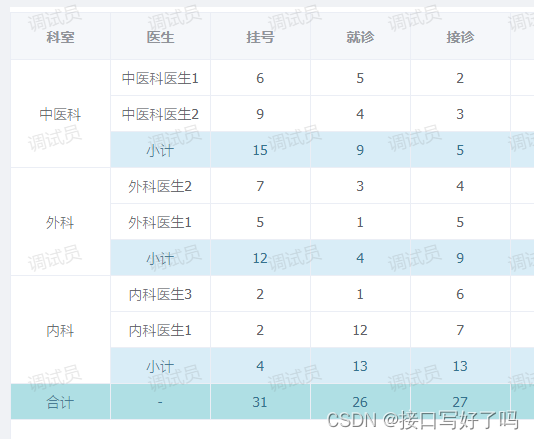
先看几个问题
- 什么事循环依赖?
- 什么情况下循环依赖可以被处理?
- spring是如何解决循环依赖的?
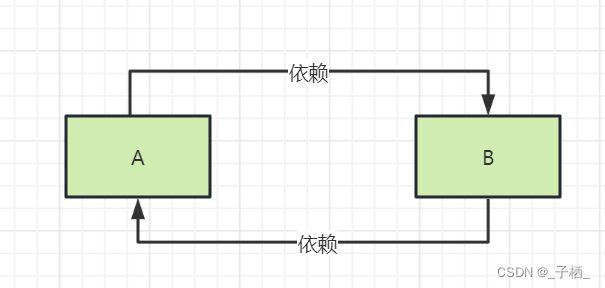
什么是循环依赖?
简单理解就是实例 A 依赖实例 B 的同时 B 也依赖了 A
@Component
public class A {
// A 中依赖 B
@Autowired
private B b;
}
@Component
public class B {
// B 中依赖 A
@Autowired
private A a;
}
什么情况下循环依赖可以被处理?
spring 解决循环依赖是有前提条件的
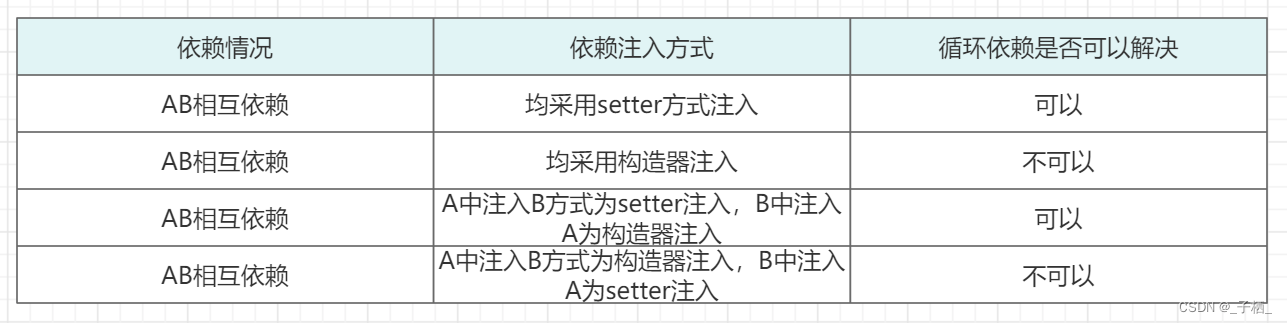
- 出现循环依赖的 bean 必须是单例的
- 依赖注入的方式不能全是构造器注入的方式
其中第一点是很好理解的,第二点:不能全是构造器注入是什么意思呢?用代码说话
@Component
public class A {
// A 中依赖 B
public A(B b){
}
}
@Component
public class B {
// B 中依赖 A
public B(A a){
}
}
为了测试循环依赖的解决情况跟注入方式的关系,我们做如下四种情况的测试
Spring是如何解决循环依赖的?
分两种情况进行说明:
- 简单的循环依赖(没有AOP)
- 含有AOP的循环依赖
简单的循环依赖(没有AOP)
还是使用上面的例子:
@Component
public class A {
// A 中依赖 B
@Autowired
private B b;
}
@Component
public class B {
// B 中依赖 A
@Autowired
private A a;
}
通过前面我们知道这种循环依赖是可以解决的,下面进行分析:
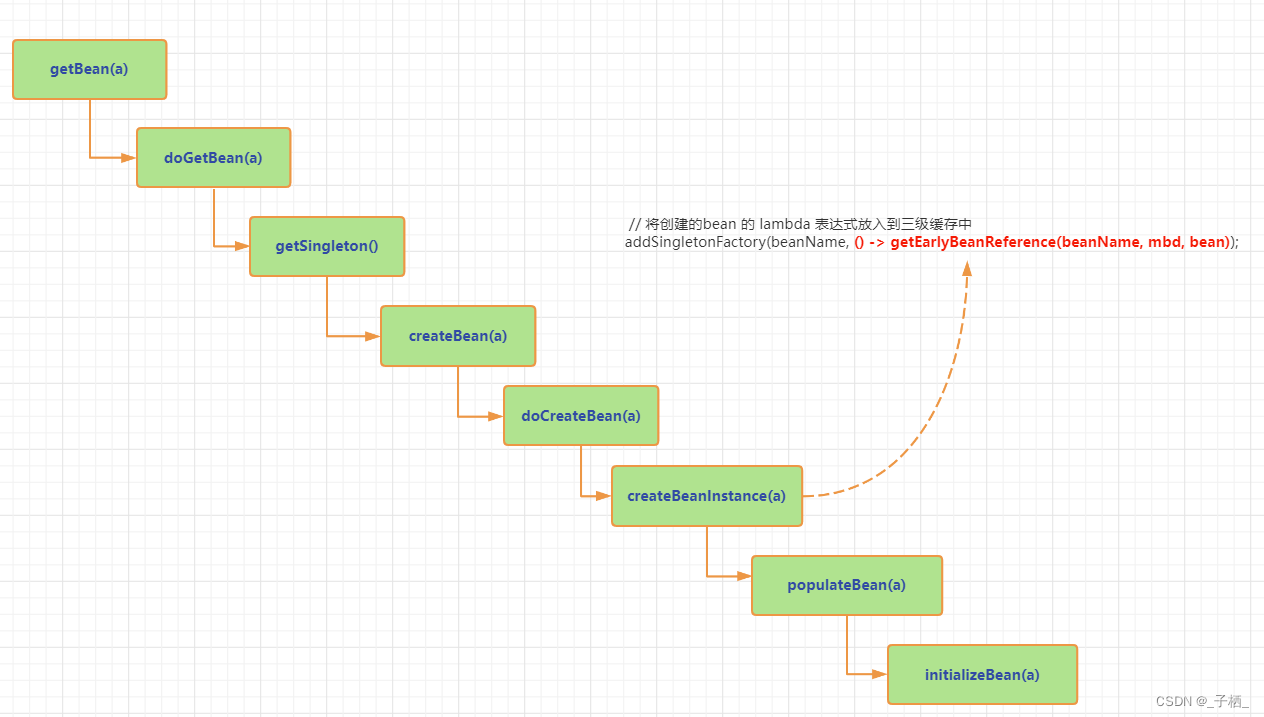
首先我们都知道Spring在创建Bean的时候主要有三步:
- 实例化,对应方法
AbstractAutowireCapableBeanFactory#createBeanInstance,实例化之后只是在堆中创建了实例,实例中属性都为默认值,然后放入到三级缓存之中 - 属性注入,对应方法
AbstractAutowireCapableBeanFactory#populateBean,为实例化之后的对象进行属性填充 - 初始化,对应方法
AbstractAutowireCapableBeanFactory#initializeBean,执行初始化方法,之后在实现了BeanPostProcessor的postProcessAfterInitialization完成AOP代理
创建A对象
getSingleton()
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
// beanName 断言处理
Assert.notNull(beanName, "Bean name must not be null");
// 对一级缓存加锁处理
synchronized (this.singletonObjects) {
// 从一级缓存中获取
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// 一级缓存中获取不到
if (this.singletonsCurrentlyInDestruction) {
throw new BeanCreationNotAllowedException(beanName,
"Singleton bean creation not allowed while singletons of this factory are in destruction " +
"(Do not request a bean from a BeanFactory in a destroy method implementation!)");
}
if (logger.isDebugEnabled()) {
logger.debug("Creating shared instance of singleton bean '" + beanName + "'");
}
// 此处是在单例bean创建之前, 判断bean是否需要检查,
// 并且将beanName添加到singletonsCurrentlyInCreation(正在创建bean的集合,是一个setFromMap集合)中
beforeSingletonCreation(beanName);
boolean newSingleton = false;
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
if (recordSuppressedExceptions) {
this.suppressedExceptions = new LinkedHashSet<>();
}
try {
// 此处是一个回调,回去执行createBean()方法,也就是开始真正的创建bean
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
catch (IllegalStateException ex) {
// Has the singleton object implicitly appeared in the meantime ->
// if yes, proceed with it since the exception indicates that state.
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
throw ex;
}
}
catch (BeanCreationException ex) {
if (recordSuppressedExceptions) {
for (Exception suppressedException : this.suppressedExceptions) {
ex.addRelatedCause(suppressedException);
}
}
throw ex;
}
finally {
if (recordSuppressedExceptions) {
this.suppressedExceptions = null;
}
// 至此,beanName创建完毕,从singletonsCurrentlyInCreation(正在创建的集合)中移除
afterSingletonCreation(beanName);
}
if (newSingleton) {
// 将成品的bean添加到一级缓存,并从二级缓存、三级缓存中移除,并添加到已完成注册的单例bean集合中
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}
从上面我们可以看到,spring在创建一个bean时,先是调用 getBean() -> doGetBean() -> getSingleton() 主要的处理逻辑就在getSingleton()之中,从getSingleton()源码中我们可以看到
- 1、先从一级缓存获取A
- 2、获取不到,再执行回调去创建A
下面接着调用回调方法 createBean() 去创建 A
大致流程如下:本质就是使用反射创建A对象实例

注意:需要注意在 createBeanInstance() 方法中先调用 instantiateBean() 方法创建bean实例对象,创建完毕以后,会接着调用 addSingletonFactory()方法,下面我们分析一下这个方法
addSingletonFactory
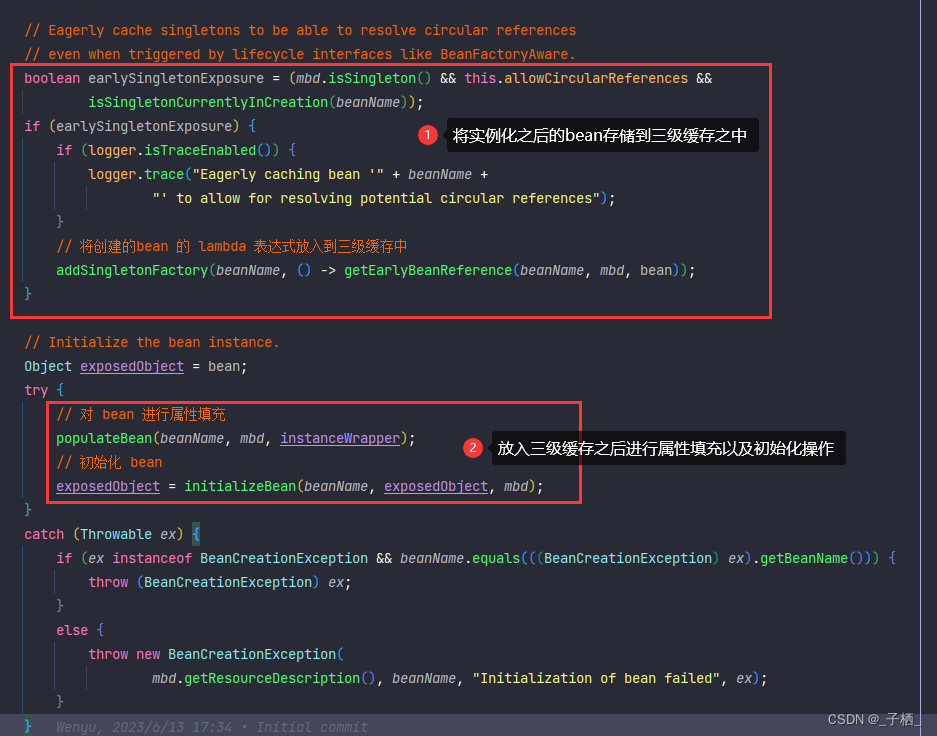
可以看到 earlySingletonExposure 为 true,就会将 创建出来的A对象实例对象放入到三级缓存之中
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
// 对 singletonFactory 进行非空校验
Assert.notNull(singletonFactory, "Singleton factory must not be null");
// 对一级缓存进行加锁
synchronized (this.singletonObjects) {
// 如果一级缓存中不存在 beanName 对应的单例对象
if (!this.singletonObjects.containsKey(beanName)) {
// 将 singletonFactory 添加到三级缓存中
this.singletonFactories.put(beanName, singletonFactory);
// 将 beanName 从二级缓存中移除
this.earlySingletonObjects.remove(beanName);
// 将 beanName 添加到 registeredSingletons 中
this.registeredSingletons.add(beanName);
}
}
}
可以看出这里放入三级缓存中的是一个 ObjectFactory ,这个工厂的 getObject()方法可以得到一个对象,而这个对象是由 getEarlyBeanReference() 创建的,那么问题来了,这个 getEarlyBeanReference() 方法什么时候被调用呢?在创建B对象的时候
接着往下看:
三级缓存放入完毕,然后对A进行属性填充,大致流程如下,这里不做详细分析
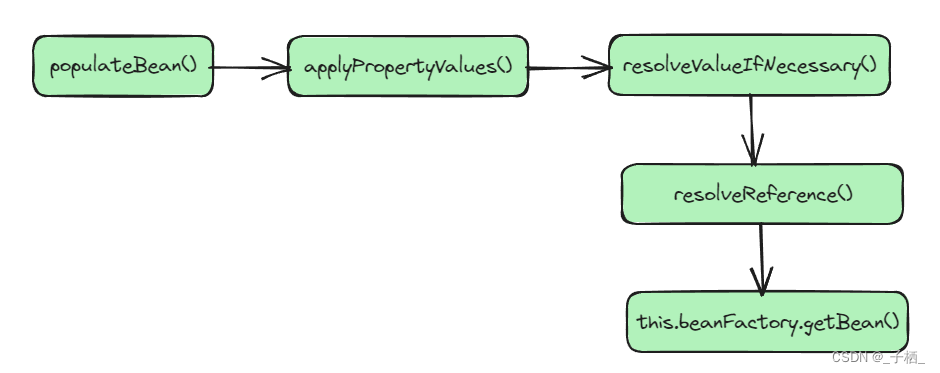
一句话概括就是:对A进行属性填充的时候发现,A中依赖了B对象,就调用 this.beanFactory.getBean()方法,获取B对象实例,也就是套娃模式开启
又开始重复上述流程去创建B对象实例,流程如下:
此时 B 对象创建完毕,三级缓存中也有了 B 对象的工厂,然后对 B 对象进行属性填充,流程与A类似,属性填充过程中发现B对象中依赖A对象,又调用 this.beanFactory.getBean(A),下面分析getSingleton()方法
注意:此处 getSingleton()方法与前面介绍的getSingleton()方法不同,前面介绍的getSingleton()方法是在本次getSingleton()方法执行完毕未获取到结果之后,才会执行前面讲解的getSingleton()方法
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
// 从一级缓存中获取该beanName实例
Object singletonObject = this.singletonObjects.get(beanName);
// 如果以及缓存中不存在并且该beanName对应的单例bean正在创建中
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 从二级缓存中获取该beanName实例
singletonObject = this.earlySingletonObjects.get(beanName);
// 二级缓存中不存在并且允许提前引用
if (singletonObject == null && allowEarlyReference) {
// 锁定全局变量进行操作
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
// 从一级缓存中获取该beanName实例
singletonObject = this.singletonObjects.get(beanName);
// 如果一级缓存中获取不到
if (singletonObject == null) {
// 从二级缓存中获取
singletonObject = this.earlySingletonObjects.get(beanName);
// 二级缓存中也获取不到
if (singletonObject == null) {
// 当某些方法需要提前初始化的时候则会调用addSingletonFactory方法将对应的 ObjectFactory 初始化策略存储在 singletonFactories
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 如果存在单例对象工厂,则通过工厂创建一个单例对象
singletonObject = singletonFactory.getObject();
// 放入到二级缓存中
this.earlySingletonObjects.put(beanName, singletonObject);
// 并从三级缓存中移除
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
从源码中可以看到:getSingleton()方法会先从一级缓存中获取A对象实例,如果获取不到再从二级缓存中获取,二级缓存中获取不到再从三级缓存中,那么此时三级缓存中肯定是可以获取到的,获取到之后调用 getObject() 方法,此时调用 getObject()方法,会回调 getEarlyBeanReference() 方法
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
// 该方法主要用于提前获取 bean 的引用,以便于解决循环依赖的问题
// 将当前 bean 赋值给 exposedObject
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
// 这块代码是用代理对象替换原始对象,这样就可以在原始对象的基础上做一些增强操作
for (BeanPostProcessor bp : getBeanPostProcessors()) {
// AOP --> AnnotationAwareAspectJAutoProxyCreator
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
从源码可以看出实际上就是调用了后置处理器的 getEarlyBeanReference,而真正实现了这个方法的后置处理器只有一个,就是通过@EnableAspectJAutoProxy 注解导入的 AnnotationAwareAspectJAutoProxyCreator。也就是说如果在不考虑AOP的情况下,上面的代码等价于:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
return exposedObject;
}
这样的话,也就是说这个工厂啥也没干,直接将实例化阶段创建的对象返回了!
所以说在不考虑AOP的情况下三级缓存有用嘛?讲道理,真的没什么用,我直接将这个对象放到二级缓存中不是一点问题都没有吗?如果你说它提高了效率,那你告诉我提高的效率在哪?
那么三级缓存到底有什么作用呢?不要急,我们先把整个流程走完,在下文结合AOP分析循环依赖的时候你就能体会到三级缓存的作用!
到这里不知道小伙伴们会不会有疑问,B中提前注入了一个没有经过初始化的A类型对象不会有问题吗?
答:不会
这个时候我们需要将整个创建A这个Bean的流程走完,如下图:
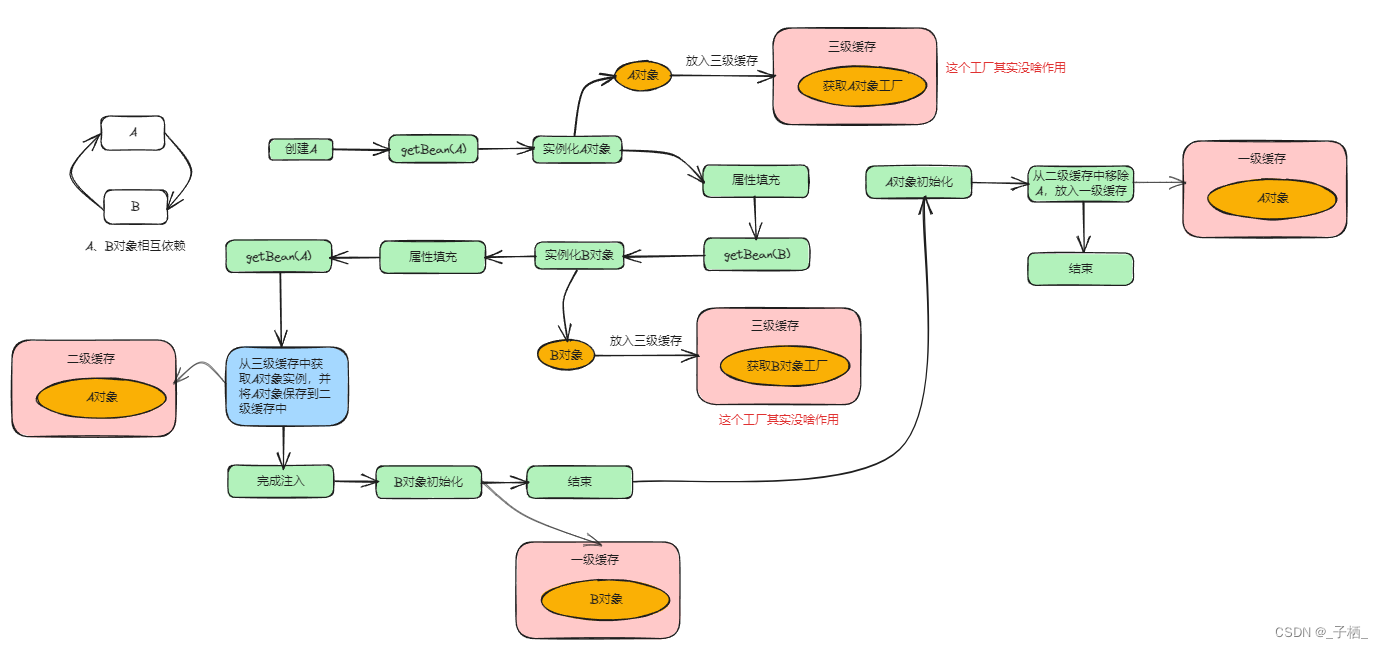
从上图中我们可以看到,虽然在创建B时会提前给B注入了一个还未初始化的A对象,但是在创建A的流程中一直使用的是注入到B中的A对象的引用,之后会根据这个引用对A进行初始化,所以这是没有问题的。
创建B对象
从前面我们已经知道,在创建A的过程中已经把B对象创建好了,而且已经放入到了一级缓存,但是spring是通过循环遍历beanName去创建bean实例的,所以B还会在创建一次,与创建A对象的区别在于,在创建B对象的过程中在调用getSingleton()方法的时候,可以从一级缓存中直接拿到B对象,所以直接返回,不在进行创建
至此没有AOP的循环依赖就到此为止,下面继续看有AOP的循环依赖
AOP循环依赖
之前我们已经说过了,在普通的循环依赖的情况下,三级缓存没有任何作用。三级缓存实际上跟Spring中的AOP相关,我们再来看一看getEarlyBeanReference()方法的代码:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
// 该方法主要用于提前获取 bean 的引用,以便于解决循环依赖的问题
// 将当前 bean 赋值给 exposedObject
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
// 这块代码是用代理对象替换原始对象,这样就可以在原始对象的基础上做一些增强操作
for (BeanPostProcessor bp : getBeanPostProcessors()) {
// AOP --> AnnotationAwareAspectJAutoProxyCreator
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
如果在开启AOP的情况下,就会调用 AnnotationAwareAspectJAutoProxyCreator的getEarlyBeanReference()方法
public Object getEarlyBeanReference(Object bean, String beanName) {
// 根据bean的类型和名称获取缓存的key,如果beanName为空,则使用bean的类型作为key
// 如果beanName不为空,则使用beanName作为key,如果beanName是一个FactoryBean的名称,则使用&+beanName作为key
Object cacheKey = getCacheKey(bean.getClass(), beanName);
// 添加到earlyProxyReferences中
this.earlyProxyReferences.put(cacheKey, bean);
// 创建aop代理
return wrapIfNecessary(bean, beanName, cacheKey);
}
从代码可以看出如果我们对A进行了AOP代理的话,那么此时的getEarlyBeanReference()方法将返回一个A的代理对象,而不是实例化阶段创建的A对象,这样就意味着B中注入的A将是一个代理对象而不是A的实例化阶段创建后的对象。
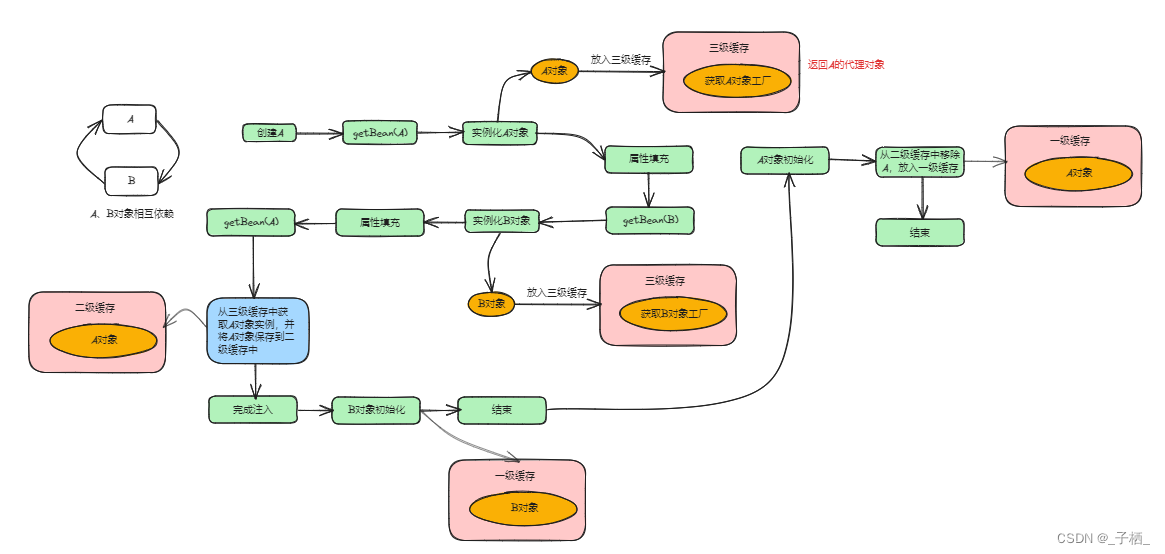
看到这个图你可能会产生下面这些疑问
在给B注入的时候为什么要注入一个代理对象?
答:当我们对A进行了AOP代理时,说明我们希望从容器中获取到的就是A代理后的对象而不是A本身,因此把A当作依赖进行注入时也要注入它的代理对象
明明初始化的时候是A对象,那么Spring是在哪里将代理对象放入到容器中的呢?
在完成初始化的时候,spring会在调用一次getSingleton()方法,这一次传入的参数又不一样了,false可以理解为禁用三级缓存,前面说过,B进行属性填充的时候,已经从三级缓存中获取到A对象,然后生成A的代理对象,并将代理对象放入到二级缓存中,所以在A完成初始化的时候,所以再从二级缓存中获取到A代理对象赋值给 exposedObject,最终放入到一级缓存中
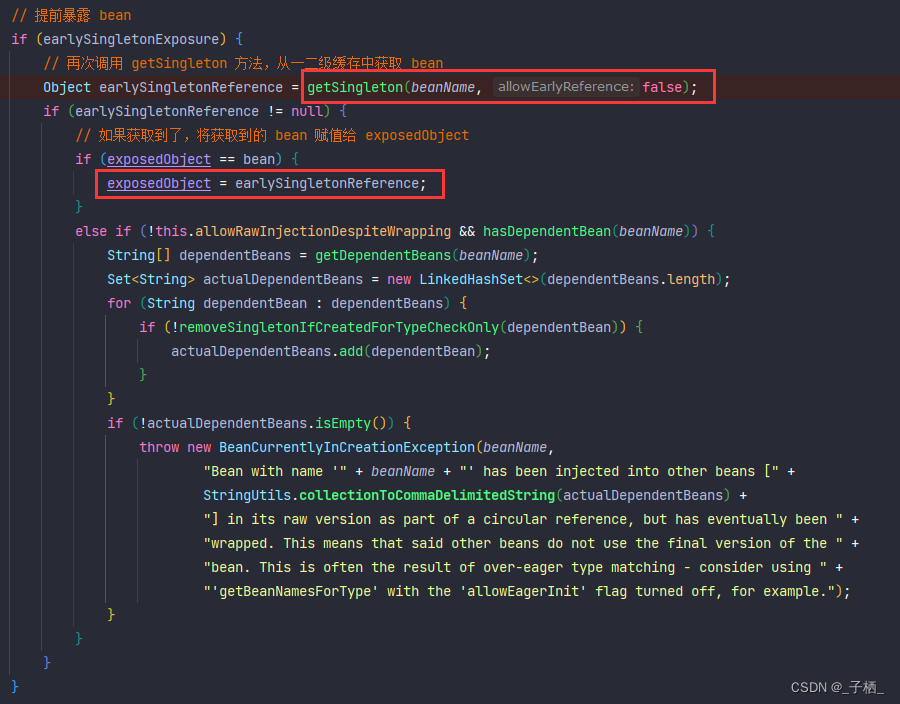
初始化的时候是对A对象本身进行初始化,而容器中以及注入到B中的都是代理对象,这样不会有问题吗?
答:不会,这是因为不管是cglib代理还是jdk动态代理生成的代理类,内部都持有一个目标类的引用,当调用代理对象的方法时,实际会去调用目标对象的方法,A完成初始化相当于代理对象自身也完成了初始化
三级缓存为什么要使用工厂而不是直接使用引用?换而言之,为什么需要这个三级缓存,直接通过二级缓存暴露一个引用不行吗?
答:这个工厂的目的在于延迟创建对实例化阶段生成的对象的代理,只有真正发生循环依赖的时候,才去提前生成代理对象,否则只会创建一个工厂并将其放入到三级缓存中,但是不会去通过这个工厂去真正创建对象
我们思考一种简单的情况,就以单独创建A为例,假设AB之间现在没有依赖关系,但是A被代理了,这个时候当A完成实例化后还是会进入下面这段代码:
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// 将创建的bean 的 lambda 表达式放入到三级缓存中
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
假设我们在这里直接使用二级缓存的话,那么意味着所有的Bean在这一步都要完成AOP代理。这样做有必要吗?
不仅没有必要,而且违背了Spring在结合AOP跟Bean的生命周期的设计!Spring结合AOP跟Bean的生命周期本身就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来完成的,在这个后置处理的postProcessAfterInitialization方法中对初始化后的Bean完成AOP代理。如果出现了循环依赖,那没有办法,只有给Bean先创建代理,但是没有出现循环依赖的情况下,设计之初就是让Bean在生命周期的最后一步完成代理而不是在实例化后就立马完成代理。
三级缓存真的提高了效率了吗?
通过以上分析,我们已经知道了三级缓存的真正作用,但是这个答案可能还无法说服你,所以我们再最后总结分析一波,三级缓存真的提高了效率了吗?分为两点讨论:
没有进行AOP的Bean间的循环依赖
从上文分析可以看出,这种情况下三级缓存根本没用!所以不会存在什么提高了效率的说法
进行了AOP的Bean间的循环依赖
就以我们上的A、B为例,其中A被AOP代理,我们先分析下使用了三级缓存的情况下,A、B的创建流程

假设不使用三级缓存直接使用二级缓存

上面两个流程的唯一区别在于为A对象创建代理的时机不同,在使用了三级缓存的情况下为A创建代理的时机是在B中需要注入A的时候,而不使用三级缓存的话在A实例化后就需要马上为A创建代理然后放入到二级缓存中去。对于整个A、B的创建过程而言,消耗的时间是一样的
综上,不管是哪种情况,三级缓存提高了效率这种说法都是错误的!
总结
“Spring是如何解决的循环依赖?”
答:Spring通过三级缓存解决了循环依赖,其中一级缓存为单例池(singletonObjects),二级缓存为早期曝光对象earlySingletonObjects,三级缓存为早期曝光对象工厂(singletonFactories)。当A、B两个类发生循环引用时,在A完成实例化后,就使用实例化后的对象去创建一个对象工厂,并添加到三级缓存中,如果A被AOP代理,那么通过这个工厂获取到的就是A代理后的对象,如果A没有被AOP代理,那么这个工厂获取到的就是A实例化的对象。当A进行属性注入时,会去创建B,同时B又依赖了A,所以创建B的同时又会去调用getBean(a)来获取需要的依赖,此时的getBean(a)会从缓存中获取,第一步,先获取到三级缓存中的工厂;第二步,调用对象工工厂的getObject方法来获取到对应的对象,得到这个对象后将其注入到B中。紧接着B会走完它的生命周期流程,包括初始化、后置处理器等。当B创建完后,会将B再注入到A中,此时A再完成它的整个生命周期。至此,循环依赖结束!
“为什么要使用三级缓存呢?二级缓存能解决循环依赖吗?”
答:如果要使用二级缓存解决循环依赖,意味着所有Bean在实例化后就要完成AOP代理,这样违背了Spring设计的原则,Spring在设计之初就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来在Bean生命周期的最后一步来完成AOP代理,而不是在实例化后就立马进行AOP代理。