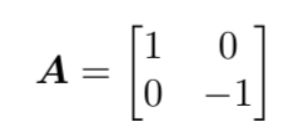Anchor DETR(AAAI 2022)
改进:
- 提出了基于anchor的对象查询
- 提出Attention变体-RCDA
在以前DETR中,目标的查询是一组可学习的embedding。然而,每个可学习的embedding都没有明确的意义 (因为是随机初始化的),所以也不能解释它最终将集中在哪里。此外,由于每个对象查询将不会关注特定的区域,所以训练时优化也是比较困难的

DETR中对可视化的注释:( slots就是100个查询中的一个 )

这里三种预测pattern可能相同也可能不同
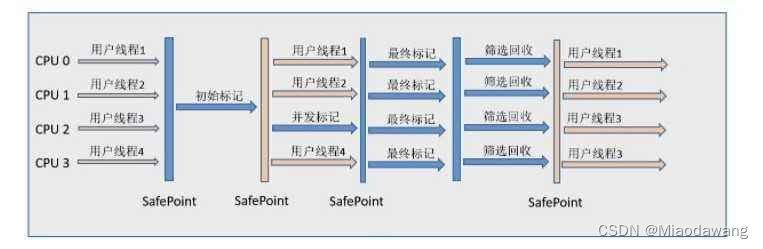
简单的模型
与DETR没有特别大的变化
6encoder,6decoder,右下角是Anchor Points
position embedding会加入到decoder的q和k中
object query:[100,256]增加了anchor point,编码成positon embedding,替换原来的oq
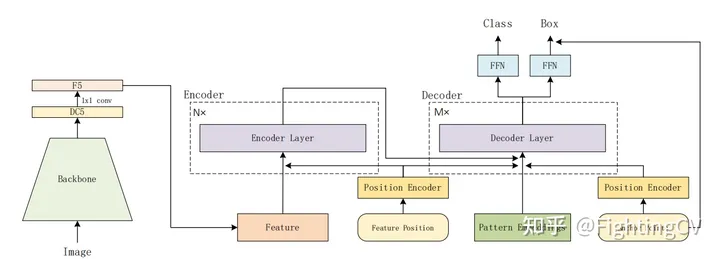
生成anchor point有两种方式
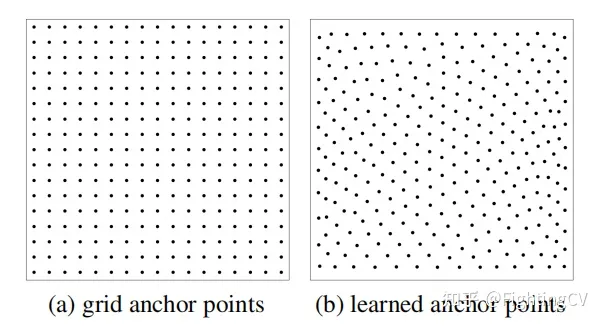
(a)anchor固定,宽高均匀分布的网格,均匀采样
(b)先将一个tensor以0-1均匀分布随机初始化点位,并作为学习参数(embedding),实验效果好

anchor point转化为 object query

首先,获得learned的[100(NA),2]的anchor points;
然后通过sin/cos转换成[100,256]高频位置编码(代码里函数为pos2posemb2d);
过两层MLP学习(代码里为adapt_pos2d),转换为Q_P:[Np(pattern),256]。
Multiple Predictions for Each Anchor Points
假设参考点100个,每个点预测一个目标,真实的图像在同一个点附近可能会有多个目标
anchor detr设计了一个点预测多个模式(3种),每个点设置Np个模式(Np=3)
原始detr,object query是[100,256]每个是[1,256]
anchor detr增加了一个pattern embedding,如下;
Q
f
i
=
Embedding
(
N
p
,
C
)
Q_{f}^{i}=\operatorname{Embedding}\left(N_{p}, C\right)
Qfi=Embedding(Np,C)
也就是每个点Np(3)个pattern,[3,256],论文里Np=300,pattern=3,也就是900个点
最终只需要将pattern embedding和anchor point的Q_p相加,就得到最终的object query, Pattern Position query可以表示为:
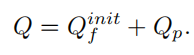
实际上代码里没用到这个上述式子
上个代码图中的代码里reference point是直接从300repeat到900的
如果我理解有误请提醒我
代码种pattern是第一个decoder的输入,原始detr的tgt全是0

Row-Column Decoupled Attention
减少的是内存开销!!!!
行列分解attention机制,加速收敛,q长度为900,减少内存减少内存开销。

原始的transformer输入token(H*W)会被拉平成一维的传入
Ax(W),先在行维度进行计算
Ay(H),在进行Ay操作
Ay和Z在高度维度进行加权求和
QK都进行行列分解,V不分解[Nq,H*W]
原始attention:Nq * H * W * M(head)
RCDA:
Ax:Nq * W * M
Ay:Nq * H * M
就只需要比较两个矩阵大小即刻,图的右侧是比例公式,两个维度比较,约掉后剩下W * M/C,W假设是32(DC5),M=8,C=256,那是一样的,看C和W * M
DC5表示在主干网络(默认resnet50)的最后一个stage加了个空洞卷积并减少了个pooling层实现分辨率增大一倍
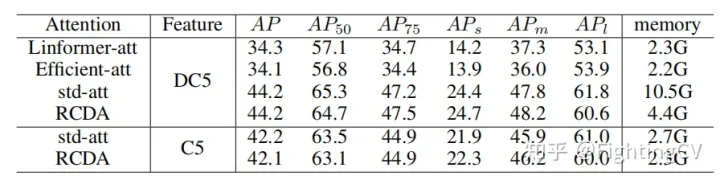
实验
1.比对了不同线性attention的memory和ap
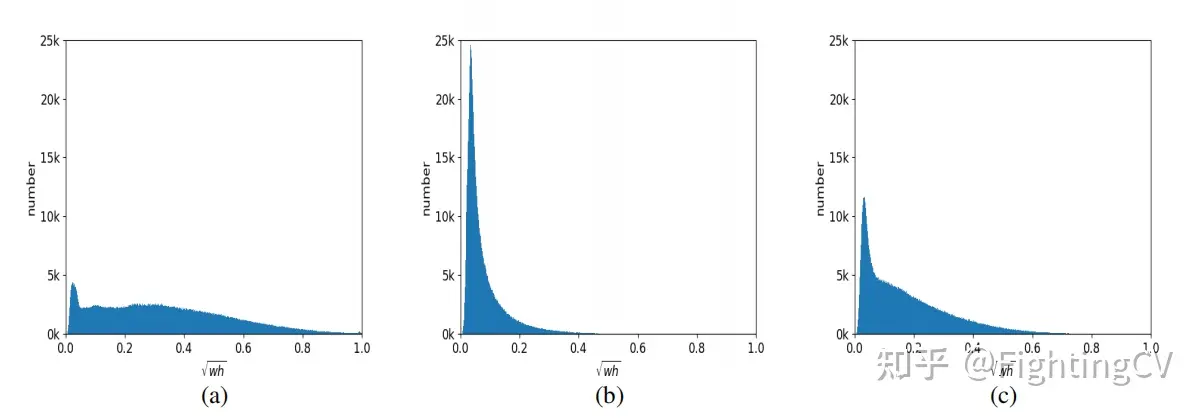
2.模式a通常是大物体,模式b是小物体,模式c比较均衡
参考
https://www.bilibili.com/video/BV148411M7ev/?spm_id_from=333.788&vd_source=4e2df178682eb78a7ad1cc398e6e154d