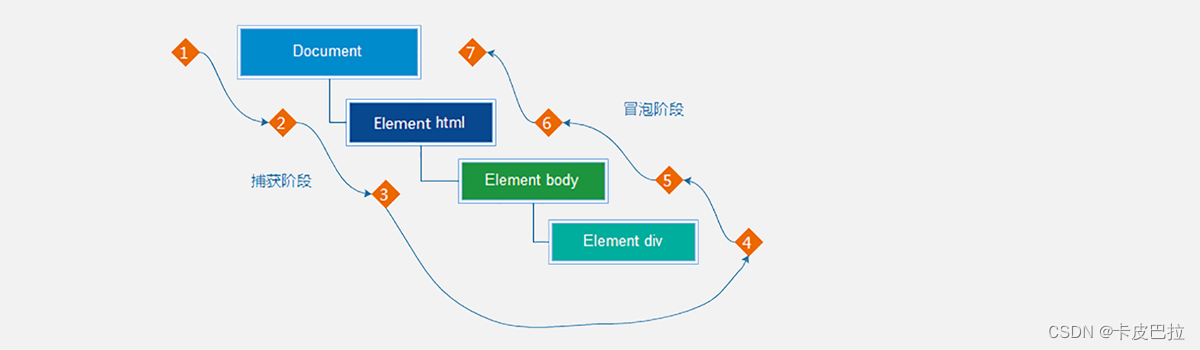
OpenMP概述
通过线程实现并行化,与Pthread一样,是基于线程的共享内存库
与Pthread的不同

简而言之:
Pthread更加底层,需要用户自己定义每一个线程的行为,OpenMP虽然更加简单,但是底层的线程交互实现很难
CLION设置
CMakeLists.txt
FIND_PACKAGE( OpenMP REQUIRED)
if(OPENMP_FOUND)
message("OPENMP FOUND")
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} ${OpenMP_C_FLAGS}")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${OpenMP_CXX_FLAGS}")
endif()
样例
#include <omp.h>
#include <iostream>
using namespace std;
int main() {
int tid, mcpu;
//get the thread ID
tid = omp_get_thread_num();
//get the number of threads in the current parallel area
mcpu = omp_get_num_threads();
cout << "hello from thread " << tid << " in " << mcpu << "CPUs" << endl;
#pragma omp parallel private(tid, mcpu) default(none)
//尽量不适用shared去***共享变量***,因为多个线程只会使用这一个变量的地址,会造成值的覆盖问题
//如果不指定thread_num默认会根据电脑CPU的逻辑线程数进行创建
{
tid = omp_get_thread_num();
mcpu = omp_get_num_threads();
//std::cout << "hello from thread " << tid << " in " << mcpu << "CPUs" << endl;
printf("aaa");
}
cout << "hello from thread " << tid << " in " << mcpu << "CPUs" << endl;
}
default(none)
表示所有的变量均默认为private,如需要设置共享变量,则需要使用shared字段
注意:
C++中的std::cout如果想要在并行空间中使用,就必须加入到shared字段中去,并且cout中的<<符号其实相当于又调用一次cout,如果期望输出不受干扰,推荐使用printf。

for
表明接下来的for循环将会使用并行的方式执行:

int main() {
#pragma omp parallel for num_threads(4) default(none)//注意这里没有大括号!!!
for (int i = 0; i < 12; i++) {
printf("i= %d,I am Thread %d\n", i, omp_get_thread_num());
}
return 0;
}
分配策略为平均分配,每个线程均等分循环次数:

数据依赖

即[i]的结果依赖于[i-1]和[i-2],这就会导致:
如果后面的线程首先被执行,但它用的却是之前未被计算的数据,从而使得数据计算不正确
变量作用域

private
表示变量在线程中私有,其他线程访问不到,相当于每个线程内部都有一个名字一样的变量,每个线程只操作自己的变量,进入for,该变量与先前定义的值无关,会自动赋值为一个默认值(int:0,double:0.000等),上代码:
int main() {
const int n=1000;
int a[n],b[n],c[n],d[n],tmp;
for(int i=0;i<n;i++) {
a[i]=i;
b[i]=1000-a[i];
}
omp_set_num_threads(8);
#pragma omp parallel for default(none) shared(a,b,c,tmp,n)//这里的shared表示并行区间要使用区间外的变量
/*
* 当前没有声明tmp为每个线程中的私有变量,所以在并行区间内,tmp是共享的,于是可能出现如下情况:
* 线程1访问完tmp,正准备给c[i],赋值,此时线程5刚好修改了tmp,于是线程1赋值给c[i]的结果就出错了
* */
//计算c[i]
for(int i=0;i<n;i++) {
tmp=a[i]-b[i];
c[i]=tmp*2;
}
//计算d[i]
for(int i=0;i<n;i++) {
tmp=a[i]-b[i];
d[i]=tmp*2;
}
//统计出错次数
int count=0;
for(int i=0;i<n;i++) {
if(c[i]!=d[i]) count++;
}
printf("%d",count);
return 0;
}
输出结果(数据量1000):

计算量越大,线程数越多,发生抢占的几率就越大,出错的可能也越大,如数据量为10000:

加入private字段后:错误数为
0

firstprivate
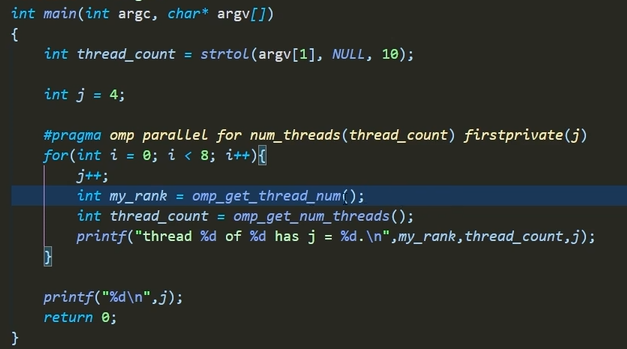

数据拷贝
无论是什么类型的数据,都会重新创建一个变量,如果是数组类型,则重新创建一个一模一样的数组,如果是类的实例,则会调用构造函数创建一个一模一样的实例,在并行区间内改变变量的值,都不会影响并行区间外的变量但是特别注意:
如果是指针,同样,会创建一个一模一样的指针,该指针和并行区间外的指针指向同一个内存单元,只是由于指针的定义,在并行区间内对变量所指地址的值进行修改,就会改变区间外变量所指的值,因为他俩指向的是同一个地址
int main() {
int a[] = {1, 2, 3, 4, 5};
int *b=a;
omp_set_num_threads(5);
#pragma omp parallel default(none) firstprivate(a,b)
{
//b[0]=100;
a[0]=100;
}
printf("a[0]=%d\n",a[0]);
printf("b[0]=%d",b[0]);
return 0;
}
输出结果:
a[0]=1
b[0]=1
如果将a[0]=100注释,而b[0]=100取消注释,则是对指针类型操作,在并行区间内改变指针所指的值,区间外指针所指的值也会随之改变
lastprivate
某一线程执行的最后一个循环(与最后执行的线程无关,而是与执行最后一次循环的线程有关)出去的时候,会将并行区间内变量的值替换掉并行区间外变量的值
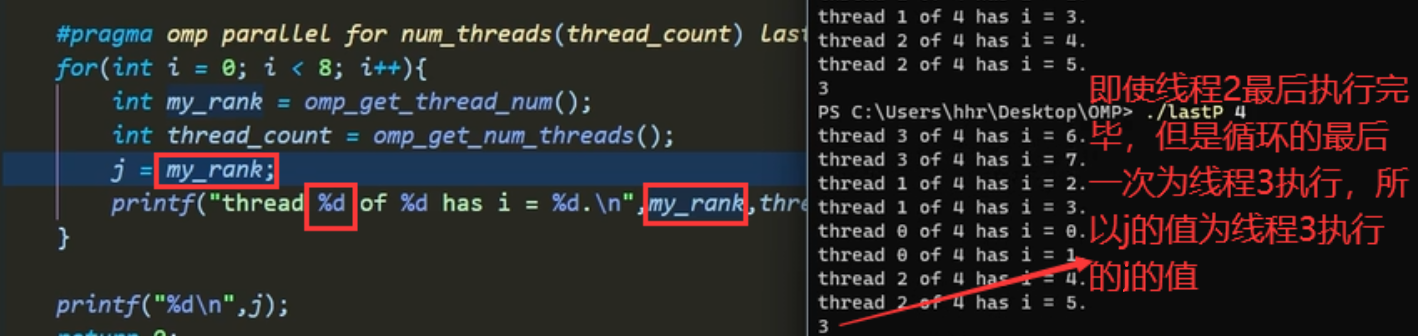
自定义哪个线程做哪一部分
single选项
- 告诉编译器接下来的代码
只由一个线程执行 - 在处理
使用多线程不安全代码时非常有用 - 不使用
no wait选项时,其他线程会等待single线程结束之后,才继续
master选项
- 告诉编译器接下来的代码只由
主线程执行 - 其他线程
不会等待


section选项
- 在
sections中定义section,由线程组分配任务- 每个section都是被
一个线程执行 - 不同section可能执行
不同任务 - 如果一个线程执行
速度很快,则该线程可能又去执行另外的section了,即一个线程可能执行多个section
- 每个section都是被
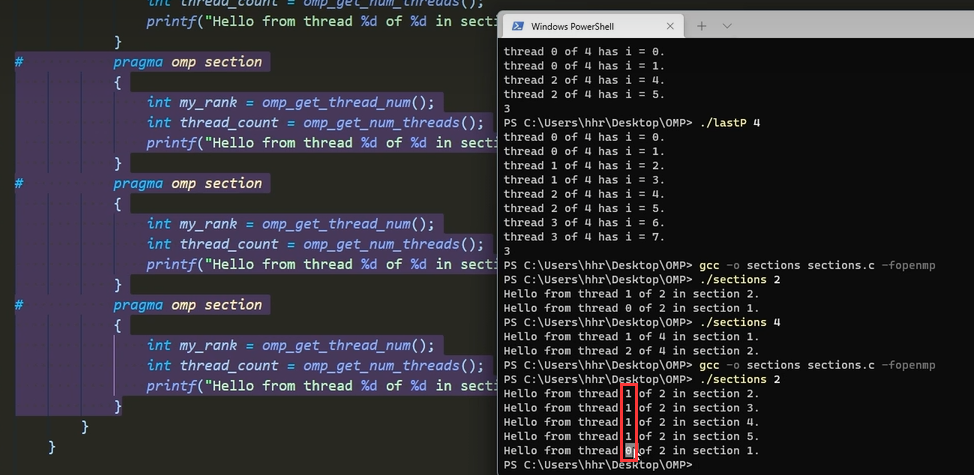
2个section 分配4个线程,谁先抢到谁执行

5个section,2个线程,同样谁先抢到谁执行: 下图可以看到,1号线程执行很快,抢到了4个section
reduction计算
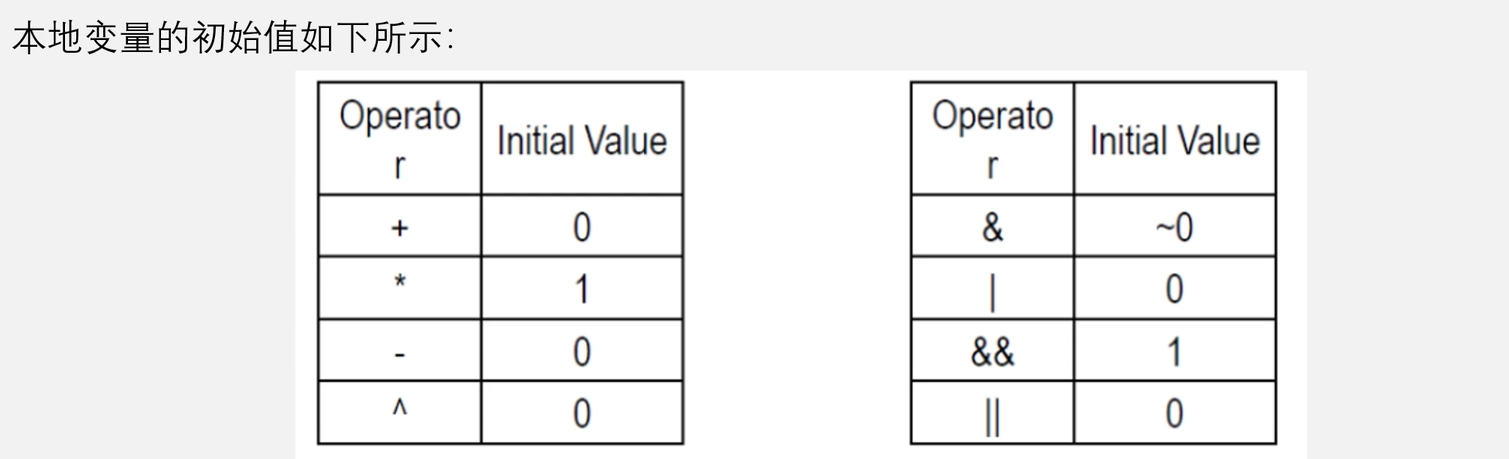
- 首先会对变量进行相当于
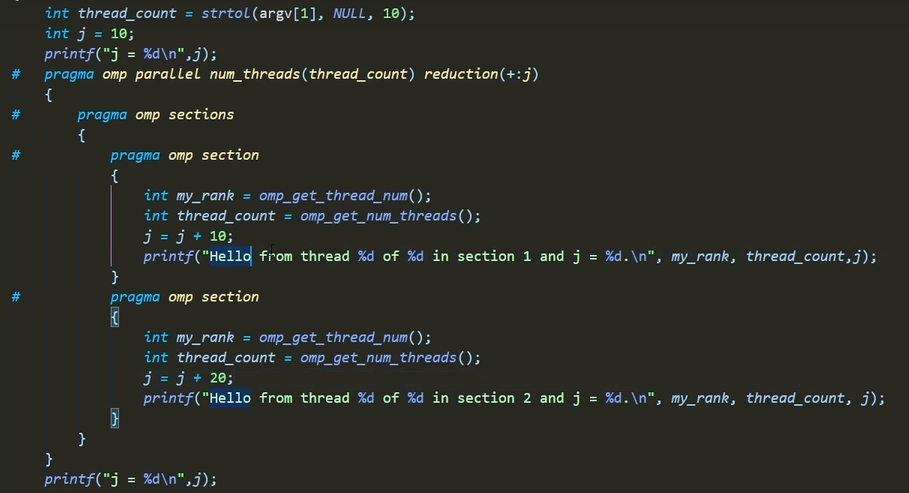
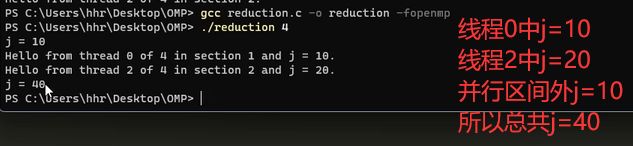
private的拷贝,并赋初值,如下图;与lastprivate不同的是,reduction会将所有该变量(包括所有线程的同名变量以及并行区间外的该变量)进行相应运算操作 reduction提供的操作符基本都符合结合律
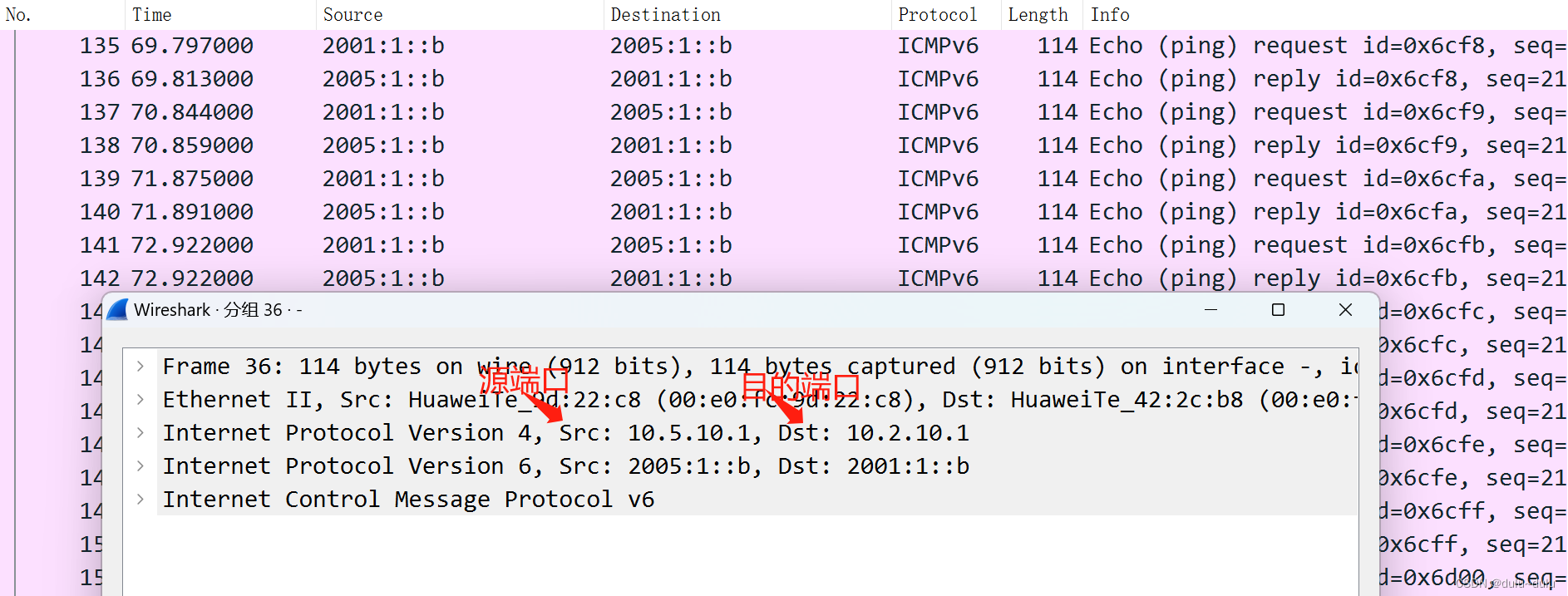
barrier同步

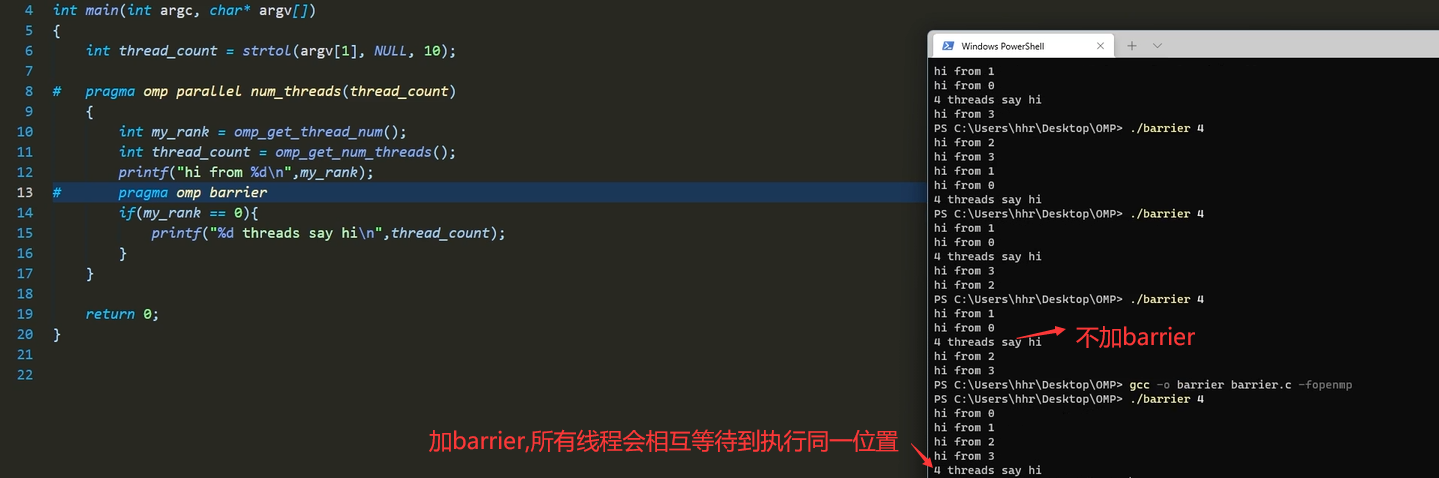
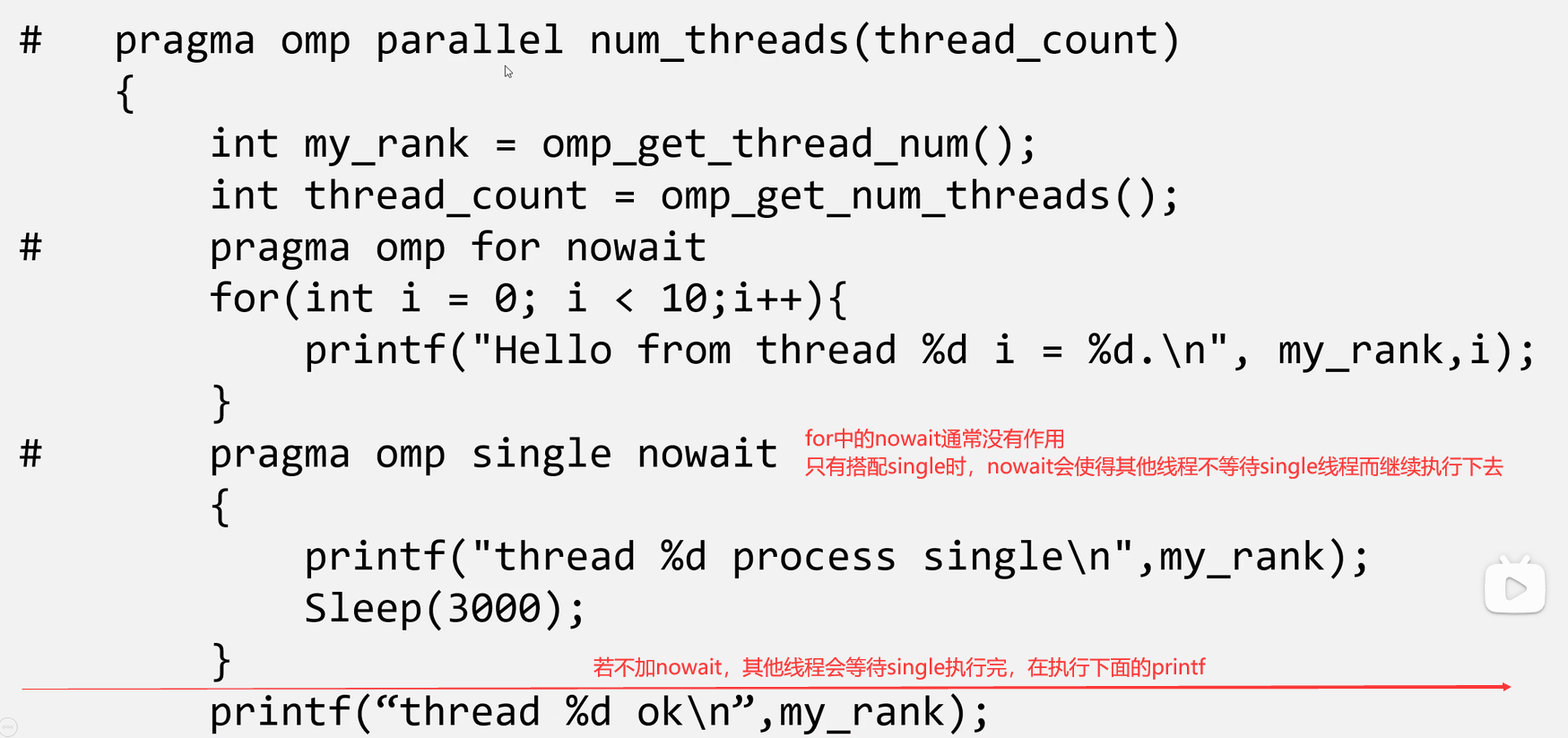
nowait取消等待
不让线程彼此相互等待,每个线程继续执行下去
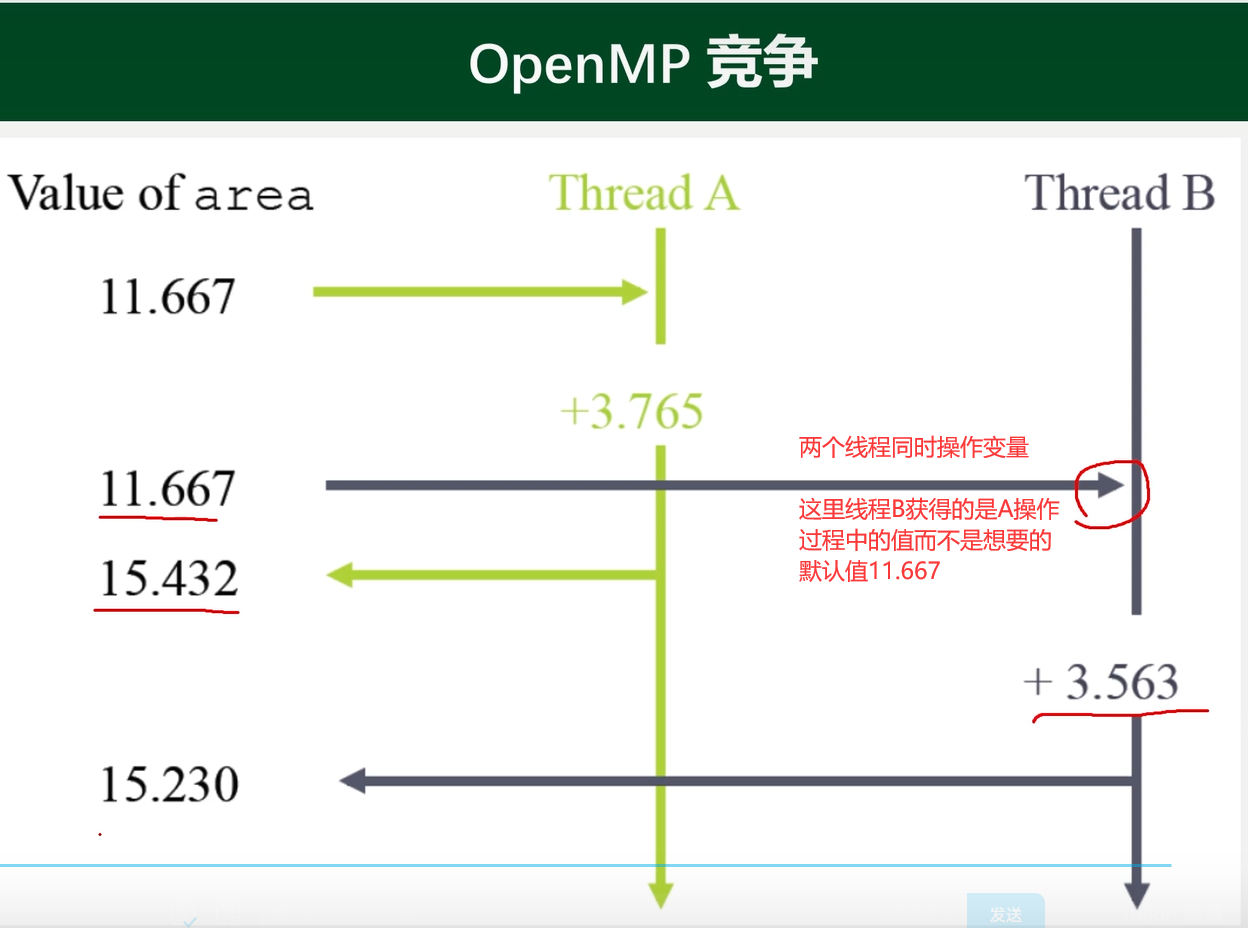
critical互斥
竞争现象

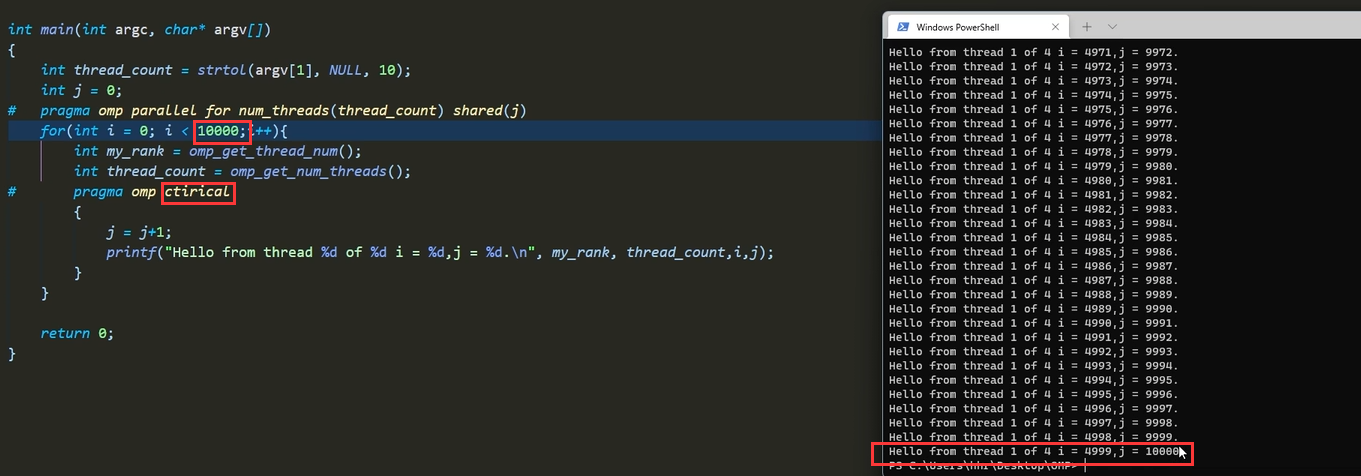
critical案例:图中打错了
automic原子操作

与critical的区别

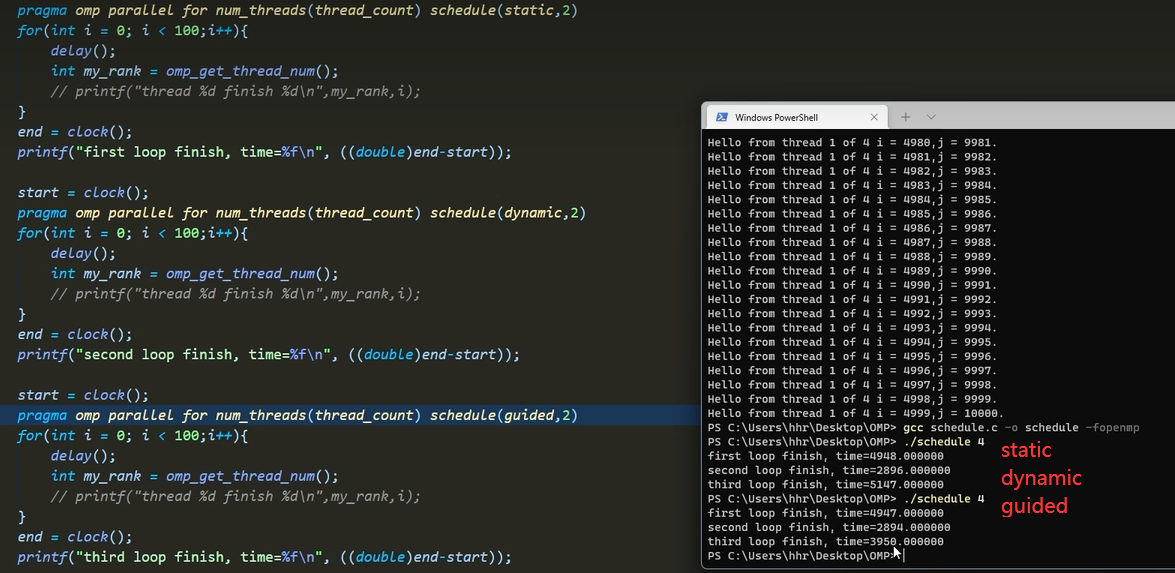
schedule调度
根据不同的for场景使用不同的策略
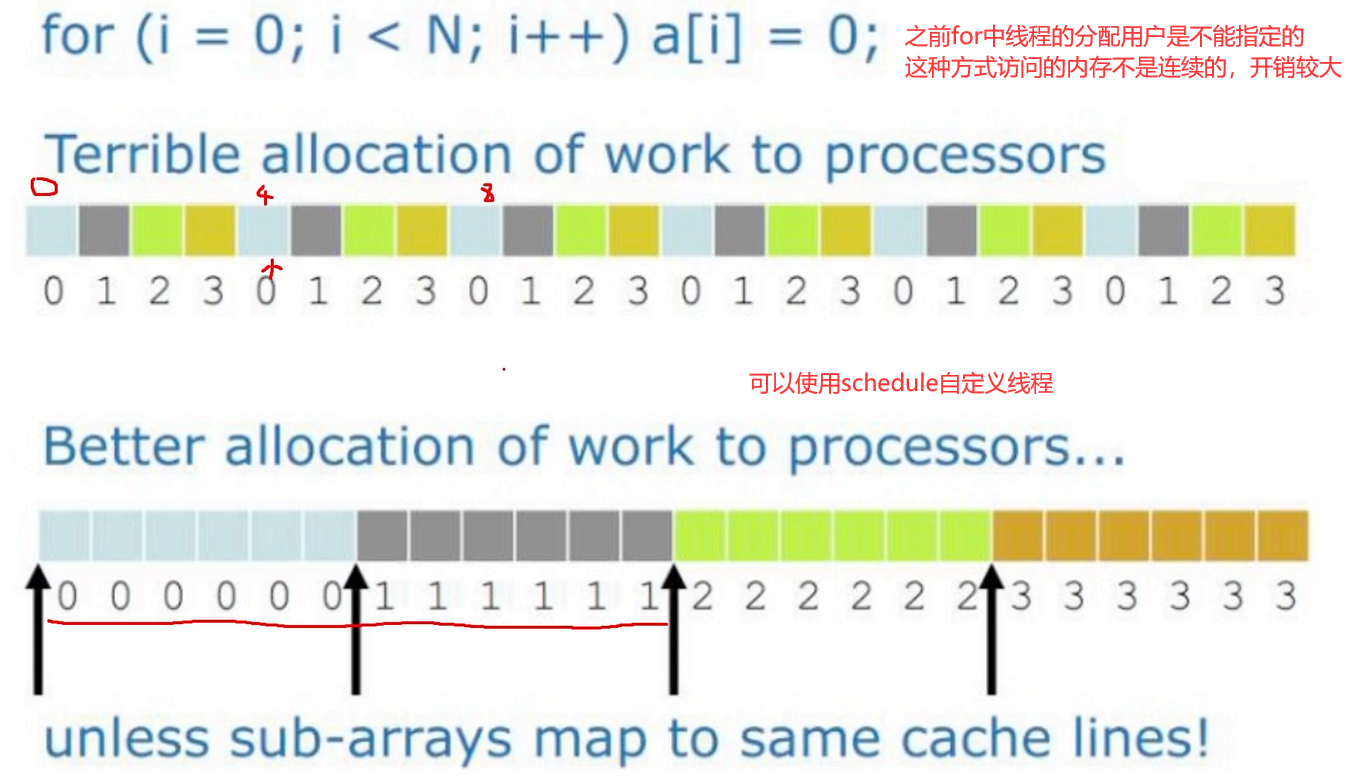
static
线程执行顺序—轮循:012301230123……

dynamic
线程每次质询一个块(chunk),谁执行的快,谁就可以优先抢占,如下图中 2号线程执行快,执行顺序为012321

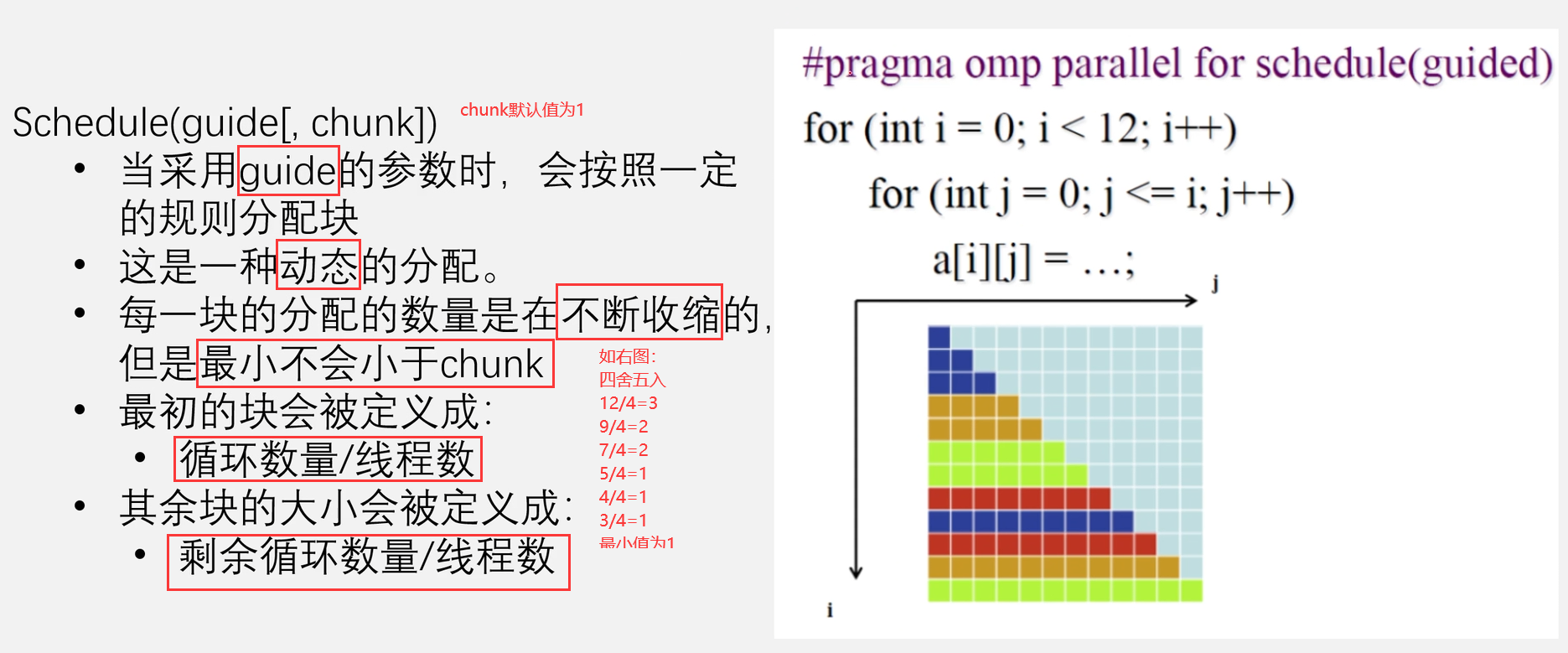
guided
开销与dynamic稍高,具体根据for的循环来确定使用哪种操作
对比
)]
static
线程执行顺序—轮循:012301230123……
[外链图片转存中…(img-AlOf1XVK-1696142420540)]
dynamic
线程每次质询一个块(chunk),谁执行的快,谁就可以优先抢占,如下图中 2号线程执行快,执行顺序为012321
[外链图片转存中…(img-bPy6Y9Om-1696142420540)]
guided
开销与dynamic稍高,具体根据for的循环来确定使用哪种操作
[外链图片转存中…(img-SsvBWOnw-1696142420542)]
对比







![2023年中国艺术涂料市场发展历程及趋势分析:艺术涂料市场规模将进一步扩大[图]](https://img-blog.csdnimg.cn/img_convert/7b336bd97d29839cd03849013ad0f6b2.png)