Shared Execution Techniques for Business Data Analytics over Big Data Streams
大数据流分析中的共享执行技术
1、摘要
2020年的一篇共享工作的论文:商业数据分析需要处理大量数据流,并创建物化视图以便给用户实时提供分析结果。物化每个查询,并作为单独的查询执行计划进行持续刷新并不高效并且不可扩展。本文针对并行执行的多个查询,提出一个全局执行计划,并最大限度减少运算符之间的scan、运算和操作之间流动的记录数量。我们提出了用于创建和维护物化视图的共享执行技术,以支持业务数据分析查询。利用多个业务数据分析查询中的供行来支持大数据流的可扩展性和高效处理。本文重点介绍了用于选择谓词、分组、聚合计算的共享执行技术。介绍了全局执行计划如何在分布式流处理系统(INGA,构建在Storm之上)中运行。在INGA中,我们能够支持2500个物化视图,该视图通过利用查询之间的共享结构使用237个查询构建。能够使用深度为21的单个全局查询执行计划树来运行所有的237个查询。
思考:
其实就是将多个并行的查询执行计划合并成一个全局的执行计划。这里需要做到:1)识别出共有的部分;2)合并成全局执行计划;3)最后的执行结果如何分发给各个并行执行的SQL
2、思路
以下面的示例进行介绍,下面3个SQL进行并行执行。主要分为group by、where谓词和聚合操作。

常规执行器下每个查询一个执行计划,输入流需要输入3次;而全局执行计划仅需要执行一次,即需要输入1次数据流。
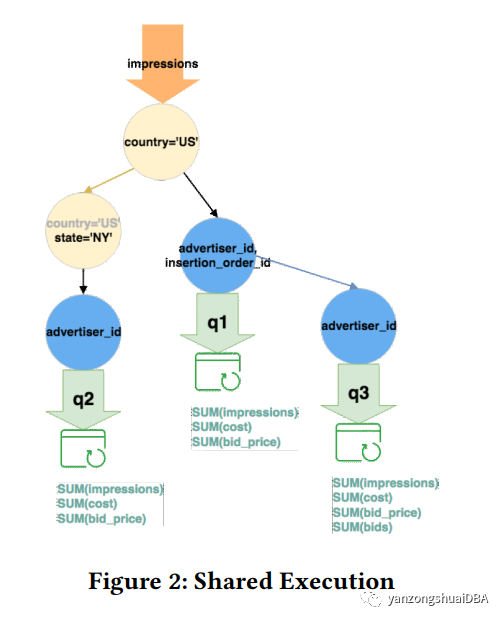
图2中,将3个SQL整个到一个全局执行计划中,一次数据流输入,执行3个SQL。全局执行计划使用heap数据结构来表示,使用节点表示操作符。使用SubsetHeap表示谓词节点,group by/aggregate使用SupersetHeap表示。黄色节点是谓词,蓝色是group by。有下面两个定义:
1)SubsetHeap
和MinHeap类似,作为一个基于树的数据结构。SubsetHeap的root节点时一个空集,表示为∅:A是B的父节点,从而A是B的子集,这里指的是谓词,而非结果集
A = parent(B) ⇒ key(A) ⊂ key(B)
2)SupersetHeap
和MaxHeap类似。Root节点是一个全集U。A是B的父节点,从而B是A的子集。这里指group by列,而非结果集:
A = parent(B) ⇒ key(A) ⊃ key(B)
再次回到图2,从上述定义上来讲,country=’US’谓词是country=’US’ && country=’NY’的子集,所以country=’US’位于父节点。
从多个谓词的语义上来将,country=’US’的结果集大,可以在谓词country=’US’的基础上接着计算country=’NY’,这样就可以先计算出3个SQL的谓词公共部分,将其结果集共享;下一步在此结果集基础上计算3个SQL的其他部分。
对于group by/agg:group by advertiser_id,insertion_order_id的列包含group by advertiser_id分组列,所以他是父节点。从结果集上讲,group by advertiser_id的结果可以在group by advertiser_id,insertion_order_id基础上接着计算,这就为group by共享计算做好了基础。
从图2中可以看到,3个SQL整个成一个SQL执行计划,先计算谓词公共部分,然后计算更深一层的谓词公共部分,接着在谓词计算基础上计算group by公共部分,最后输出结果。
如此,做到一次数据流输入,一次执行计划的执行,完成3个SQL语句。
缺陷:严格来说,这3个SQL语句并不是真正并行执行,而是挑出公共部分,按照全局执行计划依次执行各个节点。有可能其中一个SQL非常简单,在全局执行计划的分支位置正好使得他是最后执行的分支,这样其他SQL就会拖累他。
3、论文
https://www.cs.purdue.edu/homes/aref/IDAS/ssdbm2020-pdfa.pdf