视频版本:
ChatGPT实战-构建文章分析AI聊天机器人
简介
本文实现如下功能:
当浏览一篇文章,点击分享,分享到聊天软件的对话框中。它就会生成一个文章的总结和分析结果。例如分析是否有逻辑问题,是否有诱导购买,是否有焦虑制造。
一起来看看怎么实现的吧。
这里以飞书机器人为例,当然你也可以用别的平台,例如微信、钉钉。
整体方案介绍
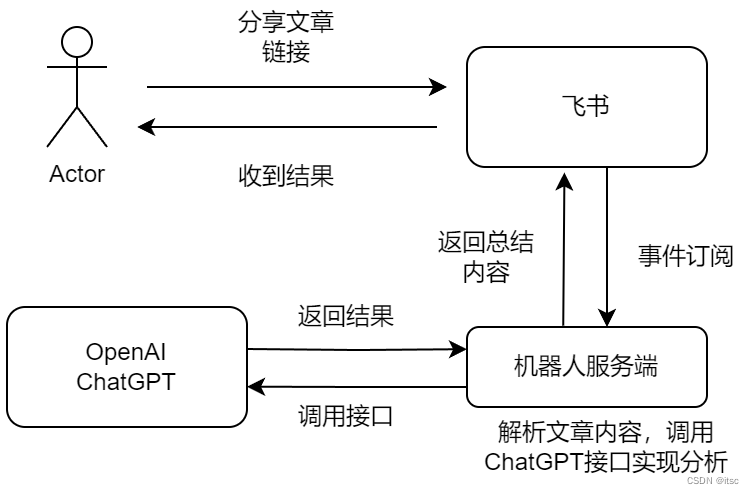
- 首先,用户将文章链接发送给飞书聊天机器人;
- 飞书通过事件订阅将内容发给机器人服务端;
- 服务端收到链接后访问网址获取内容,并调用chatgpt接口进行总结;
- 将总结后的内容回复给用户。
下面我们来一步步实现。
前置准备
在开始之,你需要准备好ChatGPT的API访问key和一台web服务器。
准备web服务器的时候,需要注意安全问题。例如服务器关闭root登录,禁止密码登录。采用ssh key的方式进行登录。
然后防火墙需要在云厂商的控制台开启。不然外部无法访问。
代码
在github中也可以找到:shanchuantian/paper_analyze_bot.git
有三个文件,入口在main.py中。
main.py
import json
import uuid
import requests
from fastapi import FastAPI
from fastapi.params import Body
from fastapi import BackgroundTasks
from openai import chat
from parse_wexin_paper import get_paper_content
app = FastAPI()
@app.get("/")
def root():
return {"message": "Hello World"}
def get_tenant_access_token():
url = 'https://open.feishu.cn/open-apis/auth/v3/app_access_token/internal'
body = {
"app_id": "cli_xxx", # todo 可以将其放入环境变量中,不能泄漏!!!!
"app_secret": "jwxxx" # todo 可以将其放入环境变量中,不能泄漏!!!!
}
res = requests.post(url, json=body)
return res.json().get('tenant_access_token')
def send_response(message_id, text_content):
# 回复消息
url = f'https://open.feishu.cn/open-apis/im/v1/messages/{message_id}/reply'
res_content = {
"text": text_content
}
response = {
"content": json.dumps(res_content),
"msg_type": "text",
"uuid": str(uuid.uuid4())
}
token = get_tenant_access_token()
headers = {
'Authorization': f'Bearer {token}',
'Content-Type': f'application/json; charset=utf-8'
}
print(f'response url:{url}, header:{headers}, data:{response}')
requests.post(url, headers=headers, json=response)
def handle_task(payload):
# 用户发过来的消息
content = payload.get('event').get('message').get('content')
print(f'content:{content}')
# 获取文章内容
paper_content = get_paper_content(json.loads(content).get('text'))
prompt = f"""我会给你一篇由<<begin>>和<<end>>包含的文章,请完成如下任务:
1.总结一下文章,以列表的形式输出关键要点,保持语句通顺,简单易懂。
2.分析文章中是否有逻辑问题,如果有请依次列出问题,写在下面的【逻辑问题列表】中,没有则保持空。
3.分析文章中是否有诱导读者购买课程、商品等行为,如果有请写在下面的【诱导购买列表】中,没有则保持空。
4.分析文章中是否有焦虑制造倾向,如果有请写在下面的【焦虑制造列表】中,没有则保持空。
严格按照如下格式输出:
【总结】
这里放总结内容。
【逻辑问题列表】
在这里列出逻辑问题。
【诱导购买列表】
在这里列出诱导购买内容。
【焦虑制造列表】
在这里放焦虑制造内容。
这是文章:
<<begin>>
{paper_content}
<<end>>"""
print(f'prompt:{prompt}')
# 调用ChatGPT进行总结
summary = chat(prompt)
message_id = payload.get('event').get('message').get('message_id')
# 回复消息
send_response(message_id, summary)
@app.post("/")
async def say_hello(background_tasks: BackgroundTasks, payload: dict = Body(...)):
# 检测到CHALLENGE标记就直接返回,以通过飞书的接入
challenge = payload.get('CHALLENGE')
if challenge:
print(f'CHALLENGE flag is exist, return it.')
return payload
# print(f'payload:{json.dumps(payload)}')
# feishu要求1秒内返回,所以此处起一个后台任务处理
background_tasks.add_task(handle_task, payload)
print('###### i will return immediately。。。')
return ''
if __name__ == '__main__':
get_tenant_access_token()
openai.py
import requests
url = "https://openai.api2d.net/v1/chat/completions"
headers = {
'Content-Type': 'application/json',
# todo 不能泄漏
'Authorization': 'Bearer fkxxx' # <-- 把 fkxxxxx 替换成你自己的 Forward Key,注意前面的 Bearer 要保留,并且和 Key 中间有一个空格。
}
def chat(content, role='user', model='gpt-3.5-turbo'):
data = {
"model": model,
"messages": [{"role": role, "content": content}]
}
print('start chat to chatgpt....')
response = requests.post(url, headers=headers, json=data)
print("ChatGPT Status Code", response.status_code)
print("ChatGPT JSON Response ", response.json())
return response.json().get('choices')[0].get('message').get('content')
if __name__ == '__main__':
content = '你好'
chat(content=content)
parse_wexin_paper.py
import requests
from lxml import etree
import os
def get_paper_content(url):
html = requests.get(url).text
# print(f'html:{html}')
con = etree.HTML(html)
# 获取标题
h2 = con.xpath('//h1[@class="rich_media_title "]/text()')
h2 = ",".join(map(str, h2))
h2 = os.linesep.join([s for s in h2.splitlines(True) if s.strip()])
h2 = h2.rstrip() # 去除右空行
print(f'h2:{h2}')
# print(h2)
# 获取正文
p_text = ''
span = con.xpath('//p | //section/span') # 通过‘|’可以增加筛选的条件
print(f'span:{span}')
# print(span)
for p_tex in span:
p_tex = p_tex.xpath('string(.)')
p_text = p_text + p_tex + '\n'
# print(p_tex)
# print(p_text)
# 保存内容
con_text = '%s%s%s%s' % (h2, '\n', p_text, '\n')
return con_text
if __name__ == '__main__':
# url = input("请输入要采集的微信公众号文章地址:")
url = "https://mp.weixin.qq.com/s/xxx"
get_paper_content(url)
我们通过fast API这个web框架来实现web服务。在这里我们需要实现两个功能:
一个是接入服务功能,另一个是我们的业务逻辑。
运行服务可以直接通过uvicorn 运行:
uvicorn main:app --host 0.0.0.0 --port 7011
飞书权限申请
主要是在飞书开放平台申请应用,然后添加权限,事件订阅发布版本。(截图太多了,上面视频中有详细介绍)
接下来就可以愉快的进行使用啦。




![buuctf-[网鼎杯 2020 朱雀组]phpweb](https://img-blog.csdnimg.cn/51f9829751524b0fb1768ce7aaee5765.png)