目录
前情回顾
1. 中断一个线程
1.1 中断的API
1.2 小结
2. 等待一个线程
2.1 等待的API
3. 线程的状态
3.1 贯彻线程的所有状态
3.2 线程状态和状态转移的意义
4. 多线程带来的的风险-线程安全 (重点)
4.1 观察线程不安全
4.2 线程安全的概念
4.3 线程不安全的原因
4.3.1 修改共享数据
4.3.2 原子性
4.3.3 可见性
4.3.4 代码顺序性
4.4 解决之前的线程不安全问题
前情回顾
操作系统、进程和线程_木子斤欠木同的博客-CSDN博客
深入浅出Java的多线程编程——第一篇_木子斤欠木同的博客-CSDN博客
让我们来回顾一下,第一篇多线程的内容:
1. 多线程:
(1)线程的概念
(2)进程和线程的区别
(3)Java代码如何创建线程
①继承Thread重写run
②实现Runnable接口重写run,将该实现类作为参数传给Thread的构造方法
③继承Thread,匿名内部类
④实现Runnable,匿名内部类
⑤lambda表达式
2. Thread的常用属性
start方法,真正从系统这里,创建一个线程,新的线程将会执行run方法。
run方法:表示线程的入口方法是啥(线程启动起来,要执行哪些逻辑)(run方法不是让程序猿调用的,要交给系统去自动调用)【换个角度理解:我们可以把线程的run方法理解为main方法,都是系统去自动调用】
1. 中断一个线程
李四一旦进到工作状态,他就会按照行动指南上的步骤去进行工作,不完成是不会结束的。但有时我们需要增加一些机制,例如老板突然来电话了,说转账的对方是个骗子,需要赶紧停止转账,那张三该如何通知李四停止呢?这就涉及到我们的停止线程的方式了。
本质上来说,让一个线程终止,办法就一种,让该线程的入口方法执行完毕!也就是让run跑完!
目前常见的有以下两种方式:
- 通过共享的标记来进行沟通
- 调用 interrupt() 方法来通知【记住,只是通知而已】
示例1:使用自定义的变量来作为标志位
- 需要给标志位上加 volatile 关键字(这个关键字的功能后面介绍).
public static volatile boolean isQuit = false;
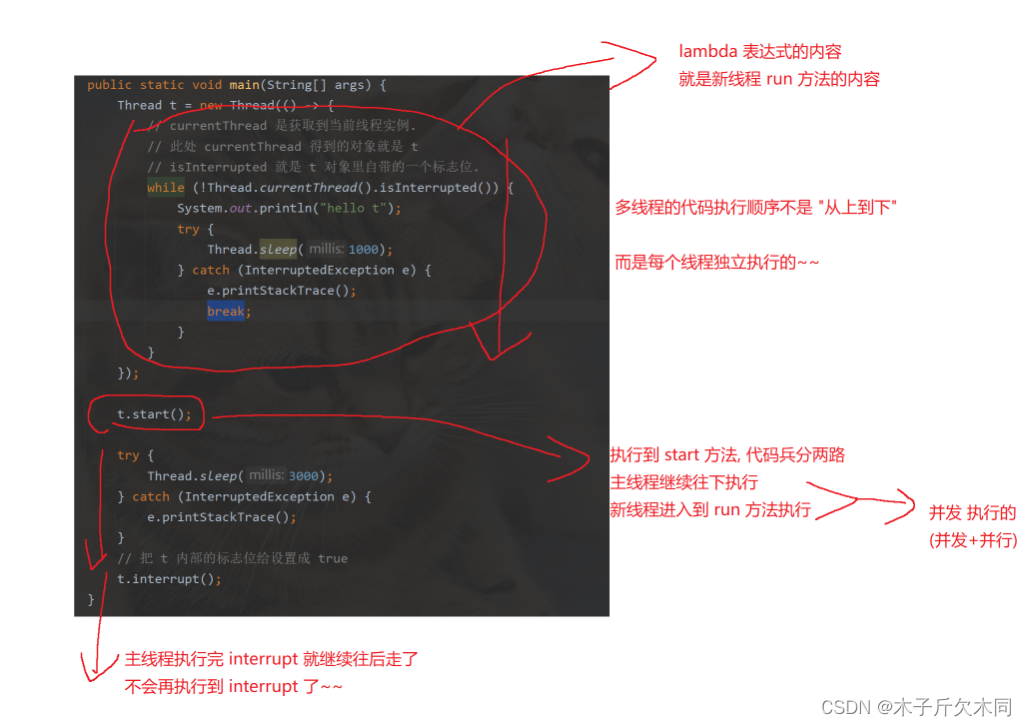
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while (!isQuit){
System.out.println(Thread.currentThread().getName() + " : 别管我,我忙着转正!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName() + " : 啊!险些误了大事");
});
System.out.println(Thread.currentThread().getName() + " : 让李四开始转账");
t.start();
Thread.sleep(10*1000);
System.out.println(Thread.currentThread().getName() + " : 老板来电话了,得赶紧通知李四对方是个骗子!");
isQuit = true;
}
这里的 public static volatile boolean isQuit = false; 为什么需要加static,因为main函数被static修饰,所以在main内部用到的成员变量要加static
示例2:使用 Thread.interrupted() 或者 Thread.currentThread().isInterrupted() 代替自定义标志位。
1.1 中断的API
- Thread 内部包含了一个 boolean 类型的变量作为线程是否被中断的标记。
| 方法 | 说明 |
| pubilc void interrupt() | 中断对象关联的线程,如果线程正在阻塞,会把线程唤醒,则以异常的方式通知,然后吧标志位设置为true |
| public static boolean interrupted() | 判断当前线程的中断标志位是否设置,调用后清除标志位 |
| public boolean isInterrupted() | 判断对象关联的线程的标志位是否设置,调用后不清除标志位 |
- 使用 thread 对象的 interrupted() 方法通知线程结束.
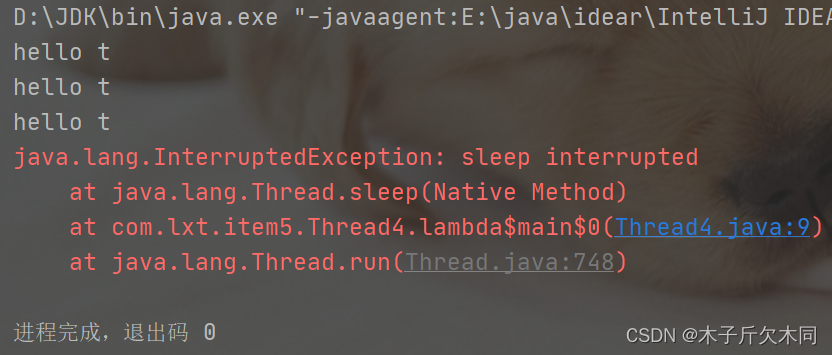
public class Thread4 {
public static void main(String[] args) {
Thread t = new Thread(() -> {
while(!Thread.currentThread().isInterrupted()){
System.out.println("hello t");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
t.interrupt();
}
}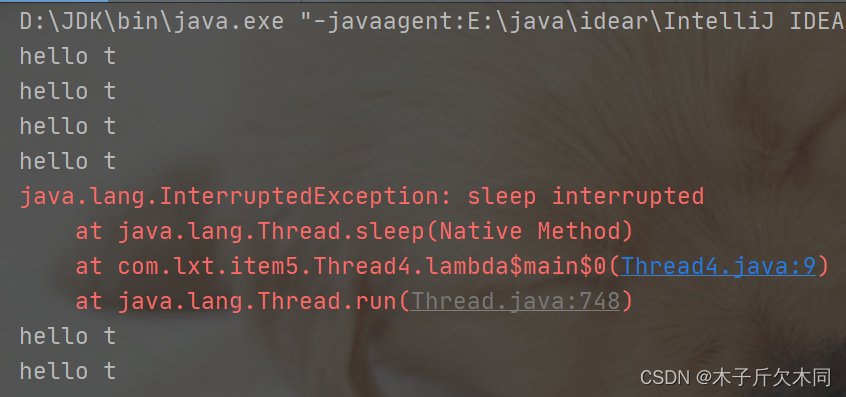
我们可以发现,调用t.interrupt方法的时候,线程并没有真的结束,而是打印了个异常信息,又继续执行了
1.2 小结
interrupt方法的作用:
(1)设置标志位为true
(2)如果该线程正在阻塞中(比如执行了sleep)此时就会把阻塞状态唤醒,通过抛出异常的方式让sleep立即结束
注意:一个非常重要的问题,当sleep被唤醒的时候(只有sleep被唤醒才会重置标志位),sleep自动地把isInterrupted标志位给清空了(true - > false),这导致下次循环,循环仍然可以继续执行了~~
有的开关,是按下之后,就按下去了
有的开关,是按下去之后,自动弹起(sleep就属于这种)
一种极端的情况:
如果设置interrupt的时候,恰好sleep刚醒,这个时候赶巧了,执行到下一轮循环条件就直接结束了。但是这种概率非常低,毕竟sleep的时间已经占据了整个循环体的99.999%的时间了
如果需要结束循环,就得在catch中搞个break
public class Thread4 {
public static void main(String[] args) {
Thread t = new Thread(() -> {
while(!Thread.currentThread().isInterrupted()){
System.out.println("hello t");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
break;
}
}
});
t.start();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
t.interrupt();
}
}
小结一下:
如果sleep执行的时候看到这个标志位是false,sleep正常进行休眠操作
如果当前的标志位为true
sleep无论是刚刚执行还是已经执行了一般,都会触发两件事
(1)立即抛出异常
(2)清空标志位为false
再下次循环,到sleep
由于当前标志位本身是false,就啥也不干~~
总结到这里,就有小伙伴有疑问了,为什么sleep要清空标志位呢?
目的就是为了让线程自身能够对于线程何时结束,有一个更明确的控制~~
当前,interrupt方法,效果不是让线程立即结束,而是告诉他,你该结束了,至于他是否真的要立即结束还是等会结束,都是由它本线程的代码来控制~~,interrupt只是通知,而非“命令”!

有的朋友就好奇了,我如果不加sleep,这些能令线程阻塞的代码,那是不是就能让该线程直接结束呢?对的,是可以,但是工作中没人会这么写代码,一个不可控的线程是多么可怕!
这里就可以又引出一个问题,java为啥不强制制定“命令结束”的操作呢?
只要调用interrupt就立即结束?
答:主要是设定成这种,对线程来说非常不友好~,线程t何时结束,一定是t自己要最清楚,交给t自身来决定比较好!
2. 等待一个线程
有时,我们需要等待一个线程完成它的工作后,才能进行自己的下一步工作。例如,张三只有等李四转账成功,才决定是否存钱,这时我们需要一个方法明确等待线程的结束。
public class Thread5 {
public static void main(String[] args) throws InterruptedException {
Runnable run = () -> {
for(int i = 0;i < 3;i++){
try {
System.out.println(Thread.currentThread().getName() + " : 我正在工作!");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName() + " : 我的工作结束了!");
};
Thread t1 = new Thread(run,"李四");
Thread t2 = new Thread(run,"张三");
System.out.println("李四先工作");
t1.start();
t1.join();
System.out.println("李四做完了,张三开始工作!");
t2.start();
t2.join();
System.out.println("王五做完了,张三开始工作!");
System.out.println("两人都工作结束了!");
}
}

在main线程中调用t1.join()表示main线程要等t1线程跑完,main线程才可以继续执行。
(1)main线程调用t1.join()的时候,如果t1还在运行,此时main线程阻塞,知道t执行完毕(t1的run执行完了),main线程才从阻塞中解除,才继续执行。
(2)main线程调用t.join()的时候,如果t已经结束了,此时join就不会阻塞,会立即执行下去。
如果把两个join方法注释掉,就会CPU的抢占式调用的典型例子:
public class Thread5 {
public static void main(String[] args) throws InterruptedException {
Runnable run = () -> {
for(int i = 0;i < 3;i++){
try {
System.out.println(Thread.currentThread().getName() + " : 我正在工作!");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName() + " : 我的工作结束了!");
};
Thread t1 = new Thread(run,"李四");
Thread t2 = new Thread(run,"张三");
System.out.println("李四先工作");
t1.start();
// t1.join();
System.out.println("李四做完了,张三开始工作!");
t2.start();
// t2.join();
System.out.println("王五做完了,张三开始工作!");
System.out.println("两人都工作结束了!");
}
}
2.1 等待的API
| 方法 | 说明 |
| public void join() | 等待线程结束 |
| public void join(long millis) | 等待线程结束,最多等 millis 毫秒 |
| public void join(long millis, int nanos) | 同理,但可以更高精度 |
3. 线程的状态
3.1 贯彻线程的所有状态
线程的状态是一个枚举类型 Thread.State
public class Thread6 {
public static void main(String[] args) {
for (Thread.State state:Thread.State.values()) {
System.out.println(state);
}
}
}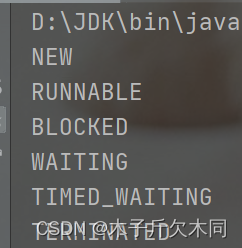
- NEW: 安排了工作, 还未开始行动
- RUNNABLE: 可工作的. 又可以分成正在工作中和即将开始工作.
- BLOCKED: 这几个都表示排队等着其他事情
- WAITING: 这几个都表示排队等着其他事情
- TIMED_WAITING: 这几个都表示排队等着其他事情
- TERMINATED: 工作完成了.
3.2 线程状态和状态转移的意义
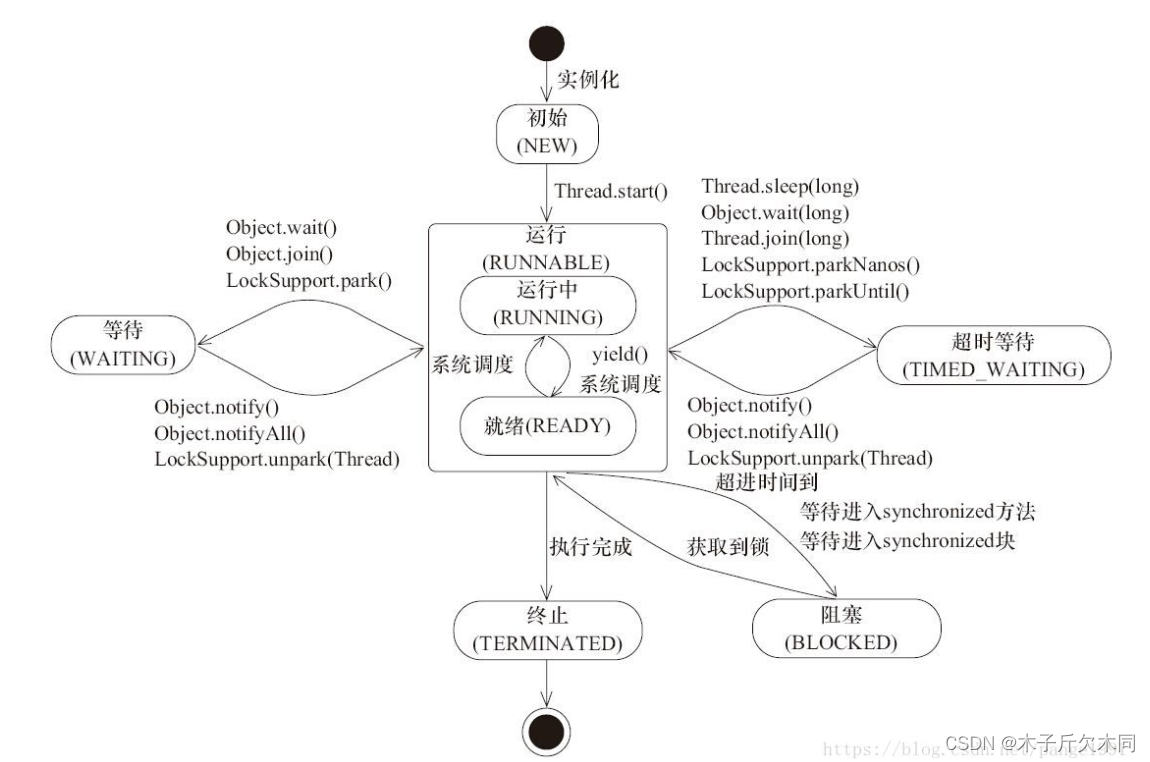
大家不要被这个状态转移图吓到,我们重点是要理解状态的意义以及各个状态的具体意思。
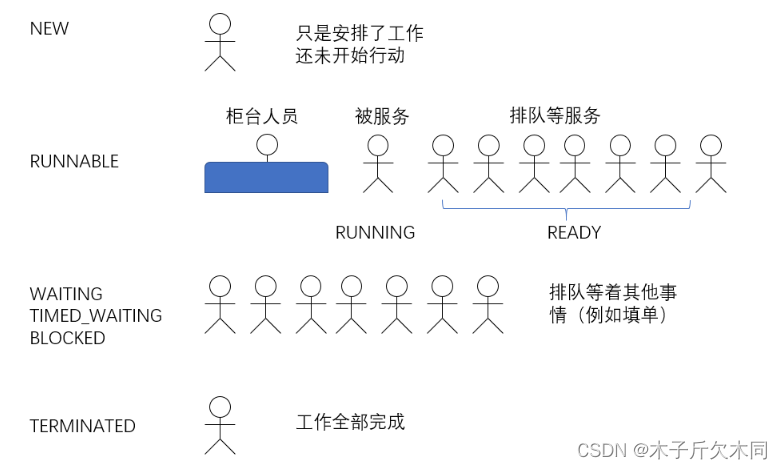
举个栗子:
刚把李四、王五找来,还是给他们在安排任务,没让他们行动起来,就是 NEW 状态;
当李四、王五开始去窗口排队,等待服务,就进入到 RUNNABLE 状态。该状态并不表示已经被银行工。
作人员开始接待,排在队伍中也是属于该状态,即可被服务的状态,是否开始服务,则看调度器的调度;
当李四、王五因为一些事情需要去忙,例如需要填写信息、回家取证件、发呆一会等等时,进入
BLOCKED 、 WATING 、 TIMED_WAITING 状态,至于这些状态的细分,我们以后再详解;
如果李四、王五已经忙完,为 TERMINATED 状态。所以,之前我们学过的 isAlive() 方法,可以认为是处于不是 NEW 和 TERMINATED 的状态都是活着的。
4. 多线程带来的的风险-线程安全 (重点)
本质是因为线程之间的调度顺序的不确定性
4.1 观察线程不安全
public class Thread7 {
static int count = 0;
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
for(int i = 0;i < 5000;i++){
count++;
}
});
Thread t2 = new Thread(() -> {
for(int i = 0;i < 5000;i++){
count++;
}
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(count);
}
}


由于当前这两线程调度的顺序是无序的~~
你也不知道这两线程自增的过程中,到底经历了什么
有多少次是“顺序执行”,有多少次是“交错执行”不知道!
得到的结果是啥也就是不确定的!
这里就引出了一个问题,出现bug之后,得到的结果一定是 <= 10000,或者结果一定是 >= 5000?

CPU调用是以原语为单位的!
4.2 线程安全的概念
想给出一个线程安全的确切定义是复杂的,但我们可以这样认为:
如果多线程环境下代码运行的结果是符合我们预期的,即在单线程环境应该的结果,则说这个程序是线程安全的。
4.3 线程不安全的原因
4.3.1 修改共享数据
上面的线程不安全的代码中, 涉及到多个线程针对 counter.count 变量进行修改.
此时这个 count 是一个多个线程都能访问到的 "共享数据"!
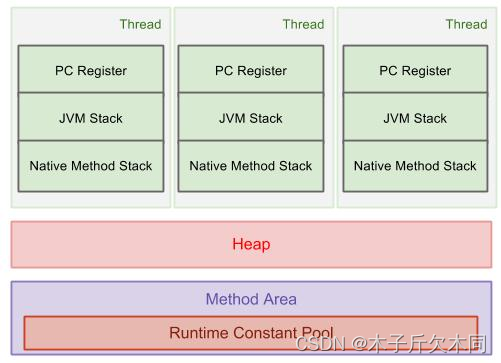
count 这个变量就是在堆上. 因此可以被多个线程共享访问.
4.3.2 原子性
什么是原子性
我们把一段代码想象成一个房间,每个线程就是要进入这个房间的人。如果没有任何机制保证,A进入房间之后,还没有出来;B 是不是也可以进入房间,打断 A 在房间里的隐私。这个就是不具备原子性的。
那我们应该如何解决这个问题呢?是不是只要给房间加一把锁,A 进去就把门锁上,其他人是不是就进不来了。这样就保证了这段代码的原子性了。有时也把这个现象叫做同步互斥,表示操作是互相排斥的。
一条 java 语句不一定是原子的,也不一定只是一条指令
比如刚才我们看到的 n++,其实是由三步操作组成的:
- 从内存把数据读到 CPU
- 进行数据更新
- 把数据写回到 CPU
不保证原子性会给多线程带来什么问题
如果一个线程正在对一个变量操作,中途其他线程插入进来了,如果这个操作被打断了,结果就可能是错误的。
这点也和线程的抢占式调度密切相关. 如果线程不是 "抢占" 的, 就算没有原子性, 也问题不大。
4.3.3 可见性
可见性指一个线程对共享变量值的修改,能够及时地被其他线程看到。
Java 内存模型 (JMM): Java虚拟机规范中定义了Java内存模型.
目的是屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的并发效果.
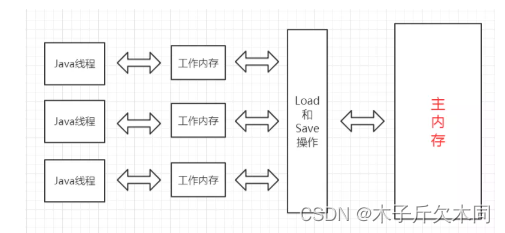
- 线程之间的共享变量存在 主内存 (Main Memory).
- 每一个线程都有自己的 "工作内存" (Working Memory) .
- 当线程要读取一个共享变量的时候, 会先把变量从主内存拷贝到工作内存, 再从工作内存读取数据.
- 当线程要修改一个共享变量的时候, 也会先修改工作内存中的副本, 再同步回主内存.
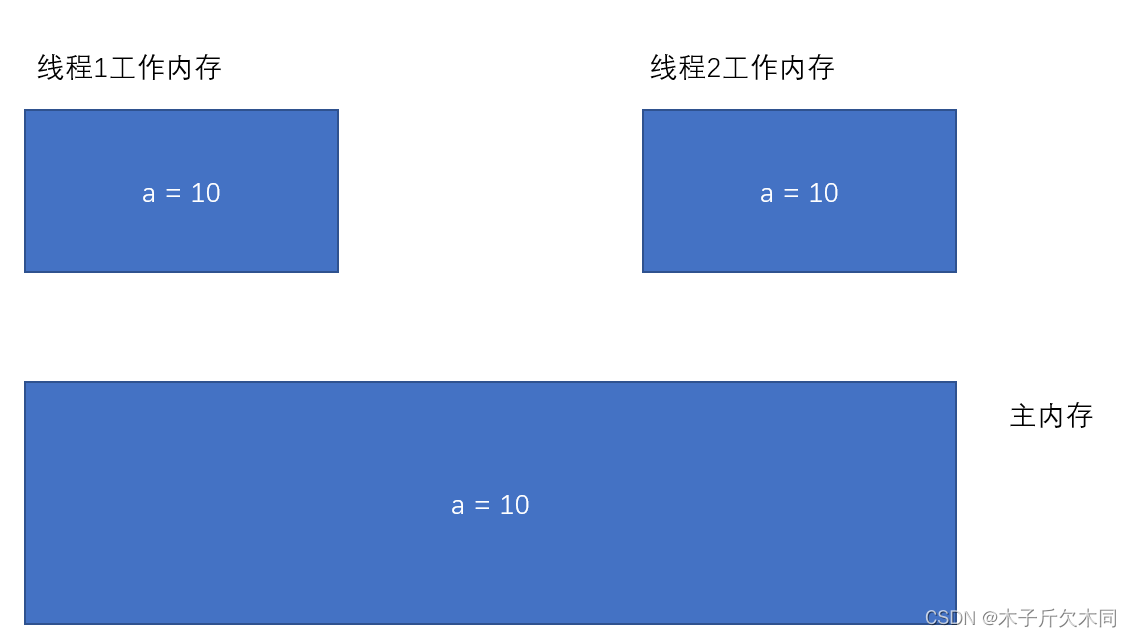
由于每个线程有自己的工作内存, 这些工作内存中的内容相当于同一个共享变量的 "副本". 此时修改线程1 的工作内存中的值, 线程2 的工作内存不一定会及时变化.
1) 初始情况下, 两个线程的工作内存内容一致.
2) 一旦线程1 修改了 a 的值, 此时主内存不一定能及时同步. 对应的线程2 的工作内存的 a 的值也不一定能及时同步.
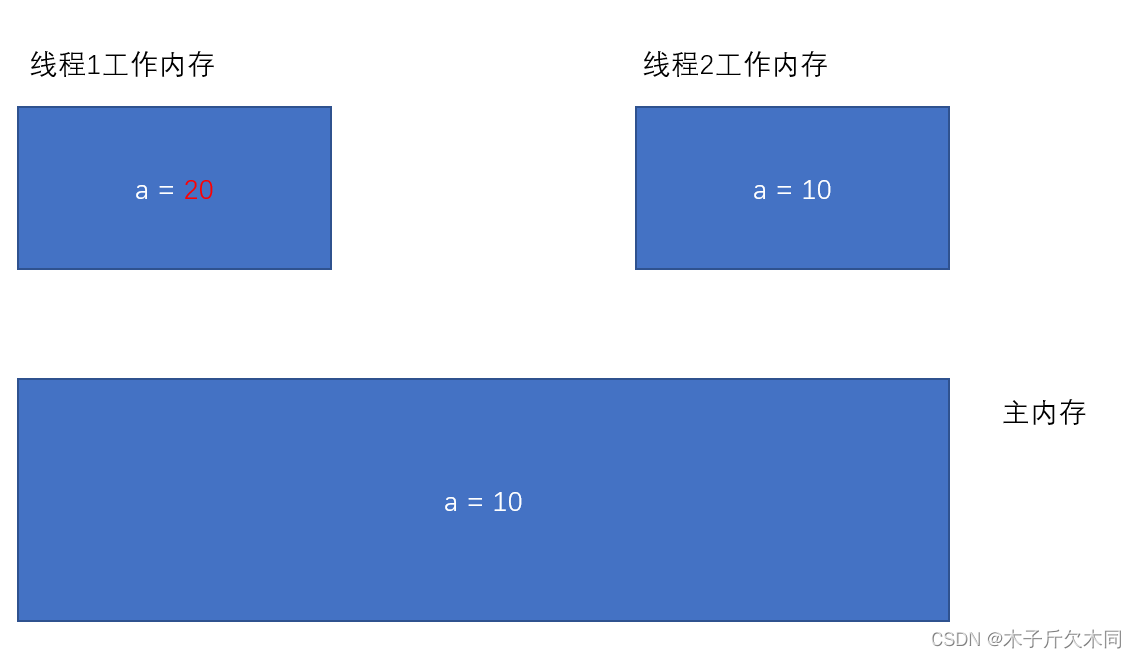
这个时候代码中就容易出现问题.
此时引入了两个问题:
- 为啥要整这么多内存?
- 为啥要这么麻烦的拷来拷去?
1) 为啥整这么多内存?
实际并没有这么多 "内存". 这只是 Java 规范中的一个术语, 是属于 "抽象" 的叫法.
所谓的 "主内存" 才是真正硬件角度的 "内存". 而所谓的 "工作内存", 则是指 CPU 的寄存器和高速缓存.
2) 为啥要这么麻烦的拷来拷去?
因为 CPU 访问自身寄存器的速度以及高速缓存的速度, 远远超过访问内存的速度(快了 3 - 4 个数量级, 也就是几千倍, 上万倍)
比如某个代码中要连续 10 次读取某个变量的值, 如果 10 次都从内存读, 速度是很慢的. 但是如果只是第一次从内存读, 读到的结果缓存到 CPU 的某个寄存器中, 那么后 9 次读数据就不必直接访问内存了,效率就大大提高了
那么接下来问题又来了, 既然访问寄存器速度这么快, 还要内存干啥??
答案就是一个字: 贵

值的一提的是, 快和慢都是相对的. CPU 访问寄存器速度远远快于内存, 但是内存的访问速度又远远快于硬盘。
对应的, CPU 的价格最贵, 内存次之, 硬盘最便宜。
4.3.4 代码顺序性
什么是代码重排序
一段代码是这样的:
- 去前台取下 U 盘
- 去教室写 10 分钟作业
- 去前台取下快递
如果是在单线程情况下,JVM、CPU指令集会对其进行优化,比如,按 1->3->2的方式执行,也是没问题,可以少跑一次前台,这种叫做指令重排序。
编译器对于指令重排序的前提是 "保持逻辑不发生变化". 这一点在单线程环境下比较容易判断, 但是在多线程环境下就没那么容易了, 多线程的代码执行复杂程度更高, 编译器很难在编译阶段对代码的执行效果进行预测, 因此激进的重排序很容易导致优化后的逻辑和之前不等价.
重排序是一个比较复杂的话题, 涉及到 CPU 以及编译器的一些底层工作原理, 此处不做过多讨论
4.4 解决之前的线程不安全问题
public class Thread7 {
static int count = 0;
public static void main(String[] args) {
Object o = new Object();
Thread t1 = new Thread(() -> {
synchronized (o) {
for(int i = 0;i < 5000;i++){
count++;
}
}
});
Thread t2 = new Thread(() -> {
synchronized (o) {
for(int i = 0;i < 5000;i++){
count++;
}
}
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(count);
}
}