文章目录
- 0 前言
- 2 开发简介
- 3 数据集
- 4 实现技术
- 4.1 系统架构
- 4.2 开发环境
- 4.3 疫情地图
- 4.3.1 填充图(Choropleth maps)
- 4.3.2 气泡图
- 4.4 全国疫情实时追踪
- 4.6 其他页面
- 5 关键代码
- 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 大数据疫情分析及可视化系统
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 开发简介
学长从各省累计确诊人数随时间增长的态势以及空间分布随时间增长的态势入手,利用所收集的数据将各省累计确诊人数的时空分布用地图、折线图、堆叠条形图的形式呈现出来,从总体态势进行大致分析,然后再通过在不同粒度上展示各省疫情相关的详细信息,以发现其在不同时间段影响其态势变化的原因(境外输入、相关政策颁布等)。
同时还将疫情相关确诊、死亡等数据与各省的GDP、受教育程度、城镇化率、医疗卫生水平进行联系,以发现其与GDP、受教育程度、城镇化率之间是否存在关系。
其目标用户是政府等防控机关,通过本系统可以分析疫情时空分布模式、监控疫情发展态势、评估疫情防控措施。
3 数据集
数据源于爬虫与手动搜集:
weibo.json 新浪微博实时热搜前50的数据

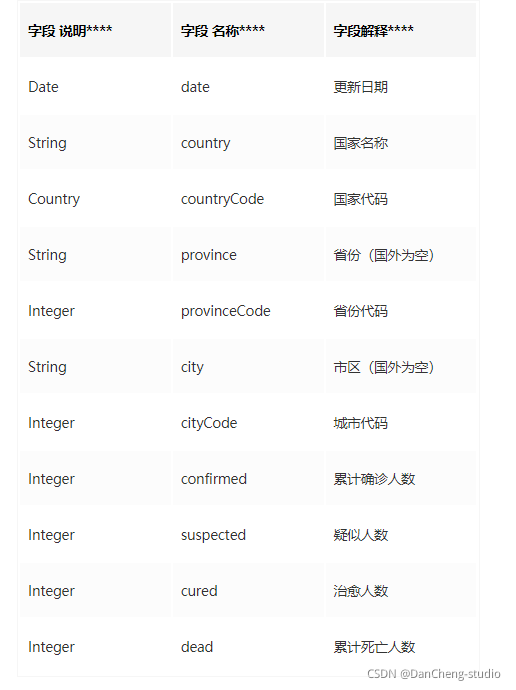
ProvinceData.json 省市疫情详情
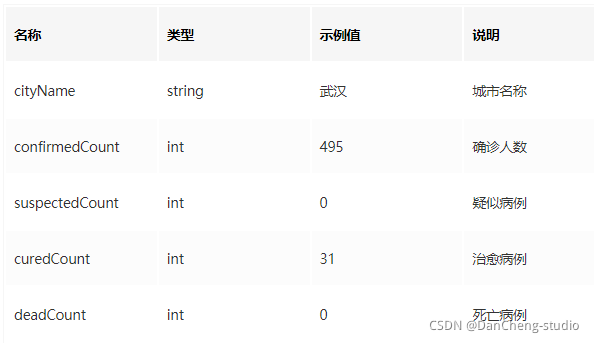
源于中国国家统计局(2018年中国统计年鉴)的数据
2020-01-10至2020-02-06数据来自国家,各省,武汉市卫健委疫情公告,2020-02-07后数据从今日头条接口采集

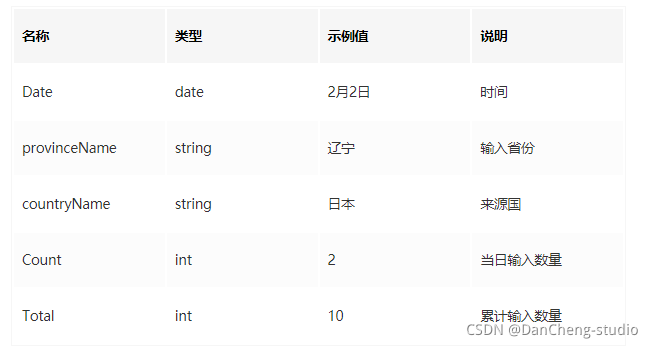
境外输入数据(手动从网上新闻中搜集)
4 实现技术
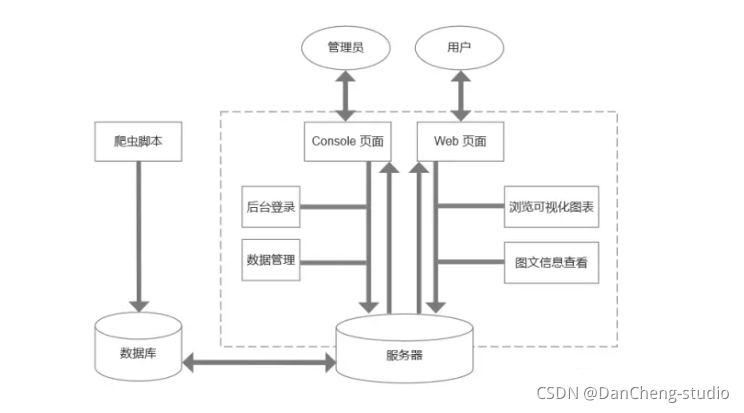
4.1 系统架构
4.2 开发环境
- 1、Node.js(前端Vue和后端node都依赖该环境)
- 2、开发工具:Git,vscode,Hbuilder,pycharm
- 3、开发语言:Python,HTML+CSS+JavaScript
- 4、重点依赖库:echarts,bootstrap,jQuery
4.3 疫情地图
新型冠状病毒肺炎已经开始全球蔓延,形势越来越严峻,我们除了关注国内发展疫情发展,也开始关注境外疫情的发展变化。通过地理可视化我们能够很直观的看到的各个区域的疫情严重程度。
4.3.1 填充图(Choropleth maps)
- 填充图适合表达区域之间的差异。
- 填充图能够很好的展现形全局差异,细微的差异很难表达。
- 但填充图的展现效果受区域面积影响比较大,容易形成误导
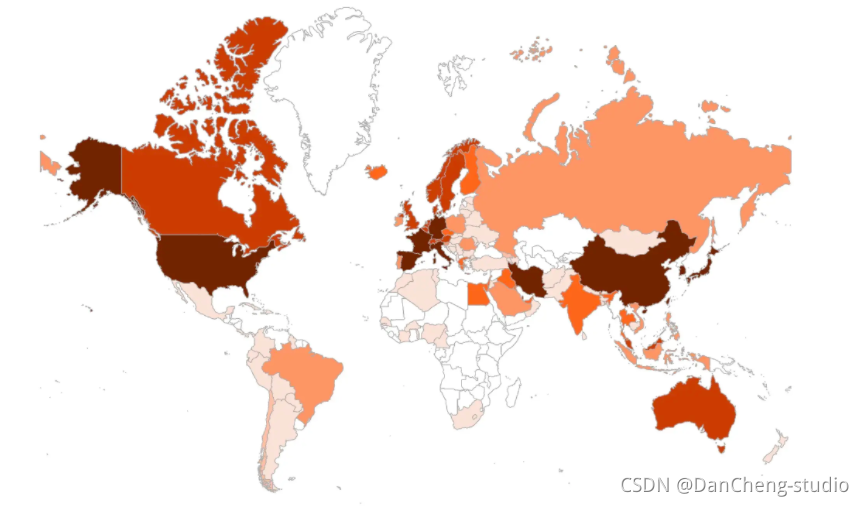
上面的填充图,我们可以关注到亚洲,欧洲,美洲三大疫情区域,但是我们很难关注到,意大利、韩国的疫情严重程度。
4.3.2 气泡图
气泡图使用不同大小的圆圈表示区域上的数值。它在每个地理坐标上显示一个气泡,或在每个区域显示一个气泡。
下图我们以气泡图形式进行疫情地图可视化

通过气泡图我们可以很明确的看出世界上疫情比较严重的国家,而且不会受到区域面积的干扰,欧洲一些面积比较小的国家我们也能够清晰的识别出来。气泡图表达方式缺点在于气泡过多,过大将会产生遮盖现在。
气泡是一种比较好的展现形式,如果使用方式不当也会产生干扰,比如数据映射方法选择,颜色色带选择都会影响数据表达的结果。
关键代码:
# 作者:丹成学长 q746876041
import json
import requests
import jsonpath
from pyecharts.charts import Map,Geo
from pyecharts import options as opts
from pyecharts.globals import GeoType,RenderType
# 1.目标网站
url=‘https://api.inews.qq.com/newsqa/v1/automation/foreign/country/ranklist’
# 2.请求资源
resp=requests.get(url)
# 3.提取数据
# 类型转换 json–>dict
data=json.loads(resp.text)
name = jsonpath.jsonpath(data,“KaTeX parse error: Expected 'EOF', got '#' at position 14: ..name") #̲ print(name) ……confirm”)
# print(confirm)
data_list = zip(name,confirm)
# print(list(data_list))
# 4.可视化 matplotlib 和 pyecharts
nameMap = {
'Singapore Rep.':'新加坡',
'Dominican Rep.':'多米尼加',
'Palestine':'巴勒斯坦',
'Bahamas':'巴哈马',
'Timor-Leste':'东帝汶',
'Afghanistan':'阿富汗',
'Guinea-Bissau':'几内亚比绍',
"Côte d'Ivoire":'科特迪瓦',
'Siachen Glacier':'锡亚琴冰川',
"Br. Indian Ocean Ter.":'英属印度洋领土',
'Angola':'安哥拉',
'Albania':'阿尔巴尼亚',
'United Arab Emirates':'阿联酋',
'Argentina':'阿根廷',
'Armenia':'亚美尼亚',
'French Southern and Antarctic Lands':'法属南半球和南极领地',
'Australia':'澳大利亚',
'Austria':'奥地利',
'Azerbaijan':'阿塞拜疆',
'Burundi':'布隆迪',
'Belgium':'比利时',
'Benin':'贝宁',
'Burkina Faso':'布基纳法索',
'Bangladesh':'孟加拉国',
'Bulgaria':'保加利亚',
'The Bahamas':'巴哈马',
'Bosnia and Herz.':'波斯尼亚和黑塞哥维那',
'Belarus':'白俄罗斯',
'Belize':'伯利兹',
'Bermuda':'百慕大',
'Bolivia':'玻利维亚',
'Brazil':'巴西',
'Brunei':'文莱',
'Bhutan':'不丹',
'Botswana':'博茨瓦纳',
'Central African Rep.':'中非',
'Canada':'加拿大',
'Switzerland':'瑞士',
'Chile':'智利',
'China':'中国',
'Ivory Coast':'象牙海岸',
'Cameroon':'喀麦隆',
'Dem. Rep. Congo':'刚果民主共和国',
'Congo':'刚果',
'Colombia':'哥伦比亚',
'Costa Rica':'哥斯达黎加',
'Cuba':'古巴',
'N. Cyprus':'北塞浦路斯',
'Cyprus':'塞浦路斯',
'Czech Rep.':'捷克',
'Germany':'德国',
'Djibouti':'吉布提',
'Denmark':'丹麦',
'Algeria':'阿尔及利亚',
'Ecuador':'厄瓜多尔',
'Egypt':'埃及',
'Eritrea':'厄立特里亚',
'Spain':'西班牙',
'Estonia':'爱沙尼亚',
'Ethiopia':'埃塞俄比亚',
'Finland':'芬兰',
'Fiji':'斐',
'Falkland Islands':'福克兰群岛',
'France':'法国',
'Gabon':'加蓬',
'United Kingdom':'英国',
'Georgia':'格鲁吉亚',
'Ghana':'加纳',
'Guinea':'几内亚',
'Gambia':'冈比亚',
'Guinea Bissau':'几内亚比绍',
'Eq. Guinea':'赤道几内亚',
'Greece':'希腊',
'Greenland':'格陵兰',
'Guatemala':'危地马拉',
'French Guiana':'法属圭亚那',
'Guyana':'圭亚那',
'Honduras':'洪都拉斯',
'Croatia':'克罗地亚',
'Haiti':'海地',
'Hungary':'匈牙利',
'Indonesia':'印度尼西亚',
'India':'印度',
'Ireland':'爱尔兰',
'Iran':'伊朗',
'Iraq':'伊拉克',
'Iceland':'冰岛',
'Israel':'以色列',
'Italy':'意大利',
'Jamaica':'牙买加',
'Jordan':'约旦',
'Japan':'日本',
'Japan':'日本本土',
'Kazakhstan':'哈萨克斯坦',
'Kenya':'肯尼亚',
'Kyrgyzstan':'吉尔吉斯斯坦',
'Cambodia':'柬埔寨',
'Korea':'韩国',
'Kosovo':'科索沃',
'Kuwait':'科威特',
'Lao PDR':'老挝',
'Lebanon':'黎巴嫩',
'Liberia':'利比里亚',
'Libya':'利比亚',
'Sri Lanka':'斯里兰卡',
'Lesotho':'莱索托',
'Lithuania':'立陶宛',
'Luxembourg':'卢森堡',
'Latvia':'拉脱维亚',
'Morocco':'摩洛哥',
'Moldova':'摩尔多瓦',
'Madagascar':'马达加斯加',
'Mexico':'墨西哥',
'Macedonia':'马其顿',
'Mali':'马里',
'Myanmar':'缅甸',
'Montenegro':'黑山',
'Mongolia':'蒙古',
'Mozambique':'莫桑比克',
'Mauritania':'毛里塔尼亚',
'Malawi':'马拉维',
'Malaysia':'马来西亚',
'Namibia':'纳米比亚',
'New Caledonia':'新喀里多尼亚',
'Niger':'尼日尔',
'Nigeria':'尼日利亚',
'Nicaragua':'尼加拉瓜',
'Netherlands':'荷兰',
'Norway':'挪威',
'Nepal':'尼泊尔',
'New Zealand':'新西兰',
'Oman':'阿曼',
'Pakistan':'巴基斯坦',
'Panama':'巴拿马',
'Peru':'秘鲁',
'Philippines':'菲律宾',
'Papua New Guinea':'巴布亚新几内亚',
'Poland':'波兰',
'Puerto Rico':'波多黎各',
'Dem. Rep. Korea':'朝鲜',
'Portugal':'葡萄牙',
'Paraguay':'巴拉圭',
'Qatar':'卡塔尔',
'Romania':'罗马尼亚',
'Russia':'俄罗斯',
'Rwanda':'卢旺达',
'W. Sahara':'西撒哈拉',
'Saudi Arabia':'沙特阿拉伯',
'Sudan':'苏丹',
'S. Sudan':'南苏丹',
'Senegal':'塞内加尔',
'Solomon Is.':'所罗门群岛',
'Sierra Leone':'塞拉利昂',
'El Salvador':'萨尔瓦多',
'Somaliland':'索马里兰',
'Somalia':'索马里',
'Serbia':'塞尔维亚',
'Suriname':'苏里南',
'Slovakia':'斯洛伐克',
'Slovenia':'斯洛文尼亚',
'Sweden':'瑞典',
'Swaziland':'斯威士兰',
'Syria':'叙利亚',
'Chad':'乍得',
'Togo':'多哥',
'Thailand':'泰国',
'Tajikistan':'塔吉克斯坦',
'Turkmenistan':'土库曼斯坦',
'East Timor':'东帝汶',
'Trinidad and Tobago':'特里尼达和多巴哥',
'Tunisia':'突尼斯',
'Turkey':'土耳其',
'Tanzania':'坦桑尼亚',
'Uganda':'乌干达',
'Ukraine':'乌克兰',
'Uruguay':'乌拉圭',
'United States':'美国',
'Uzbekistan':'乌兹别克斯坦',
'Venezuela':'委内瑞拉',
'Vietnam':'越南',
'Vanuatu':'瓦努阿图',
'West Bank':'西岸',
'Yemen':'也门',
'South Africa':'南非',
'Zambia':'赞比亚',
'Zimbabwe':'津巴布韦'
}
map = Map().add(series_name='世界疫情分布',
data_pair=data_list,
maptype='world',
name_map=nameMap,
is_map_symbol_show=False
)
map.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
map.render('世界疫情分布情况3.html')
# 作者:丹成学长 q746876041
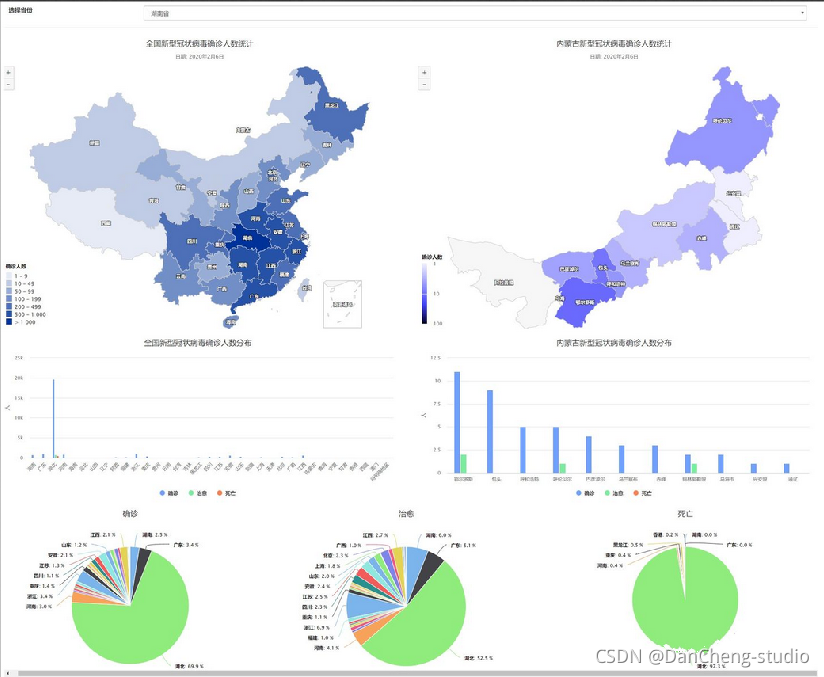
4.4 全国疫情实时追踪
全国疫情实时追踪页面,支持折线图、条形图、扇形图、地图热力图展示,图表由Echarts实现,支持左上角侧边栏跳转。

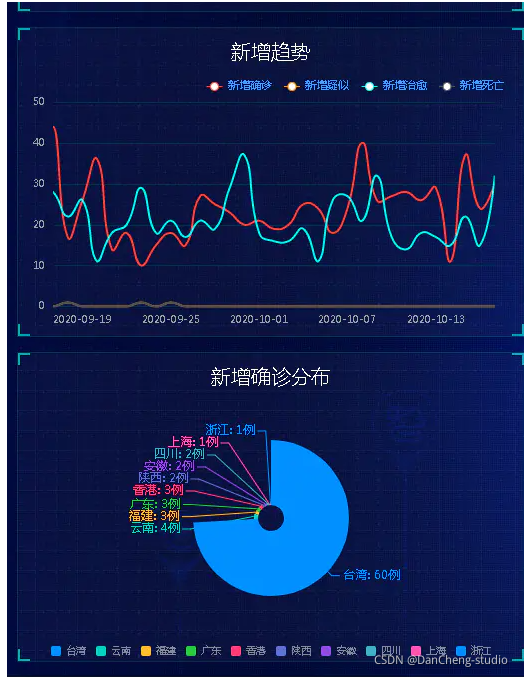
4.6 其他页面


5 关键代码
两个数据表
CREATE TABLE `history` (
`ds` datetime NOT NULL COMMENT '日期',
`confirm` int(11) DEFAULT NULL COMMENT '累计确诊',
`confirm_add` int(11) DEFAULT NULL COMMENT '当日新增确诊',
`suspect` int(11) DEFAULT NULL COMMENT '剩余疑似',
`suspect_add` int(11) DEFAULT NULL COMMENT '当日新增疑似',
`heal` int(11) DEFAULT NULL COMMENT '累计治愈',
`heal_add` int(11) DEFAULT NULL COMMENT '当日新增治愈',
`dead` int(11) DEFAULT NULL COMMENT '累计死亡',
`dead_add` int(11) DEFAULT NULL COMMENT '当日新增死亡',
PRIMARY KEY (`ds`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `details` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`update_time` datetime DEFAULT NULL COMMENT '数据最后更新时间',
`province` varchar(50) DEFAULT NULL COMMENT '省',
`city` varchar(50) DEFAULT NULL COMMENT '市',
`confirm` int(11) DEFAULT NULL COMMENT '累计确诊',
`confirm_add` int(11) DEFAULT NULL COMMENT '新增治愈',
`heal` int(11) DEFAULT NULL COMMENT '累计治愈',
`dead` int(11) DEFAULT NULL COMMENT '累计死亡',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
import requests
import json
import time
import pymysql
#返回历史数据和当日详细数据
def get_tencent_data():
url1 = "https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5"
url2 = "https://view.inews.qq.com/g2/getOnsInfo?name=disease_other"
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
r1 = requests.get(url1, headers)
r2 = requests.get(url2, headers)
#json字符串转字典
res1 = json.loads(r1.text)
res2 = json.loads(r2.text)
data_all1 = json.loads(res1["data"])
data_all2 = json.loads(res2["data"])
#历史数据
history = {}
for i in data_all2["chinaDayList"]:
ds = "2020." + i["date"]
tup = time.strptime(ds, "%Y.%m.%d") # 匹配时间
ds = time.strftime("%Y-%m-%d", tup) #改变时间输入格式,不然插入数据库会报错,数据库是datatime格式
confirm = i["confirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
history[ds] = {"confirm": confirm, "suspect": suspect, "heal": heal, "dead": dead}
for i in data_all2["chinaDayAddList"]:
ds = "2020." + i["date"]
tup = time.strptime(ds, "%Y.%m.%d") # 匹配时间
ds = time.strftime("%Y-%m-%d", tup) #改变时间输入格式,不然插入数据库会报错,数据库是datatime格式
confirm = i["confirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
history[ds].update({"confirm_add": confirm, "suspect_add": suspect, "heal_add": heal, "dead_add": dead})
#当日详细数据
details = []
update_time = data_all1["lastUpdateTime"]
data_country = data_all1["areaTree"] #list 25个国家
data_province = data_country[0]["children"] #中国各省
for pro_infos in data_province:
province = pro_infos["name"] #省名
for city_infos in pro_infos["children"]:
city = city_infos["name"]
confirm = city_infos["total"]["confirm"]
confirm_add = city_infos["today"]["confirm"]
heal = city_infos["total"]["heal"]
dead = city_infos["total"]["dead"]
details.append([update_time, province, city, confirm, confirm_add, heal, dead])
return history, details
def get_conn():
#建立连接
conn = pymysql.connect(host="127.0.0.1", user="root", password="*", db="cov", charset="utf8")
#创建游标
cursor = conn.cursor()
return conn,cursor
def close_conn(conn,cursor):
if cursor:
cursor.close()
if conn:
conn.close()
#插入details数据
def update_details():
cursor = None
conn = None
try:
li = get_tencent_data()[1] #0是历史数据,1是当日详细数据
conn,cursor = get_conn()
sql = "insert into details(update_time,province,city,confirm,confirm_add,heal,dead) values(%s,%s,%s,%s,%s,%s,%s)"
sql_query = "select %s=(select update_time from details order by id desc limit 1)" #对比当前最大时间戳
#对比当前最大时间戳
cursor.execute(sql_query,li[0][0])
if not cursor.fetchone()[0]:
print(f"{time.asctime()}开始更新数据")
for item in li:
cursor.execute(sql,item)
conn.commit()
print(f"{time.asctime()}更新到最新数据")
else:
print(f"{time.asctime()}已是最新数据!")
except:
traceback.print_exc()
finally:
close_conn(conn,cursor)
#插入history数据
def insert_history():
cursor = None
conn = None
try:
dic = get_tencent_data()[0]#0代表历史数据字典
print(f"{time.asctime()}开始插入历史数据")
conn,cursor = get_conn()
sql = "insert into history values (%s,%s,%s,%s,%s,%s,%s,%s,%s)"
for k,v in dic.items():
cursor.execute(sql,[k, v.get("confirm"),v.get("confirm_add"),v.get("suspect"),
v.get("suspect_add"),v.get("heal"),v.get("heal_add"),
v.get("dead"),v.get("dead_add")])
conn.commit()
print(f"{time.asctime()}插入历史数据完毕")
except:
traceback.print_exc()
finally:
close_conn(conn,cursor)
#更新历史数据
def update_history():
cursor = None
conn = None
try:
dic = get_tencent_data()[0]#0代表历史数据字典
print(f"{time.asctime()}开始更新历史数据")
conn,cursor = get_conn()
sql = "insert into history values (%s,%s,%s,%s,%s,%s,%s,%s,%s)"
sql_query = "select confirm from history where ds=%s"
for k,v in dic.items():
if not cursor.execute(sql_query,k):
cursor.execute(sql,[k, v.get("confirm"),v.get("confirm_add"),v.get("suspect"),
v.get("suspect_add"),v.get("heal"),v.get("heal_add"),
v.get("dead"),v.get("dead_add")])
conn.commit()
print(f"{time.asctime()}历史数据更新完毕")
except:
traceback.print_exc()
finally:
close_conn(conn,cursor)
insert_history()
update_details()
最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate