# 前言
随着人工智能技术的不断发展,尤其是深度学习技术的广泛应用,多模态数据处理和大模型训练已成为当下研究的热点之一,这些技术也为文档图像智能处理和分析领域带来了新的发展机遇。
近期,2023第十二届中国智能产业高峰论坛(CIIS2023)在江西南昌开幕,政企研学各界学者专家同台交流,在成果分享、观点碰撞、经验互鉴中,共促智能科技引领行业创新变革、驱动数字经济快速发展。

多模态大模型与文档图像处理
多模态大模型是指能够处理多种输入模态数据(如文本、图像、语音等)的深度学习模型。
传统的深度学习模型通常只能处理单一模态的数据,例如只能处理文本数据或图像数据。但在现实世界中,我们经常会遇到多种模态的数据,比如一篇包含文本和图像的新闻报道,或者一个包含图像和语音的视频。为了更好地处理这些多模态数据,多模态大模型应运而生。
从古至今,文档一直是最常见,也是最重要的信息载体之一,如何从文档图像中提取出有用的信息,并进行准确理解和有效应用,是一项非常困难的挑战,需要消耗大量的人力和时间。
综合使用多模态数据训练大模型可以极大地提高文档图像处理和分析的效率和精度,进而推动相关行业的数字化转型和智能化升级。
在大会上,合合信息 智能技术平台事业部 副总经理 丁凯 在 多模态大模型与文档图像智能理解专题论坛 进行了介绍分享。
文档图像技术难题
文档图像分析识别与理解的技术难题主要包括以下方面:
- 场景及版式多样:文档图像可能来自不同的场景和版式,如报纸、书籍、手写笔记等,每种场景和版式都具有不同的特点和挑战,需要算法能够适应不同的场景和版式。
- 采集设备不确定性:文档图像可能通过不同的采集设备获取,如扫描仪、手机相机等,不同设备的成像质量和参数不同,导致图像质量和特征的差异,需要算法具备鲁棒性,能够处理不同设备采集的图像。
- 用户需求多样性:用户对文档图像的需求各不相同,有些用户可能只需要提取文本信息,而有些用户可能需要进行结构化的理解和分析,算法需要能够满足不同用户的需求。
- 文档图像质量退化严重:由于文档的老化、损坏或存储条件等原因,文档图像的质量可能会受到严重的退化,如模糊、噪声、光照不均等,这会给文字检测、字符识别等任务带来困难。
- 文字检测及版面分析困难:文档图像中的文字可能存在不同的字体、大小、颜色等变化,而且文字可能与背景颜色相似,导致文字检测和版面分析变得困难,算法需要具备高效准确的文字检测和版面分析能力。
- 非限定条件文字识别率低:在非限定条件下,文档图像中的文字可能出现扭曲、变形、遮挡等情况,这会导致传统的文字识别算法的准确率下降,需要算法具备对非限定条件下的文字进行准确识别的能力。
- 结构化智能理解能力差:文档图像中的信息不仅仅是文字,还包括表格、图表、图像等结构化信息,算法需要具备结构化智能理解的能力,能够对文档中的结构化信息进行提取、分析和理解。

基于这些难题,合合信息将智能文档处理研究主题分成了以下六个模块:
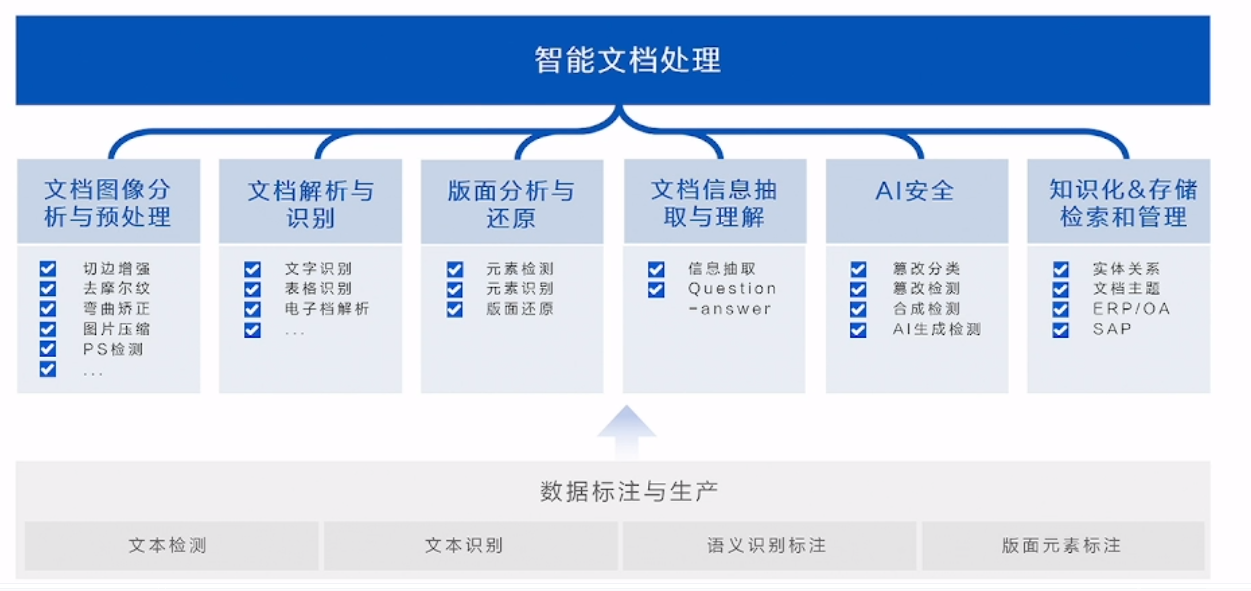
合合信息通过图像分析、文档解析、版面分析、信息抽取、安全保障和知识化管理等方法,实现了智能文档处理的全流程,提供了高效、准确和安全的文档处理服务。
- 文档图像分析与预处理:通过图像处理技术对文档图像进行分析和预处理,去除噪声、调整图像亮度和对比度等,以提高后续处理的准确性和效果。
- 文档解析与识别:在图像预处理之后,采用光学字符识别(OCR)技术对文档进行解析和识别,将图像中的文字转换为可编辑和可搜索的文本格式,以便后续处理和分析。
- 版面分析与还原:进行版面分析,识别文档中的标题、段落、表格、图像等元素,并还原文档的原始版面结构,以便后续的信息抽取和理解。
- 文档信息抽取与理解:利用自然语言处理(NLP)和机器学习技术,对文档中的关键信息进行抽取和理解,以获取业务实际场景所需要的关键信息。
- AI安全:检查文档图像是否有篡改、合成、生成痕迹,保障文档图像安全。
- 知识化&存储检索和管理:将处理后的文档信息进行知识化,以便于后续的存储、检索和管理,用户可快速找到所需的文档或信息。
合合信息文档图像专有大模型
合合信息的文档图像专有大模型是基于深度学习技术开发的一种大语言模型,专门用于处理文档图像相关的任务。
该模型基于深度神经网络结构,经过了海量数据的训练和优化,拥有强大的文档图像处理能力。它可以识别和提取文档中的文字、表格、图形等信息,实现自动化的文档解析和理解。在多个领域都有广泛的应用,例如金融、法律、医疗等。它可以帮助企业和个人实现文档的自动化处理,提高工作效率,减少人工成本。
目前,受到视觉编码器的分辨率和训练数据的限制,现有多模态大模型对显著文本的处理较好,但是对于细粒度文本的处理很差:
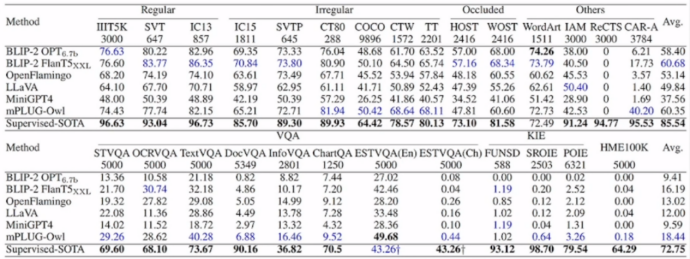
为此,合合信息与华南理工大学进行了深入探讨:

首先,不同模态的数据具有不同的特点和表达方式,如何有效地将它们进行融合和交互是一个关键问题。其次,多模态大模型需要处理更加复杂和庞大的数据,对计算资源和模型设计提出了更高的要求。另外,多模态数据的标注和训练也是一个挑战,因为不同模态之间的关联和对齐需要更加精细的处理。
研究人员认为,可以将文档图像识别分析的各种任务定义为序列预测的形式(文本,段落,版面分析,表格,公式等等),再通过不同的prompt引导模型完成不同的OCR任务,支持篇章级的文档图像识别分析,输出Markdown/HTML/Text等标准格式,最后将文档理解相关的工作交给LLM去做。
总的来说,文档图像大模型主要包括以下功能:
文字识别与提取:能够对文档图像中的文字进行准确识别,并提取出文字内容。无论是印刷体还是手写体,多种语言都可以被识别。
文档结构分析:能够智能地分析文档的结构,识别出标题、段落、列表、表格等不同的结构元素,帮助用户更好地理解文档的组织结构。
表格解析与提取:能够自动识别和解析文档中的表格结构,提取出表格中的数据,并将其转化为结构化的数据形式,方便后续的数据处理和分析。
关键信息提取:能够从文档中提取出关键信息,如日期、金额、公司名称等,帮助用户快速获取文档中的重要内容。
文档分类与检索:能够根据文档的内容和特征,将文档进行分类和索引,方便用户进行文档管理和检索,提高工作效率。
研发过程
以2022年被提出的SPTS文档图像大模型为例,
针对场景文字,将端到端检测识别定义为图片到序列的预测任务,采用单点标注指示文本位置,极大地降低了标注成本,无需Rol采样和复杂的后处理操作,真正将检测识别融为一体。

随后,在SPTS v2的研究中,企业和高校重点关注速度优化的问题。
依旧是针对场景文字,将检测识别解耦为自回归的单点检测和并行的文本识别。IAD根据视觉编码器特征自回归地得到每个文本的单点坐标。PRD根据IAD的单点特征,并行地得到各个文本的识别结果。
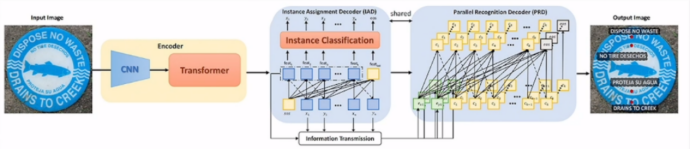
经过数轮迭代,基于SPTS的OCR大一统模型(SPTS v3),成功将输入从场景文字拓展到表格、公式、篇章节的文档等。
将多种OCR任务定义为序列预测的形式,通过不同的prompt引导模型完成不同的OCR任务,模型沿用SPTS的CNN+TransformerEncoder+Transformer Decoder的图片到序列的结构。

SPTS v3目前主要关注以下任务:端到端检测识别、表格结构识别、手写数学公式识别。

研究结果


展望未来
作为行业领先的人工智能及大数据科技企业,合合信息深耕智能文字识别、图像处理、自然语言处理和大数据挖掘等领域,其研发的智能图像处理引擎提供多种图像智能处理黑科技,例如图像切边增强、PS 篡改检测以及图像矫正等都已落地并服务与各行业领域。
未来,合合信息还将继续在文档图像处理方向发力,让新技术实现多场景应用。
合合信息的研究成果在智能产业中具有重要意义,同时这些成果和问题的探索也将为智能产业的发展提供新的思路和方向。