(b)是同样的。同理,在(d)状态时,处理跳转到了调用源,因此(d)和(e)是同样的。在(f)状态时则进行了清理处理。栈的最高位的数据地址,是一直存储在esp寄存器中的。

重放一下图10-4如下:
全局变量
众所周知,C语言中,在函数外部定义的变量称为全局变量,在函数内部定义的变量称为局部变量。全局变量可以参阅源代码的任意部分,而局部变量只能在定义该变量的函数内进行参阅。下面通过汇编语言的源代码,对比全局变量和局部变量的不同。代码10-6是一段使用了局部变量和全局变量的C语言代码:
//代码10-6 使用了全局变量和局部变量的C语言代码
// 定义被初始化的全局变量
int a1 = 1;
int a2 = 2;
int a3 = 3;
int a4 = 4;
int a5 = 5;
// 定义没有初始化的全局变量
int b1, b2, b3, b4, b5;
// 定义函数
void MyFunc()
{
// 定义局部变量
int c1, c2, c3, c4, c5, c6, c7, c8, c9, c10;
// 给局部变量赋值
c1 = 1;
c2 = 2;
c3 = 3;
c4 = 4;
c5 = 5;
c6 = 6;
c7 = 7;
c8 = 8;
c9 = 9;
c10 = 10;
// 把局部变量的值赋给全局变量
a1 = c1;
a2 = c2;
a3 = c3;
a4 = c4;
a5 = c5;
b1 = c6;
b2 = c7;
b3 = c8;
b4 = c9;
b5 = c10;
}将代码清单10-6 变换成汇编语言的源代码后,结果就如代码清单10-7 所示。为了方便说明,省略了一部分汇编语言源代码,并改变了一下段定义的配置顺序,删除了注释。
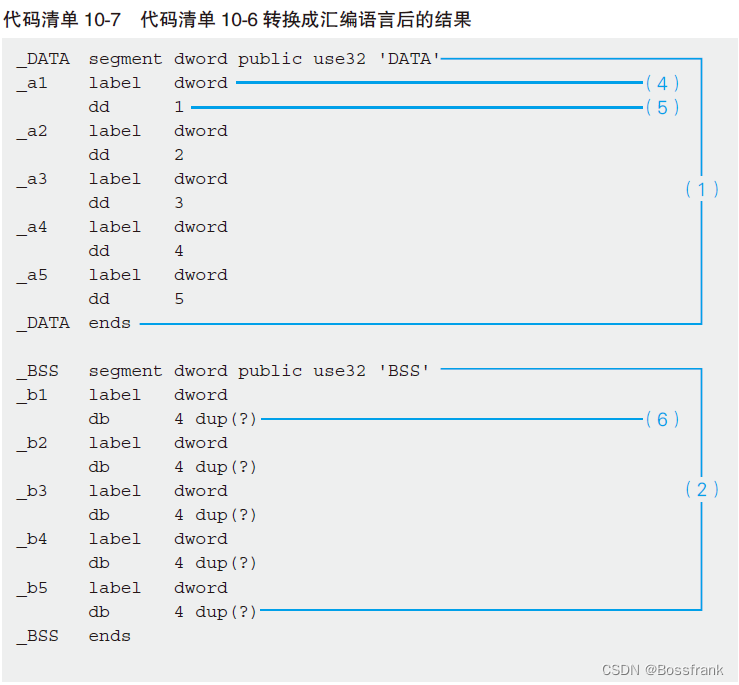

如前文所述,编译后的程序会被归类到名为段定义的组。初始化的全局变量,会像代码10-7 的(1)那样被汇总到名为_DATA的段定义中,没有初始化的全局变量,会像(2)那样被汇总到名为_BSS的段定义中。指令则会像(3)那样被汇总到名为_TEXT的段定义中。这些段定义的名称是由Borland C++的编译器的使用规范来决定的。_DATA segment 和_DATA ends、_BSS segment 和_BSS ends、_TEXT segment 和_TEXT ends,这些都是表示各段定义范围的伪指令。
_DATA 段定义的内容
(4)中的_a1 label dword 定义了_a1 这个标签。 标签表示的是相对于段定义起始位置的位置。由于_a1 在_DATA 段定义的开头位置,所以相对位置是0。_a1就相当于全局变量a1。编译后的函数名和变量名前会附加一个下划线,这也是Borland C++的规定。(5)中的dd 1 指的是,申请分配了4字节的内存空间,存储着1 这个初始值。dd(define double word)表示定义了双字的数据,也就是申请了4字节的内存空间。
_BSS 段定义的内容
这里定义了相当于全局变量b1~b5 的标签_b1~_b5。(6)的db 4 dup(?) 表示的是申请分
配了4 字节的领域,但值尚未确定(这里用? 来表示)的意思。db(define byte)表示有1 个长度是1字节的内存空间。因而,db 4 dup(?)的情况下,就是4字节的内存空间。这里大家要注意不要和dd 4 混淆了。db 4 dup(?) 表示的是4个长度是1 字节的内存空间。而dd 4 表示
的则是双字节(= 4 字节)的内存空间中存储的值是4。
在_DATA 和_BSS 的段定义中,全局变量的内存空间都得到了确保。因而,从程序的开始到结束,所有部分都可以参阅全局变量。而这里之所以根据是否进行了初始化把全局变量的段定义划分为了两部分,是因为在Borland C++ 中,程序运行时没有初始化的全局变量的领域(_BSS 段定义)都会被设定为0进行初始化。可见,通过汇总,初始化很容易实现,只要把内存的特定范围全部设定为0就可以了。
局部变量
为什么局部变量只能在定义该变量的函数内使用?这是因为,局部变量是临时保存在寄存器和栈中的。正如本章前半部分讲的那样,函数内部利用的栈,在函数处理完毕后会恢复到初始状态,因此局部变量的值也就被销毁了,而寄存器也可能会被用于其他目的。因此,局部变量只是在函数处理运行期间临时存储在寄存器和栈上。
在代码清单10-6 中定义了10 个局部变量。这是为了表示存储局部变量的不仅仅是栈,还有寄存器。为确保c1~c10 所需的领域,寄存器空闲时就使用寄存器,寄存器空间不足的话就使用栈。
_TEXT 段定义的内容
(7)表示的是MyFunc 函数的范围。在MyFunc 函数中定义的局部变量所需要的内存空间会被尽可能地分配在寄存器中。只要寄存器有空间,编译器就会使用它。因为与内存相比,
使用寄存器时访问速度会高很多,这样就可以更快速地进行处理。(8)表示的是往寄存器中分配局部变量的部分。仅仅对局部变量进行定义是不够的,只有在给局部变量赋值时,才会被分配到寄存器的内存区域。(8)就相当于给5 个局部变量c1~c5 分别赋予数值1~5 这一处理。eax、edx、ecx、ebx、esi 是Pentium 等x86系列32 位CPU 寄存器的名称(参考表10-2)。至于使用哪一个寄存器,则要由编译器来决定。这种情况下,寄存器只是被单纯地用于存储变量的值,和其本身的角色没有任何关系。x86 系列CPU 拥有的寄存器中,程序可以操作的有十几个。其中空闲的,最多也只有几个。因而,局部变量数目很多的时候,可分配的寄存器就不够了。这种情况下,局部变量就会申请分配栈的内存空间。
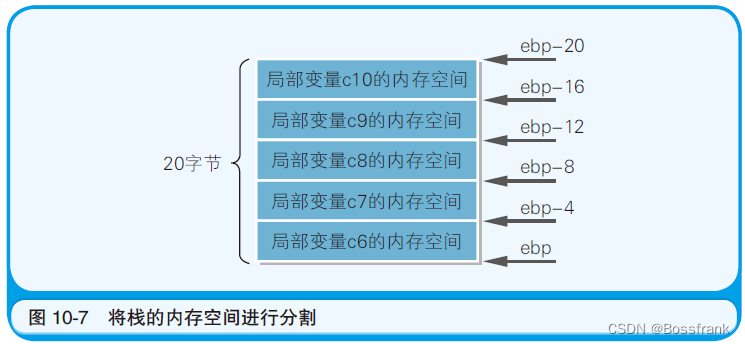
在(8)这一部分中,给局部变量c1~c5 分配完寄存器后,可用的寄存器数量就不足了。于是,剩下的5个局部变量c6~c10 就被分配了栈的内存空间,如(9)所示。函数入口(10)处的add esp,-20 指的是,对栈数据存储位置的esp 寄存器(栈指针)的值做减20的处理,相当于开辟了20字节的空间用于存储变量。为了确保内部变量c6~c10 在栈中,就需要保留5个int类型的局部变量(4 字节×5 = 20 字节)所需的空间。
(11)中的mov ebp,esp 这一处理,指的是把当前esp 寄存器的值复制到ebp 寄存器中。之所以需要(11)这一处理,是为了通过在函数出口处的(12)这一move esp,ebp 的处理,把esp 寄存器的值还原到原始状态,从而对申请分配的栈空间进行释放,这时栈中用到的局部变量就消失了。这也是栈的清理处理。在使用寄存器的情况下,局部变量则会在寄存器被用于其他用途时自动消失(图10-6,这个图画的太好了)。

(9)中的5 行代码是往栈空间中代入数值的部分。由于在向栈申请内存空间前,借助mov ebp,esp 这个处理,esp 寄存器的值被保存到了ebp 寄存器中,因此,通过使用[ebp - 4]、[ebp - 8]、[ebp - 12]、[ebp - 16]、[ebp - 20] 这样的形式,就可以将申请分配的20 字节的栈内存空间切分成5 个长度分别是4 字节的空间来使用(图10-7)。例如,(9)中的mov dword ptr [ebp - 4], 6 表示的就是,从申请分配的内存空间的下端(ebp 寄存器指示的位置)开始往前4字节的地址([ebp - 4])中,存储着数值6这个4字节的数据。
关于往全局变量中代入局部变量的数值这一内容,借助了寄存器作为中介。比如b1 = c6这一操作用了两行的语句,如下:
mov eax,dword ptr [ebp-4]
mov dword ptr [_b1],eax
意思大家应该能明白,就是把ebp - 4 位置的数据,即c6变量,值为6存储到eax中,再将eax中数据存入全局变量b1所在的地址,这样就实现了赋值。为啥不直接move dword ptr [_b1], dword ptr [ebp-4]呢,我觉得是因为不能直接将一个内存地址空间中的值存储到另一个内存空间,必须要借助CPU中的寄存器才行。
程序的流程控制
循环语句
本节介绍C语言等高级程序语言实现循环的流程控制语句对应的汇编语言的处理方式。C语言代码示例10-8如下:
//代码10-8 执行循环处理的C语言源代码
// 定义MySub 函数
void MySub()
{
// 不做任何处理
}
// 定义MyFunc 函数
Void MyFunc()
{
int i;
for (i = 0; i < 10; i++ )
{
// 重复调用MySub 函数10 次
MySub();
}
}转换为汇编语言如代码10-9所示:
;代码10-9 循环语句的汇编代码
xor ebx, ebx ; 将eax 寄存器清0
@4 call _MySub ; // 调用MySub 函数
inc ebx ; //ebx 寄存器的值加1
cmp ebx,10 ; // 将ebx 寄存器的值和10 进行比较
jl short @4 ; // 如果小于10 就跳转到@4
C 语言的for 语句是通过在括号中指定循环计数器的初始值(i =0)、循环的继续条件(i < 10)、循环计数器的更新(i++)这3 种形式来进行循环处理的。与此相对,在汇编语言的源代码中,循环是通过比较指令(cmp)和跳转指令(jl表示小于则跳转)来实现的。
下面就让我们按照代码清单10-9 的内容的顺序来进行说明。
MyFunc 函数中用到的局部变量只有i,变量i申请分配了ebx 寄存器的内存空间。for 语句的括号中的i = 0; 被转换成了xor ebx,ebx 这一处理。xor 指令会对左起第一个操作数和右起第二个操作数进行XOR 运算,然后把结果存储在第一个操作数中。由于这里把第一个操作数和第二个操作数都指定为了ebx,因此就变成了对相同数值进行XOR 运算。也就是说,不管当前ebx 寄存器的值是什么,结果肯定都是0。虽然用mov 指令的mov ebx,0 也会得到同样的结果,但与mov 指令相比,xor指令的处理速度更快。这里,编译器的最优化功能也会启动。ebx 寄存器的值初始化后,会通过call 指令调用MySub 函数(_MySub)。从MySub 函数返回后,则会通过inc指令对ebx寄存器的值做加1处理。该处理就相当于for 语句的i++。
下一行的cmp 指令是用来对第一个操作数和第二个操作数的数值进行比较的指令。cmp ebx,10 就相当于C 语言的i<10 这一处理,意思是把ebx 寄存器的数值同10 进行比较。汇编语言中比较指令的结果,会存储在CPU 的标志寄存器中。
不过,标志寄存器的值,程序是无法直接参考的。那么,程序是怎么来判断比较结果的呢?实际上,汇编语言中有多个跳转指令,这些跳转指令会根据标志寄存器的值来判定是否需要跳转。例如,最后一行的jl,是jump onless than(小于的话就跳转)的意思。也就是说,jl short @4 的意思就是,前面运行的比较指令的结果若“小”的话就跳转到@4 这个标签。
条件分支
条件分支的实现方法同循环处理的实现方法类似,使用的也是cmp 指令和跳转指令。代码清单10-11 是,根据变量a的值来调用不同函数(MySub1 函数、MySub2 函数、MySub3 函数)的C语言源代码:
//代码10-11 条件分支结构的C语言代码
// 定义MySub1 函数
void MySub1()
{
// 不做任何处理
}
// 定义MySub2 函数
void MySub2()
{
// 不做任何处理
}
// 定义MySub3 函数
void MySub3()
{
// 不做任何处理
}
// 定义MyFunc 函数
void MyFunc()
{
int a = 123;
// 根据条件调用不同的函数
if (a > 100)
{
MySub1();
}
else if (a < 50)
{
MySub2();
}
else
{
MySub3();
}
}
将代码10-11转换为汇编代码,如下所示:
;将代码10-11 的MyFunc 函数转换成汇编语言后的结果
_MyFunc proc near
push ebp;
mov ebp,esp;mov eax,123 ; 把123 存入eax 寄存器中
cmp eax,100 ; 把eax 寄存器的值同100 进行比较
jle short @8 ; 比100 小时,跳转到@8 标签
call _MySub1 ; 调用MySub1 函数
jmp short @11 ; 跳转到@11 标签
@8: cmp eax,50 ; 把eax 寄存器的值同50 进行比较
jge short @10 ; 大于50 时,跳转到@10 标签
call _MySub2 ; 调用MySub2 函数
jmp short @11 ; 跳转到@11 标签
@10: call _MySub3 ; 调用MySub4 函数
@11: pop ebp
ret
_MyFunc endp
代码10-12 中用到了三种跳转指令,分别是比较结果小时跳转的jle(jump on less or equal)、大时跳转的jge(jump on greater or equal)、不管结果怎样都无条件跳转的jmp。在这些跳转指令之前还有用来比较的cmp 指令,比较结果被保存在了标志寄存器中。这里添加了注释,读者不妨顺着程序的流程看一下。虽然同C语言源代码的处理流程不完全相同,不过大家应该知道处理结果是相同的。此外,还有一点需要注意的是,eax 寄存器表示的是变量a。
通过汇编语言了解程序运行方式的必要性
从汇编语言源代码中获得的知识,在某些情况下对查找bug的原因也是有帮助的。本节将举出一个例子说明,由于汇编语言和本地代码的一一对应特性,如果懂得汇编语言,也就更容易理解程序是怎样跑起来的,一些底层的Bug也就能够得以解决。示例代码10-13是两个函数更新同一个全局变量数值的C语言程序:
//代码10-13 两个函数更新同一个全局变量数值的C语言程序
// 定义全局变量
int counter = 100;
// 定义MyFunc1 函数
void MyFunc1()
{
counter *= 2;
}
// 定义MyFunc2 函数
void MyFunc2()
{
counter *=2;
}将代码10-13 的counter *= 2; 部分转换成汇编语言源代码后,结果就如代码10-14 所示:
;将全局变量的值翻倍这一部分转换成汇编语言源代码的结果
mov eax,dword ptr[_counter] ; 将counter 的值读入eax 寄存器
add eax,eax ; 将eax 寄存器的值扩大至原来的2 倍
mov dword ptr[_counter],eax ; 将eax 寄存器的数值存入counter 中
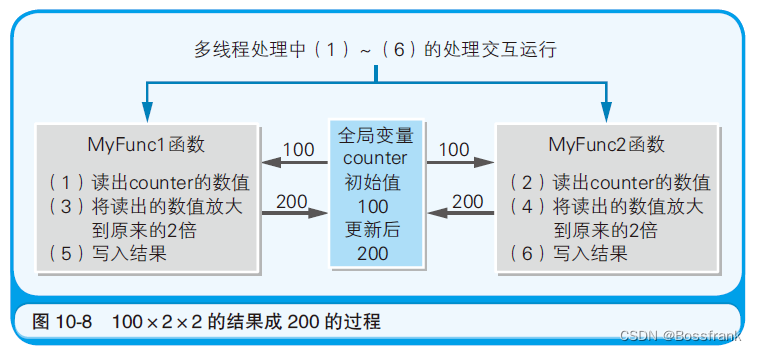
C语言源代码中counter *= 2; 这一个指令的部分,在汇编语言源代码,也就是实际运行的程序中,分成了3个指令。如果只是看counter *= 2; 的话,就会以为counter 的数值被直接扩大为了原来的2 倍。然而,实际上执行的却是“把counter 的数值读入eax 寄存器”“将eax 寄存器的数值变成原来的2 倍”“把eax 寄存器的数值写入counter”这3 个处理。
在多线程处理中,用汇编语言记述的代码每运行1 行,处理都有可能切换到其他线程(函数)中。因而,假设 MyFunc1 函数在读出counter 的数值100 后,还未来得及将它的2 倍值200 写入counter 时,正巧MyFunc2 函数读出了counter 的数值100, 那么结果就会导致counter 的数值变成了200(图10-8):
为了避免该bug,可以采用以函数或C语言源代码的行为单位来禁止线程切换的锁定方法。通过锁定,在特定范围内的处理完成之前,处理不会被切换到其他函数中。至于为什么要锁定MyFunc1函数和MyFunc2 函数,如果不了解汇编语言源代码的话想必是不明白的吧。
结尾
本章的内容比较长,不过总体来说通过举代码示例的方法,还是对汇编语言进行了通俗的阐释。因为汇编语言和CPU运行的本地代码具有一一对应的关系,了解汇编语言对我们理解程序的执行流程有很大的帮助。下面这段话是作者的原话翻译的:
没有汇编语言经验的程序员,就相当于只知道汽车的驾驶方法而不了解汽车结构的驾驶员。对这样的驾驶员来说,如果汽车出现了故障或奇怪的现象,他们就无法自己找到原因。不了解汽车结构的话,开车的时候还可能会浪费油。这样的话,作为职业驾驶员是不合格的。与此相对,有汇编语言经验的程序员,也就相当于了解计算机和程序机制的驾驶员,他们不仅能自己解决问题,还能在驾驶过程中省油。
感觉非常形象。这一章节也让我更加深入的理解了程序是怎样跑起来的!有关这本书的读书笔记就到这里了,我已经将其中最重要的五个章节进行了介绍,收获还是蛮多的,我对于程序的底层原理有了更深入的理解。有关《程序是怎样跑起来的》这本书的读书笔记完结!以后可能还会补一些计算机基础类的书籍。
我还会进一步更新红队打靶的解析和渗透测试相关的技术分享,恳请希望读者们多多支持。