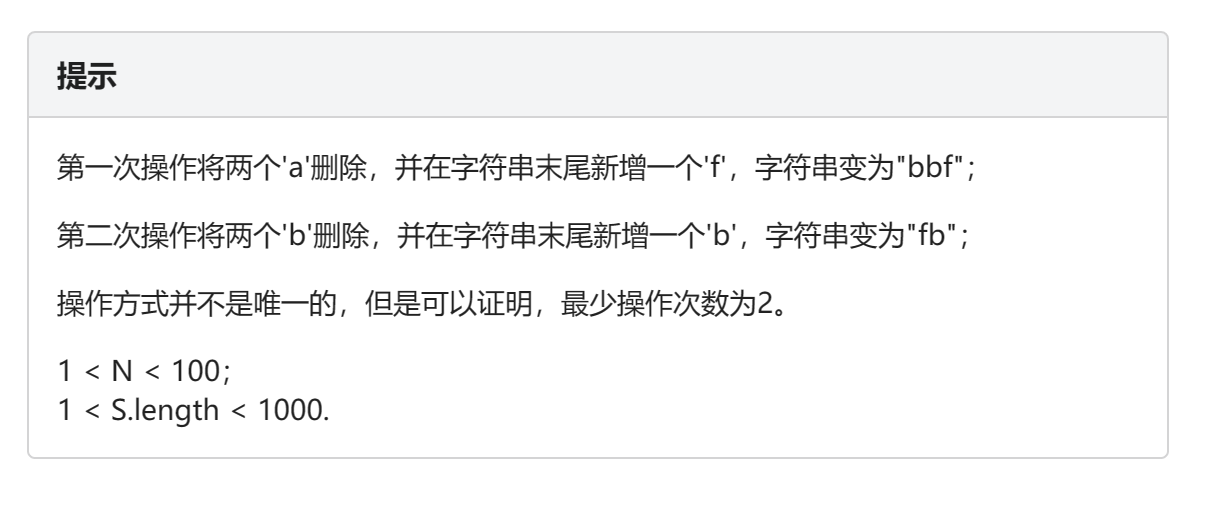
此题不容易考虑全部情况,对于未出现字母不够的情况,需要自己模拟假设一下,才会发现处理方法的玄妙
// 分析题目不难发现,这道题其实和字符具体长啥样没关系
// 只和字母的个数有关系,所以我们只需统计字母的个数
// 总体思路分两个情况
// 第一个情况,若有不存在的字母
// 例如abab,除ab以外的字母都不存在,可以将两个a转化为单个z,以此类推
// 当所有字母都被占用的时候,那么就进入到第二种情况
// 把所有多出来的字符全都转化成某一个字母,比如a
// 此时的情况一定是a有n个,其他字母全是1个,我们只需要消除多余的a即可
// 每次删掉两个a,再转化成一个a,这样操作一次就少一个a
// 总会变成所有字母都只剩下一个的情况,即达成题意不重复
#include<iostream>
#include<vector>
#include <string>
using namespace std;
int n;
string s;
void solve() {
while(n--) {
cin >> s;
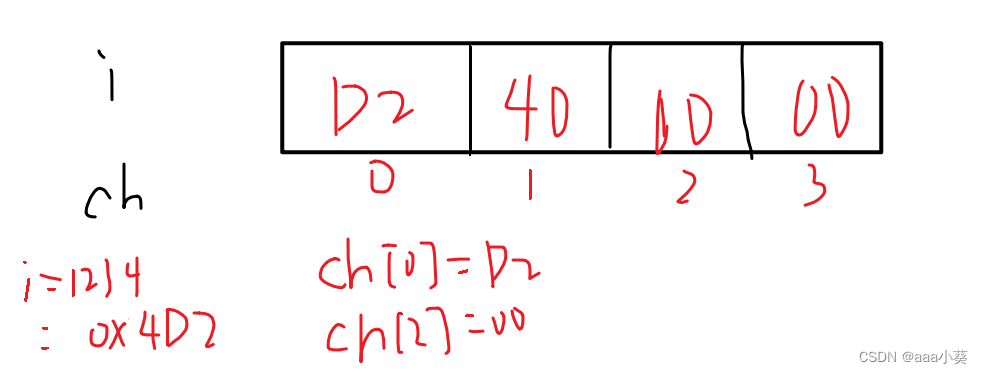
vector<int> a(26, 0); //建立数组储存26个字母的出现次数
for(int i = 0; i < s.size(); ++i) { //储存数据
a[s[i] - 97]++;
}
int cnt = 0;
for(int i = 0; i < 26; ++i) {
if(a[i] > 1) { // 找出用第一种情况要操作的次数
int temp = a[i] / 2;
cnt += temp;
a[i] = a[i] - temp * 2; // 减去被删除的字母
}
}
int cnt0 = 0; // 统计此时未出现的字母个数
for(int i = 0; i < 26; ++i) {
if(a[i] == 0) {
cnt0++;
}
}
int ans;
if(cnt > cnt0) { // 如果此时未出现字母的个数不够
ans = cnt + (cnt - cnt0);
// 第一个cnt代表第一种情况的操作次数
// cnt - cnt0代表将所有未被消化的字母累加到a头上
// 因每次操作会消除掉一个多余的a
// 所以最终答案是 第一种情况的操作次数 + (第二种情况的操作次数)
}
else {
ans = cnt;// 第一种情况可以容纳,那么操作次数就是答案
}
cout << ans << endl;
}
}
int main() {
while(cin >> n) {
solve();
}
return 0;
}