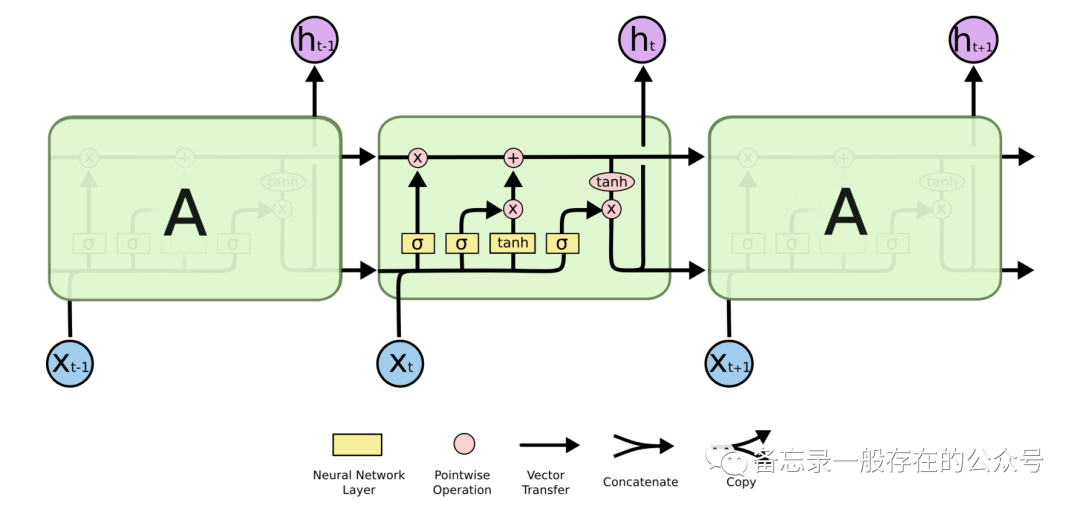
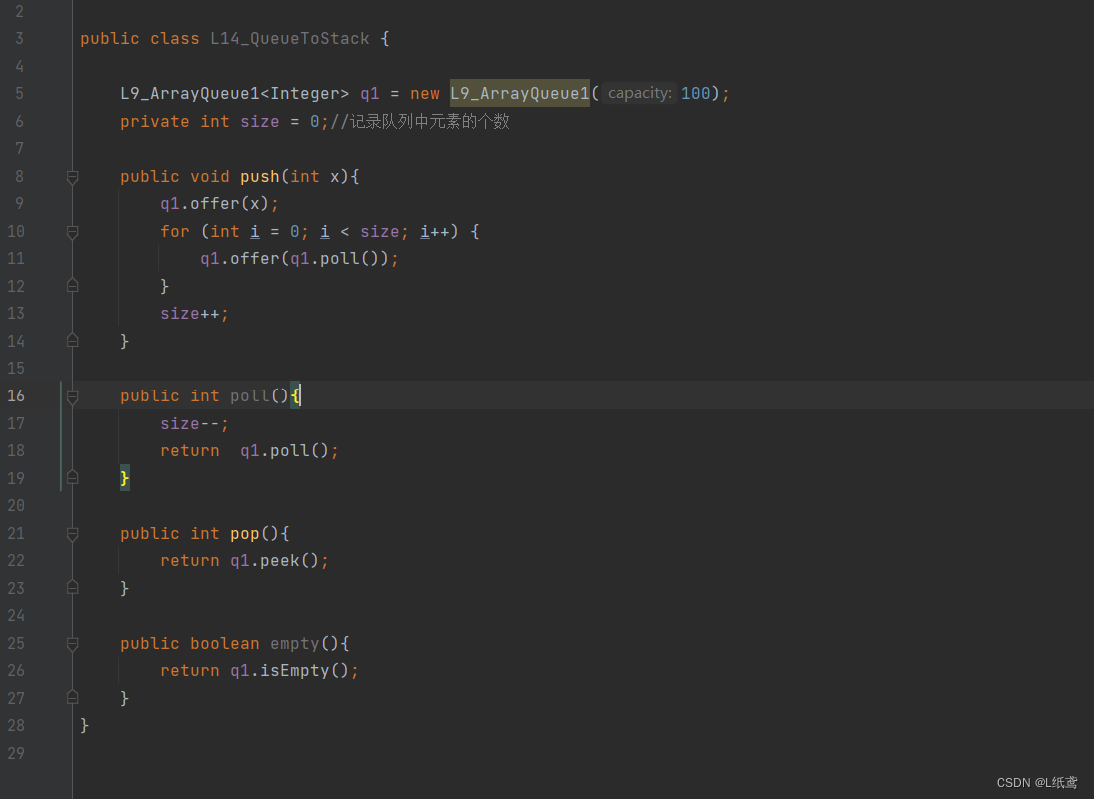
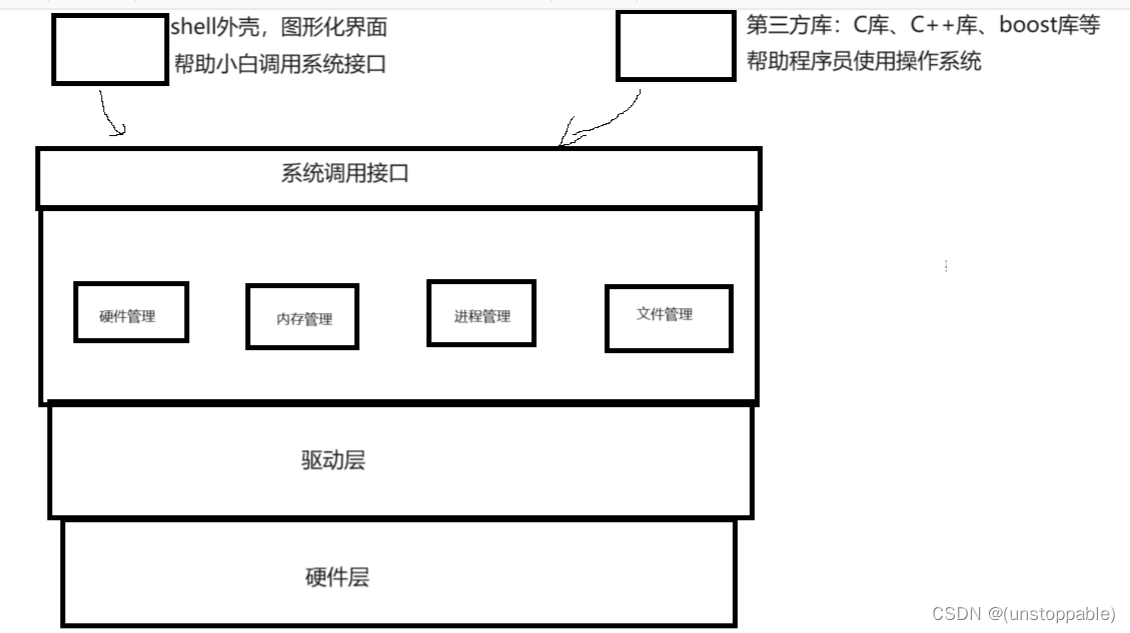
RNN Cell:
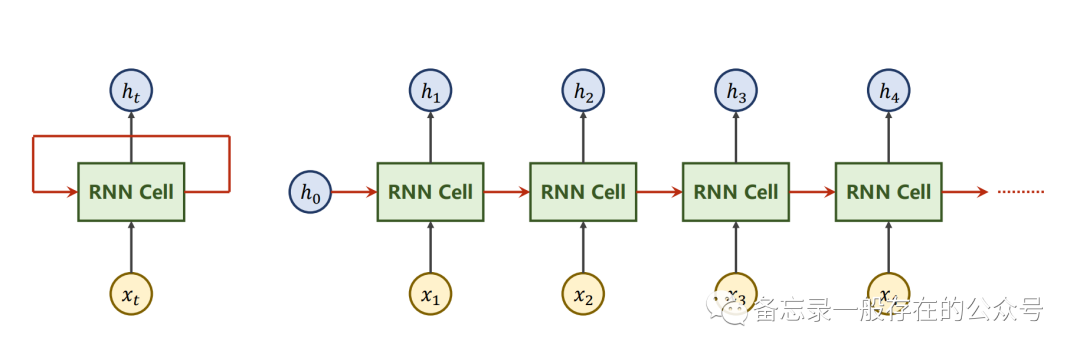
h0和x1生成h1,把h1作为输出送到下一次的RNN Cell里面。(h1=linear(h0,x1))
RNN计算过程:
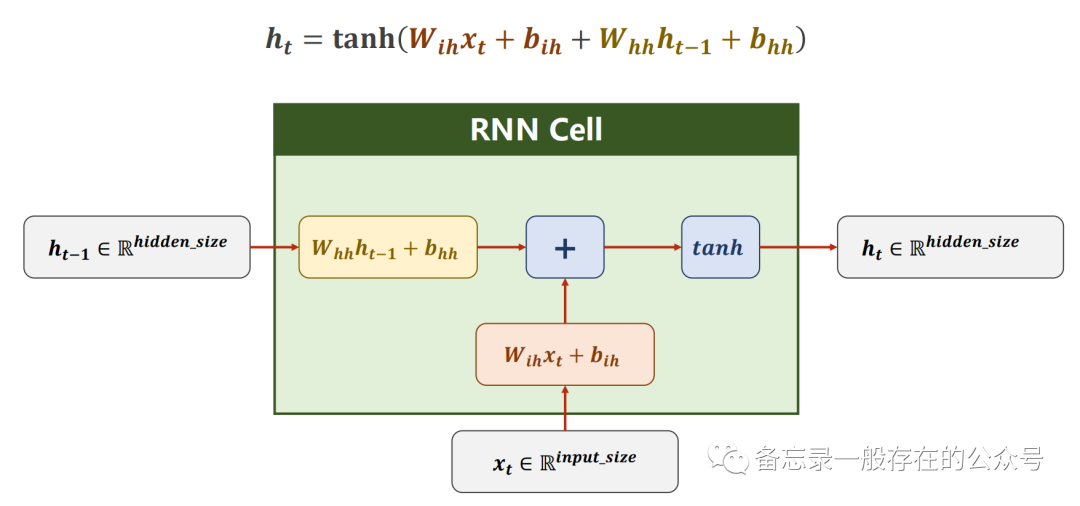
输入先做线性变换,循环神经网络常用的激活函数是tanh(±1区间)。
构造RNN Cell:

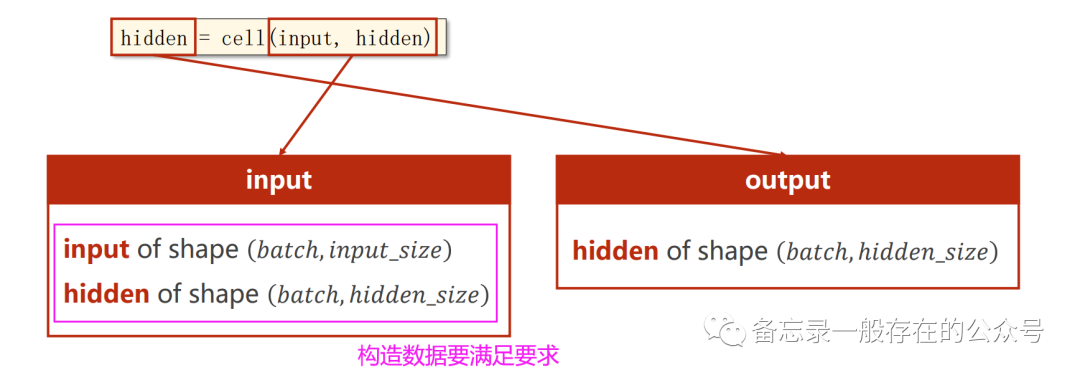
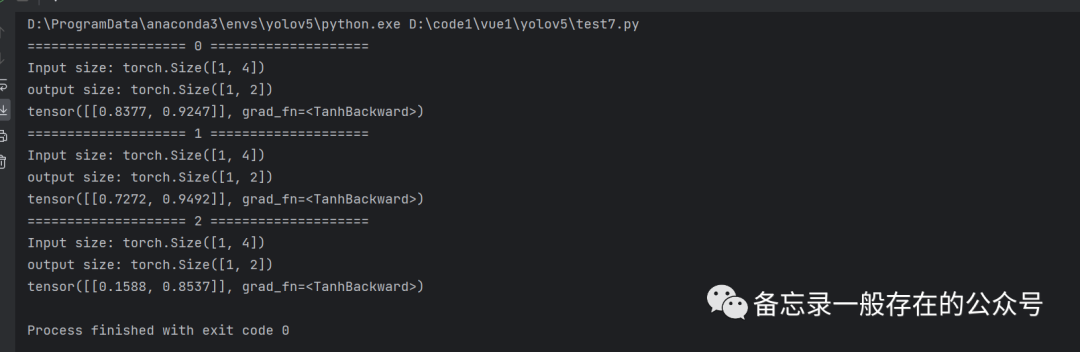
代码:
import torchbatch_size = 1seq_len = 3input_size = 4hidden_size = 2# Construction of RNNCellcell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)# Wrapping the sequence into:(seqLen,batchSize,InputSize)dataset = torch.randn(seq_len, batch_size, input_size) # (3,1,4) ; 序列数据# Initializing the hidden to zerohidden = torch.zeros(batch_size, hidden_size) # (1,2) ;隐层,全0for idx, input in enumerate(dataset):print('=' * 20, idx, '=' * 20) #分割线,20个=号print('Input size:', input.shape) # (batch_size, input_size)# 按序列依次输入到cell中,seq_len=3,故循环3次hidden = cell(input, hidden) # 返回的hidden是下一次的输入之一,循环使用同一个cell;这一次的输入+上一次的隐层#隐层维度是batch_size×hidden_size,就是“torch.Size([1,2])”print('output size:', hidden.shape) # (batch_size, hidden_size)print(hidden)
RNN本质是一个线性层。
用RNN首先要把维度搞清楚,数据集的维度多了序列这样一个维度。
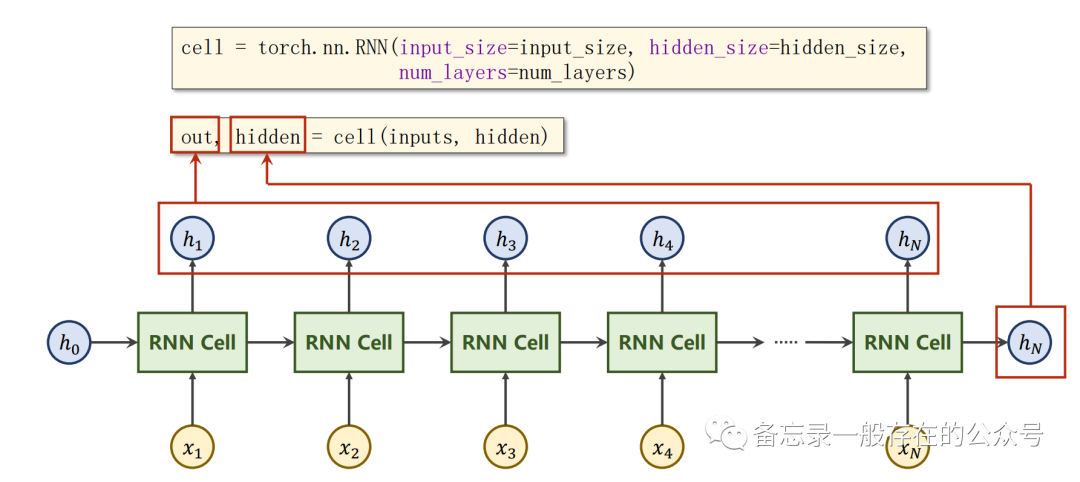
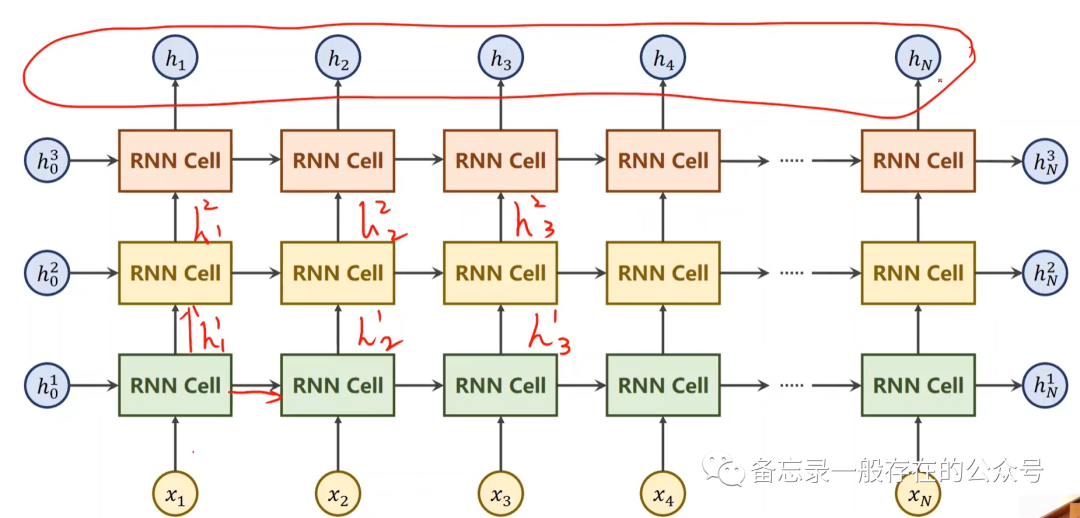
每一层都有对应输出。同样颜色的RNN Cell都是一个线性层,也就是说一共只有3个线性层。
代码:
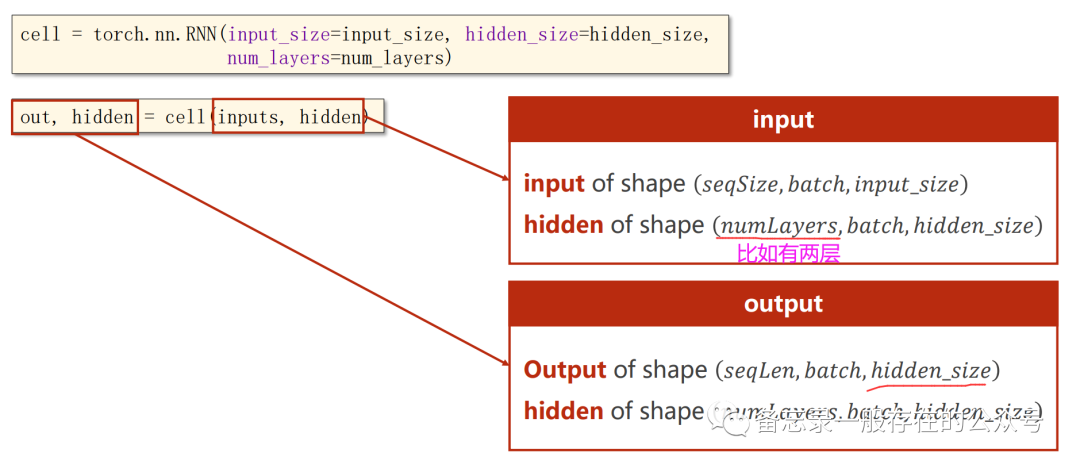
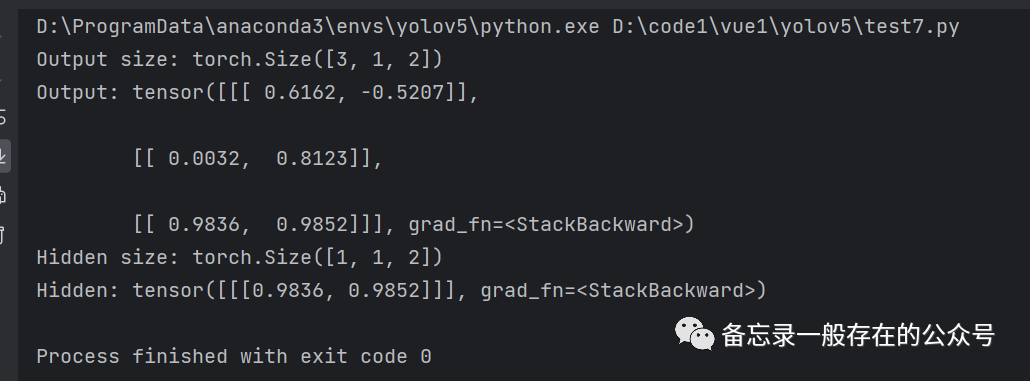
import torchbatch_size = 1 #参数构造seq_len = 3input_size = 4hidden_size = 2num_layers = 1 # RNN层数# Construction of RNNrnn = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers)# Wrapping the sequence into:(seqLen,batchSize,InputSize)inputs = torch.randn(seq_len, batch_size, input_size) # (3,1,4)# Initializing the hidden to zerohidden = torch.zeros(num_layers, batch_size, hidden_size) # (1,1,2),隐层维数output, hidden = rnn(inputs, hidden) # RNN内部包含了循环,故这里只需把整个序列输入即可print('Output size:', output.shape) # (seq_len, batch_size, hidden_size)print('Output:', output)print('Hidden size:', hidden.shape) # (num_layers, batch_size, hidden_size)print('Hidden:', hidden)
预测字符串(RNN Cell):
import torch# 1、确定参数input_size = 4hidden_size = 4batch_size = 1# 2、准备数据index2char = ['e', 'h', 'l', 'o'] #字典x_data = [1, 0, 2, 2, 3] #用字典中的索引(数字)表示来表示helloy_data = [3, 1, 2, 3, 2] #标签:ohlolone_hot_lookup = [[1, 0, 0, 0], # 用来将x_data转换为one-hot向量的参照表[0, 1, 0, 0],[0, 0, 1, 0],[0, 0, 0, 1]]x_one_hot = [one_hot_lookup[x] for x in x_data] #将x_data转换为one-hot向量inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size) #(𝒔𝒆𝒒𝑳𝒆𝒏,𝒃𝒂𝒕𝒄𝒉𝑺𝒊𝒛𝒆,𝒊𝒏𝒑𝒖𝒕𝑺𝒊𝒛𝒆)labels = torch.LongTensor(y_data).view(-1, 1) # (seqLen*batchSize,𝟏).计算交叉熵损失时标签不需要我们进行one-hot编码,其内部会自动进行处理# 3、构建模型class Model(torch.nn.Module):def __init__(self, input_size, hidden_size, batch_size):super(Model, self).__init__()self.batch_size = batch_sizeself.input_size = input_sizeself.hidden_size = hidden_sizeself.rnncell = torch.nn.RNNCell(input_size=self.input_size, hidden_size=self.hidden_size)def forward(self, input, hidden):hidden = self.rnncell(input, hidden)return hiddendef init_hidden(self): #生成初始化隐藏层,需要batch_size。return torch.zeros(self.batch_size, self.hidden_size)net = Model(input_size, hidden_size, batch_size)# 4、损失和优化器criterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(net.parameters(), lr=0.1) # Adam优化器# 5、训练for epoch in range(15):loss = 0optimizer.zero_grad() #梯度清零hidden = net.init_hidden() # 初始化隐藏层print('Predicted string:', end='')for input, label in zip(inputs, labels): #每次输入一个字符,即按序列次序进行循环。(input=seq×b×inputsize)hidden = net(input, hidden)loss += criterion(hidden, label) # 计算损失,不用item(),因为后面还要反向传播_, idx = hidden.max(dim=1) # 选取最大值的索引print(index2char[idx.item()], end='') # 打印预测的字符loss.backward() # 反向传播optimizer.step() # 更新参数print(', Epoch [%d/15] loss: %.4f' % (epoch + 1, loss.item()))
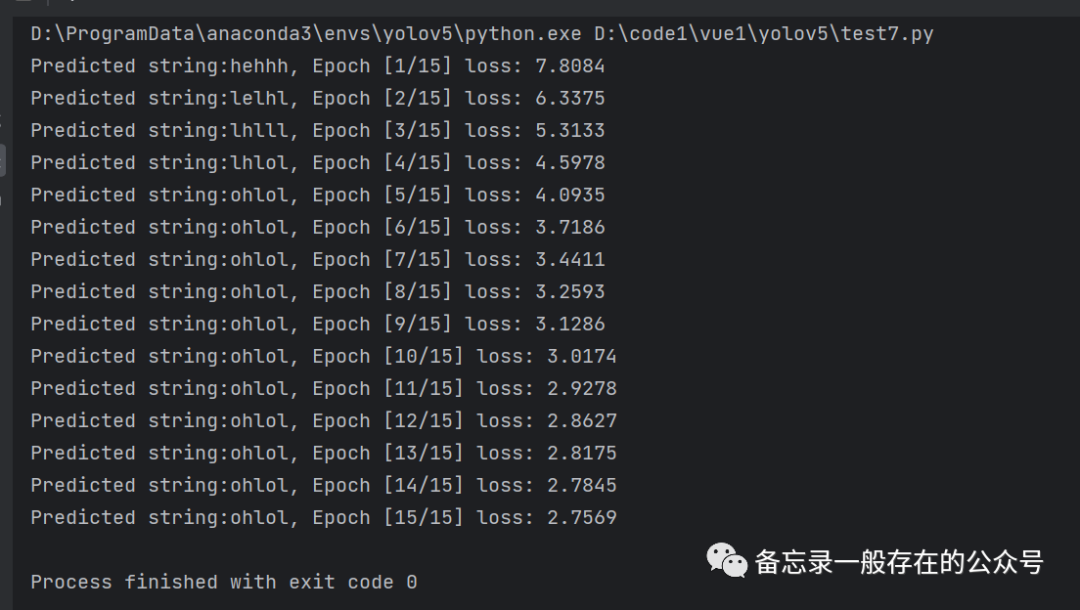
预测字符串(RNN):
import torch# 1、确定参数seq_len = 5input_size = 4hidden_size = 4batch_size = 1# 2、准备数据index2char = ['e', 'h', 'l', 'o'] #字典。将来可以根据索引把字母拿出来x_data = [1, 0, 2, 2, 3] #用字典中的索引(数字)表示来表示helloy_data = [3, 1, 2, 3, 2] #标签:ohlolone_hot_lookup = [[1, 0, 0, 0], # 用来将x_data转换为one-hot向量的参照表[0, 1, 0, 0], # 独热向量[0, 0, 1, 0],[0, 0, 0, 1]]x_one_hot = [one_hot_lookup[x] for x in x_data] #将x_data转换为one-hot向量inputs = torch.Tensor(x_one_hot).view(seq_len, batch_size,input_size) #(𝒔𝒆𝒒𝑳𝒆𝒏,𝒃𝒂𝒕𝒄𝒉𝑺𝒊𝒛𝒆,𝒊𝒏𝒑𝒖𝒕𝑺𝒊𝒛𝒆)labels = torch.LongTensor(y_data)# 3、构建模型class Model(torch.nn.Module):def __init__(self, input_size, hidden_size, batch_size, num_layers=1):super(Model, self).__init__()self.num_layers = num_layers # 1self.batch_size = batch_size # 1self.input_size = input_size # 4self.hidden_size = hidden_size # 4self.rnn = torch.nn.RNN(input_size=self.input_size, hidden_size=self.hidden_size, num_layers=num_layers)def forward(self, input):hidden = torch.zeros(self.num_layers, self.batch_size, self.hidden_size)out, _ = self.rnn(input, hidden) # out: tensor of shape (seq_len, batch, hidden_size)return out.view(-1, self.hidden_size) # 将输出的三维张量转换为二维张量,(𝒔𝒆𝒒𝑳𝒆𝒏×𝒃𝒂𝒕𝒄𝒉𝑺𝒊𝒛𝒆,𝒉𝒊𝒅𝒅𝒆𝒏𝑺𝒊𝒛𝒆)def init_hidden(self): #初始化隐藏层,需要batch_sizereturn torch.zeros(self.batch_size, self.hidden_size)net = Model(input_size, hidden_size, batch_size)# 4、损失和优化器criterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(net.parameters(), lr=0.05) # Adam优化器# 5、训练步骤for epoch in range(15):optimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()_, idx = outputs.max(dim=1)idx = idx.data.numpy()print('Predicted string: ', ''.join([index2char[x] for x in idx]), end='')print(', Epoch [%d/15] loss: %.4f' % (epoch + 1, loss.item()))
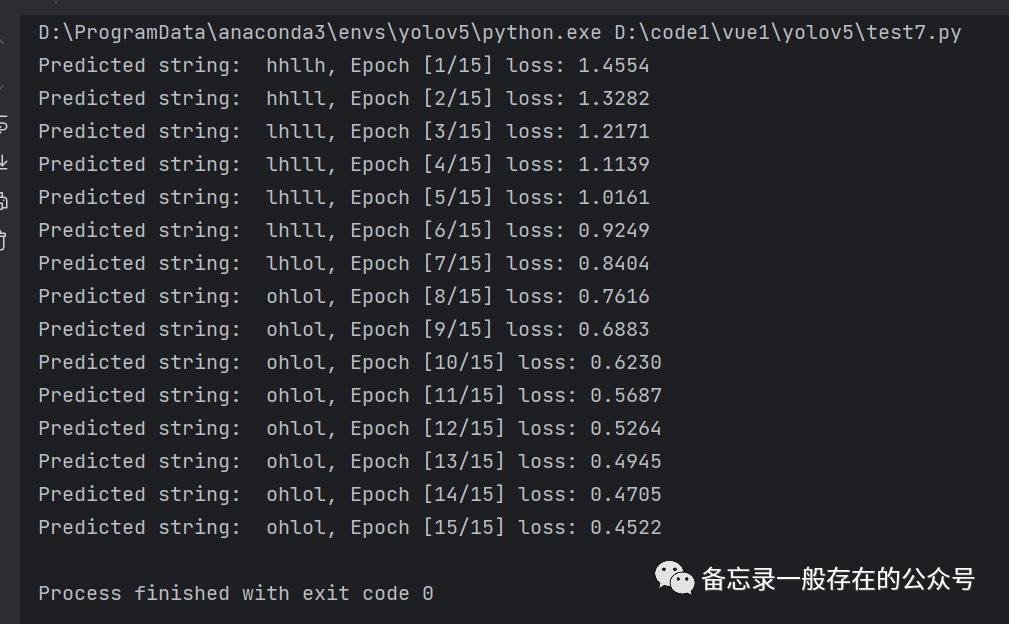
使用embedding and linear layer:
import torch# 1、确定参数num_class = 4input_size = 4hidden_size = 8embedding_size = 10num_layers = 2batch_size = 1seq_len = 5# 2、准备数据index2char = ['e', 'h', 'l', 'o'] #字典x_data = [[1, 0, 2, 2, 3]] # (batch_size, seq_len) 用字典中的索引(数字)表示来表示helloy_data = [3, 1, 2, 3, 2] # (batch_size * seq_len) 标签:ohlolinputs = torch.LongTensor(x_data) # (batch_size, seq_len)labels = torch.LongTensor(y_data) # (batch_size * seq_len)# 3、构建模型class Model(torch.nn.Module):def __init__(self):super(Model, self).__init__()self.emb = torch.nn.Embedding(num_class, embedding_size)self.rnn = torch.nn.RNN(input_size=embedding_size, hidden_size=hidden_size, num_layers=num_layers,batch_first=True)self.fc = torch.nn.Linear(hidden_size, num_class)def forward(self, x):hidden = torch.zeros(num_layers, x.size(0), hidden_size) # (num_layers, batch_size, hidden_size)x = self.emb(x) # 返回(batch_size, seq_len, embedding_size)x, _ = self.rnn(x, hidden) # 返回(batch_size, seq_len, hidden_size)x = self.fc(x) # 返回(batch_size, seq_len, num_class)return x.view(-1, num_class) # (batch_size * seq_len, num_class)net = Model()# 4、损失和优化器criterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(net.parameters(), lr=0.05) # Adam优化器# 5、训练for epoch in range(15):optimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()_, idx = outputs.max(dim=1)idx = idx.data.numpy()print('Predicted string: ', ''.join([index2char[x] for x in idx]), end='')print(', Epoch [%d/15] loss: %.4f' % (epoch + 1, loss.item()))
番外:LSTM