目录
1 Tokenizer 介绍
1.1 Tokenizer定义
1.2 Tokenizer方法
1.3 Tokenizer属性
2 Tokenizer文本向量化
2.1 英文文本向量化
2.2 中文文本向量化
3 总结
1 Tokenizer 介绍
Tokenizer是一个用于向量化文本,将文本转换为序列的类。计算机在处理语言文字时,是无法理解文字含义的,通常会把一个词(中文单个字或者词)转化为一个正整数,将一个文本就变成了一个序列,然后再对序列进行向量化,向量化后的数据送入模型处理。
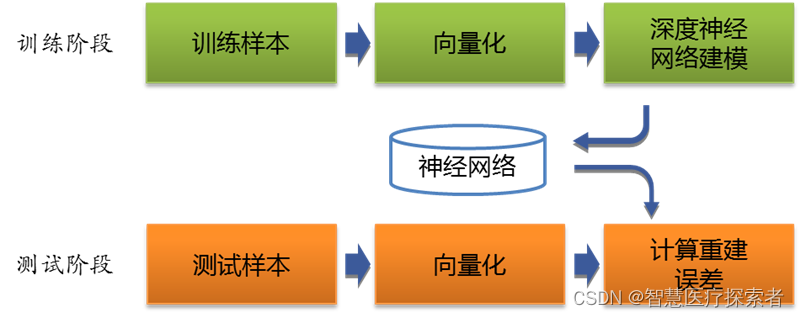
Tokenizer 允许使用两种方法向量化一个文本语料库: 将每个文本转化为一个整数序列(每个整数都是词典中标记的索引); 或者将其转化为一个向量,其中每个标记的系数可以是二进制值、词频、TF-IDF权重等。
1.1 Tokenizer定义
keras.preprocessing.text.Tokenizer(num_words=None,
filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~ ',
lower=True,
split=' ',
char_level=False,
oov_token=None,
document_count=0)参数说明:
- num_words: 需要保留的最大词数,基于词频。只有最常出现的 num_words 词会被保留。
- filters: 一个字符串,其中每个元素是一个将从文本中过滤掉的字符。默认值是所有标点符号,加上制表符和换行符,减去 ’ 字符。
- lower: 布尔值。是否将文本转换为小写。
- split: 字符串。按该字符串切割文本。
- char_level: 如果为 True,则每个字符都将被视为标记。
- oov_token: 如果给出,它将被添加到 word_index 中,并用于在 text_to_sequence 调用期间替换词汇表外的单词。
1.2 Tokenizer方法
(1)fit_on_texts(texts)
- 参数 texts:要用以训练的文本列表。
- 返回值:无。
(2)texts_to_sequences(texts)
- 参数 texts:待转为序列的文本列表。
- 返回值:序列的列表,列表中每个序列对应于一段输入文本。
(3)texts_to_sequences_generator(texts)
本函数是texts_to_sequences的生成器函数版。
- 参数 texts:待转为序列的文本列表。
- 返回值:每次调用返回对应于一段输入文本的序列。
(4)texts_to_matrix(texts, mode) :
- 参数 texts:待向量化的文本列表。
- 参数 mode:'binary','count','tfidf','freq' 之一,默认为 'binary'。
- 返回值:形如
(len(texts), num_words)的numpy array。
(5)fit_on_sequences(sequences) :
- 参数 sequences:要用以训练的序列列表。
- 返回值:无
(5)sequences_to_matrix(sequences) :
- 参数 sequences:待向量化的序列列表。
- 参数 mode:'binary','count','tfidf','freq' 之一,默认为 'binary'。
- 返回值:形如
(len(sequences), num_words)的 numpy array。
1.3 Tokenizer属性
(1)word_counts
类型:字典
描述:将单词(字符串)映射为它们在训练期间出现的次数。仅在调用fit_on_texts之后设置。
(2)word_docs
类型:字典
描述:将单词(字符串)映射为它们在训练期间所出现的文档或文本的数量。仅在调用fit_on_texts之后设置。
(3)word_index
类型:字典,
描述:将单词(字符串)映射为它们的排名或者索引。仅在调用fit_on_texts之后设置。
(4)document_count
类型:整数。
描述:分词器被训练的文档(文本或者序列)数量。仅在调用fit_on_texts或fit_on_sequences之后设置。
2 Tokenizer文本向量化
2.1 英文文本向量化
默认情况下,删除所有标点符号,将文本转换为空格分隔的单词序列(单词可能包含 ’ 字符)。 这些序列然后被分割成标记列表。然后它们将被索引或向量化。0是不会被分配给任何单词的保留索引。
from keras.preprocessing.text import Tokenizer
texts = ["Life is a journey, and if you fall in love with the journey, you will be in love forever.",
"Dreams are like stars, you may never touch them, but if you follow them, they will lead you to your destiny.",
"Memories are the heart's treasures, they hold the wisdom and beauty of our past.",
"Nature is the most beautiful artist, its paintings are endless and always breathtaking.",
"True happiness is not about having everything, but about being content with what you have.",
"Wisdom comes with age, but more often with experience.",
"Music has the power to transport us to a different place, a different time.",
"Love is blind, but often sees more than others.",
"Time heals all wounds, but only if you let it.",
"Home is where the heart is, and for many, that is where the memories are."]
tokenizer = Tokenizer(num_words=64, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
lower=True, split=' ', char_level=False, oov_token=None,
document_count=0)
# 根据输入的文本列表更新内部字典
tokenizer.fit_on_texts(texts)
print("处理的文档数量,document_count: ", tokenizer.document_count)
print("单词到索引的映射,word_index: \n", tokenizer.word_index)
print("索引到单词的映射,index_word: \n", tokenizer.index_word)
print("每个单词出现的总频次,word_counts: \n", tokenizer.word_counts)
print("出现单词的文档的数量,word_docs: \n", tokenizer.word_docs)
print("单词索引对应的出现单词的文档的数量,index_docs: \n", tokenizer.index_docs)运行结果显示如下:
处理的文档数量,document_count: 10
单词到索引的映射,word_index:
{'is': 1, 'you': 2, 'the': 3, 'but': 4, 'and': 5, 'with': 6, 'are': 7, 'a': 8, 'if': 9, 'love': 10, 'to': 11, 'journey': 12, 'in': 13, 'will': 14, 'them': 15, 'they': 16, 'memories': 17, 'wisdom': 18, 'about': 19, 'more': 20, 'often': 21, 'different': 22, 'time': 23, 'where': 24, 'life': 25, 'fall': 26, 'be': 27, 'forever': 28, 'dreams': 29, 'like': 30, 'stars': 31, 'may': 32, 'never': 33, 'touch': 34, 'follow': 35, 'lead': 36, 'your': 37, 'destiny': 38, "heart's": 39, 'treasures': 40, 'hold': 41, 'beauty': 42, 'of': 43, 'our': 44, 'past': 45, 'nature': 46, 'most': 47, 'beautiful': 48, 'artist': 49, 'its': 50, 'paintings': 51, 'endless': 52, 'always': 53, 'breathtaking': 54, 'true': 55, 'happiness': 56, 'not': 57, 'having': 58, 'everything': 59, 'being': 60, 'content': 61, 'what': 62, 'have': 63, 'comes': 64, 'age': 65, 'experience': 66, 'music': 67, 'has': 68, 'power': 69, 'transport': 70, 'us': 71, 'place': 72, 'blind': 73, 'sees': 74, 'than': 75, 'others': 76, 'heals': 77, 'all': 78, 'wounds': 79, 'only': 80, 'let': 81, 'it': 82, 'home': 83, 'heart': 84, 'for': 85, 'many': 86, 'that': 87}
索引到单词的映射,index_word:
{1: 'is', 2: 'you', 3: 'the', 4: 'but', 5: 'and', 6: 'with', 7: 'are', 8: 'a', 9: 'if', 10: 'love', 11: 'to', 12: 'journey', 13: 'in', 14: 'will', 15: 'them', 16: 'they', 17: 'memories', 18: 'wisdom', 19: 'about', 20: 'more', 21: 'often', 22: 'different', 23: 'time', 24: 'where', 25: 'life', 26: 'fall', 27: 'be', 28: 'forever', 29: 'dreams', 30: 'like', 31: 'stars', 32: 'may', 33: 'never', 34: 'touch', 35: 'follow', 36: 'lead', 37: 'your', 38: 'destiny', 39: "heart's", 40: 'treasures', 41: 'hold', 42: 'beauty', 43: 'of', 44: 'our', 45: 'past', 46: 'nature', 47: 'most', 48: 'beautiful', 49: 'artist', 50: 'its', 51: 'paintings', 52: 'endless', 53: 'always', 54: 'breathtaking', 55: 'true', 56: 'happiness', 57: 'not', 58: 'having', 59: 'everything', 60: 'being', 61: 'content', 62: 'what', 63: 'have', 64: 'comes', 65: 'age', 66: 'experience', 67: 'music', 68: 'has', 69: 'power', 70: 'transport', 71: 'us', 72: 'place', 73: 'blind', 74: 'sees', 75: 'than', 76: 'others', 77: 'heals', 78: 'all', 79: 'wounds', 80: 'only', 81: 'let', 82: 'it', 83: 'home', 84: 'heart', 85: 'for', 86: 'many', 87: 'that'}
每个单词出现的总频次,word_counts:
OrderedDict([('life', 1), ('is', 7), ('a', 3), ('journey', 2), ('and', 4), ('if', 3), ('you', 7), ('fall', 1), ('in', 2), ('love', 3), ('with', 4), ('the', 7), ('will', 2), ('be', 1), ('forever', 1), ('dreams', 1), ('are', 4), ('like', 1), ('stars', 1), ('may', 1), ('never', 1), ('touch', 1), ('them', 2), ('but', 5), ('follow', 1), ('they', 2), ('lead', 1), ('to', 3), ('your', 1), ('destiny', 1), ('memories', 2), ("heart's", 1), ('treasures', 1), ('hold', 1), ('wisdom', 2), ('beauty', 1), ('of', 1), ('our', 1), ('past', 1), ('nature', 1), ('most', 1), ('beautiful', 1), ('artist', 1), ('its', 1), ('paintings', 1), ('endless', 1), ('always', 1), ('breathtaking', 1), ('true', 1), ('happiness', 1), ('not', 1), ('about', 2), ('having', 1), ('everything', 1), ('being', 1), ('content', 1), ('what', 1), ('have', 1), ('comes', 1), ('age', 1), ('more', 2), ('often', 2), ('experience', 1), ('music', 1), ('has', 1), ('power', 1), ('transport', 1), ('us', 1), ('different', 2), ('place', 1), ('time', 2), ('blind', 1), ('sees', 1), ('than', 1), ('others', 1), ('heals', 1), ('all', 1), ('wounds', 1), ('only', 1), ('let', 1), ('it', 1), ('home', 1), ('where', 2), ('heart', 1), ('for', 1), ('many', 1), ('that', 1)])
出现单词的文档的数量,word_docs:
defaultdict(<class 'int'>, {'a': 2, 'journey': 1, 'is': 5, 'if': 3, 'will': 2, 'and': 4, 'forever': 1, 'life': 1, 'love': 2, 'in': 1, 'fall': 1, 'be': 1, 'you': 4, 'the': 5, 'with': 3, 'dreams': 1, 'touch': 1, 'lead': 1, 'stars': 1, 'but': 5, 'your': 1, 'may': 1, 'to': 2, 'never': 1, 'like': 1, 'follow': 1, 'destiny': 1, 'are': 4, 'they': 2, 'them': 1, 'memories': 2, 'treasures': 1, 'of': 1, 'past': 1, 'wisdom': 2, 'hold': 1, 'beauty': 1, 'our': 1, "heart's": 1, 'paintings': 1, 'most': 1, 'breathtaking': 1, 'beautiful': 1, 'nature': 1, 'always': 1, 'endless': 1, 'artist': 1, 'its': 1, 'having': 1, 'not': 1, 'content': 1, 'everything': 1, 'about': 1, 'happiness': 1, 'have': 1, 'being': 1, 'what': 1, 'true': 1, 'comes': 1, 'age': 1, 'more': 2, 'often': 2, 'experience': 1, 'power': 1, 'place': 1, 'us': 1, 'has': 1, 'transport': 1, 'time': 2, 'music': 1, 'different': 1, 'blind': 1, 'others': 1, 'sees': 1, 'than': 1, 'it': 1, 'all': 1, 'only': 1, 'heals': 1, 'let': 1, 'wounds': 1, 'where': 1, 'heart': 1, 'for': 1, 'many': 1, 'that': 1, 'home': 1})
单词索引对应的出现单词的文档的数量,index_docs:
defaultdict(<class 'int'>, {8: 2, 12: 1, 1: 5, 9: 3, 14: 2, 5: 4, 28: 1, 25: 1, 10: 2, 13: 1, 26: 1, 27: 1, 2: 4, 3: 5, 6: 3, 29: 1, 34: 1, 36: 1, 31: 1, 4: 5, 37: 1, 32: 1, 11: 2, 33: 1, 30: 1, 35: 1, 38: 1, 7: 4, 16: 2, 15: 1, 17: 2, 40: 1, 43: 1, 45: 1, 18: 2, 41: 1, 42: 1, 44: 1, 39: 1, 51: 1, 47: 1, 54: 1, 48: 1, 46: 1, 53: 1, 52: 1, 49: 1, 50: 1, 58: 1, 57: 1, 61: 1, 59: 1, 19: 1, 56: 1, 63: 1, 60: 1, 62: 1, 55: 1, 64: 1, 65: 1, 20: 2, 21: 2, 66: 1, 69: 1, 72: 1, 71: 1, 68: 1, 70: 1, 23: 2, 67: 1, 22: 1, 73: 1, 76: 1, 74: 1, 75: 1, 82: 1, 78: 1, 80: 1, 77: 1, 81: 1, 79: 1, 24: 1, 84: 1, 85: 1, 86: 1, 87: 1, 83: 1})对词频进行排序并输出排序结果
sort_fre = sorted(tokenizer.word_counts.items(), key = lambda i:i[1], reverse = True)
print("对词频进行排序, sort_fre:\n", sort_fre)运行结果显示如下:
对词频进行排序, sort_fre:
[('is', 7), ('you', 7), ('the', 7), ('but', 5), ('and', 4), ('with', 4), ('are', 4), ('a', 3), ('if', 3), ('love', 3), ('to', 3), ('journey', 2), ('in', 2), ('will', 2), ('them', 2), ('they', 2), ('memories', 2), ('wisdom', 2), ('about', 2), ('more', 2), ('often', 2), ('different', 2), ('time', 2), ('where', 2), ('life', 1), ('fall', 1), ('be', 1), ('forever', 1), ('dreams', 1), ('like', 1), ('stars', 1), ('may', 1), ('never', 1), ('touch', 1), ('follow', 1), ('lead', 1), ('your', 1), ('destiny', 1), ("heart's", 1), ('treasures', 1), ('hold', 1), ('beauty', 1), ('of', 1), ('our', 1), ('past', 1), ('nature', 1), ('most', 1), ('beautiful', 1), ('artist', 1), ('its', 1), ('paintings', 1), ('endless', 1), ('always', 1), ('breathtaking', 1), ('true', 1), ('happiness', 1), ('not', 1), ('having', 1), ('everything', 1), ('being', 1), ('content', 1), ('what', 1), ('have', 1), ('comes', 1), ('age', 1), ('experience', 1), ('music', 1), ('has', 1), ('power', 1), ('transport', 1), ('us', 1), ('place', 1), ('blind', 1), ('sees', 1), ('than', 1), ('others', 1), ('heals', 1), ('all', 1), ('wounds', 1), ('only', 1), ('let', 1), ('it', 1), ('home', 1), ('heart', 1), ('for', 1), ('many', 1), ('that', 1)]
将文本转化为sequence
print("将文档列表转换为向量, texts_to_sequences: \n", tokenizer.texts_to_sequences(texts))
print("将文档列表转换为矩阵表示, texts_to_matrix: \n", tokenizer.texts_to_matrix(texts))运行结果显示如下:
将文档列表转换为向量, texts_to_sequences:
[[25, 1, 8, 12, 5, 9, 2, 26, 13, 10, 6, 3, 12, 2, 14, 27, 13, 10, 28], [29, 7, 30, 31, 2, 32, 33, 34, 15, 4, 9, 2, 35, 15, 16, 14, 36, 2, 11, 37, 38], [17, 7, 3, 39, 40, 16, 41, 3, 18, 5, 42, 43, 44, 45], [46, 1, 3, 47, 48, 49, 50, 51, 7, 52, 5, 53, 54], [55, 56, 1, 57, 19, 58, 59, 4, 19, 60, 61, 6, 62, 2, 63], [18, 6, 4, 20, 21, 6], [3, 11, 11, 8, 22, 8, 22, 23], [10, 1, 4, 21, 20], [23, 4, 9, 2], [1, 24, 3, 1, 5, 1, 24, 3, 17, 7]]
将文档列表转换为矩阵表示, texts_to_matrix:
[[0. 1. 1. 1. 0. 1. 1. 0. 1. 1. 1. 0. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 1. 0. 0. 1. 0. 1. 0. 1. 0. 0. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 1. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 1. 0. 1. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1.
1. 1. 1. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 1. 1. 0. 1. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[0. 0. 0. 0. 1. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 1. 1. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0. 0. 1. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 1. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 1. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 1. 0. 1. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.
1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]pad_sequences填充数据
tokens = tokenizer.texts_to_sequences(texts)
print("将文档列表转换为向量, texts_to_sequences: \n", tokens)
tokens_pad = sequence.pad_sequences(tokens, maxlen=32, padding='post', truncating='pre')
print("tokens_pad: \n", tokens_pad)
运行结果显示如下:
将文档列表转换为向量, texts_to_sequences:
[[25, 1, 8, 12, 5, 9, 2, 26, 13, 10, 6, 3, 12, 2, 14, 27, 13, 10, 28],
[29, 7, 30, 31, 2, 32, 33, 34, 15, 4, 9, 2, 35, 15, 16, 14, 36, 2, 11, 37, 38],
[17, 7, 3, 39, 40, 16, 41, 3, 18, 5, 42, 43, 44, 45],
[46, 1, 3, 47, 48, 49, 50, 51, 7, 52, 5, 53, 54],
[55, 56, 1, 57, 19, 58, 59, 4, 19, 60, 61, 6, 62, 2, 63],
[18, 6, 4, 20, 21, 6], [3, 11, 11, 8, 22, 8, 22, 23],
[10, 1, 4, 21, 20], [23, 4, 9, 2], [1, 24, 3, 1, 5, 1, 24, 3, 17, 7]]
tokens_pad:
[[25 1 8 12 5 9 2 26 13 10 6 3 12 2 14 27 13 10 28 0 0 0 0 0
0 0 0 0 0 0 0 0]
[29 7 30 31 2 32 33 34 15 4 9 2 35 15 16 14 36 2 11 37 38 0 0 0
0 0 0 0 0 0 0 0]
[17 7 3 39 40 16 41 3 18 5 42 43 44 45 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[46 1 3 47 48 49 50 51 7 52 5 53 54 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[55 56 1 57 19 58 59 4 19 60 61 6 62 2 63 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[18 6 4 20 21 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[ 3 11 11 8 22 8 22 23 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[10 1 4 21 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[23 4 9 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[ 1 24 3 1 5 1 24 3 17 7 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]]
2.2 中文文本向量化
中文文本向量化,首先使用jieba分词,对文本进行分词处理,然后将词语在转化为数据序列。
import jieba
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
def cut_text(text):
seg_list = jieba.cut(text)
return ' '.join(seg_list)
texts = ["生活就像一场旅行,如果你爱上了这场旅行,你将永远充满爱。",
"梦想就像天上的星星,你可能永远无法触及,但如果你追随它们,它们将引领你走向你的命运。",
"真正的幸福不在于拥有一切,而在于满足于你所拥有的。",
"记忆是心灵的宝藏,它们蕴含着我们过去的智慧和美丽。",
"大自然是最美丽的艺术家,它的画作无边无际,总是令人叹为观止。",
"智慧往往随着年龄的增长而增加,但更多时候是随着经验的积累而到来。",
"音乐有能力将我们带到一个不同的地方、一个不同的时间。",
"爱是盲目的,但往往比别人看得更清楚。",
"时间可以治愈一切伤痛,但前提是你必须让它过去。",
"家是心灵的归宿,对许多人来说,也是记忆的所在。"]
tokenizer = Tokenizer(num_words=64, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n,。',)
tokenizer.fit_on_texts([cut_text(text) for text in texts])
print("处理的文档数量,document_count: ", tokenizer.document_count)
print("词语到索引的映射,word_index: \n", tokenizer.word_index)
print("索引到词语的映射,index_word: \n", tokenizer.index_word)
print("每个词语出现的总频次,word_counts: \n", tokenizer.word_counts)
print("出现词语的文档的数量,word_docs: \n", tokenizer.word_docs)
print("词语索引对应的出现词语的文档的数量,index_docs: \n", tokenizer.index_docs)
splits = [cut_text(text) for text in texts]
tokens = tokenizer.texts_to_sequences(splits)
tokens_pad = sequence.pad_sequences(tokens, maxlen=32, padding='post', truncating='pre')
print("splits:\n", splits)
print("tokens:\n", tokens)
print("tokens_pad:\n", tokens_pad)
运行结果显示如下:
处理的文档数量,document_count: 10
词语到索引的映射,word_index:
{'的': 1, '你': 2, '是': 3, '但': 4, '将': 5, '它们': 6, '而': 7, '就': 8, '像': 9, '旅行': 10, '如果': 11, '爱': 12, '永远': 13, '在于': 14, '拥有': 15, '一切': 16, '记忆': 17, '心灵': 18, '我们': 19, '过去': 20, '智慧': 21, '美丽': 22, '它': 23, '往往': 24, '随着': 25, '更': 26, '一个': 27, '不同': 28, '时间': 29, '生活': 30, '一场': 31, '上': 32, '了': 33, '这场': 34, '充满': 35, '梦想': 36, '天上': 37, '星星': 38, '可能': 39, '无法': 40, '触及': 41, '追随': 42, '引领': 43, '走向': 44, '命运': 45, '真正': 46, '幸福': 47, '不': 48, '满足': 49, '于': 50, '所': 51, '宝藏': 52, '蕴含着': 53, '和': 54, '大自然': 55, '最': 56, '艺术家': 57, '画作': 58, '无边无际': 59, '总是': 60, '令人': 61, '叹为观止': 62, '年龄': 63, '增长': 64, '增加': 65, '多': 66, '时候': 67, '经验': 68, '积累': 69, '到来': 70, '音乐': 71, '有': 72, '能力': 73, '带到': 74, '地方': 75, '、': 76, '爱是': 77, '盲目': 78, '比': 79, '别人': 80, '看得': 81, '清楚': 82, '可以': 83, '治愈': 84, '伤痛': 85, '前提': 86, '必须': 87, '让': 88, '家': 89, '归宿': 90, '对': 91, '许多': 92, '人': 93, '来说': 94, '也': 95, '所在': 96}
索引到词语的映射,index_word:
{1: '的', 2: '你', 3: '是', 4: '但', 5: '将', 6: '它们', 7: '而', 8: '就', 9: '像', 10: '旅行', 11: '如果', 12: '爱', 13: '永远', 14: '在于', 15: '拥有', 16: '一切', 17: '记忆', 18: '心灵', 19: '我们', 20: '过去', 21: '智慧', 22: '美丽', 23: '它', 24: '往往', 25: '随着', 26: '更', 27: '一个', 28: '不同', 29: '时间', 30: '生活', 31: '一场', 32: '上', 33: '了', 34: '这场', 35: '充满', 36: '梦想', 37: '天上', 38: '星星', 39: '可能', 40: '无法', 41: '触及', 42: '追随', 43: '引领', 44: '走向', 45: '命运', 46: '真正', 47: '幸福', 48: '不', 49: '满足', 50: '于', 51: '所', 52: '宝藏', 53: '蕴含着', 54: '和', 55: '大自然', 56: '最', 57: '艺术家', 58: '画作', 59: '无边无际', 60: '总是', 61: '令人', 62: '叹为观止', 63: '年龄', 64: '增长', 65: '增加', 66: '多', 67: '时候', 68: '经验', 69: '积累', 70: '到来', 71: '音乐', 72: '有', 73: '能力', 74: '带到', 75: '地方', 76: '、', 77: '爱是', 78: '盲目', 79: '比', 80: '别人', 81: '看得', 82: '清楚', 83: '可以', 84: '治愈', 85: '伤痛', 86: '前提', 87: '必须', 88: '让', 89: '家', 90: '归宿', 91: '对', 92: '许多', 93: '人', 94: '来说', 95: '也', 96: '所在'}
每个词语出现的总频次,word_counts:
OrderedDict([('生活', 1), ('就', 2), ('像', 2), ('一场', 1), ('旅行', 2), ('如果', 2), ('你', 8), ('爱', 2), ('上', 1), ('了', 1), ('这场', 1), ('将', 3), ('永远', 2), ('充满', 1), ('梦想', 1), ('天上', 1), ('的', 15), ('星星', 1), ('可能', 1), ('无法', 1), ('触及', 1), ('但', 4), ('追随', 1), ('它们', 3), ('引领', 1), ('走向', 1), ('命运', 1), ('真正', 1), ('幸福', 1), ('不', 1), ('在于', 2), ('拥有', 2), ('一切', 2), ('而', 3), ('满足', 1), ('于', 1), ('所', 1), ('记忆', 2), ('是', 6), ('心灵', 2), ('宝藏', 1), ('蕴含着', 1), ('我们', 2), ('过去', 2), ('智慧', 2), ('和', 1), ('美丽', 2), ('大自然', 1), ('最', 1), ('艺术家', 1), ('它', 2), ('画作', 1), ('无边无际', 1), ('总是', 1), ('令人', 1), ('叹为观止', 1), ('往往', 2), ('随着', 2), ('年龄', 1), ('增长', 1), ('增加', 1), ('更', 2), ('多', 1), ('时候', 1), ('经验', 1), ('积累', 1), ('到来', 1), ('音乐', 1), ('有', 1), ('能力', 1), ('带到', 1), ('一个', 2), ('不同', 2), ('地方', 1), ('、', 1), ('时间', 2), ('爱是', 1), ('盲目', 1), ('比', 1), ('别人', 1), ('看得', 1), ('清楚', 1), ('可以', 1), ('治愈', 1), ('伤痛', 1), ('前提', 1), ('必须', 1), ('让', 1), ('家', 1), ('归宿', 1), ('对', 1), ('许多', 1), ('人', 1), ('来说', 1), ('也', 1), ('所在', 1)])
出现词语的文档的数量,word_docs:
defaultdict(<class 'int'>, {'这场': 1, '旅行': 1, '一场': 1, '将': 3, '爱': 1, '充满': 1, '了': 1, '像': 2, '如果': 2, '生活': 1, '永远': 2, '上': 1, '你': 4, '就': 2, '梦想': 1, '但': 4, '天上': 1, '它们': 2, '追随': 1, '的': 8, '可能': 1, '无法': 1, '引领': 1, '走向': 1, '星星': 1, '命运': 1, '触及': 1, '一切': 2, '而': 2, '真正': 1, '拥有': 1, '在于': 1, '幸福': 1, '于': 1, '不': 1, '满足': 1, '所': 1, '记忆': 2, '和': 1, '是': 5, '智慧': 2, '我们': 2, '美丽': 2, '蕴含着': 1, '心灵': 2, '过去': 2, '宝藏': 1, '它': 2, '无边无际': 1, '叹为观止': 1, '令人': 1, '最': 1, '总是': 1, '大自然': 1, '艺术家': 1, '画作': 1, '经验': 1, '往往': 2, '随着': 1, '时候': 1, '更': 2, '增加': 1, '年龄': 1, '多': 1, '积累': 1, '增长': 1, '到来': 1, '、': 1, '带到': 1, '一个': 1, '地方': 1, '音乐': 1, '有': 1, '不同': 1, '能力': 1, '时间': 2, '看得': 1, '比': 1, '盲目': 1, '别人': 1, '清楚': 1, '爱是': 1, '可以': 1, '前提': 1, '治愈': 1, '伤痛': 1, '必须': 1, '让': 1, '对': 1, '也': 1, '许多': 1, '归宿': 1, '来说': 1, '所在': 1, '家': 1, '人': 1})
词语索引对应的出现词语的文档的数量,index_docs:
defaultdict(<class 'int'>, {34: 1, 10: 1, 31: 1, 5: 3, 12: 1, 35: 1, 33: 1, 9: 2, 11: 2, 30: 1, 13: 2, 32: 1, 2: 4, 8: 2, 36: 1, 4: 4, 37: 1, 6: 2, 42: 1, 1: 8, 39: 1, 40: 1, 43: 1, 44: 1, 38: 1, 45: 1, 41: 1, 16: 2, 7: 2, 46: 1, 15: 1, 14: 1, 47: 1, 50: 1, 48: 1, 49: 1, 51: 1, 17: 2, 54: 1, 3: 5, 21: 2, 19: 2, 22: 2, 53: 1, 18: 2, 20: 2, 52: 1, 23: 2, 59: 1, 62: 1, 61: 1, 56: 1, 60: 1, 55: 1, 57: 1, 58: 1, 68: 1, 24: 2, 25: 1, 67: 1, 26: 2, 65: 1, 63: 1, 66: 1, 69: 1, 64: 1, 70: 1, 76: 1, 74: 1, 27: 1, 75: 1, 71: 1, 72: 1, 28: 1, 73: 1, 29: 2, 81: 1, 79: 1, 78: 1, 80: 1, 82: 1, 77: 1, 83: 1, 86: 1, 84: 1, 85: 1, 87: 1, 88: 1, 91: 1, 95: 1, 92: 1, 90: 1, 94: 1, 96: 1, 89: 1, 93: 1})
splits:
['生活 就 像 一场 旅行 , 如果 你 爱 上 了 这场 旅行 , 你 将 永远 充满 爱 。', '梦想 就 像 天上 的 星星 , 你 可能 永远 无法 触及 , 但 如果 你 追随 它们 , 它们 将 引领 你 走向 你 的 命运 。', '真正 的 幸福 不 在于 拥有 一切 , 而 在于 满足 于 你 所 拥有 的 。', '记忆 是 心灵 的 宝藏 , 它们 蕴含着 我们 过去 的 智慧 和 美丽 。', '大自然 是 最 美丽 的 艺术家 , 它 的 画作 无边无际 , 总是 令人 叹为观止 。', '智慧 往往 随着 年龄 的 增长 而 增加 , 但 更 多 时候 是 随着 经验 的 积累 而 到来 。', '音乐 有 能力 将 我们 带到 一个 不同 的 地方 、 一个 不同 的 时间 。', '爱是 盲目 的 , 但 往往 比 别人 看得 更 清楚 。', '时间 可以 治愈 一切 伤痛 , 但 前提 是 你 必须 让 它 过去 。', '家 是 心灵 的 归宿 , 对 许多 人 来说 , 也 是 记忆 的 所在 。']
tokens:
[[30, 8, 9, 31, 10, 11, 2, 12, 32, 33, 34, 10, 2, 5, 13, 35, 12], [36, 8, 9, 37, 1, 38, 2, 39, 13, 40, 41, 4, 11, 2, 42, 6, 6, 5, 43, 2, 44, 2, 1, 45], [46, 1, 47, 48, 14, 15, 16, 7, 14, 49, 50, 2, 51, 15, 1], [17, 3, 18, 1, 52, 6, 53, 19, 20, 1, 21, 54, 22], [55, 3, 56, 22, 1, 57, 23, 1, 58, 59, 60, 61, 62], [21, 24, 25, 63, 1, 7, 4, 26, 3, 25, 1, 7], [5, 19, 27, 28, 1, 27, 28, 1, 29], [1, 4, 24, 26], [29, 16, 4, 3, 2, 23, 20], [3, 18, 1, 3, 17, 1]]
tokens_pad:
[[30 8 9 31 10 11 2 12 32 33 34 10 2 5 13 35 12 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[36 8 9 37 1 38 2 39 13 40 41 4 11 2 42 6 6 5 43 2 44 2 1 45
0 0 0 0 0 0 0 0]
[46 1 47 48 14 15 16 7 14 49 50 2 51 15 1 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[17 3 18 1 52 6 53 19 20 1 21 54 22 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[55 3 56 22 1 57 23 1 58 59 60 61 62 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[21 24 25 63 1 7 4 26 3 25 1 7 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[ 5 19 27 28 1 27 28 1 29 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[ 1 4 24 26 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[29 16 4 3 2 23 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[ 3 18 1 3 17 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]]3 总结
文本向量化是自然语言处理必不可少的操作,本文通过实际例子,分别介绍了使用Tokenizer对中文、英文文本预处理方法,处理后输出的向量化数据,作为深度神经网络模型的输入进行训练和推理。