字符串
其实就是字符数组
注意
字节数组与字符串可以相互转换
a := "hello world"
b := []byte(a)
c := string(b)
字节数组转换为字符串在运行时调用了slicebytetostring函数。需要注意的是,字节数组与字符串的相互转换并不是简单的指针引用,而是涉及了复制。当字符串大于32字节时,还需要申请堆内存,因此在涉及一些密集的转换场景时,需要评估这种转换带来的性能损耗
当字符串转换为字节数组时,在运行时需要调用stringtoslicebyte函数,其和slicebytetostring函数非常类似,需要新的足够大小的内存空间。当字符串小于32字节时,可以直接使用缓存buf。当字符串大于32字节时,rawbyteslice函数需要向堆区申请足够的内存空间。最后使用copy函数完成内存复制。
切片
概要
有data、len 、cap 三个元素。 分别指向数据,长度,容量,底层是一个数组
切片是一种简化版的动态数组。切片的在go中的定义为如下,在对切片赋值,就是修改指向数组的指针,len,cap的值。而在拷贝的时候,如果直接使用=,则会复制被拷贝的切片的数组指针,cap,len值,因此会指向同一个地址,而使用copy的话会把被拷贝的切片中的数组的值复制到拷贝的切片的数组中。即地址是不同的
切片在被截取时的另一个特点是,被截取后的数组仍然指向原始切片的底层数据。 要真正复制切片,需要用copy
slice:= make(int[], 4, 6)
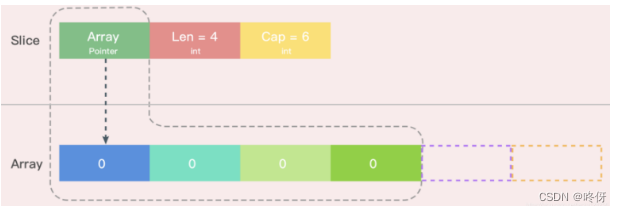
Go语言中,切片的复制其实也是值复制,但这里的值复制指对于运行时SliceHeader结构的复制。如图底层指针仍然指向相同的底层数据的数组地址,因此可以理解为数据进行了引用传递。切片的这一特性使得即便切片中有大量数据,在复制时的成本也比较小,这与数组有显著的不同
切片扩容
cap增长的策略:
- 如果新申请容量(cap)大于2倍的旧容量(old.cap),则最终容量(newcap)是新申请的容量(cap)。
- 如果当前大小小于1024,则两倍增长;
- 否则每次增长25%,直到满足期望。
- 如果新申请容量(cap)大于2倍的旧容量(old.cap),则最终容量(newcap)是新申请的容量(cap)。
// slice 扩容伪代码:
{
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
for newcap < cap {
newcap += newcap / 4
}
}
}
map
源码
// Map contains Type fields specific to maps.
type Map struct {
Key *Type // Key type
Elem *Type // Val (elem) type
Bucket *Type // internal struct type representing a hash bucket
Hmap *Type // internal struct type representing the Hmap (map header object)
Hiter *Type // internal struct type representing hash iterator state
}
// A header for a Go map.
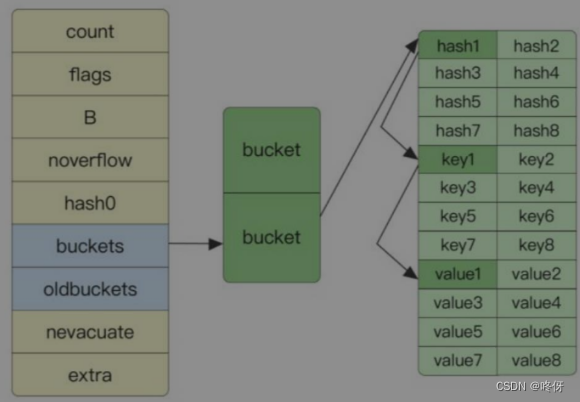
type hmap struct {
// 元素个数,调用 len(map) 时,直接返回此值
count int
flags uint8 // flags代表当前map的状态(是否处于正在写入的状态等
B uint8 // buckets 的对数 log_2
// overflow 的 bucket 近似数 noverflow为map中溢出桶的数量。当溢出的桶太多时,map会进行same-size map growth,其实质是避免溢出桶过大导致内存泄露
noverflow uint16
// 计算 key 的哈希的时候会传入哈希函数
hash0 uint32
buckets unsafe.Pointer // 指向内存的指针,可以看作是:[]bmap。 其大小为 2^B. 如果元素个数为0,就为 nil
// 扩容的时候,buckets 长度会是 oldbuckets 的两倍
oldbuckets unsafe.Pointer
// 指示扩容进度,小于此地址的 buckets 迁移完成
nevacuate uintptr
extra *mapextra // optional fields
}
// buckets指向的结构体
type bmap struct {
tophash [bucketCnt]uint8 // bucketCnt值固定为8个,也就是每个bmap最大能存储8个key-value对。
}
// go编译器在编译时,会扩展bmap为如下的结构:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
type mapextra struct {
// If both key and elem do not contain pointers and are inline, then we mark bucket
// type as containing no pointers. This avoids scanning such maps.
// However, bmap.overflow is a pointer. In order to keep overflow buckets
// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.
// overflow and oldoverflow are only used if key and elem do not contain pointers.
// overflow contains overflow buckets for hmap.buckets.
// oldoverflow contains overflow buckets for hmap.oldbuckets.
// The indirection allows to store a pointer to the slice in hiter.
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap
}
/*
当一个 map 的 key 和 elem 都不含指针并且他们的长度都没有超过 128 时(当 key 或 value 的长度超过 128 时, go 在 map 中会使用指针存储), 该 map 的 bucket 类型会被标注为不含有指针, 这样 gc 不会扫描该 map, 这会导致一个问题, bucket 的底层结构 bmap 中含有一个指向溢出桶的指针(uintptr类型, uintptr指针指向的内存不保证不会被 gc free 掉), 当 gc 不扫描该结构时, 该指针指向的内存会被 gc free 掉, 因此在 hmap 结构中增加了 mapextra 字段, 其中 overflow 是一个指向保存了所有 hmap.buckets 的溢出桶地址的 slice 的指针, 相对应的 oldoverflow 是指向保存了所有 hmap.oldbuckets 的溢出桶地址的 slice 的指针, 只有当 map 的 key 和 elem 都不含指针时这两个字段才有效, 因为这两个字段设置的目的就是避免当 map 被 gc 跳过扫描带来的引用内存被 free 的问题, 当 map 的 key 和 elem 含有指针时, gc 会扫描 map, 从而也会获知 bmap 中指针指向的内存是被引用的, 因此不会释放对应的内存。
*/
溢出桶

Go语言选择将key与value分开存储而不是以key/value/key/value的形式存储,是为了在字节对齐时压缩空间
hmap 结构相当于 go map 的头, 它存储了哈希桶的内存地址, 哈希桶之间在内存中紧密连续存储, 彼此之间没有额外的 gap, 每个哈希桶最多存放 8 个 k/v 对, 冲突次数超过 8 时会存放到溢出桶中, 哈希桶可以跟随多个溢出桶, 呈现一种链式结构, 当 HashTable 的装载因子超过阈值(6.5) 后会触发哈希的扩容
冲突检测
Go语言中的哈希表采用的是开放寻址法中的线性探测(Linear Probing)策略,线性探测策略是顺序(每次探测间隔为1)的
插入过程
例如:m1 map[string]string插入一条数据的过程如下:
insert “key1 name”:“乔布斯”
hashvalue = hash(“key1 name”)
slot = hashvalue的低8bit % len(m1),例如m1的槽位是4个,则slot = hashvalue % 4。假设slot = 2
hashvalue的高8bit这条数据应该插入到bmap中的第几个子槽。如果bmap已经写满8个,则读取overflow指向的下一个紧邻着的bmap(溢出桶)去插入这条数据
删除过程
其核心代码位于runtime.mapdelete函数中,删除操作同样需要根据key计算出hash的前8位和指定的桶,同样会一直寻找是否有相同的key,如果找不到,则会一直查找当前桶的溢出桶,直到到达溢出桶链表末尾。如果查找到了指定的key,则会清空该数据,将hash位设置为emptyOne。如果发现后面没有元素,则会将hash位设置为emptyRest,并循环向上检查前一个元素是否为空
扩容
当插入的元素越来越多,导致哈希桶慢慢填满,导致溢出桶越来越多,所以发生哈希碰撞的频率越来越高,就需要进行扩容,
若装载因子过大, 说明此时 map 中元素数目过多, 此时 go map 的扩容策略为将 hmap 中的 B 增一, 即将整个哈希桶数目扩充为原来的两倍大小, 而当因为溢出桶数目过多导致扩容时, 因此时装载因子并没有超过 6.5, 这意味着 map 中的元素数目并不是很多, 因此这时的扩容策略是等量扩容, 即新建完全等量的哈希桶, 然后将原哈希桶的所有元素搬迁到新的哈希桶中。
需要注意的几点
3.1 Go map遍历为什么是无序的
使用 range 多次遍历 map 时输出的 key 和 value 的顺序可能不同。这是 Go 语言的设计者们有意为之,旨在提示开发者们,Go 底层实现并不保证 map 遍历顺序稳定,不要依赖 range 遍历结果顺序。
主要原因有2点:
- map在遍历时,并不是从固定的0号bucket开始遍历的,每次遍历,都会从一个随机值序号的bucket,再从其中随机的cell开始遍历
- map遍历时,是按序遍历bucket,同时按需遍历bucket中和其overflow bucket中的cell。但是map在扩容后,会发生key的搬迁,这造成原来落在一个bucket中的key,搬迁后,有可能会落到其他bucket中了,从这个角度看,遍历map的结果就不可能是按照原来的顺序了。
因此如果不加入随机数,在不发生扩容情况下,一些不熟悉该原理的开发者会认为map是有序的,一旦依赖这个特性,就会引发bug。所以golang直接通过加随机数(在初始化迭代器时会生成一个随机数,决定从哪一个bucket开始迭代)避免问题的发生。这就是map为什么每次遍历顺序是不一样的原因。
3.2 如何让map有序
把key取出来进行排序,再通过key依次从map中取值。
3.3 map并发读写会产生什么情况
map在默认情况下时不支持并发的,这是由于golang的设计者考虑到使用map的场景都不是并发访问,如果map并发读写会产生什么呢?如果并发时写入,则会产生panic。runtime.map 代码判断:
//赋值时检查是否在写入
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
}
//读取数据时检查是否在写入
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
}
3.4 如何安全使用map
Go map不是线程安全的,在使用过程中如果需要保证线程安全,则需要保持同步。
- 使用sync.Mutex或sync.RWMutex进行加锁
- 使用go官方提供的sync.Map替代map
3.5 map中的key可以取地址吗?
不可以,因为key对应的value的内存地址可能因为扩容而变化,所以不允许取地址。也正因为如此,下面代码是错误的。
type Student struct {
name string
}
func main() {
m := map[string]Student{"people": {"zhoujielun"}}
m["people"].name = "wuyanzu"
}
函数
闭包
一个函数捕获了和他在同一个作用域的其他常量和变量.这就意味着当闭包被调用的时候,不管在程序什么地方调用,闭包能够使用这些常量或者变量.
它不关心这些捕获了的变量和常量是否已经超出了作用域,所以只有闭包还在使用他,这些变量就还会存在,
在go里面,所有的匿名函数都是闭包
闭包是一个函数值,它引用了函数体之外的变量。 这个函数可以对这个引用的变量进行访问和赋值;换句话说这个函数被“绑定”在这个变量上
例如,函数 adder 返回一个闭包。每个返回的闭包都被绑定到其各自的 sum 变量上。
package main
import "fmt"
func adder() func(int) int {
sum := 0
return func(x int) int {
sum += x
return sum
}
}
func main() {
pos, neg := adder(), adder()
for i := 0; i < 10; i++ {
fmt.Println(
pos(i),
neg(-2*i),
)
}
}