【CFD小工坊】模型网格(三角形网格)
- 前言
- 网格几何
- 网格编号
- 编程实现
- 数据读入
- 网格数据构建
本系列博文的是我学习二维浅水方程理论,直至编译一个实用的二维浅水流动模型的过程。(上一篇Blog回顾)
前言
本二维浅水模型将采用非结构化网格。为简单起见,我将从三角形网格开始构建模型、编写求解器。
许多代码库,软件都能实现三角形网格的生成。例如DHI MIKE软件、Triangle库等。对此,我个人推荐SMS软件;SMS软件能够通过导入边界格点,方便地生成三角形网格,且能检查所生成网格的质量。
当然,我们需要将这些网格数据导出,并编辑成我们所需的数据,最后输入本浅水模型。本博文将会明确我们导出的数据有哪些。
网格几何
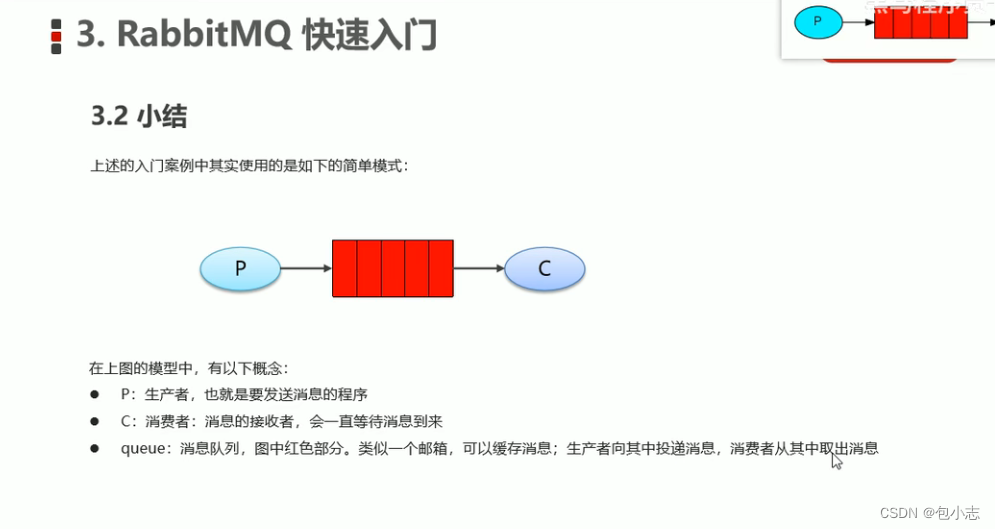
首先,我对三角形网格的各个部分做了如下定义:
- 网格节点(point),指构成三角形的三个顶点,如下图空心圆所示;
- 网格面(cell),指这整个三角形;
- 网格中心(cell center),指三角形的几何中心,如下图红圆所示;
- 网格边(edges),一条边由两个网格节点(points)确定。
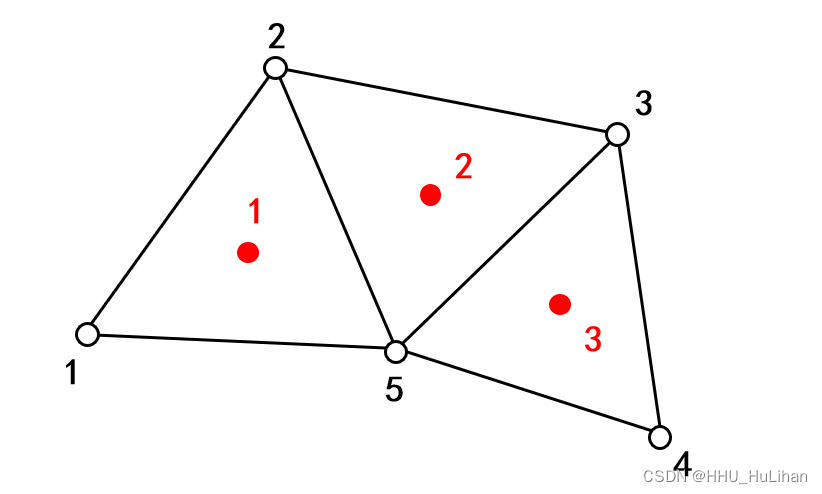
一般来说,构成网格的两个必要元素是网格节点(points)和网格边(edges);当画出了三角形的顶点,并连出了网格边,则一套三角形网格得以确定。
但在一般情况下,我们常用的输入数据是网格节点,以及构成每个三角形的顶点序号。对于网格节点,输入数据即各个顶点的序号、x和y坐标值;之后,分别给出构成各个三角形的序号序列。以上图为例,point数据如下:
| 节点序号 | x 坐标 | y坐标 |
|---|---|---|
| 1 | x1 | y1 |
| 2 | x2 | y2 |
| 3 | x3 | y3 |
| 4 | x4 | y4 |
| 5 | x5 | y5 |
构成各个cell的数据如下(以下将这个类型的数据简称为“cell”,即默认的输入元素为point和cell数据):
| 网格序号 | 构成网格的三个格点(格点序号) |
|---|---|
| 1 | 1,2,5 |
| 2 | 2,3,5 |
| 3 | 3,4,5 |
网格编号
根据上面的例子,我们知道point和cell数据并非共用一套编号系统。例如,1号网格和1号节点并不存在必然关联,而网格三角形与节点间的关联通过cell数据描述。
这里,我们强调三角形网格中的点(point)、边(edge)和网格本身(cell)都各自用着一套编号系统;只有网格中心(cell center)和cell数据可共用同一套编号系统。因此,在本模型中,网格三角形cell的编号等同于其中心点cell center的编号。
编程实现
数据读入
首先,我们通过fopen、fgets等函数,从txt文件中分别读入格点坐标,记为xp和yp。xp和yp均为一个大小为Np的一维数值(xp[0 ~ (Np-1)]),Np表示总网格数。要注意的是,c语言中,数组索引的起点为0。
之后,再读入构成各个三角形的节点序号cell,记为node数组。node数据为一个二维数组,其大小 node[0 ~ 2][0 ~ (Nc-1)];其中,Nc表示三角形总数。
在此,我们给出一个示例代码:
/*
* Function: ReadGrid
* Usage: Read the grid data from the input files
* Called by: main
*/
void ReadGrid() {
int num=0, i;
// 1. to read grid points
FILE* fp1 = fopen("points.txt", "r");
if (fp1 == NULL) {
fprintf(stderr, "Fail to read grid files (points.txt)! \n");
exit(EXIT_FAILURE);
}
char* row1 = (char*)malloc(sizeof(char) * N_str);
fgets(row1, N_str, fp1);
sscanf(row1, "%d", &num);
xp = (double *)malloc(sizeof(double) * num);
yp = (double *)malloc(sizeof(double) * num);
zbp = (double *)malloc(sizeof(double) * num);
for (i = 0; i < num; i++) {
fgets(row1, N_str, fp1);
sscanf(row1, "%lf %lf \n", &xp[i], &yp[i]);
}
Np = num;
free(row1);
fclose(fp1);
// 2. to read geometric data of all cells
FILE* fp2 = fopen("cells.txt", "r");
if (fp2 == NULL) {
fprintf(stderr, "Fail to read grid files (elements.txt)! \n");
exit(EXIT_FAILURE);
}
char* row2 = (char*)malloc(sizeof(char) * N_str);
fgets(row2, N_str, fp2);
sscanf(row2, "%d", &num);
node = (int **)malloc(sizeof(int) * 3);
for (int i = 0; i < 3; i++)
{
node[i] = (int *)malloc(sizeof(int) * num);
}
for (i = 0; i < num; i++) {
fgets(row2, N_str, fp1);
sscanf(row2, "%d %d %d \n", &node[0][i], &node[1][i], &node[2][i]);
// redefine the index from zero instead of one
node[0][i] = node[0][i] - 1;
node[1][i] = node[1][i] - 1;
node[2][i] = node[2][i] - 1;
}
Nc = num;
free(row2);
fclose(fp2);
fprintf(stderr, "The grid data has been read... \n");
}
代码所需的读入文件points.txt的示例如下(第一行表示Np):
5
0.0 0.0
1.0 1.0
4.0 1.0
5.0 0.0
3.0 0.0
代码所需的读入文件cells.txt的示例如下(第一行表示Nc):
3
1 2 5
2 3 5
3 4 5
网格数据构建
在模型中,我们还需要知道的量有中心点坐标、网格面积、各条边的边长、网格的相邻关系等等(这个之后还会介绍)。在此,我们先以这几个量为例,介绍网格数据的处理。
/*
* Function: ConstructGrid
* Usage: Construct the grids for reading other data
* Called by: main
*/
void ConstructGrid() {
int i, j, k, p1, p2, p3, count, count2;
double x1, x2, x3, y1, y2, y3;
xc = (double *)malloc(sizeof(double) * Nc);
yc = (double *)malloc(sizeof(double) * Nc);
area = (double *)malloc(sizeof(double) * Nc);
neigh = (int **)malloc(sizeof(int) * 3);
for (int i = 0; i < 3; i++)
{
neigh[i] = (int *)malloc(sizeof(int) * Nc);
}
edgeL = (double **)malloc(sizeof(int) * 3);
for (int i = 0; i < 3; i++)
{
edgeL[i] = (double *)malloc(sizeof(int) * Nc);
}
for (i = 0; i < Nc; i++) {
p1 = node[0][i];
p2 = node[1][i];
p3 = node[2][i];
x1 = xp[p1];
x2 = xp[p2];
x3 = xp[p3];
y1 = yp[p1];
y2 = yp[p2];
y3 = yp[p3];
// 1. to define the cell centers and calculate the area
xc[i] = (x1 + x2 + x3) / 3.0;
yc[i] = (y1 + y2 + y3) / 3.0;
area[i] = fabs(x1*y2 - x2*y1 + x2*y3 - x3*y2 + x3*y1 - x1*y3);
// 2. to find the neiborning cells
count = 0;
for (j = 0; j < Nc; j++) {
if (count >= 3) break; // "count=3" means that all neighboring cells have been found
if (j == i) continue; // skip the itself
count2 = 0;
for (k = 0; k < 3; k++) {
if (node[k][j] == p1 || node[k][j] == p2 || node[k][j] == p3) count2 = count2 + 1;
}
if (count2 == 2) {
neigh[count][i] = j;
count = count + 1;
}
}
if (count == 1) {
neigh[1][i] = -1;
neigh[2][i] = -1;
}
else if(count == 2){
neigh[2][i] = -1;
}
// 3. to calculate the lengths of all edges
edgeL[0][i] = sqrt((x2 - x1)*(x2 - x1) + (y2 - y1)*(y2 - y1));
edgeL[1][i] = sqrt((x3 - x2)*(x3 - x2) + (y3 - y2)*(y3 - y2));
edgeL[2][i] = sqrt((x1 - x3)*(x1 - x3) + (y1 - y3)*(y1 - y3));
}
fprintf(stderr, "The computational grid has been constructed... \n");
}
首先第一部分,我们定义了数组xc和yc用于记录网格中心点的坐标,这两个变量可以通过malloc函数开辟存储空间(上述代码第10 ~ 11行)。其余变量同理,均可用malloc函数定义空间。
之后,我们计算网格中心的xc和yc(上述代码第37 ~ 38行);随后再计算每个网格的面积area(上述代码第39行),面积公式如下:
A
r
e
a
=
∣
x
1
y
2
−
x
2
y
1
+
x
2
y
3
−
x
3
y
2
+
x
3
y
1
−
x
1
y
3
∣
Area = |x_1 y_2 - x_2 y_1 + x_2 y_3 - x_3 y_2 + x_3 y_1 - x_1 y_3|
Area=∣x1y2−x2y1+x2y3−x3y2+x3y1−x1y3∣
之后,我们再搜索每个网格的相邻网格,这对我们求解网格间的通量很有帮助。因为在每个时间步内,只有相邻的网格才有质量和动量通量传递。网格的接邻情况我们通过数组neigh[0 ~ 2][1 ~ (Nc-1)]来存储。在上述代码的42 ~ 62行,我们搜索了相邻网格。思路如下:
- 对于网格i与网格j,判断它们是否有两个相同的顶点;这可以通过它们的node[ ][i]与node[ ][j]
来判断。当找到node[ ][i]与node[ ][j]有两个相同的元素(上述代码第46 ~ 53行),记录此时的i和j(上述代码第50 ~ 53行)。 - 一个网格的相邻网格可能有1,2或3个。对于相邻网格数为3的情况,neigh数组无需额外处理;当相邻网格数为1或2,neigh数组多余的元素将用-1填充
以上图的网格为例,当搜索结束后,得到的neigh数组结果如下(注意这里的编号,c语言的数组起点是0):
1 -1 -1
0 2 -1
1 -1 -1
此外,注意上述第二点的这个处理方法是暂时的,相邻网格数为1或2的网格的边会对应了计算区域的边界。所以后续还需对neigh数组进行处理。
最后,我们计算每一条边的长度,存于edgeL数组中(上述代码第65 ~ 67行)。