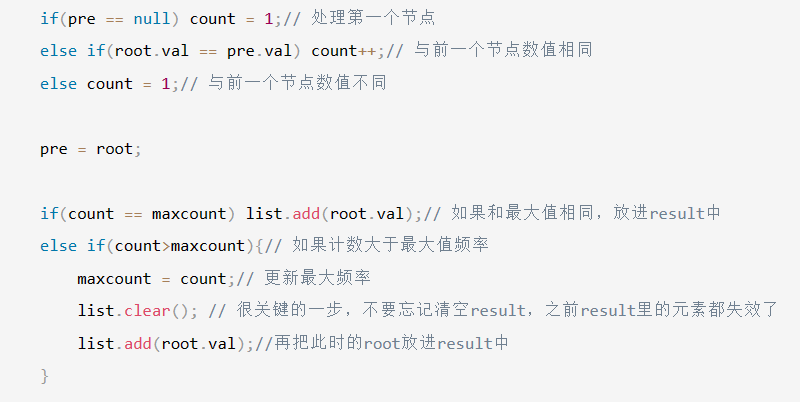
最近在恶补Freya产品100/200/400/800GE AN/LT端口自适应和链路学习的知识,主要用在基于56Gb/s 的400G,112GGb/s的800G,和1.6Tbps高速接口上,当其使用DAC/AEC/ACC cable时,如果实现端口性能的自动调整。好奇的去拓展了下,目前51.2T级别的大厂们,都怎么宣传自己的芯片产品的,然后就爬了下Marvell Teralynx 10,Cisco Silicon ONE ,Broadcom Tomahawk 5的相关介绍。
以下附上机翻的版本和原文链接。
我关注的信息有
- 带宽带来的效能提供(供电/散热/布线/器件各方面)1PCS x 51.2T = 12PCS x 12.8T
- 都是基于5nm
- 对SONiC的支持/可编程
- 可遥测/管理功能的增强
- 低延迟/确定性延迟
- 512x112G SerDes,32 x 1.6T、64 x 800G和128 x 400G
- Long Reach SerDes(3米DAC / 5米DAC)
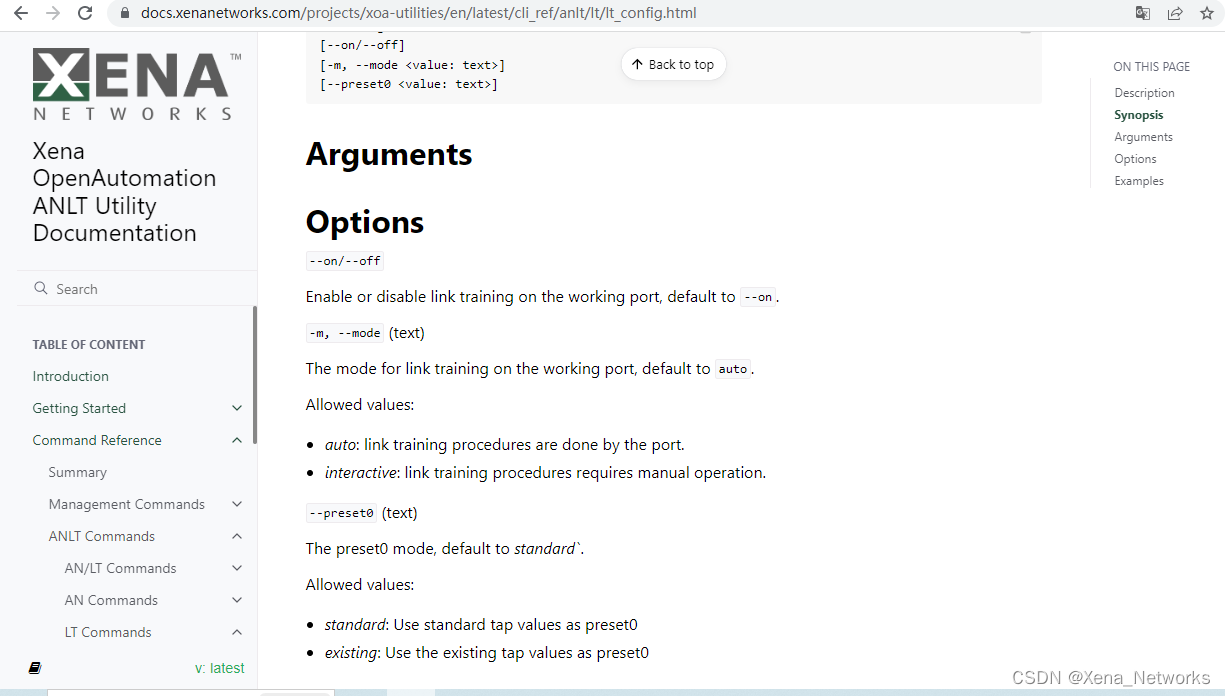
xoa-utils[123456][port0/2] > lt config --on --preset0=existing --mode=interactive
LT configuration to be on port 2/0
[SHADOW CONFIG]
Auto-negotiation : off (allow loopback: no)
Link training : on (interactive) (preset0: existing tap values)
xoa-utils[123456][port0/2] >
AN Functionalities
- Enable/disable auto-negotiation
- Auto-negotiation trace log, provides AN trace log for debugging and troubleshooting.
- Auto-negotiation status, provides the following AN status:
- Received and transmitted number of Link Code Words (Base Pages), message pages, and unformatted pages
- Number of HCD (Highest Common Denominator) failures
- Number of FEC failures
- Number of LOS (Loss of Sync) failures
- Number of timeouts
- Number of successes
- Duration of AN in microseconds
LT Functionalities
-
Enable/disable link training
-
Allow/deny link training loopback
-
Enable/disable link training timeout
-
Tuning link partner TX EQ coefficient, use presets as a starting point to tune link partner TX EQ coefficients per serdes, increment and decrement of coefficients c(-3), c(-2), c(-1), c(0), c(1).
-
Configure local TX EQ coefficients
-
Monitor local TX EQ coefficients
-
Link training trace log per serdes
-
Link training status per serdes, provides the following LT status:
- Number of lost locks
- Local value of coefficient (per coefficient)
- RX number of increment/decrement requests from link partner (per coefficient)
- RX number of EQ coefficient request limits reached from link partner (per coefficient)
- RX number of EQ request limits reached from link partner (per coefficient)
- RX number of coefficients not supported from link partner (per coefficient)
- RX number of coefficients at limit from link partner (per coefficient)
- TX number of increment/decrement requests to link partner (per coefficient)
- TX number of EQ coefficient request limits reached to link partner (per coefficient)
- TX number of EQ request limits reached to link partner (per coefficient)
- TX number of coefficients not supported to link partner (per coefficient)
- TX number of coefficients at limit to link partner (per coefficient)
- Duration of LT in microseconds
- PRBS total error bits
- PRBS total error bits
- PRBS bit error rate
- Local frame lock status
- Link partner frame lock status
美满Marvell推出业界延迟最低的可编程交换机 51.2T Teralynx 10
作者:Marvell 产品营销高级总监 Amit Sanyal
时间:2023年3月2日
原文链接: https://blogs.marvell.com/2023/03/51-2t-teralynx-10-industrys-lowest-latency-programmable-switch/
如果您是 ChatGPT 1 亿多月活用户中的一员,或者曾经使用过谷歌的 Bard 或微软的必应人工智能,那么您就证明人工智能已经进入了主流消费市场。
而进入大众消费市场的人工智能必然会进入企业这个更大的市场。目前有数百家生成式人工智能初创公司正在为实现这一目标而努力。而那些负责提供这些人工智能工具的企业--云数据中心运营商--正在投入巨资,以满足当前和预期的需求。
当然,推动未来基础设施升级周期的不仅仅是最新的人工智能语言模型。运营商也将同样关注通用云基础设施的改进,并采取措施进一步自动化和简化操作。
Teralynx 10
为了帮助运营商实现扩展和效率目标,Marvell今天推出了Teralynx® 10,这是一款51.2 Tbps的可编程5纳米单片交换机芯片,旨在解决运营商带宽爆炸的问题,同时满足严格的每比特功耗和成本要求。它适用于下一代数据中心网络中的叶片和脊柱应用,以及 AI/ML 和高性能计算 (HPC) Fabric。
单个 Teralynx 10 可替代12个12.8 Tbps 产品,后者是最后一个得到广泛部署的产品。由此带来的节能效果令人印象深刻:同等容量下,功耗降低了 80%。
正如我在上一篇文章中提到的,AI/ML、HPC 和其他分布式应用需要的不仅仅是带宽来获得最佳性能。它们需要超低的确定性延迟,以最大限度地减少联网时间,并疏通会延迟作业完成并降低云服务收入的网络瓶颈。
Teralynx 架构就是为应对这样的挑战而专门设计的。我之所以说 "架构",是因为 Teralynx 10 是最新的芯片,采用了 Teralynx 独有的通用超低延迟交换机和缓冲结构--这是所有可编程交换机中最低的。除了低延迟外,Teralynx 10 还支持拥塞感知路由和实时流遥测,使网络能够自动调整和自我修复。通过线速可编程性,可以添加新的协议和功能,以满足人工智能/移动通信不断发展的要求。
以下是功能和优势的简要介绍:
久经考验、坚固耐用的 112G SerDes
Teralynx 10 具有 512 个Long reach(LR)112G SerDes。有了它,交换机系统供应商可以开发多种交换机配置,如32 x 1.6T、64 x 800G和128 x 400G,从而灵活地满足每个运营商的独特需求。
可编程转发
Teralynx 10 提供全面的数据中心功能集,包括 IP 转发、隧道、丰富的 QoS 和强大的 RDMA。Teralynx 10 还提供可编程的灵活转发功能,使运营商能够根据网络需求的变化,在不影响吞吐量、延迟或功耗的情况下,对新的数据包转发协议进行编程。
超低延迟结构
Teralynx 10 基于下一代可编程交换机中延迟最低的 Fabric 架构。这种低延迟有助于疏通网络瓶颈,最大限度地减少联网时间,并缩短分布式高要求应用(如高性能计算和机器学习培训)的作业完成时间。这有助于运营商最大限度地利用其计算资源以及与这些资源相关的收入。
Teralynx® Flashlight™ 高级遥测技术
Teralynx 10 支持广泛的实时网络遥测,包括 P4 带内网络遥测 (INT)。这些功能实现了预测性分析、更快的问题解决和更高的自动化程度,所有这些都降低了运营支出,增加了网络正常运行时间。
Teralynx 软件
Teralynx 10 的软件与 Teralynx 7 完全兼容,最大限度地减少了现有客户的过渡时间和成本。软件工具包包括 SDK 和 SAI,便于 NOS 移植,具有强大、高性能和可移植性。
Teralynx 10 简介
与目前的 12.8T 交换机相比,大大降低了功耗和成本。
减少 AI/ML 等分布式应用在联网方面花费的时间,以提供最佳应用性能。
帮助客户实现自动化操作,快速排除故障并解决网络问题,从而降低运营成本,提高应用可用性。
继 Teralynx 7 之后,Teralynx 7 为 500 多万个 400G 数据中心交换机端口提供支持。
Teralynx 10 将于第二季度出样。我们期待着继续与客户合作,并在产品出样时分享更多信息。
思科 Silicon One 突破 51.2 Tbps 大关
作者:拉克什-乔普拉
时间:2023,6,20
原文链接:Cisco Silicon One Breaks the 51.2 Tbps Barrier - Cisco Blogs
2019 年 12 月,我们大胆宣布,我们将永远改变互联网经济,以前所未有的速度推动创新。这些都是雄心勃勃的宣言,许多人持观望态度也就不足为奇了。从那时起,我们以越来越快的速度不断创新,以满足客户需求的创新解决方案引领行业发展。
今天,在推出 Cisco Silicon One™ 仅三年半之后,我们自豪地宣布推出第四代设备 Cisco Silicon One G200 和 Cisco Silicon One G202,现在我们正在向客户提供样品。通常情况下,每隔 18 到 24 个月就会推出新一代产品,这表明我们的创新速度是普通硅产品开发速度的两倍。
Cisco Silicon One G200 提供了我们统一架构的优势,并特别关注基于以太网的增强型人工智能/机器学习(AI/ML)和网络规模脊柱部署。Cisco Silicon One G200 是一款 5 纳米、51.2 Tbps、512 x 112 Gbps 的串行器-解串器(SerDes)设备。它是一种独特的可编程、确定性、低延迟设备,具有先进的可视性和控制能力,是网络规模网络的理想选择。
Cisco Silicon One G202 为仍希望使用 50G SerDes 将光学器件连接到交换机的客户带来了类似的优势。它是一款 5 纳米、25.6 Tbps、512 x 56 Gbps SerDes 设备,具有与 Cisco Silicon One G200 相同的特性,但性能只有后者的一半。
为了实现 Cisco Silicon One 的愿景,我们必须对关键技术进行投资。七年前,思科开始投资于我们自己的高速 SerDes 开发,并立即意识到随着速度的提高,业界必须转向基于模数转换(ADC)的 SerDes。SerDes 是高性能计算和人工智能部署中网络互连的基本构件。今天,我们很高兴地宣布,我们的下一代超高性能、低功耗 112 Gbps ADC SerDes 能够支持 4 米直连电缆 (DAC)、传统光学器件、线性驱动光学器件 (LDO) 和协同封装光学器件 (CPO),同时最大限度地减少硅芯片面积和功耗。

Cisco Silicon One G200 和 G202 在业内具有独特的定位,其先进的功能可优化 AI/ML 工作负载的实际性能,同时通过重大创新降低网络的成本、功耗和延迟。
思科 Silicon One G200 是基于以太网的 AI/ML 网络的理想解决方案,原因有以下几点:
~ 凭借业界密度最高的交换机(一台设备上有 512 x 100GE 以太网端口),客户可以构建一个 32K 400G GPU 的 AI/ML 集群,其两层网络所需的光学器件减少 50%,交换机减少 40%,网络层减少 33%--大大减少了 AI/ML 集群对环境的影响。每年可节省多达 900 万千瓦时,根据美国环境保护署的数据,这相当于每年减少 6000 多吨二氧化碳 (CO2e) 或燃烧 730 万磅煤炭。
~ 先进的拥塞感知负载平衡技术使网络能够避免传统的拥塞事件。
~ 先进的数据包喷射技术可最大限度地减少网络拥塞热点。
~ 先进的基于硬件的链路故障恢复技术,即使在出现故障的情况下,也能在大规模网络中提供最佳性能。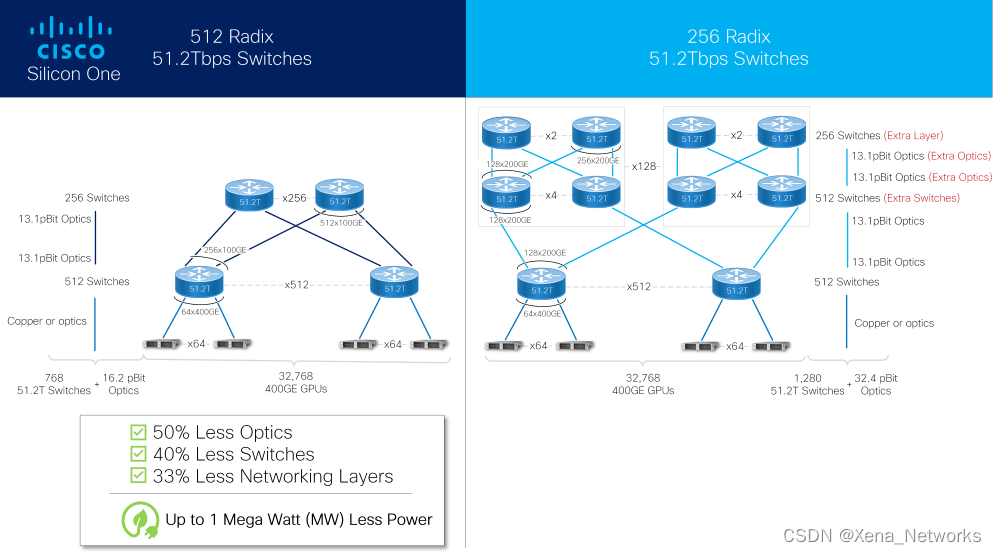
思科 Silicon One 创新
下面将详细介绍我们与 Cisco Silicon One 相关的一些创新:
融合架构
~ Cisco Silicon One 提供了一种可在客户网络中部署的架构,从路由角色到网络规模的前端网络,再到网络规模的后端网络,从而大大缩短了部署时间,同时通过实现融合基础架构最大限度地降低了持续运营成本。
~ 使用通用的软件开发工具包(SDK)和标准交换机抽象接口(SAI)层,客户只需将思科 Silicon One 环境移植到他们的网络操作系统(NOS)上一次,即可在不同的网络角色中利用这项投资。
~ 与我们的所有设备一样,Cisco Silicon One G200 拥有一个完全统一的大型数据包缓冲区,可优化大型网络规模网络中的突发吸收和吞吐量。这可以通过吸收突发而不是生成优先流控制来最大限度地减少线头阻塞。
优化整个价值链
~ 思科 Silicon One G200 的密度比其他具有 512 以太网 MAC 的解决方案高出两倍,使客户能够通过消除网络层来显著降低网络部署的成本、功耗和延迟。
~ 凭借我们内部开发的新一代 SerDes 技术,思科 Silicon One G200 设备能够驱动 43 dB 的凸块到凸块通道,从而实现共同封装光学器件 (CPO)、线性可插拔对象 (LPO),并使用 4 米长的 26 AWG 铜缆,这远远超出了机架内最佳连接的 IEEE 标准。
~ 与已经优化的思科 Silicon One G100 设备相比,Silicon One G200 的能效提高了两倍以上,延迟降低了两倍。
~ 设备的物理设计和布局采用系统优先的方法,允许客户降低系统风扇的运行速度,从而大幅降低系统功耗。
创新的负载平衡和故障检测
~ 支持非相关、加权等成本多路径(WECMP)和等成本多路径(ECMP)负载平衡功能,其接近理想的特性有助于避免散列极化,即使在大规模网络中也是如此。
~ 针对有状态 ECMP、流量和小流量的拥塞感知负载平衡功能,可实现最佳网络吞吐量,同时优化流量完成时间和作业完成时间(JCT)。
~ 拥塞感知无状态数据包喷射可通过使用所有可用网络带宽(无论流量特性如何)实现接近理想的 JCT。
~ 支持基于链路故障的硬件数据包重新分配,使 Cisco Silicon One G200 能够优化大规模网络的实际吞吐量。
先进的数据包处理器
~ Cisco Silicon One G200 采用业界首款完全定制的 P4 可编程并行数据包处理器,每秒可启动超过 4350 亿次查询。它以全速支持 SRv6 Micro-SID (uSID) 等高级功能,并可通过完整的运行到完成处理功能进行扩展,以处理更复杂的数据流。这种独特的数据包处理架构具有确定性低延迟和低功耗的灵活性。
深度可见性和分析
~ 可编程处理器支持标准的和新兴的网络规模带内遥测标准,提供业界领先的网络可视性。
~ 嵌入式硬件分析仪通过事件前后的时间流信息记录来检测微爆,使网络运营商能够利用硬件时间可视性对网络事件进行事后分析。
新一代网络能力
业界各自为政的时代已经一去不复返了。思科 Silicon One 采用统一的架构,消除了长期以来定义我们行业的硬性分界线。客户不再需要担心因过去的想象力和技术限制而造成的架构差异。如今,客户可以在其网络中以多种方式部署 Cisco Silicon One。
通过 Cisco Silicon One G200 和 G202 设备,我们利用专为脊柱和 AI/ML 部署而优化的高带宽设备扩大了 Cisco Silicon One 的覆盖范围。客户可以通过部署数量更少、效率更高的设备来节约成本,利用超长距离 SerDes 享受新的部署拓扑,利用创新的负载平衡和故障发现技术提高 AI/ML 工作性能,利用先进的遥测和硬件分析仪提高网络可调试性。
如果您自我们于 2019 年 12 月首次发布思科 Silicon One 以来就一直在关注,就不难发现这仅仅是个开始。我们期待继续加速为客户增值。
博通Broadcom 推出业界最高带宽交换机芯片 Tomahawk 5,以加速 AI/ML 工作负载
时间:2022年8月16日
原文链接:
https://www.broadcom.com/company/news/product-releases/60456
全球首款 51.2 Tbps 以太网交换机芯片
美国加利福尼亚州圣何塞市2022年8月16日(环球新闻电讯)--博通公司(纳斯达克股票代码:AVGO)今天宣布,该公司已交付StrataXGS® Tomahawk® 5交换机系列,在单个单片设备中提供51.2兆位/秒的以太网交换容量,是目前市场上任何其他交换机芯片带宽的两倍。
"博通公司高级副总裁兼核心交换事业部总经理Ram Velaga表示:"在我们发布业界首款25 Tbps交换机Tomahawk 4两年后,我们又推出了全球首款51.2 Tbps交换机,这充分证明了博通团队出色的执行力和创新能力。"自 2014 年推出 Tomahawk 1 以来,Broadcom 始终坚持大约每两年将带宽翻一番。随着今天第五代 Tomahawk 系列的推出,我们可以自豪地说,一台 Tomahawk 5 就可以取代网络中的四十八台 Tomahawk 1 交换机,从而使功耗降低 95% 以上。我们为客户、合作伙伴和工程师实现这一目标而喝彩"。
在数据中心对网络带宽的需求持续大幅增长的同时,将通用计算和存储的网络基础设施与 AI/ML 计算的网络基础设施统一起来的动力也十分强劲。AI/ML 训练集群推动了对具有高带宽连接性、高密度和较短作业完成时间的 Fabric 的需求,同时还能以较高的网络利用率运行。
以太网为统一网络基础设施提供了最佳解决方案,它具有功耗最低、带宽最高、密度最大、SerDes 速度最快的特点,而且带宽每 18 到 24 个月就可翻一番。以太网的这些优势与其庞大而充满活力的生态系统相结合,为 AI/ML 和云规模基础设施提供了每瓦和每美元最高的性能互连。
为实现下一代统一网络,Broadcom 现已推出 Tomahawk 5 系列。Tomahawk 5 具有单通 VxLAN 路由和桥接等功能,对高效利用大型数据中心的大规模共享基础设施至关重要,可提供 AI/ML 工作负载虚拟化。Tomahawk 5 提供 Broadcom 认知路由、高级共享数据包缓冲、可编程带内遥测和基于硬件的链路故障切换等功能,对最大限度地缩短 AI/ML 工作负载的作业完成时间 (JCT) 至关重要。
Tomahawk 5 的 "认知路由"(Cognitive Routing)可自动、动态地为穿过交换机的每个数据流选择系统中负载最轻的链路,从而提高网络链路利用率。这一点对于人工智能/人工智能工作负载尤为重要,因为这些工作负载通常既有寿命短的小鼠流,也有寿命长、带宽高且熵值低的大象流。Tomahawk 5 包括实时动态负载平衡,可跟踪交换机和网络下游所有链路的利用率,为每个流量确定最佳路径。它还能监控硬件链路的健康状况,并自动引导流量远离故障链路。这些功能大大提高了网络利用率,减少了拥塞,从而缩短了 JCT。
通过控制每个源注入网络的流量速率,最大限度地减少网络拥塞,对改善 JCT 也很重要。由于网络运营商在其端点(如商家或定制网卡)采用了各种不同的拥塞控制算法,因此 Tomahawk 5 对实时流量和网络探测器提供了广泛的可编程带内遥测。实时元数据可在流量穿越网络时以线路速率插入流量,以收集队列大小、数据包延迟、交换机利用率和其他各种客户可选指标的遥测数据。这些元数据可用于精确的端到端网络拥塞控制。
为了实现最低功耗和最低成本的物理连接,Tomahawk 5 支持直接连接铜缆 (DAC)、前面板可插拔光学器件和共封装光学器件的直接 100G PAM4 接口。灵活、长距离的 Tomahawk 5 SerDes 可为机架内的所有设备甚至机架之间提供 DAC 连接,而无需使用重定时器或其他有源元件。它还可以直接连接到广泛的标准前面板可插拔光模块生态系统。
此外,利用 Broadcom 领先的硅光子学和封装技术,Tomahawk 5 将使用 Broadcom 的硅光子学小片封装 (SCIP) 平台提供协同封装光学器件,从而将光连接所需的功率降低 50%以上。由于相同的交换芯片可提供所有这些选项,客户可为其集群内、集群间和 DC 间的每个部分选择最佳的 I/O 解决方案。
StrataXGS Tomahawk 5 系列的主要优势:
通过 64 个 800GbE 交换和路由端口,实现下一代统一数据中心基础架构。
通过单路 VxLAN 路由和桥接实现通用计算和 AI/ML 工作负载的虚拟化。
使用 512 个业界最高性能、最灵活、最长距离的 100G PAM4 SerDes 实例,提供无与伦比的物理 I/O 选项。
高精度 PTP 和 SyncE 时间同步。
六个片上 ARM 处理器,用于高带宽、完全可编程的流式遥测和复杂的嵌入式应用,如片上统计汇总。
无与伦比的能效,采用单片 5 纳米芯片实现。
"Wheeler's Network 首席分析师鲍勃-惠勒(Bob Wheeler)表示:"尾部延迟是分布式 AI/ML 训练的关键网络性能指标。"Broadcom认识到了传统的基于哈希值的负载均衡对这些工作负载的局限性,并在Tomahawk 5中增加了具有动态小流量转向功能的认知路由。超大规模运营商现在可以统一他们的网络结构,消除仅用于培训集群的专用互连。"
与普通计算和存储相比,AI/ML 培训集群具有独特的通信模式。为了最大限度地缩短作业完成时间,Tomahawk 5 为这些工作负载和网络拓扑增加了特定功能。
StrataXGS Tomahawk 5 系列针对 AI/ML 的主要功能:
全球最高的 200GbE 端口密度: 单芯片支持 256 个端口,实现了扁平、低延迟的 AI/ML 集群。
业界最先进的 51.2 Tbps 共享缓冲区架构,为 RoCEv2 和其他新 RDMA 协议提供最高性能和最低尾延迟。
先进的 Broadcom 认知路由、动态负载平衡和端到端拥塞控制功能支持,专门用于处理 AI/ML 工作负载中典型的大流量、低熵流。
支持 Clos 和非 Clos 拓扑,如 torus、Dragonfly、Dragonfly+ 和 Megafly。
基于硬件的链路故障切换,可提高网络弹性并减少 JCT。
Tomahawk 系列与 Trident 和 Jericho 交换机系列一样,都是 Broadcom 为不同网络应用提供优化交换机架构的三管齐下战略的一部分。所有这些设备共享一个通用编程接口,因此客户可以轻松地在不同平台上利用他们的软件开发工作。
Broadcom 坚定地致力于开放式网络,为战斧系列的所有五代产品提供了 SAI(交换机抽象接口)和 Broadcom SDK 开放式 API。Broadcom 是 SAI 和 SONiC 网络操作系统的最大贡献者之一。为加快部署速度,Tomahawk 5 芯片支持 SAI 和 Broadcom SDK,并提供全面的网络和设备仿真工具套件。
行业引言:
阿里云智能网络基础设施负责人 Dennis Cai
"阿里巴巴已在整个网络基础设施中部署了多代基于 Tomahawk 的平台。在 Tomahawk 5 中,Broadcom 再次提供了强大的产品,其带宽、radix、能效和产品质量都无与伦比。我们很荣幸能与 Broadcom 合作开发 Tomahawk 5,利用可编程带内遥测等一些尖端功能来构建我们可预测的超性能集群,并满足我们指数级增长的 AI/ML 工作负载和高性能存储需求。
AT&T 高级副总裁兼网络首席技术官 Igal Elbaz
"AT&T在推出5G基础设施方面的领导地位需要像博通这样的战略合作者提供高质量的商用芯片产品,以支持我们在开发强大的开放式分类白小姐一肖中特马生态系统方面的持续努力。这些及时上市的创新解决方案还可部署在我们整个网络的任何节点中。AT&T 对 Broadcom 在单芯片 Tomahawk 5 芯片方面取得的又一行业第一表示赞赏。
百度杰出工程师兼网络架构主管 Gang Cheng
"Broadcom 的最新 Tomahawk 5 产品是一项令人印象深刻的技术成就。我们很高兴看到商用芯片生态系统的持续增长,从而使百度能够继续构建世界一流的网络基础设施。
字节跳动系统部总经理王云雀
"我们的短视频平台在过去几年的发展表明了在数据中心拥有可扩展、高带宽、高性能和高效网络的重要性。Tomahawk 5将继续实现这些指标,ByteDance非常高兴地看到Tomahawk 5在商用芯片生态系统中已经准备就绪,这将使ByteDance能够开发新一代交换机和网络基础设施。"
微软Azure网络技术研究员兼公司副总裁Dave Maltz
"在微软,我们相信商用芯片、硬件独立性以及开源协议和管理堆栈是运行融合超大规模数据中心工作负载(包括计算、存储和 AI/ML)的最佳解决方案。我们祝贺博通继续为实现这一愿景做出贡献,并取得了里程碑式的成就,以 51.2 Tbps 的速度对 Tomahawk 5 进行了采样,同时在硅片和仿真模型上为 SAI 提供了强大的支持。Broadcom 是 SONiC 和 SAI 开源计划的主要贡献者之一,Tomahawk 5 代表了支持 SAI 和 SONiC 的 Tomahawk 系列的第五代产品。
微软Azure硬件架构技术研究员兼公司副总裁Steve Scott
"Microsoft Azure 为各种规模的 HPC 和 AI/ML 工作负载提供了一流的基础架构。Broadcom 的 Tomahawk 5 为满足下一代 HPC 和 AI/ML 需求提供了重要优势。Tomahawk 5在开放和创新的以太网生态系统框架内推进了支持HPC和AI/ML网络需求所需的规模、遥测和高级功能"。
腾讯云副总裁邹思源
"随着腾讯不断扩展我们的全球基础设施,与博通合作推出战斧5等突破性产品对我们来说至关重要。我们很高兴看到博通将同时提供 DAC 和 CPO 连接。毫无疑问,Tomahawk 5 将成为我们下一代低成本高性能云网络的基石"。
Tenstorrent 总裁兼首席技术官 Jim Keller
"我对下一代高带宽交换机感到非常兴奋。人工智能工作负载比我为之设计的任何其他工作负载移动的数据都要多。很高兴看到在性能、QOS 和功耗方面取得的进展。我们将充分利用这一切"。
Anshul Sadana,Arista Networks 首席运营官兼高级副总裁
"运行 EOS 的 Arista 7060X 和模块化 7388X 系列为超大规模云数据中心提供了一系列引人注目的高辐射解决方案,由多代 Broadcom Tomahawk 架构提供支持。Tomahawk 5创新技术可为云计算和存储网络以及融合AI/ML提供800G、高能效和高密度的以太网解决方案。
H3C 联席总裁兼首席技术官 Steven Yoe
"作为长期战略合作伙伴,H3C 对 Broadcom 推出市场领先的 Tomahawk 5 交换机系列感到非常兴奋。该芯片系列将改变超大规模数据中心的网络基础架构和实施,因为它采用了 5 纳米技术和 400GbE+ 端口,更重要的是,它推出了 51.2 Tbps 的全球最高性能以太网交换机 ASIC。我们期待着利用 Tomahawk 5 及其重大创新,为 H3C 的直流交换机产品组合带来下一代突破。这将帮助我们快速部署领先的网络解决方案,以满足超大规模云数据中心的增长需求。
瞻博网络集团副总裁 Michael Bushong
瞻博网络集团副总裁 Michael Bushong 表示:"Broadcom 通过 Tomahawk 5 将单芯片数据中心平台的带宽提高了一倍,取得了令人瞩目的成就,这使瞻博网络能够以无与伦比的能效继续提供广泛的路由和交换产品组合。将同类最佳的芯片技术与业界最先进的网络操作系统Junos OS相结合,可以满足客户的前沿需求。
诺基亚硬件工程副总裁 Ken Kutzler
"Broadcom的Tomahawk 5 64x800G交换机是帮助我们的数据中心客户迁移到800GE时代的重要工具。800G 光学器件将于今年全面上市,与 400GE 相比,无论从商业角度还是从功耗角度来看,使用 800G 光学器件都非常合理。
Accton科技公司首席执行官 Edgar Masri
"Accton 很高兴看到 Broadcom 继续引领行业发展,并推出首款 51.2 Tbps 交换 ASIC。Accton及其子公司Edgecore Networks亲眼目睹了超大规模运营商的浓厚兴趣,我们很自豪能够引领潮流,为我们尊贵的超大规模客户开发基于Tomahawk 5的世界级400GbE+平台。"
Daniel Huang,Alpha Networks Inc 总经理
"Broadcom通过Tomahawk 5提供世界上性能最高的单芯片以太网交换机,专门针对云AI/ML工作负载进行了优化,再次确立了市场领导地位。Alpha很高兴能与博通和我们的客户合作,为我们全球的网络规模客户和OEM客户提供最先进的400GbE和800GbE平台,提供一流的经济性和无与伦比的产品质量和可靠性。"
Celestica Inc.服务提供商解决方案副总裁Steven Dorwart表示。
"Celestica很荣幸能继续与Broadcom密切合作,开发基于Tomahawk系列的丰富的开放式网络平台产品组合。Tomahawk 5不仅带来了卓越的速度和馈送,还集成了新的功能,对全球最大数据中心中运行的人工智能/ML工作负载大有帮助。我们期待着提供新一波基于 Tomahawk 5 的平台,帮助我们的客户实现业务增长。
台达信息与通信技术事业群资深副总裁兼总经理Victor Cheng 台达ICTBG副总裁兼总经理
"台达祝贺Broadcom推出又一款改变游戏规则的产品。Tomahawk 5可节省功耗和每千兆位成本,将开创400GbE+网络系统的新时代,使网络运营商能够利用自适应路由等创新功能,以无与伦比的能力处理AI/ML工作负载。Delta期待利用Tomahawk 5将市场领先的400GbE+网络解决方案推向市场。
英业达高级副总裁兼总经理Jack Tsai
"随着 51.2 Tbps Tomahawk 5 芯片的推出,Broadcom 将继续以完美的执行力、技术创新和商用芯片生态系统的支持引领行业发展。我们期待着提供基于战斧5的新平台组合。
锐捷网络总裁兼首席执行官刘忠东
"战斧5在单片51.2 Tbps芯片中将交换容量再次翻倍,这令人振奋!通过集成业界领先的 100G SerDes 和先进的交换/遥测功能,战斧 5 已为 400G/800G 云规模网络做好了充分准备。作为领先的专用交换机解决方案供应商,锐捷通过战斧 5 丰富了我们的产品组合。我们现在可以支持中国和全球客户构建下一代计算/存储/AI&ML融合网络。
广达电脑公司高级副总裁兼广达云技术公司总裁 Mike Yang
"作为领先的数据中心基础架构解决方案提供商,QCT 很荣幸能与博通合作,展示 Tomahawk 5 的创新成果。QCT非常高兴能够开发战斧5的DAC和CPO版本,以满足我们客户的需求。"
纬创资通首席执行官林文韬
"纬创很高兴能与 Broadcom 合作,向市场推出基于 Tomahawk 5 的交换产品。Tomahawk 5将为400GbE+网络平台提供前所未有的密度、性能和效率。我们期待提供新的 Tomahawk 5 平台,以满足复杂的 AI/ML 工作负载对更多带宽日益增长的需求。
UfiSpace首席执行官何文生
"作为Broadcom的主要网络ODM供应商,UfiSpace专注于为固定和模块化系统提供以太网交换机领域的最佳产品。我们很高兴看到 Tomahawk 5 的上市,因为我们期待它的新功能将使我们的客户把下一代服务提升到前所未有的高度。"




![[C++随笔录] list使用](https://img-blog.csdnimg.cn/a32d918a4fc94810b082fd35388d7110.png)