深度学习——模型选择、欠拟合和过拟合
文章目录
- 前言
- 一、训练误差和泛化误差
- 1.1. 统计学习理论
- 1.2. 模型复杂性
- 二、模型选择
- 2.1. 验证集
- 2.2. K折交叉验证
- 三、欠拟合 or 过拟合
- 3.1. 模型复杂性
- 3.2. 数据集大小
- 四、多项式回归
- 4.1. 生成数据集
- 4.2. 对模型进行训练和测试
- 4.3. 三阶多项式函数拟合(正常)
- 4.4. 线性函数拟合(欠拟合)
- 4.5. 高阶多项式函数拟合(过拟合)
- 总结
前言
前面对多层感知机进行了一定的了解,我们知道随着隐藏层的增多虽然多层感知机的表示能力会增强,但模型的复杂度也会增加,容易导致过拟合。而本章将对模型选择、欠拟合和过拟合问题进行探讨。
机器学习的目标是发现模式(pattern)。 但是,我们如何才能确定模型是真正发现了一种泛化的模式, 而不是简单地记住了数据?
一、训练误差和泛化误差
将模型在训练数据上拟合的比在潜在分布中更接近的现象称为过拟合(overfitting),
用于对抗过拟合的技术称为正则化(regularization)
训练误差(training error)是指, 模型在训练数据集上计算得到的误差。 泛化误差(generalization error)是指, 模型应用在同样从原始样本的分布中抽取的无限多数据样本时,模型误差的期望。
1.1. 统计学习理论
在监督学习情景中, 我们假设训练数据和测试数据都是从相同的分布中独立提取的(即训练数据和测试数据是相互独立且具有相同的特征分布)。 这通常被称为独立同分布假设, 这意味着对数据进行采样的过程没有进行“记忆”。
换句话说,抽取的第2个样本和第3个样本的相关性, 并不比抽取的第2个样本和第200万个样本的相关性更强。
有时候我们即使轻微违背独立同分布假设,模型仍将继续运行得非常好。 比如,我们有许多有用的工具已经应用于现实,如人脸识别、语音识别和语言翻译。 毕竟,几乎所有现实的应用都至少涉及到一些违背独立同分布假设的情况.
有些违背独立同分布假设的行为肯定会带来麻烦。 比如,我们试图只用来自大学生的人脸数据来训练一个人脸识别系统, 然后想要用它来监测疗养院中的老人。 这不太可能有效,因为大学生看起来往往与老年人有很大的不同。(即他们的人脸数据具有不同的特征分布)
1.2. 模型复杂性
当我们有简单的模型和大量的数据时,我们期望泛化误差与训练误差相近。 当我们有更复杂的模型和更少的样本时,我们预计训练误差会下降,但泛化误差会增大。 模型复杂性由什么构成是一个复杂的问题。 一个模型是否能很好地泛化取决于很多因素。
几个倾向于影响模型泛化的因素:
- 可调整参数的数量:当可调整参数的数量(有时称为自由度)很大时,模型往往更容易过拟合。
- 参数采用的值。当权重的取值范围较大时,模型可能更容易过拟合。
- 训练样本的数量:即使模型很简单,也很容易过拟合只包含一两个样本的数据集:而过拟合一个有数百万个样本的数据集则需要一个极其灵活的模型。
二、模型选择
在机器学习中,我们通常在评估几个候选模型后选择最终的模型。 这个过程叫做模型选择。
为了确定候选模型中的最佳模型,我们通常会使用验证集。
-
有时,需要进行比较的模型在本质上是完全不同的(比如,决策树与线性模型)。
-
又有时,我们需要比较不同的超参数设置下的同一类模型。
例如,训练多层感知机模型时,比较具有不同数量的隐藏层、不同数量的隐藏单元以及不同的激活函数组合的模型。
2.1. 验证集
原则上,在我们确定所有的超参数之前,我们不希望用到测试集。
如果我们在模型选择过程中使用测试数据,可能会有过拟合测试数据的风险
因此,我们决不能依靠测试数据进行模型选择。 然而,我们也不能仅仅依靠训练数据来选择模型,因为我们无法估计训练数据的泛化误差。
虽然理想情况下我们只会使用测试数据一次, 以评估最好的模型或比较一些模型效果,但现实是测试数据很少在使用一次后被丢弃。 我们很少能有充足的数据来对每一轮实验采用全新测试集。
解决此问题的常见做法是将我们的数据分成三份, 除了训练和测试数据集之外,还增加一个验证数据集, 也叫验证集。
但现实是验证数据和测试数据之间的边界模糊得令人担忧
2.2. K折交叉验证
当训练数据稀缺时,我们甚至可能无法提供足够的数据来构成一个合适的验证集。 这个问题的一个流行的解决方案是采用K折交叉验证。
这里,原始训练数据被分成K个不重叠的子集。 然后执行K次模型训练和验证,每次在K−1个子集上进行训练, 并在剩余的一个子集(在该轮中没有用于训练的子集)上进行验证。 最后,通过对K次实验的结果取平均来估计训练和验证误差。
传统机器学习算法中运用网格搜索与交叉验证中就用到了K折交叉验证。
三、欠拟合 or 过拟合
过拟合并不总是一件坏事。 特别是在深度学习领域,众所周知, 最好的预测模型在训练数据上的表现往往比在保留(验证)数据上好得多。 最终,我们通常更关心验证误差,而不是训练误差和验证误差之间的差距
3.1. 模型复杂性
以一个多项式为例
高阶多项式函数比低阶多项式函数复杂得多。 高阶多项式的参数较多,模型函数的选择范围较广。 因此在固定训练数据集的情况下, 高阶多项式函数相对于低阶多项式的训练误差应该始终更低(最坏也是相等)
3.2. 数据集大小
训练数据集中的样本越少,我们就越有可能(且更严重地)过拟合。 随着训练数据量的增加,泛化误差通常会减小。 此外,一般来说,更多的数据不会有什么坏处。
对于许多任务,深度学习只有在有数千个训练样本时才优于线性模型。
四、多项式回归
4.1. 生成数据集
给定 x x x,我们将使用以下三阶多项式来生成训练和测试数据的标签:
y = 5 + 1.2 x − 3.4 x 2 2 ! + 5.6 x 3 3 ! + ϵ where ϵ ∼ N ( 0 , 0. 1 2 ) . y = 5 + 1.2x - 3.4\frac{x^2}{2!} + 5.6 \frac{x^3}{3!} + \epsilon \text{ where } \epsilon \sim \mathcal{N}(0, 0.1^2). y=5+1.2x−3.42!x2+5.63!x3+ϵ where ϵ∼N(0,0.12).
在优化的过程中,我们通常希望避免非常大的梯度值或损失值。这就是我们将特征从
x
i
x^i
xi调整为
x
i
i
!
\frac{x^i}{i!}
i!xi的原因,
这样可以避免很大的
i
i
i带来的特别大的指数值。
import math
import numpy as np
import torch
from torch import nn
from d2l import torch as d2l
##1. 生成数据集
max_degree = 20 #多项式的最大阶数
n_train ,n_test = 100,100 #训练和测试数据集大小
true_w = np.zeros(max_degree) #存储多项式回归的真实权重
true_w[0:4] = np.array([5,1.2,-3.4,5.6]) #权重
features = np.random.normal(size= (n_test+n_test,1)) #生成特征矩阵
np.random.shuffle(features)
poly_features = np.power(features,np.arange(max_degree).reshape(1,-1))
for i in range(max_degree):
poly_features[:, i] /= math.gamma(i + 1) # gamma(n)=(n-1)!
# labels的维度:(n_train+n_test,)
labels = np.dot(poly_features, true_w)
labels += np.random.normal(scale=0.1, size=labels.shape)
# NumPy ndarray转换为tensor
true_w,features ,poly_features,labels = [torch.tensor(x,dtype=torch.float32) for x in [true_w,features,poly_features,labels]]
#print(features[:2],poly_features[:2,:],labels[:2])
4.2. 对模型进行训练和测试
#对模型进行测试
def evaluate_loss(net,data_iter,loss): #@save
"""评估给定数据集上模型的损失"""
metric = d2l.Accumulator(2) # 损失的总和,样本数量
for X, y in data_iter:
out = net(X)
y = y.reshape(out.shape)
l = loss(out, y)
metric.add(l.sum(), l.numel())
return metric[0] / metric[1]
#定义训练函数
def train(train_features, test_features, train_labels, test_labels,
num_epochs=400):
loss = nn.MSELoss(reduction='none')
input_shape = train_features.shape[-1]
# 不设置偏置,因为我们已经在多项式中实现了它
net = nn.Sequential(nn.Linear(input_shape, 1, bias=False))
batch_size = min(10, train_labels.shape[0])
train_iter = d2l.load_array((train_features, train_labels.reshape(-1,1)),
batch_size)
test_iter = d2l.load_array((test_features, test_labels.reshape(-1,1)),
batch_size, is_train=False)
trainer = torch.optim.SGD(net.parameters(), lr=0.01)
animator = d2l.Animator(xlabel='epoch', ylabel='loss', yscale='log',
xlim=[1, num_epochs], ylim=[1e-3, 1e2],
legend=['train', 'test'])
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
if epoch == 0 or (epoch + 1) % 20 == 0:
animator.add(epoch + 1, (evaluate_loss(net, train_iter, loss),
evaluate_loss(net, test_iter, loss)))
print('weight:', net[0].weight.data.numpy())
4.3. 三阶多项式函数拟合(正常)
# 从多项式特征中选择前4个维度,即1,x,x^2/2!,x^3/3!
train(poly_features[:n_train, :4], poly_features[n_train:, :4],
labels[:n_train], labels[n_train:])
#结果:
weight: [[ 5.001957 1.2103279 -3.3940623 5.612016 ]]
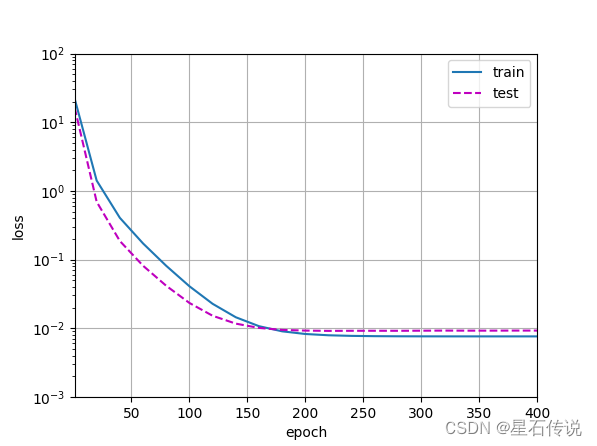
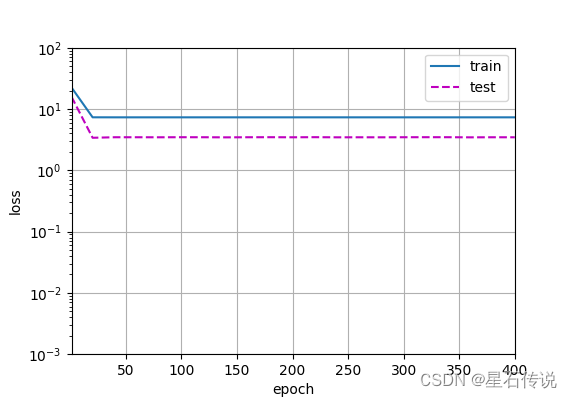
4.4. 线性函数拟合(欠拟合)
# 从多项式特征中选择前2个维度,即1和x
train(poly_features[:n_train, :2], poly_features[n_train:, :2],
labels[:n_train], labels[n_train:])
#结果:
weight: [[3.6474984 3.5916603]]
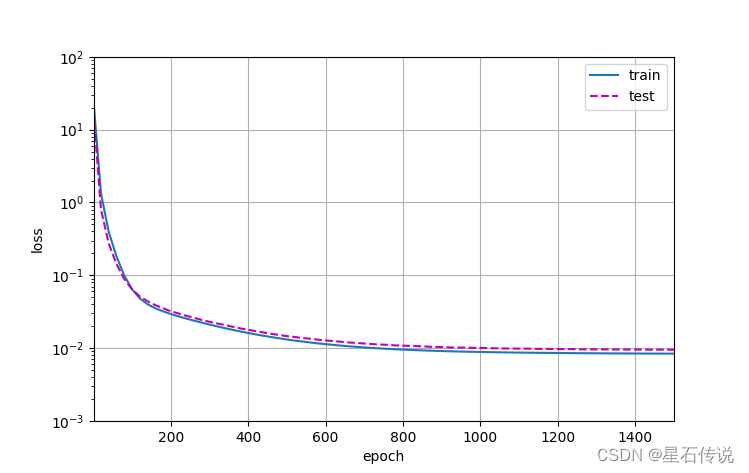
4.5. 高阶多项式函数拟合(过拟合)
# 从多项式特征中选取所有维度
train(poly_features[:n_train, :], poly_features[n_train:, :],
labels[:n_train], labels[n_train:], num_epochs=1500)
#结果:
weight: [[ 5.0018353 1.3056387 -3.40714 5.0540347 0.05627811 1.4985588
-0.01145003 0.13559504 0.08288393 -0.18558608 -0.137055 -0.1332902
0.06292755 -0.13735987 0.02380645 -0.22054781 0.04794919 0.19363585
-0.10306321 -0.11154444]]
总结
本章对模型选择的问题进行了一定的了解,知道了验证集的概念。并且以多项式回归问题为例探讨了欠拟合和过拟合的区别。
故贵以身为天下,若可寄天下;爱以身为天下,若可托天下。
–2023-9-29 进阶篇