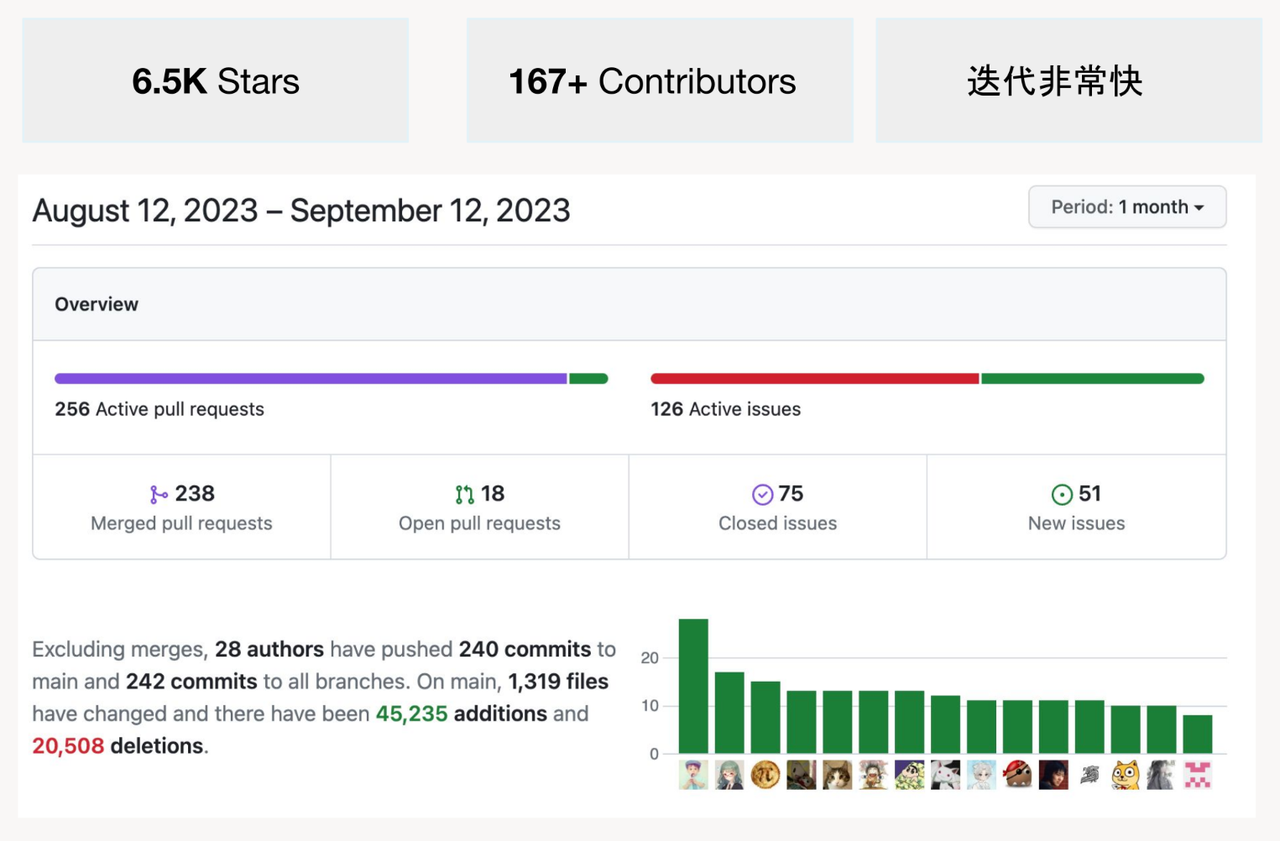
目录
一、了解网络爬虫
二、Python与网络爬虫
三、批量采集任务的实现
1.确定采集网站及关键词
2.安装相关库
3.发送请求并获取响应
4.解析HTML文档
5.提取文章内容
6.保存文章内容
7.循环采集多篇文章
8.增加异常处理机制
9.优化代码性能
四、注意事项
总结
在当今信息化社会,数据已经成为我们决策和发展的重要资源。网络爬虫作为一种自动化的数据采集工具,能够快速、大量地获取所需数据。本文将详细介绍如何使用Python编写爬虫程序,批量采集网络数据,并对其进行深入分析和利用。

一、了解网络爬虫
网络爬虫(也称网络蜘蛛、网络机器人)是一种自动化程序,能够在互联网上自动抓取、分析和整理数据。根据其实现的技术,爬虫可以分为广度优先搜索、深度优先搜索、启发式搜索等。其中,广度优先搜索适合于数据量较大、链接结构较简单的网站,而深度优先搜索则适用于数据量较小、链接结构复杂的网站。
二、Python与网络爬虫
Python作为一种易学易用的编程语言,在爬虫领域有着广泛的应用。其丰富的第三方库,如requests、bs4、re等,为编写网络爬虫提供了极大的便利。在Python中,我们可以使用requests库发送HTTP请求,并获取响应;使用bs4库解析HTML文档;使用re库进行正则表达式匹配等。
三、批量采集任务的实现
1.确定采集网站及关键词
在开始编写爬虫程序之前,我们需要明确需要采集的网站及相应的关键词。例如,我们需要采集一些新闻网站的内容,那么我们可以通过搜索相应的关键词,找到相应的新闻网站,并记录下这些网站的URL。
2.安装相关库
在编写Python脚本之前,我们需要先安装相关库以便于后续操作。常用的库包括requests、bs4、re等。这些库可以通过pip命令进行安装。例如:pip install requests beautifulsoup4 re。

3.发送请求并获取响应
在Python中,我们可以使用requests库中的get方法来发送请求,并通过response.text属性获取相应的HTML文档。例如:
import requests
url = "http://example.com"
response = requests.get(url)
html_doc = response.text4.解析HTML文档
获取HTML文档后,我们可以使用BeautifulSoup库中的BeautifulSoup方法来解析HTML文档,并通过find、find_all等方法来获取所需的元素。例如:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, "html.parser")
title = soup.find("title").string5.提取文章内容
在获取到所需的元素后,我们可以使用正则表达式等方法来提取所需内容,例如文章的标题、正文等。例如:
import re
content = soup.find("div", {"class": "content"}).get_text()
pattern = r"title:(.*?)link:(.*?)</a>"
matches = re.findall(pattern, content)6.保存文章内容
在提取出文章内容后,我们可以使用Python内置的open方法来创建文件,并将文章内容写入到文件中。例如:
with open("articles.txt", "a") as f:
f.write(str(matches))7.循环采集多篇文章
编写完一个简单的采集脚本后,我们还需要考虑如何循环采集多篇文章。我们可以使用for循环等方式来实现。例如:
import time
urls = ["http://example.com/article/1", "http://example.com/article/2", "http://example.com/article/3"]
for url in urls:
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
# 进行解析和保存操作
time.sleep(1) # 避免过于频繁的请求被屏蔽8.增加异常处理机制
在编写脚本时,我们需要考虑到可能出现的异常情况,例如网络连接失败、HTML文档解析失败等。因此需要在脚本中增加相应的异常处理机制。例如:
try:
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
# 进行解析和保存操作
except requests.exceptions.RequestException as e:
print(f"Failed to request {url}: {e}")9.优化代码性能
在编写脚本时,我们还需要考虑代码性能问题。例如,如何降低网络请求次数、如何减少页面解析时间等。以下是一些优化代码性能的方法:
a.批量请求:我们可以使用requests库的Session对象来批量发送请求。这样可以在一次网络请求中获取多个页面内容,减少网络请求次数。
import requests
from bs4 import BeautifulSoup
with requests.Session() as session:
urls = ["http://example.com/article/{}/".format(i) for i in range(1, 101)]
for url in urls:
response = session.get(url)
soup = BeautifulSoup(response.text, "html.parser")
# 进行解析和保存操作b.使用多线程或异步IO:我们可以使用Python的多线程或异步IO库,如asyncio、tornado等,以提高代码性能。这样可以在同一时间处理多个网络请求,提高采集效率。

c.使用代理IP:如果需要大量采集数据,我们可以使用代理IP来避免IP被封禁。代理IP可以购买或使用免费的代理IP,但免费的代理IP不太稳定且速度较慢。
d.使用缓存:我们可以使用Python的缓存库,如Beaker、cachetools等,将频繁请求的HTML文档缓存起来,避免重复的网络请求,提高采集效率。
四、注意事项
- 遵守法律法规:在编写爬虫程序时,必须遵守法律法规和网站的使用规则。不得擅自采集他人网站数据,不得将爬取的数据用于非法用途。
- 尊重网站隐私:在编写爬虫程序时,要尊重网站的隐私和安全。不得随意泄露网站的敏感信息,不得将爬取的数据用于商业用途。
- 注意爬取频率:在编写爬虫程序时,要注意爬取的频率和量级。不得频繁地请求网站,不得大量地爬取网站数据,以免对网站的正常运营造成影响。
- 及时调整策略:在编写爬虫程序时,要根据网站的结构和内容及时调整策略。对于不同的网站,要采用不同的爬取方法和策略,以保证爬取的准确性和效率。
总结
网络爬虫作为一种高效的数据采集工具,在互联网时代具有广泛的应用前景。掌握网络爬虫技术意味着能够快速获取大量数据,为各行各业提供强有力的支持。未来,随着人工智能和大数据技术的不断发展,网络爬虫将在更多领域发挥重要作用。