本节目录
数据准备(数据源与数据库)
CTA策略
数据源:
在进行量化分析的时候,最基础的工作是数据准备,即收集数据、清理数据、建立数据库。下面先讨论收集数据的来源,数据来源可分为两大类:免费的数据源和商业数据库。
免费数据源包括新浪财经、Yahoo财经等。这些数据源提供的接口比较复杂,不是很好用。好消息是,Python中有对应的开源工具可以让数据获取变得简单。比如,akShare 能够获取新浪财经的数据,pandas-reader能够获取 Yahoo Finance 的数据。本章主要讨论akShare 和 pandas-reader 的用法。
商业数据库包括万得(Wind)、同花顺(iFind)、聚源等。商业数据库也分为两种,一种是软件终端,除了可以提供各种数据查询和可视化功能之外,还提供了接口以便从终端上提取数据。比如万得终端。终端的好处是价格便宜,简单易用。坏处是对提取的数据量有限制,而且数据的定制化功能很差,很多数据甚至都没有提供接口。另一种是落地数据库,通常是SQL数据库,所有数据直接落地,可以用SQL语句进行提取。落地数据库的好处是数据丰富,定制灵活,没有数据量限制;缺点是成本较高,而且技术门槛也相对较高。大部分人使用的是第一种,即终端提供的接口。本章就以Wind为例,讨论第一种数据库的用法。
前几张也详细谈到过获取数据接口,这里就不展开了,接找几个有用的技巧:
获取交易日历:
import akshare as ak
from datetime import datetime
# Get the trade date history dataframe
tool_trade_date_hist_sina_df = ak.tool_trade_date_hist_sina()
# Specify the start and end dates
start_date = "2022-01-01"
end_date = "2022-12-31"
start_date = datetime.strptime(start_date, "%Y-%m-%d").date()
end_date = datetime.strptime(end_date, "%Y-%m-%d").date()
# Extract the dates within the specified range
selected_dates = tool_trade_date_hist_sina_df[(tool_trade_date_hist_sina_df["trade_date"] >= start_date)\
& (tool_trade_date_hist_sina_df["trade_date"] <= end_date)]
print(selected_dates)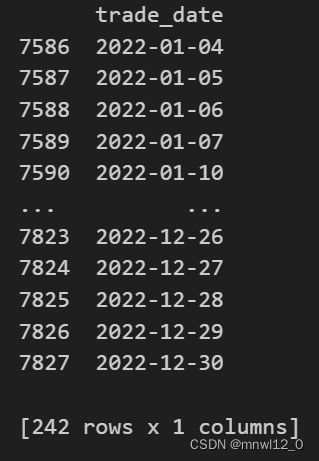
import akshare as ak
from datetime import datetime
macro_usa_gdp_monthly_df = ak.macro_usa_gdp_monthly()
start_date = "2022-01-01"
end_date = "2022-12-31"
start_date = datetime.strptime(start_date, "%Y-%m-%d").date()
end_date = datetime.strptime(end_date, "%Y-%m-%d").date()
# Extract the dates within the specified range
selected_dates = macro_usa_gdp_monthly_df[(macro_usa_gdp_monthly_df["日期"] >= start_date)\
& (macro_usa_gdp_monthly_df["日期"] <= end_date)]
print(selected_dates)如果想要获取国外市场数据,那么pandas-reader将是一个很好的免费数据接口。但pandas-reader也没有包含在Anaconda当中,需要自行安装。可以使用pip命令进行安装,命令如下:
pip install pandas-datareaderPandas集成了很多免费的数据接口,包括但不限于Yahoo Finance、Google Finance、quandl、美联储、世界银行等提供的数据。
pandas-reader的接口使用也很简单。先导入相关的函数,命令如下:
import pandas_datareader.data as web但是好像接口被关闭,获取不到数据。
获取美国宏观经济数据:
import akshare as ak
from datetime import datetime
macro_usa_gdp_monthly_df = ak.macro_usa_gdp_monthly()
start_date = "2022-01-01"
end_date = "2022-12-31"
start_date = datetime.strptime(start_date, "%Y-%m-%d").date()
end_date = datetime.strptime(end_date, "%Y-%m-%d").date()
# Extract the dates within the specified range
selected_dates = macro_usa_gdp_monthly_df[(macro_usa_gdp_monthly_df["日期"] >= start_date)\
& (macro_usa_gdp_monthly_df["日期"] <= end_date)]
print(selected_dates)
万得接口
一个简单例子
万得(Wind)提供了一系列的接口,其中也包含Python的接口。下面列举一段简单的示例代码,用于提取股票000001.SZ一周的日线数据,具体如下:
由于没有账号不方便演示,自行学习跳过。教你使用Python连接Wind金融数据接口 - 知乎 (zhihu.com)
基于Wind返回的data的数据结构特点,在创建DataFrame的时候,必须先将index与Fields 对应,columns与日期对应,之后再进行矩阵转置。
数据库:
存储数据有很多种方式。有人比较喜欢以文件的形式存储,比如,csv文件或hdf5文件。但通常情况下,我还是比较喜欢建立一个数据库,以便于进行数据的管理和分享。而且,数据库本身也能完成很多数据计算和分析工作。
现今的数据库主要分为两种:一种是关系型数据库,也就是使用SQL语句进行操作的数据库,常见的有MySQL、PostgreSQL、SQL Sever等;一种是非关系型(NoSQL)数据库,比如MongoDB。这两种数据库各有其优势,这里主要还是使用传统的SQL数据库。本书中以PostgreSQL为例。SQL基础知识的讲解不在范围之内,大家可以自行查找相关的教程进行学习。这里假设读者已经具有SQL的相关基础。
Pandas利用SQLAlchemy包,提供了简单的数据库接口。比如,我们想把一个dataframe 存储到数据库里面,
前提是已经安装了:
pip install psycopg2
pip install sqlalchemy可以使用如下代码:
from sqlalchemy import create_engine
engine=create_engine ('postgresql://postgres@localhost:5432/postgres')
df.to_sql('stock_all_info',engine, if_exists='replace', index=True)其中,engine存储了连接数据库的相关信息(数据库地址、数据库名称、用户名和密码)。
在df.to_sql中,第一个参数表示表的名称。参数if_exists表示假如现在已经存在此表,应进行什么操作;append代表在当前表中添加新的列;replace 表示替换当前表(删除当前已有的表);fail 表示不进行任何操作,默认值是fail;参数index 表示是否将DataFrame的索引也存储到表中。
存储的时候,数据库会自动识别每列的数据类型,并对应到SQL数据库的类型。比如我们将前面获取到的数据存储到stock_all_info中。数据库中会生成一张表。
由于date在df里面是索引,所以数据库也会自动地为这张表创建一个 date索引。
数据库的读取也非常容易,可以使用如下代码实现:
df=pd.read_sql('select * from stock_info',where windcode = '000001.SZ',engine)其中,第一个参数是一个SQL查询语句,接口将返回该查询语句对应的DataFrame。
下载所有股票历史数据并存储
做策略研究的朋友经常会有建立一个完整的股票数据库的需求。本节将展示一个小程序,指导下载所有股票历史行情并存储到数据库中。
先回顾如何在数据库里面创建表:
CREATE TABLE stocks (
id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
symbol VARCHAR(10) NOT NULL,
date DATE NOT NULL,
open DECIMAL(10,4),
high DECIMAL(10,4),
low DECIMAL(10,4),
close DECIMAL(10,4)
);
实现代码具体如下:
上面的程序,主要分为两步,第一步获取所有A股的代码。第二步是针对每一个股票,获取对应的指标(这里是open、high、low、close),并存储于数据中。