大语言模型的发展潜力已经毋庸置疑了,如何让中文大语言模型更适合中小公司使用这是一道难题。在模型的选择上我们倾向于选择国外的LLama或者BLoom之类的,而不是百川之类的中文大模型,原因在于从基建到框架到数据国外的开源资料非常多,比如Huggingface Transformer、微软的DeepSpeed、meta的LLama、Pytorch,Google的colab、TensorFlow、BERT,这些公司提供了大量开源的技术工具以及成果。
国外的人才密度高,引领着大语言的发展,所以从国外优秀的开源大语言模型入手是非常不错的途径,减小了学习成本,也减少了公司的使用成本。
但是国外主要是英语系为主,对中文支持不是特别理想,比如原版LLaMA模型的词表大小是32K,LLaMA词表中的中文token比较少(只有几百个,常用汉字都有三千个)。LLaMA 原生tokenizer词表中仅包含少量中文字符,在对中文字进行tokenzation时,一个中文汉字往往被切分成多个token(2-3个Token才能组合成一个汉字),显著降低编解码的效率。
我试过源码中文LLama的推理,效果差很多,但是从头训练又是个庞大的工程,预训练数据集动辄几个T,成本太高,所以在现有优秀的模型基础上扩充中文词汇以及中文训练集以更好支持中文场景是个不错的选择。值得一提的是多语言模型(如:XLM-R、Bloom)的词表大小约为250K,会有更多优秀的模型出现。
为了提升中文场景的效果,需要做如下2~3件事:
1.扩充中文词汇表,提高中文编码效率;在中文语料库上训练一个中文tokenizer模型,然后将中文 tokenizer 与 LLaMA 原生的 tokenizer 进行合并,通过组合它们的词汇表,最终获得一个合并后的 tokenizer 模型。
2.使用增加的中文预训练数据集(Chinese-LLaMA-Alpaca使用了120GB),对模型进行中文预训练;
3.加入SFT指令微调训练,以及RLHF训练
本偏博客用于扩充LLama 2 的中文词汇表。因为LLaMA tokenizer 是使用sentencepiece基于 BPE算法得到的,所以这里也使用BPE方法训练中文模型。没了解过SentencePiece可以先看《大语言模型之十 SentencePiece》
1.下载原版LLama-2模型
以7B为例
- 首先下载meta的原始模型,需要注册Huggingface账号
git lfs install
git clone https://huggingface.co/meta-llama/Llama-2-7b
- 使用Huggingface提供的转换脚本转换
python3 convert_llama_weights_to_hf.py --input_dir Llama-2-7b --model_size 7B --output_dir llama-2-7b-hf
其中convert_llama_weights_to_hf.py文件源于Huggingface的Transformer开源git库。
因为转换过程中使用到protobuffer
如果报错请按如下方式安装:
LlamaConverter requires the protobuf library but it was not found in your environment. Checkout the instructions on the
installation page of its repo: https://github.com/protocolbuffers/protobuf/tree/master/python#installation and follow the ones
that match your environment. Please note that you may need to restart your runtime after installation.
则需要按如下方式安装protobuffer
(venv) ➜ chinese_llama pip3 install --no-binary=protobuf protobuf
Collecting protobuf
Downloading protobuf-4.24.3.tar.gz (383 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 383.9/383.9 kB 232.4 kB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Installing collected packages: protobuf
成功转换时终端的输入如下信息:
Fetching all parameters from the checkpoint at Llama-2-7b.
Loading the checkpoint in a Llama model.
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████| 33/33 [00:10<00:00, 3.30it/s]
Saving in the Transformers format.
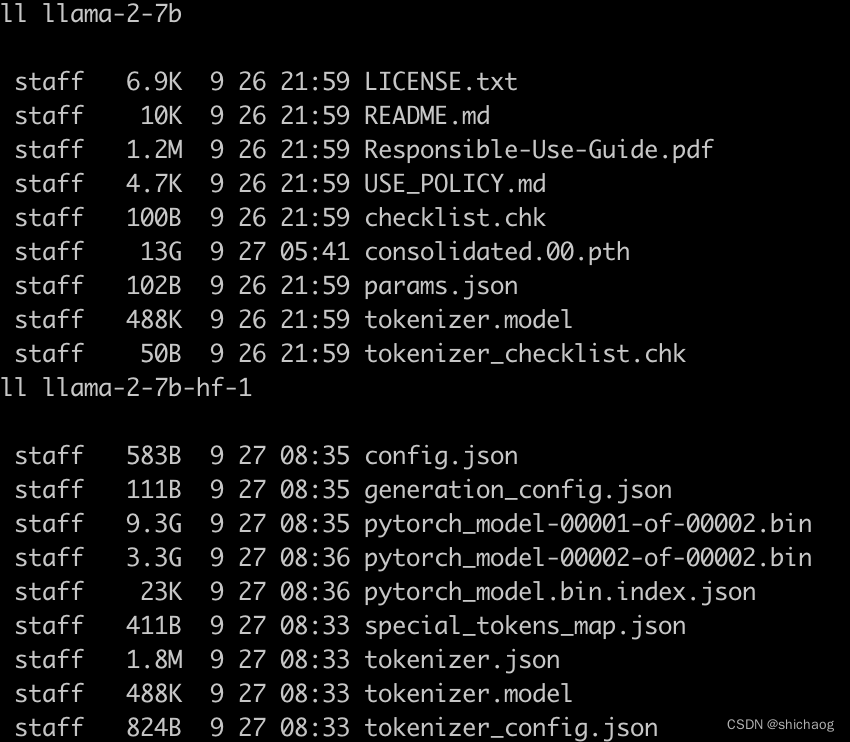
成功转换完毕后,两个文件夹的对比如下,
3.成功转换之后,可以使用Huggingface提供的Transformer库加载模型和tokenizer
from transformers import LlamaForCausalLM, LlamaTokenizer
tokenizer = LlamaTokenizer.from_pretrained("/output/path")
model = LlamaForCausalLM.from_pretrained("/output/path")
训练中文tokenizer
基于colab的过程见github代码中文词汇扩充
import sentencepiece as spm
# train sentencepiece model from `zhetian.txt` and makes `m.model` and `m.vocab`
# `m.vocab` is just a reference. not used in the segmentation.
spm.SentencePieceTrainer.train('--input=zhetian.txt --model_prefix=m --vocab_size=3439')
# makes segmenter instance and loads the model file (m.model)
sp = spm.SentencePieceProcessor()
sp.load('m.model')
# encode: text => id
print(sp.encode_as_pieces('叶凡经历九龙抬棺'))
print(sp.encode_as_ids('叶凡经历九龙抬棺'))
# decode: id => text
print(sp.decode_pieces(['▁', '叶', '凡', '经', '历', '九', '龙', '抬', '棺']))
print(sp.decode_ids([388, 359, 295, 606, 117]))
tokenizer 合并
## Add Chinese tokens to LLaMA tokenizer
llama_spm_tokens_set=set(p.piece for p in llama_spm.pieces)
print(len(llama_spm_tokens_set))
print(f"Before:{len(llama_spm_tokens_set)}")
for p in chinese_spm.pieces:
piece = p.piece
if piece not in llama_spm_tokens_set:
new_p = sp_pb2_model.ModelProto().SentencePiece()
new_p.piece = piece
new_p.score = 0
llama_spm.pieces.append(new_p)
print(f"New model pieces: {len(llama_spm.pieces)}")
32000
Before:32000
New model pieces: 34816
可以看到我这里多了2816个中文词。
保存和测试新的词汇表
## Save
output_sp_dir = 'merged_tokenizer_sp'
output_hf_dir = 'merged_tokenizer_hf' # the path to save Chinese-LLaMA tokenizer
os.makedirs(output_sp_dir,exist_ok=True)
with open(output_sp_dir+'/chinese_llama.model', 'wb') as f:
f.write(llama_spm.SerializeToString())
tokenizer = LlamaTokenizer(vocab_file=output_sp_dir+'/chinese_llama.model')
tokenizer.save_pretrained(output_hf_dir)
print(f"Chinese-LLaMA tokenizer has been saved to {output_hf_dir}")
# Test
llama_tokenizer = LlamaTokenizer.from_pretrained(model_id)
chinese_llama_tokenizer = LlamaTokenizer.from_pretrained(output_hf_dir)
print(tokenizer.all_special_tokens)
print(tokenizer.all_special_ids)
print(tokenizer.special_tokens_map)
text='''叶凡独自一人来到山前。
The primary use of LLaMA is research on large language models, including'''
print("Test text:\n",text)
print(f"Tokenized by LLaMA tokenizer:{llama_tokenizer.tokenize(text)}")
print(f"Tokenized by Chinese-LLaMA tokenizer:{chinese_llama_tokenizer.tokenize(text)}")
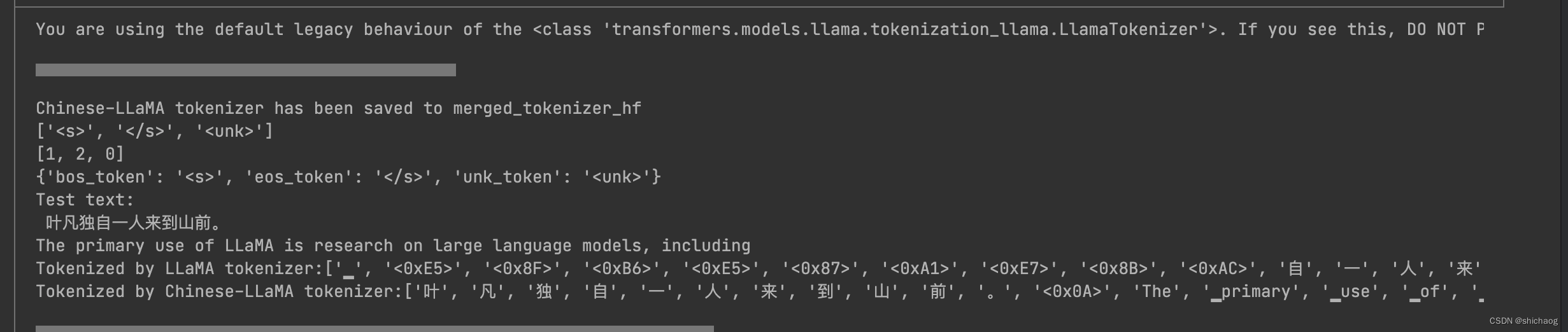 可以看到中文词汇变多了。
可以看到中文词汇变多了。
至此中文词汇表就扩充完毕了,但是扩充的词汇表多了,那么Embedding也就会相应的增加,从头训练有点得不偿失。每个token都对应于《大语言模型之四-LlaMA-2从模型到应用》博客中图3 LLama-2 图例过程中4096的Embedding矩阵,在重新预训练的时候,可以将对应的token锁定,没有的token随机赋予一个4096的向量,这样组合参与训练,会使得训练的过程更为高效。
后文将继续就国内Chinese-LLaMA-Alpaca开源项目详细说明模型预训练和模型指令精调的整个过程。