Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs
26、Flink 的SQL之概览与入门示例
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1)
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2)
27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3)
27、Flink 的SQL之SELECT (窗口聚合)介绍及详细示例(4)
27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(5)
27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介绍及详细示例(6)
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
41、Flink之Hive 方言介绍及详细示例
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例–网上有些说法好像是错误的
文章目录
- Flink 系列文章
- 一、模式检测
- 1、介绍及示例
- 1)、介绍
- 2)、示例
- 2、分区
- 3、事件顺序
- 4、Define & Measures
- 1)、Aggregations
- 2)、示例
- 5、定义模式
- 1)、贪婪量词和勉强量词
- 2)、时间约束
- 6、输出方式
- 7、模式导航
- 1)、引用模式变量
- 2)、Logical Offsets
- 8、匹配后的策略
- 1)、环境/数据准备
- 2)、AFTER MATCH SKIP PAST LAST ROW示例
- 3)、AFTER MATCH SKIP TO NEXT ROW示例
- 4)、AFTER MATCH SKIP TO LAST variable 示例
- 5)、AFTER MATCH SKIP TO FIRST variable 示例
- 9、时间属性
- 10、控制内存消耗
- 11、已知的局限
本文介绍了Flink 的模式检测,以及每个可运行的示例、运行结果的图示分析。
本文依赖flink和hadoop集群能正常使用。
本文通过模式检测的语法,根据语法逐个介绍了其用法以及详细的示例,同时也列出了其局限性。
一、模式检测
搜索一组事件模式(event pattern)是一种常见的用例,尤其是在数据流情景中。Flink 提供复杂事件处理(CEP)库,该库允许在事件流中进行模式检测。此外,Flink 的 SQL API 提供了一种关系式的查询表达方式,其中包含大量内置函数和基于规则的优化,可以开箱即用。
2016 年 12 月,国际标准化组织(ISO)发布了新版本的 SQL 标准,其中包括在 SQL 中的行模式识别(Row Pattern Recognition in SQL)(ISO/IEC TR 19075-5:2016)。它允许 Flink 使用 MATCH_RECOGNIZE 子句融合 CEP 和 SQL API,以便在 SQL 中进行复杂事件处理。
MATCH_RECOGNIZE 子句启用以下任务:
- 使用 PARTITION BY 和 ORDER BY 子句对数据进行逻辑分区和排序。
- 使用 PATTERN 子句定义要查找的行模式。这些模式使用类似于正则表达式的语法。
- 在 DEFINE 子句中指定行模式变量的逻辑组合。
- measures 是指在 MEASURES 子句中定义的表达式,这些表达式可用于 SQL 查询中的其他部分。
下面的示例演示了基本模式识别的语法:
SELECT T.aid, T.bid, T.cid
FROM MyTable
MATCH_RECOGNIZE (
PARTITION BY userid
ORDER BY proctime
MEASURES
A.id AS aid,
B.id AS bid,
C.id AS cid
PATTERN (A B C)
DEFINE
A AS name = 'a',
B AS name = 'b',
C AS name = 'c'
) AS T
本文将更详细地解释每个关键字,并演示说明更复杂的示例。
Flink 的 MATCH_RECOGNIZE 子句实现是一个完整标准子集。仅支持以下部分中记录的功能。
1、介绍及示例
1)、介绍
模式识别特性使用 Apache Flink 内部的 CEP 库。为了能够使用 MATCH_RECOGNIZE 子句,需要将库作为依赖项添加到 Maven 项目中。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep</artifactId>
<version>1.17.1</version>
</dependency>
如果你想在 SQL Client 中使用 MATCH_RECOGNIZE 子句,你无需执行任何操作,因为默认情况下包含所有依赖项。
每个 MATCH_RECOGNIZE 查询都包含以下子句:
- PARTITION BY - 定义表的逻辑分区;类似于 GROUP BY 操作。
- ORDER BY - 指定传入行的排序方式;这是必须的,因为模式依赖于顺序。
- MEASURES - 定义子句的输出;类似于 SELECT 子句。
- ONE ROW PER MATCH - 输出方式,定义每个匹配项应产生多少行。
- AFTER MATCH SKIP - 指定下一个匹配的开始位置;这也是控制单个事件可以属于多少个不同匹配项的方法。
- PATTERN - 允许使用类似于 正则表达式 的语法构造搜索的模式。
- DEFINE - 本部分定义了模式变量必须满足的条件。
截至版本Flink 1.17,MATCH_RECOGNIZE 子句只能应用于追加表。此外,它也总是生成一个追加表
2)、示例
查找ticker2表中的‘a’记录不断降低的时间,查询从何时开始降低、何时最低以及何时开始增长。
---- 1、建表
CREATE TABLE alan_ticker (
symbol STRING,
price DOUBLE,
tax DOUBLE,
rowtime TIMESTAMP(3),
WATERMARK FOR rowtime AS rowtime - INTERVAL '1' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'alan_ticker_topic',
'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
);
Flink SQL> desc alan_ticker;
+---------+------------------------+------+-----+--------+---------------------------------+
| name | type | null | key | extras | watermark |
+---------+------------------------+------+-----+--------+---------------------------------+
| symbol | STRING | TRUE | | | |
| price | DOUBLE | TRUE | | | |
| tax | DOUBLE | TRUE | | | |
| rowtime | TIMESTAMP(3) *ROWTIME* | TRUE | | | `rowtime` - INTERVAL '1' SECOND |
+---------+------------------------+------+-----+--------+---------------------------------+
---- 2、查询数据
Flink SQL> select * from alan_ticker;
+----+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| op | symbol | price | tax | rowtime |
+----+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| +I | alan | 12.0 | 1.0 | 2023-09-25 13:16:01.000 |
| +I | alan | 17.0 | 2.0 | 2023-09-25 13:16:02.000 |
| +I | alan | 19.0 | 1.0 | 2023-09-25 13:16:03.000 |
| +I | alan | 21.0 | 3.0 | 2023-09-25 13:16:04.000 |
| +I | alan | 25.0 | 2.0 | 2023-09-25 13:16:05.000 |
| +I | alan | 18.0 | 1.0 | 2023-09-25 13:16:06.000 |
| +I | alan | 15.0 | 1.0 | 2023-09-25 13:16:07.000 |
| +I | alan | 14.0 | 2.0 | 2023-09-25 13:16:08.000 |
| +I | alan | 24.0 | 2.0 | 2023-09-25 13:16:09.000 |
| +I | alan | 25.0 | 2.0 | 2023-09-25 13:16:10.000 |
| +I | alan | 19.0 | 1.0 | 2023-09-25 13:16:11.000 |
---- 3、模式检测示例
# 此查询将 alan_ticker 表按照 symbol 列进行分区并按照 rowtime 属性进行排序
# PATTERN 子句指定我们对以下模式感兴趣:该模式具有开始事件 START_ROW,然后是一个或多个 PRICE_DOWN 事件,并以 PRICE_UP 事件结束。如果可以找到这样的模式,如 AFTER MATCH SKIP TO LAST 子句所示,则从最后一个 PRICE_UP 事件开始寻找下一个模式匹配。
# DEFINE 子句指定 PRICE_DOWN 和 PRICE_UP 事件需要满足的条件。尽管不存在 START_ROW 模式变量,但它具有一个始终被评估为 TRUE 隐式条件
# 模式变量 PRICE_DOWN 定义为价格小于满足 PRICE_DOWN 条件的最后一行。对于初始情况或没有满足 PRICE_DOWN 条件的最后一行时,该行的价格应小于该模式中前一行(由 START_ROW 引用)的价格。
# 模式变量 PRICE_UP 定义为价格大于满足 PRICE_DOWN 条件的最后一行
# 在查询的 MEASURES 子句部分定义确切的输出行信息。输出行数由 ONE ROW PER MATCH 输出方式定义
Flink SQL> SELECT *
> FROM alan_ticker
> MATCH_RECOGNIZE (
> PARTITION BY symbol -- 按照 symbol 列进行分区并按照 rowtime 属性进行排序
> ORDER BY rowtime
> MEASURES
> START_ROW.rowtime AS start_tstamp,
> LAST(PRICE_DOWN.rowtime) AS bottom_tstamp,
> LAST(PRICE_UP.rowtime) AS end_tstamp
> ONE ROW PER MATCH -- 输出行数由 ONE ROW PER MATCH 输出方式定义
> AFTER MATCH SKIP TO LAST PRICE_UP --如果找到完全匹配后从最后一个PRICE_UP 事件开始寻找下一个模式匹配
> --指定模式,有开始事件START_ROW,然后是一个或多个PRICE_DOWN 事件,并以 PRICE_UP 事件结束
> --定义了模式变量PRICE_DOWN、PRICE_UP 必须满足的条件
> --不存在 START_ROW 模式变量,它具有一个始终被评估为 TRUE 隐式条件。
> --任意行都可以是 START_ROW
> PATTERN (START_ROW PRICE_DOWN+ PRICE_UP)
> DEFINE
> -- 模式变量 PRICE_DOWN 定义
> -- 对于初始情况或没有满足 PRICE_DOWN 条件的最后一行时,该行的价格应小于该模式中前一行(由 START_ROW 引用)的价格。
> -- 价格小于满足 PRICE_DOWN 条件的最后一行
> PRICE_DOWN AS (LAST(PRICE_DOWN.price, 1) IS NULL AND PRICE_DOWN.price < START_ROW.price) OR PRICE_DOWN.price < LAST(PRICE_DOWN.price, 1),
> --模式变量 PRICE_UP 定义
> --价格大于满足 PRICE_DOWN 条件的最后一行
> PRICE_UP AS PRICE_UP.price > LAST(PRICE_DOWN.price, 1)
> ) MR;
+----+--------------------------------+-------------------------+-------------------------+-------------------------+
| op | symbol | start_tstamp | bottom_tstamp | end_tstamp |
+----+--------------------------------+-------------------------+-------------------------+-------------------------+
| +I | alan | 2023-09-25 13:16:05.000 | 2023-09-25 13:16:08.000 | 2023-09-25 13:16:09.000 |
# 该行结果描述了从 2023-09-25 13:16:05 开始的降低,在 2023-09-25 13:16:08 达到最低,到 2023-09-25 13:16:09 再次上涨
2、分区
可以在分区数据中寻找模式,例如单个股票行情或特定用户的趋势。这可以用 PARTITION BY 子句来表示。该子句类似于对 aggregation 使用 GROUP BY。
强烈建议对传入的数据进行分区,否则 MATCH_RECOGNIZE 子句将被转换为非并行算子,以确保全局排序
3、事件顺序
Apache Flink 可以根据时间(处理时间或者事件时间)进行模式搜索。
如果是事件时间,则在将事件传递到内部模式状态机之前对其进行排序。所以,无论行添加到表的顺序如何,生成的输出都是正确的。而模式是按照每行中所包含的时间指定顺序计算的。
MATCH_RECOGNIZE 子句假定升序的 时间属性 是 ORDER BY 子句的第一个参数。
对于示例 alan_ticker 表,诸如 ORDER BY rowtime ASC, price DESC 的定义是有效的,但 ORDER BY price, rowtime 或者 ORDER BY rowtime DESC, price ASC 是无效的。
4、Define & Measures
DEFINE 和 MEASURES 关键字与简单 SQL 查询中的 WHERE 和 SELECT 子句具有相近的含义。
MEASURES 子句定义匹配模式的输出中要包含哪些内容。它可以投影列并定义表达式进行计算。产生的行数取决于输出方式设置。
DEFINE 子句指定行必须满足的条件才能被分类到相应的模式变量。如果没有为模式变量定义条件,则将对每一行使用计算结果为 true 的默认条件。
有关在这些子句中可使用的表达式的更详细的说明,请查看事件流导航部分。
1)、Aggregations
Aggregations 可以在 DEFINE 和 MEASURES 子句中使用。支持内置函数和用户自定义函数。
对相应匹配项的行子集可以使用 Aggregate functions。请查看事件流导航部分以了解如何计算这些子集。
下面这个示例的任务是找出股票平均价格没有低于某个阈值的最长时间段。它展示了 MATCH_RECOGNIZE 在 aggregation 中的可表达性。可以使用以下查询执行此任务:
2)、示例
下面这个示例的任务是找出股票平均价格没有低于某个阈值的最长时间段。它展示了 MATCH_RECOGNIZE 在 aggregation 中的可表达性。可以使用以下查询执行此任务:
----1、建表
# 使用上述示例的表 alan_ticker
----2、查询表数据
# 使用上述示例的表 alan_ticker 及其数据
Flink SQL> select * from alan_ticker;
+----+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| op | symbol | price | tax | rowtime |
+----+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| +I | alan | 12.0 | 1.0 | 2023-09-25 13:16:01.000 |
| +I | alan | 17.0 | 2.0 | 2023-09-25 13:16:02.000 |
| +I | alan | 19.0 | 1.0 | 2023-09-25 13:16:03.000 |
| +I | alan | 21.0 | 3.0 | 2023-09-25 13:16:04.000 |
| +I | alan | 25.0 | 2.0 | 2023-09-25 13:16:05.000 |
| +I | alan | 18.0 | 1.0 | 2023-09-25 13:16:06.000 |
| +I | alan | 15.0 | 1.0 | 2023-09-25 13:16:07.000 |
| +I | alan | 14.0 | 2.0 | 2023-09-25 13:16:08.000 |
| +I | alan | 24.0 | 2.0 | 2023-09-25 13:16:09.000 |
| +I | alan | 25.0 | 2.0 | 2023-09-25 13:16:10.000 |
| +I | alan | 19.0 | 1.0 | 2023-09-25 13:16:11.000 |
----3、聚合验证
# 只要事件的平均价格不超过 18,查询就会将事件作为模式变量 A 的一部分进行累积。
# 例如,这种限制发生在 2023-09-25 13:16:05。接下来的时间段在 2023-09-25 13:16:10 再次超过平均价格 18
# 因此,所述查询的结果将是:
Flink SQL> SELECT *
> FROM alan_ticker
> MATCH_RECOGNIZE (
> PARTITION BY symbol
> ORDER BY rowtime
> MEASURES
> FIRST(A.rowtime) AS start_tstamp,
> LAST(A.rowtime) AS end_tstamp,
> AVG(A.price) AS avgPrice
> ONE ROW PER MATCH
> AFTER MATCH SKIP PAST LAST ROW
> PATTERN (A+ B)
> DEFINE
> A AS AVG(A.price) < 18
> ) MR;
+----+--------------------------------+-------------------------+-------------------------+--------------------------------+
| op | symbol | start_tstamp | end_tstamp | avgPrice |
+----+--------------------------------+-------------------------+-------------------------+--------------------------------+
| +I | alan | 2023-09-25 13:16:01.000 | 2023-09-25 13:16:04.000 | 17.25 |
| +I | alan | 2023-09-25 13:16:07.000 | 2023-09-25 13:16:09.000 | 17.666666666666668 |
Aggregation 可以应用于表达式,但前提是它们引用单个模式变量。因此,SUM(A.price * A.tax) 是有效的,而
AVG(A.price * B.tax) 则是无效的。
不支持 DISTINCT aggregation。
5、定义模式
MATCH_RECOGNIZE 子句允许用户在事件流中使用功能强大、表达力强的语法搜索模式,这种语法与广泛使用的正则表达式语法有些相似。
每个模式都是由基本的构建块构造的,称为 模式变量,可以应用算子(量词和其他修饰符)到这些模块中。整个模式必须用括号括起来。
示例模式如下所示:
PATTERN (A B+ C* D)
-- 开始行复合A模式
-- 然后是1或者多行B模式事件
-- 接着是0或者多行C模式事件
-- 以D模式行结束
可以使用以下算子:
1、Concatenation - 像 (A B) 这样的模式意味着 A 和 B 之间的连接是严格的。因此,在它们之间不能存在没有映射到 A 或 B 的行。
2、Quantifiers - 修改可以映射到模式变量的行数。
- ‘*’ — 0 或者多行
- ‘+’ — 1 或者多行
- ? — 0 或者 1 行
- { n } — 严格 n 行(n > 0)
- { n, } — n 或者更多行(n ≥ 0)
- { n, m } — 在 n 到 m(含)行之间(0 ≤ n ≤ m,0 < m)
- { , m } — 在 0 到 m(含)行之间(m > 0)
不支持可能产生空匹配的模式。此类模式的示例如 PATTERN (A*),PATTERN (A? B*),PATTERN (A{0,} B{0,} C*) 等
1)、贪婪量词和勉强量词
每一个量词可以是 贪婪(默认行为)的或者 勉强 的。贪婪的量词尝试匹配尽可能多的行,而勉强的量词则尝试匹配尽可能少的行。
为了说明区别,可以通过查询查看以下示例,其中贪婪量词应用于 B 变量:
----1、建表
# 使用上述示例的表 alan_ticker
----2、查询表数据
# 使用上述示例的表 alan_ticker 及其数据
Flink SQL> select * from alan_ticker;
+----+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| op | symbol | price | tax | rowtime |
+----+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| +I | alan | 12.0 | 1.0 | 2023-09-25 13:16:01.000 |
| +I | alan | 17.0 | 2.0 | 2023-09-25 13:16:02.000 |
| +I | alan | 19.0 | 1.0 | 2023-09-25 13:16:03.000 |
| +I | alan | 21.0 | 3.0 | 2023-09-25 13:16:04.000 |
| +I | alan | 25.0 | 2.0 | 2023-09-25 13:16:05.000 |
| +I | alan | 18.0 | 1.0 | 2023-09-25 13:16:06.000 |
| +I | alan | 15.0 | 1.0 | 2023-09-25 13:16:07.000 |
| +I | alan | 14.0 | 2.0 | 2023-09-25 13:16:08.000 |
| +I | alan | 24.0 | 2.0 | 2023-09-25 13:16:09.000 |
| +I | alan | 25.0 | 2.0 | 2023-09-25 13:16:10.000 |
| +I | alan | 19.0 | 1.0 | 2023-09-25 13:16:11.000 |
----3、贪婪量词(B*)示例
Flink SQL> SELECT *
> FROM alan_ticker
> MATCH_RECOGNIZE(
> PARTITION BY symbol
> ORDER BY rowtime
> MEASURES
> C.price AS lastPrice,
> C.rowtime AS rowtime
> ONE ROW PER MATCH
> AFTER MATCH SKIP PAST LAST ROW --从最后一个 C 事件开始寻找下一个模式匹配
> PATTERN (A B* C) -- 贪婪量词应用于 B
> DEFINE
> A AS A.price > 12,
> B AS B.price < 25,
> C AS C.price > 18
> );
+----+--------------------------------+--------------------------------+-------------------------+
| op | symbol | lastPrice | rowtime |
+----+--------------------------------+--------------------------------+-------------------------+
| +I | alan | 25.0 | 2023-09-25 13:16:05.000 |
| +I | alan | 25.0 | 2023-09-25 13:16:10.000 |
----4、勉强量词(B*?)示例
Flink SQL> SELECT *
> FROM alan_ticker
> MATCH_RECOGNIZE(
> PARTITION BY symbol
> ORDER BY rowtime
> MEASURES
> C.price AS lastPrice,
> C.rowtime AS rowtime
> ONE ROW PER MATCH
> AFTER MATCH SKIP PAST LAST ROW
> PATTERN (A B*? C)
> DEFINE
> A AS A.price > 12,
> B AS B.price < 25,
> C AS C.price > 18
> );
+----+--------------------------------+--------------------------------+-------------------------+
| op | symbol | lastPrice | rowtime |
+----+--------------------------------+--------------------------------+-------------------------+
| +I | alan | 19.0 | 2023-09-25 13:16:03.000 |
| +I | alan | 25.0 | 2023-09-25 13:16:05.000 |
| +I | alan | 24.0 | 2023-09-25 13:16:09.000 |
- 匹配模式 A B* C
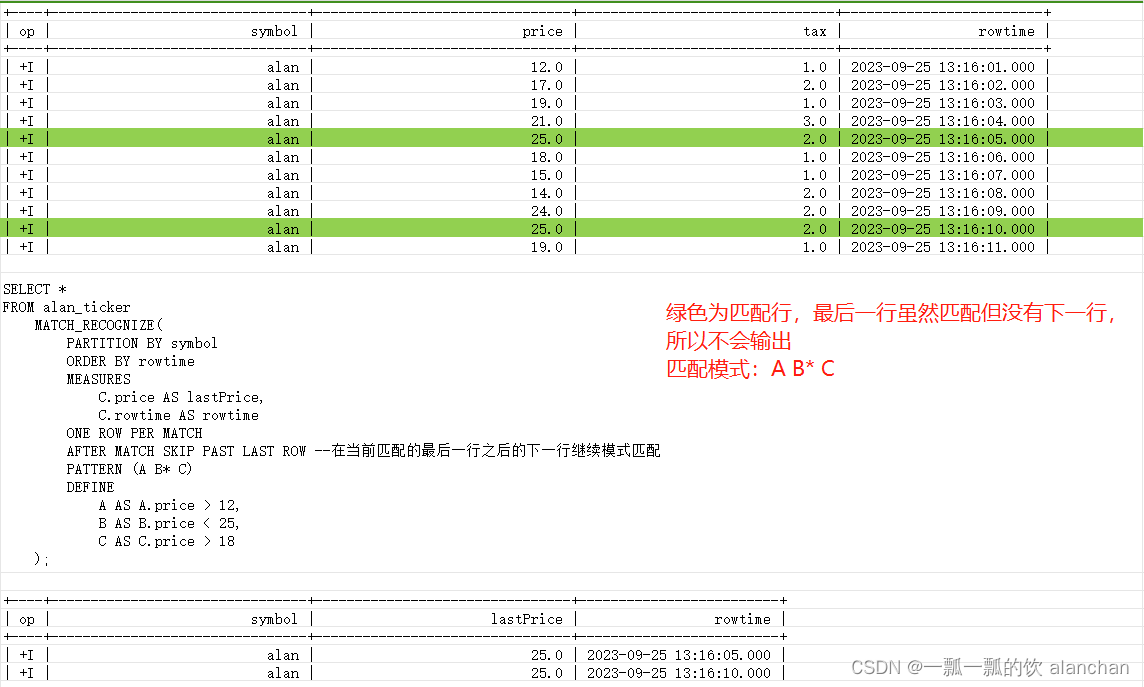
- 匹配模式 A B*? C
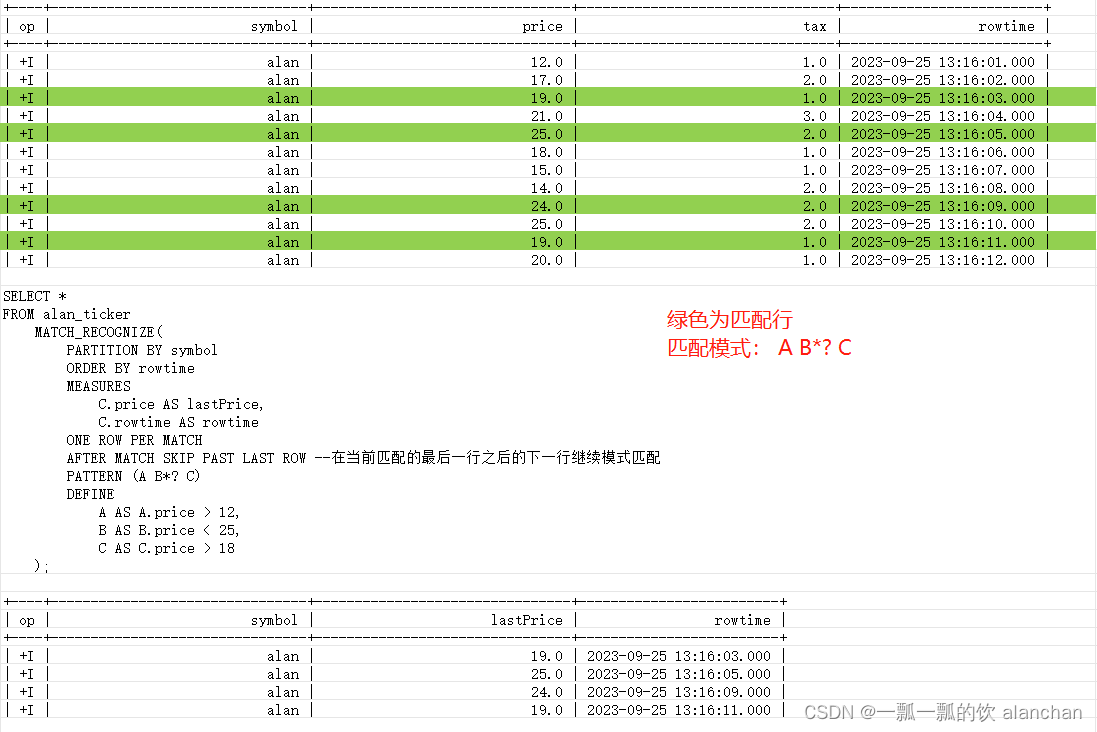
模式的最后一个变量不能使用贪婪量词。因此,不允许使用类似 (A B*) 的模式。通过引入条件为 B 的人工状态(例如 C),可以轻松解决此问题。因此,你可以使用类似以下的查询
PATTERN (A B* C)
DEFINE
A AS condA(),
B AS condB(),
C AS NOT condB()
截至版本Flink 1.17不支持可选的勉强量词(A?? 或者 A{0,1}?)
2)、时间约束
特别是对于流的使用场景,通常需要在给定的时间内完成模式。这要求限制住 Flink 在内部必须保持的状态总体大小(即已经过期的状态就不需要再维护了),即使在贪婪的量词的情况下也是如此。
因此,Flink SQL 支持附加的(非标准 SQL)WITHIN 子句来定义模式的时间约束。子句可以在 PATTERN 子句之后定义,并以毫秒为间隔进行解析。
如果潜在匹配的第一个和最后一个事件之间的时间长于给定值,则不会将这种匹配追加到结果表中。
通常鼓励使用 WITHIN 子句,因为它有助于 Flink 进行有效的内存管理。一旦达到阈值,即可修剪基础状态。然而,WITHIN 子句不是 SQL 标准的一部分。时间约束处理的方法已被提议将来可能会改变
----1、建表
CREATE TABLE alan_ticker2 (
symbol STRING,
price DOUBLE,
tax DOUBLE,
rowtime TIMESTAMP(3),
WATERMARK FOR rowtime AS rowtime - INTERVAL '1' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'alan_ticker2_topic',
'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
);
[INFO] Execute statement succeed.
Flink SQL> desc ticker7;
+---------+------------------------+------+-----+--------+---------------------------------+
| name | type | null | key | extras | watermark |
+---------+------------------------+------+-----+--------+---------------------------------+
| symbol | STRING | TRUE | | | |
| rowtime | TIMESTAMP(3) *ROWTIME* | TRUE | | | `rowtime` - INTERVAL '1' SECOND |
| price | INT | TRUE | | | |
| tax | INT | TRUE | | | |
+---------+------------------------+------+-----+--------+---------------------------------+
----2、查询数据
Flink SQL> select * from alan_ticker2;
+----+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| op | symbol | price | tax | rowtime |
+----+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| +I | alan | 20.0 | 1.0 | 2023-09-25 13:00:00.000 |
| +I | alan | 17.0 | 2.0 | 2023-09-25 13:20:00.000 |
| +I | alan | 18.0 | 1.0 | 2023-09-25 13:40:00.000 |
| +I | alan | 11.0 | 3.0 | 2023-09-25 14:00:00.000 |
| +I | alan | 14.0 | 2.0 | 2023-09-25 14:20:00.000 |
| +I | alan | 9.0 | 1.0 | 2023-09-25 14:40:00.000 |
| +I | alan | 15.0 | 1.0 | 2023-09-25 15:00:00.000 |
| +I | alan | 14.0 | 2.0 | 2023-09-25 15:20:00.000 |
| +I | alan | 24.0 | 2.0 | 2023-09-25 15:40:00.000 |
| +I | alan | 1.0 | 2.0 | 2023-09-25 16:00:00.000 |
| +I | alan | 19.0 | 1.0 | 2023-09-25 16:20:00.000 |
----3、验证时间约束
Flink SQL> SELECT *
> FROM alan_ticker2
> MATCH_RECOGNIZE(
> PARTITION BY symbol
> ORDER BY rowtime
> MEASURES
> C.rowtime AS dropTime,
> A.price - C.price AS dropDiff
> ONE ROW PER MATCH
> AFTER MATCH SKIP PAST LAST ROW
> PATTERN (A B* C) WITHIN INTERVAL '1' HOUR
> DEFINE
> B AS B.price > A.price - 10,
> C AS C.price < A.price - 10
> );
+----+--------------------------------+-------------------------+--------------------------------+
| op | symbol | dropTime | dropDiff |
+----+--------------------------------+-------------------------+--------------------------------+
| +I | alan | 2023-09-25 16:00:00.000 | 13.0 |
# 结果行代表价格从 15(在2023-09-25 15:00:00)下降到 1(在2023-09-25 16:00:00)。dropDiff 列包含价格差异。
# 即使价格也下降了较高的值,例如,下降了 11(在 2023-09-25 13:00:00 和 2023-09-25 14:40:00 之间),这两个事件之间的时间差大于 1 小时。因此,它们不会产生匹配。
#### 为什么本人运行出来的结果是13而不是14?官方示例也是14#########

6、输出方式
输出方式 描述每个找到的匹配项应该输出多少行。SQL 标准描述了两种方式:
- ALL ROWS PER MATCH
- ONE ROW PER MATCH
截至版本Flink 1.17 ,唯一支持的输出方式是 ONE ROW PER MATCH,它将始终为每个找到的匹配项生成一个输出摘要行。
输出行的 schema 将是按特定顺序连接 [partitioning columns] + [measures columns]。
以下示例显示了所定义的查询的输出:
----1、建表
# 使用上文中的表结构
----2、查询数据
# 使用上文中的表数据
Flink SQL> select * from alan_ticker;
+----+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| op | symbol | price | tax | rowtime |
+----+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| +I | alan | 12.0 | 1.0 | 2023-09-25 13:16:01.000 |
| +I | alan | 17.0 | 2.0 | 2023-09-25 13:16:02.000 |
| +I | alan | 19.0 | 1.0 | 2023-09-25 13:16:03.000 |
| +I | alan | 21.0 | 3.0 | 2023-09-25 13:16:04.000 |
| +I | alan | 25.0 | 2.0 | 2023-09-25 13:16:05.000 |
| +I | alan | 18.0 | 1.0 | 2023-09-25 13:16:06.000 |
| +I | alan | 15.0 | 1.0 | 2023-09-25 13:16:07.000 |
| +I | alan | 14.0 | 2.0 | 2023-09-25 13:16:08.000 |
| +I | alan | 24.0 | 2.0 | 2023-09-25 13:16:09.000 |
| +I | alan | 25.0 | 2.0 | 2023-09-25 13:16:10.000 |
| +I | alan | 19.0 | 1.0 | 2023-09-25 13:16:11.000 |
| +I | alan | 20.0 | 1.0 | 2023-09-25 13:16:12.000 |
----3、验证输出方式
# 该模式识别由 symbol 列分区。即使在 MEASURES 子句中未明确提及,分区列仍会添加到结果的开头
Flink SQL> SELECT *
> FROM alan_ticker
> MATCH_RECOGNIZE(
> PARTITION BY symbol
> ORDER BY rowtime
> MEASURES
> FIRST(A.price) AS startPrice,
> LAST(A.price) AS topPrice,
> B.price AS lastPrice
> ONE ROW PER MATCH
> PATTERN (A+ B)
> DEFINE
> A AS LAST(A.price, 1) IS NULL OR A.price > LAST(A.price, 1),
> B AS B.price < LAST(A.price)
> );
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| op | symbol | startPrice | topPrice | lastPrice |
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| +I | alan | 12.0 | 25.0 | 18.0 |
| +I | alan | 17.0 | 25.0 | 18.0 |
| +I | alan | 19.0 | 25.0 | 18.0 |
| +I | alan | 21.0 | 25.0 | 18.0 |
| +I | alan | 25.0 | 25.0 | 18.0 |
| +I | alan | 18.0 | 18.0 | 15.0 |
| +I | alan | 15.0 | 15.0 | 14.0 |
| +I | alan | 14.0 | 25.0 | 19.0 |
| +I | alan | 24.0 | 25.0 | 19.0 |
| +I | alan | 25.0 | 25.0 | 19.0 |
7、模式导航
DEFINE 和 MEASURES 子句允许在(可能)匹配模式的行列表中进行导航。
本部分介绍 用于声明条件或产生输出结果的导航。
1)、引用模式变量
引用模式变量 允许引用一组映射到 DEFINE 或 MEASURES 子句中特定模式变量的行。
例如,如果我们尝试将当前行与 A 进行匹配,则表达式 A.price 描述了目前为止已映射到 A 的一组行加上当前行。如果 DEFINE/MEASURES 子句中的表达式需要一行(例如 a.price 或 a.price > 10),它将选择属于相应集合的最后一个值。
如果没有指定模式变量(例如 SUM(price)),则表达式引用默认模式变量 *,该变量引用模式中的所有变量。换句话说,它创建了一个列表,其中列出了迄今为止映射到任何变量的所有行以及当前行。
示例 #
对于更全面的示例,可以查看以下模式和相应的条件:
PATTERN (A B+)
DEFINE
A AS A.price >= 10,
B AS B.price > A.price AND SUM(price) < 100 AND SUM(B.price) < 80
下表描述了如何为每个传入事件计算这些条件。
该表由以下列组成:
- ‘#’ - 行标识符,用于唯一标识列表中的传入行 [A.price]/[B.price]/[price]。
- price - 传入行的价格。
- [A.price]/[B.price]/[price] - 描述 DEFINE 子句中用于计算条件的行列表。
- Classifier - 当前行的分类器,指示该行映射到的模式变量。
- A.price/B.price/SUM(price)/SUM(B.price) - 描述了这些表达式求值后的结果。

从表中可以看出,第一行映射到模式变量 A,随后的行映射到模式变量 B。但是,最后一行不满足 B 条件,因为所有映射行 SUM(price) 的总和与 B 中所有行的总和都超过了指定的阈值。
2)、Logical Offsets
Logical offsets 在映射到指定模式变量的事件启用导航。这可以用两个相应的函数表示:
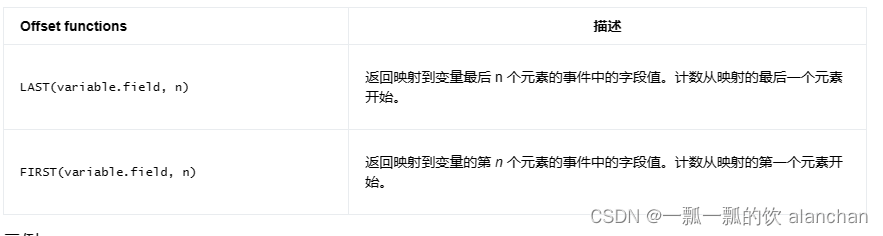
对于更全面的示例,可以参考以下模式和相应的条件:
PATTERN (A B+)
DEFINE
A AS A.price >= 10,
B AS (LAST(B.price, 1) IS NULL OR B.price > LAST(B.price, 1)) AND
(LAST(B.price, 2) IS NULL OR B.price > 2 * LAST(B.price, 2))
下表描述了如何为每个传入事件计算这些条件。
该表包括以下列:
- price - 传入行的价格。
- Classifier - 当前行的分类器,指示该行映射到的模式变量。
- LAST(B.price, 1)/LAST(B.price, 2) - 描述对这些表达式求值后的结果。

将默认模式变量与 logical offsets 一起使用也可能很有意义。
在这种情况下,offset 会包含到目前为止映射的所有行:
PATTERN (A B? C)
DEFINE
B AS B.price < 20,
C AS LAST(price, 1) < C.price
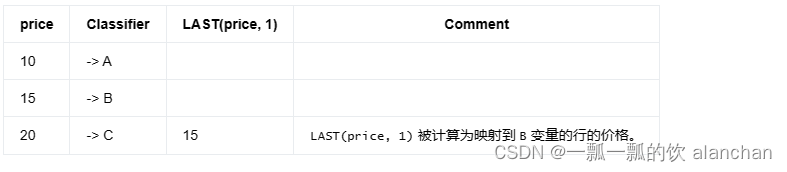
如果第二行没有映射到 B 变量,则会得到以下结果:

也可以在 FIRST/LAST 函数的第一个参数中使用多个模式变量引用。这样,可以编写访问多个列的表达式。但是,它们都必须使用相同的模式变量。换句话说,必须在一行中计算 LAST/FIRST 函数的值。
因此,可以使用 LAST(A.price * A.tax),但不允许使用类似 LAST(A.price * B.tax) 的表达式。
8、匹配后的策略
AFTER MATCH SKIP 子句指定在找到完全匹配后从何处开始新的匹配过程。
有四种不同的策略:
- SKIP PAST LAST ROW - 在当前匹配的最后一行之后的下一行继续模式匹配。
- SKIP TO NEXT ROW - 继续从匹配项开始行后的下一行开始搜索新匹配项。
- SKIP TO LAST variable - 恢复映射到指定模式变量的最后一行的模式匹配。
- SKIP TO FIRST variable - 在映射到指定模式变量的第一行继续模式匹配。
这也是一种指定单个事件可以属于多少个匹配项的方法。例如,使用 SKIP PAST LAST ROW 策略,每个事件最多只能属于一个匹配项。
为了更好地理解这些策略之间的差异,参考下面的例子。
1)、环境/数据准备
----1、建表
Flink SQL> CREATE TABLE alan_ticker_test (
> symbol STRING,
> price DOUBLE,
> tax DOUBLE,
> rowtime TIMESTAMP(3),
> WATERMARK FOR rowtime AS rowtime - INTERVAL '1' SECOND
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'alan_ticker_test',
> 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
> 'scan.startup.mode' = 'earliest-offset',
> 'format' = 'csv'
> );
----2、查询数据
Flink SQL> select * from alan_ticker_test;
+----+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| op | symbol | price | tax | rowtime |
+----+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| +I | alan | 12.0 | 1.0 | 2023-09-25 13:16:01.000 |
| +I | alan | 17.0 | 2.0 | 2023-09-25 13:16:02.000 |
| +I | alan | 19.0 | 1.0 | 2023-09-25 13:16:03.000 |
| +I | alan | 21.0 | 3.0 | 2023-09-25 13:16:04.000 |
| +I | alan | 25.0 | 2.0 | 2023-09-25 13:16:05.000 |
| +I | alan | 18.0 | 1.0 | 2023-09-25 13:16:06.000 |
| +I | alan | 15.0 | 1.0 | 2023-09-25 13:16:07.000 |
| +I | alan | 14.0 | 2.0 | 2023-09-25 13:16:08.000 |
| +I | alan | 24.0 | 2.0 | 2023-09-25 13:16:09.000 |
| +I | alan | 25.0 | 2.0 | 2023-09-25 13:16:10.000 |
| +I | alan | 19.0 | 1.0 | 2023-09-25 13:16:11.000 |
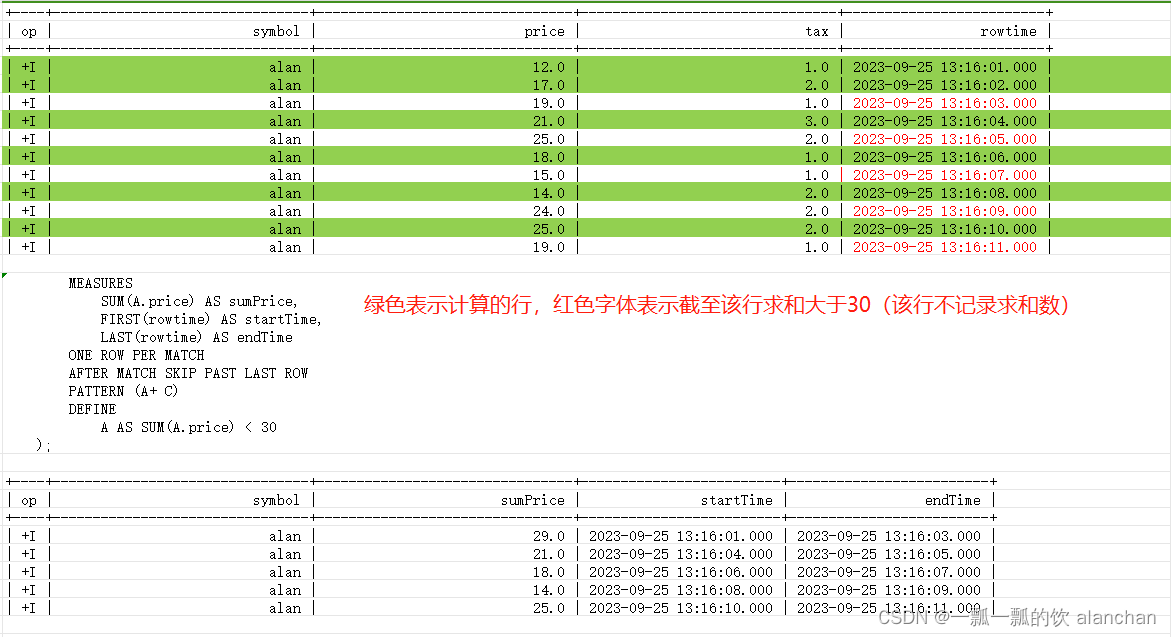
2)、AFTER MATCH SKIP PAST LAST ROW示例
使用上述的数据,查询结果如下
Flink SQL> SELECT *
> FROM alan_ticker_test
> MATCH_RECOGNIZE(
> PARTITION BY symbol
> ORDER BY rowtime
> MEASURES
> SUM(A.price) AS sumPrice,
> FIRST(rowtime) AS startTime,
> LAST(rowtime) AS endTime
> ONE ROW PER MATCH
> AFTER MATCH SKIP PAST LAST ROW --在当前匹配的最后一行之后的下一行继续模式匹配
> PATTERN (A+ C)
> DEFINE
> A AS SUM(A.price) < 30
> );
+----+--------------------------------+--------------------------------+-------------------------+-------------------------+
| op | symbol | sumPrice | startTime | endTime |
+----+--------------------------------+--------------------------------+-------------------------+-------------------------+
| +I | alan | 29.0 | 2023-09-25 13:16:01.000 | 2023-09-25 13:16:03.000 |
| +I | alan | 21.0 | 2023-09-25 13:16:04.000 | 2023-09-25 13:16:05.000 |
| +I | alan | 18.0 | 2023-09-25 13:16:06.000 | 2023-09-25 13:16:07.000 |
| +I | alan | 14.0 | 2023-09-25 13:16:08.000 | 2023-09-25 13:16:09.000 |
| +I | alan | 25.0 | 2023-09-25 13:16:10.000 | 2023-09-25 13:16:11.000 |
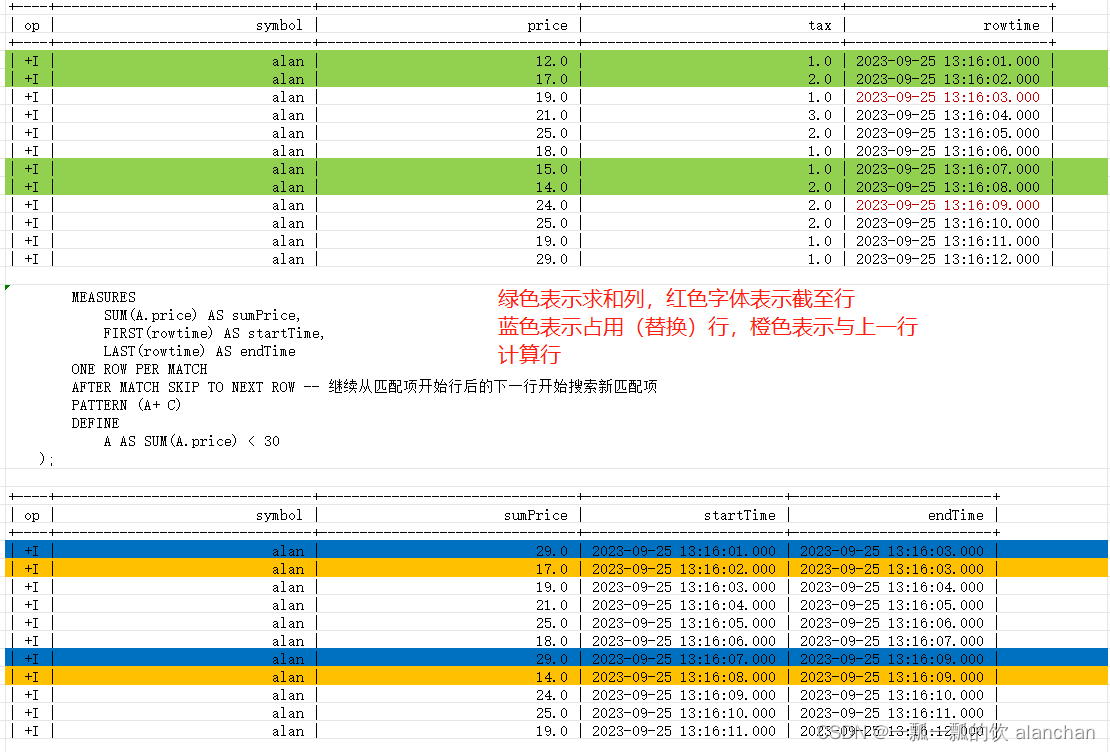
3)、AFTER MATCH SKIP TO NEXT ROW示例
Flink SQL> select * from alan_ticker_test;
+----+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| op | symbol | price | tax | rowtime |
+----+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| +I | alan | 12.0 | 1.0 | 2023-09-25 13:16:01.000 |
| +I | alan | 17.0 | 2.0 | 2023-09-25 13:16:02.000 |
| +I | alan | 19.0 | 1.0 | 2023-09-25 13:16:03.000 |
| +I | alan | 21.0 | 3.0 | 2023-09-25 13:16:04.000 |
| +I | alan | 25.0 | 2.0 | 2023-09-25 13:16:05.000 |
| +I | alan | 18.0 | 1.0 | 2023-09-25 13:16:06.000 |
| +I | alan | 15.0 | 1.0 | 2023-09-25 13:16:07.000 |
| +I | alan | 14.0 | 2.0 | 2023-09-25 13:16:08.000 |
| +I | alan | 24.0 | 2.0 | 2023-09-25 13:16:09.000 |
| +I | alan | 25.0 | 2.0 | 2023-09-25 13:16:10.000 |
| +I | alan | 19.0 | 1.0 | 2023-09-25 13:16:11.000 |
| +I | alan | 29.0 | 1.0 | 2023-09-25 13:16:12.000 |
4)、AFTER MATCH SKIP TO LAST variable 示例
本示例使用以下sql运行将产生如下异常
SELECT *
FROM alan_ticker_test
MATCH_RECOGNIZE(
PARTITION BY symbol
ORDER BY rowtime
MEASURES
SUM(A.price) AS sumPrice,
FIRST(rowtime) AS startTime,
LAST(rowtime) AS endTime
ONE ROW PER MATCH
AFTER MATCH SKIP TO LAST A
PATTERN (A+ C)
DEFINE
A AS SUM(A.price) < 30
);
java.lang.RuntimeException:> org.apache.flink.util.FlinkRuntimeException: Could not skip to first element of a match.
本文开头的示例中有关于该方法的使用,如下:
Flink SQL> SELECT *
> FROM alan_ticker
> MATCH_RECOGNIZE (
> PARTITION BY symbol -- 按照 symbol 列进行分区并按照 rowtime 属性进行排序
> ORDER BY rowtime
> MEASURES
> START_ROW.rowtime AS start_tstamp,
> LAST(PRICE_DOWN.rowtime) AS bottom_tstamp,
> LAST(PRICE_UP.rowtime) AS end_tstamp
> ONE ROW PER MATCH -- 输出行数由 ONE ROW PER MATCH 输出方式定义
> AFTER MATCH SKIP TO LAST PRICE_UP --如果找到完全匹配后从最后一个PRICE_UP 事件开始寻找下一个模式匹配
> --指定模式,有开始事件START_ROW,然后是一个或多个PRICE_DOWN 事件,并以 PRICE_UP 事件结束
> --定义了模式变量PRICE_DOWN、PRICE_UP 必须满足的条件
> --不存在 START_ROW 模式变量,它具有一个始终被评估为 TRUE 隐式条件。
> --任意行都可以是 START_ROW
> PATTERN (START_ROW PRICE_DOWN+ PRICE_UP)
> DEFINE
> -- 模式变量 PRICE_DOWN 定义
> -- 对于初始情况或没有满足 PRICE_DOWN 条件的最后一行时,该行的价格应小于该模式中前一行(由 START_ROW 引用)的价格。
> -- 价格小于满足 PRICE_DOWN 条件的最后一行
> PRICE_DOWN AS (LAST(PRICE_DOWN.price, 1) IS NULL AND PRICE_DOWN.price < START_ROW.price) OR PRICE_DOWN.price < LAST(PRICE_DOWN.price, 1),
> --模式变量 PRICE_UP 定义
> --价格大于满足 PRICE_DOWN 条件的最后一行
> PRICE_UP AS PRICE_UP.price > LAST(PRICE_DOWN.price, 1)
> ) MR;
+----+--------------------------------+-------------------------+-------------------------+-------------------------+
| op | symbol | start_tstamp | bottom_tstamp | end_tstamp |
+----+--------------------------------+-------------------------+-------------------------+-------------------------+
| +I | alan | 2023-09-25 13:16:05.000 | 2023-09-25 13:16:08.000 | 2023-09-25 13:16:09.000 |
# 该行结果描述了从 2023-09-25 13:16:05 开始的降低,在 2023-09-25 13:16:08 达到最低,到 2023-09-25 13:16:09 再次上涨
5)、AFTER MATCH SKIP TO FIRST variable 示例
SELECT *
FROM alan_ticker_test
MATCH_RECOGNIZE(
PARTITION BY symbol
ORDER BY rowtime
MEASURES
SUM(A.price) AS sumPrice,
FIRST(rowtime) AS startTime,
LAST(rowtime) AS endTime
ONE ROW PER MATCH
AFTER MATCH SKIP TO FIRST A --在映射到指定模式变量的第一行继续模式匹配
PATTERN (A+ C)
DEFINE
A AS SUM(A.price) < 30
);
java.lang.RuntimeException: org.apache.flink.util.FlinkRuntimeException: Could not skip to first element of a match.
这种组合将产生一个运行时异常,因为人们总是试图在上一个开始的地方开始一个新的匹配。这将产生一个无限循环,因此是禁止的。
在 SKIP TO FIRST/LAST variable 策略的场景下,可能没有映射到该变量的行(例如,对于模式 A*)。在这种情况下,将抛出一个运行时异常,因为标准要求一个有效的行来继续匹配
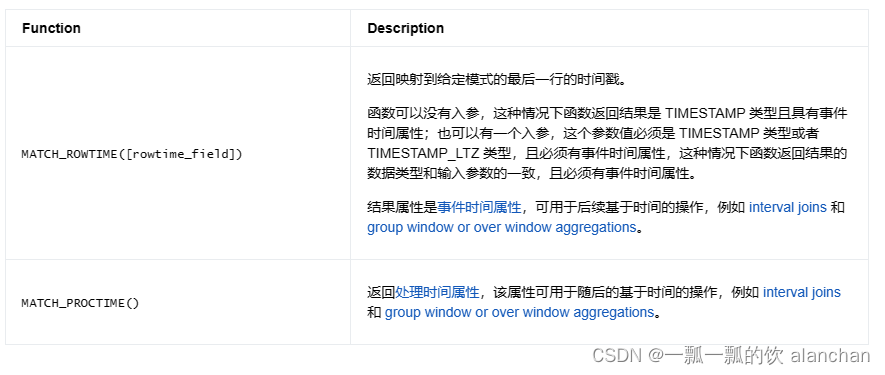
9、时间属性
为了在 MATCH_RECOGNIZE 之上应用一些后续查询,可能需要使用时间属性。有两个函数可供选择:
10、控制内存消耗
在编写 MATCH_RECOGNIZE 查询时,内存消耗是一个重要的考虑因素,因为潜在匹配的空间是以宽度优先的方式构建的。鉴于此,我们必须确保模式能够完成。最好使用映射到匹配项的合理数量的行,因为它们必须内存相适。
例如,该模式不能有没有接受每一行上限的量词。这种模式可以是这样的:
PATTERN (A B+ C)
DEFINE
A as A.price > 10,
C as C.price > 20
查询将每个传入行映射到 B 变量,因此永远不会完成。可以纠正此查询,例如,通过否定 C 的条件:
PATTERN (A B+ C)
DEFINE
A as A.price > 10,
B as B.price <= 20,
C as C.price > 20
或者使用 reluctant quantifier:
PATTERN (A B+? C)
DEFINE
A as A.price > 10,
C as C.price > 20
MATCH_RECOGNIZE 子句未使用配置的 state retention time。为此,可能需要使用 WITHIN 子句。
11、已知的局限
Flink 对 MATCH_RECOGNIZE 子句实现是一项长期持续的工作,截至flink版本1.17尚不支持 SQL 标准的某些功能。
不支持的功能包括:
1、模式表达式:
- Pattern groups - 这意味着量词不能应用于模式的子序列。因此,(A (B C)+) 不是有效的模式。
- Alterations - 像 PATTERN((A B | C D) E)这样的模式,这意味着在寻找 E 行之前必须先找到子序列 A B 或者 C D。
- PERMUTE operator - 这等同于它应用于所示的所有变量的排列 PATTERN (PERMUTE (A, B, C)) = PATTERN (A B C | A C B | B A C | B C A | C A B | C B A)。
- Anchors - ^, $,表示分区的开始/结束,在流上下文中没有意义,将不被支持。
- Exclusion - PATTERN ({- A -} B) 表示将查找 A,但是不会参与输出。这只适用于 ALL ROWS PER MATCH 方式。
- Reluctant optional quantifier - PATTERN A?? 只支持贪婪的可选量词。
2、ALL ROWS PER MATCH 输出方式 - 为参与创建匹配项的每一行产生一个输出行。这也意味着:
- MEASURES 子句唯一支持的语义是 FINAL
- CLASSIFIER 函数,尚不支持返回行映射到的模式变量。
3、SUBSET - 它允许创建模式变量的逻辑组,并在 DEFINE 和 MEASURES 子句中使用这些组。
4、Physical offsets - PREV/NEXT,它为所有可见事件建立索引,而不是仅将那些映射到模式变量的事件编入索引(如 logical offsets 的情况)。
5、提取时间属性 - 目前无法为后续基于时间的操作提取时间属性。
6、MATCH_RECOGNIZE 仅 SQL 支持。Table API 中没有等效项。
7、Aggregations:
不支持 distinct aggregations。
以上,介绍了Flink 的模式检测,以及每个可运行的示例、运行结果的图示分析。






![[学习笔记]ARXML - Data Format](https://img-blog.csdnimg.cn/997f5fe6d71e4f8fb8b01360c9834fbd.png)