基于MMYOLO的电离图实时目标检测基准
数据集
数字电离图是获取实时电离层信息的最重要方式。电离层结构检测对于准确提取电离层关键参数具有重要的研究意义。
本研究利用中国科学院在海南、武汉和怀来获得的4311张不同季节的电离图建立数据集。使用labelme手动注释包括 Layer E、Es-l、Es-c、F1、F2 和 Spread F 在内的六个结构。

数据集准备
下载数据后,将其放在MMYOLO存储库的根目录下,并使用(for Linux)解压到当前文件夹。解压后的文件夹结构如下:unzip test.zip
Iono4311/
├── images
| ├── 20130401005200.png
| └── …
└── labels
├── 20130401005200.json
└── …
该images目录包含输入图像,而该labels目录包含labelme生成的注释文件。
将数据集转换为COCO格式
使用脚本tools/dataset_converters/labelme2coco.py将labelme标签转换为COCO标签。
python tools/dataset_converters/labelme2coco.py --img-dir ./Iono4311/images \
--labels-dir ./Iono4311/labels \
--out ./Iono4311/annotations/annotations_all.json
检查转换后的COCO标签
要确认转换过程是否成功,请使用以下命令在图像上显示 COCO 标签。
python tools/analysis_tools/browse_coco_json.py --img-dir ./Iono4311/images \
--ann-file ./Iono4311/annotations/annotations_all.json
将数据集分为训练集、验证集和测试集
将数据集中70%的图像作为训练集,15%作为验证集,15%作为测试集。
python tools/misc/coco_split.py --json ./Iono4311/annotations/annotations_all.json \
--out-dir ./Iono4311/annotations \
--ratios 0.7 0.15 0.15 \
--shuffle \
--seed 14
划分后的文件树如下:
Iono4311/
├── annotations
│ ├── annotations_all.json
│ ├── class_with_id.txt
│ ├── test.json
│ ├── train.json
│ └── val.json
├── classes_with_id.txt
├── images
├── labels
├── test_images
├── train_images
└── val_images
配置文件
配置文件存储在目录中/projects/misc/ionogram_detection/。
数据集分析
要执行数据集分析,可以使用该脚本分析数据集中的 200 个图像样本tools/analysis_tools/dataset_analysis.py。
python tools/analysis_tools/dataset_analysis.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py \
--out-dir output
部分输出如下:
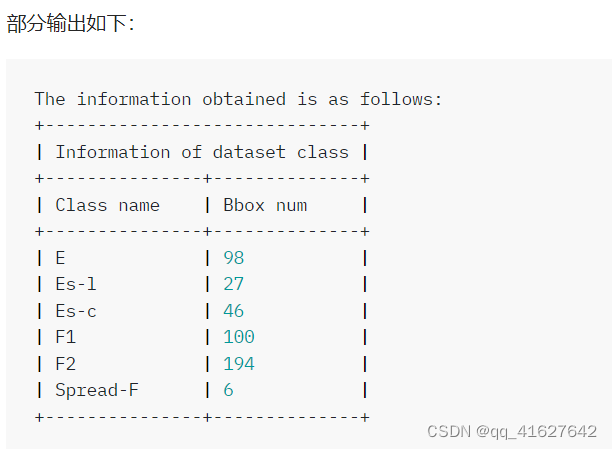
这表明数据集中类别的分布不平衡。
据统计,E、Es-l、Es-c、F1类以小型物体为主,F2、Spread F类以中型物体较多。
配置中数据处理部分的可视化
以YOLOv5-s为例,根据train_pipeline配置文件中的,训练时使用的数据增强策略包括:
Mosaic augmentation
Random affine
Albumentations (include various digital image processing methods)
HSV augmentation
Random affine
使用脚本的“管道”tools/analysis_tools/browse_dataset.py模式获取数据管道中的所有中间图像。
python tools/analysis_tools/browse_dataset.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py \
-m pipeline \
--out-dir output

数据管道中中间图像的可视化
优化锚点大小
使用脚本tools/analysis_tools/optimize_anchors.py获取适合数据集的先前锚框大小。
python tools/analysis_tools/optimize_anchors.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py \
--algorithm v5-k-means \
--input-shape 640 640 \
--prior-match-thr 4.0 \
--out-dir work_dirs/dataset_analysis_5_s
模型复杂度分析
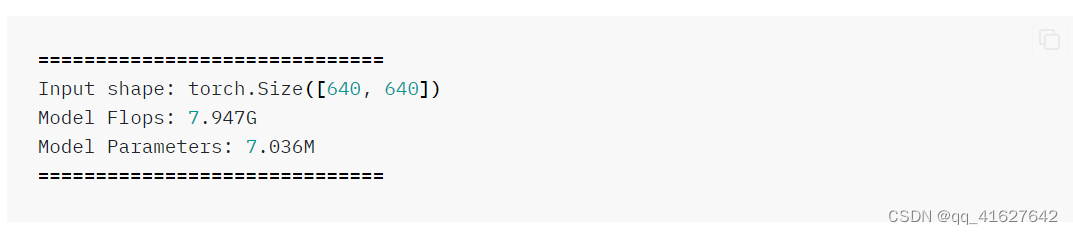
有了配置文件,参数和FLOPs就可以通过脚本计算出来tools/analysis_tools/get_flops.py。以yolov5-s为例:
python tools/analysis_tools/get_flops.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py
以下输出表明,该模型在输入形状 (640, 640) 下具有 7.947G FLOP,总共有 7.036M 个可学习参数。
Train and test
训练可视化:按照自定义数据集的注释到部署工作流程教程,本示例使用wandb来可视化训练。
训练可视化
如果需要使用浏览器来可视化训练过程,MMYOLO 目前提供了wandb和TensorBoard两种方式。根据自己的情况选择一个(后续我们会扩展对更多可视化后端的支持)。
调试技巧:在调试代码的过程中,有时需要训练几个epoch,例如调试验证过程或检查检查点保存是否符合预期。对于继承自的数据集BaseDataset(例如YOLOv5CocoDataset本例),字段indices中的设置dataset可以指定每个时期的样本数量,以减少迭代时间。
train_dataloader = dict(
batch_size=train_batch_size_per_gpu,
num_workers=train_num_workers,
dataset=dict(
_delete_=True,
type='RepeatDataset',
times=1,
dataset=dict(
type=_base_.dataset_type,
indices=200, # set indices=200,represent every epoch only iterator 200 samples
data_root=data_root,
metainfo=metainfo,
ann_file=train_ann_file,
data_prefix=dict(img=train_data_prefix),
filter_cfg=dict(filter_empty_gt=False, min_size=32),
pipeline=_base_.train_pipeline)))
开始训练:
python tools/train.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py
测试
指定配置文件的路径和启动测试的模型:
python tools/test.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py \
work_dirs/yolov5_s-v61_fast_1xb96-100e_ionogram/xxx
实验与结果
选择合适的批量大小
通常,批量大小决定训练速度,理想的批量大小将是可用硬件支持的最大批量大小。
如果视频内存尚未充分利用,则将批量大小加倍应该会导致训练吞吐量相应加倍(或接近加倍)。这相当于随着批量大小的增加,每步保持恒定(或接近恒定)的时间。
自动混合精度(AMP)是一种以最小的精度损失加速训练的技术。要启用 AMP 训练,请添加–amp到训练命令的末尾。
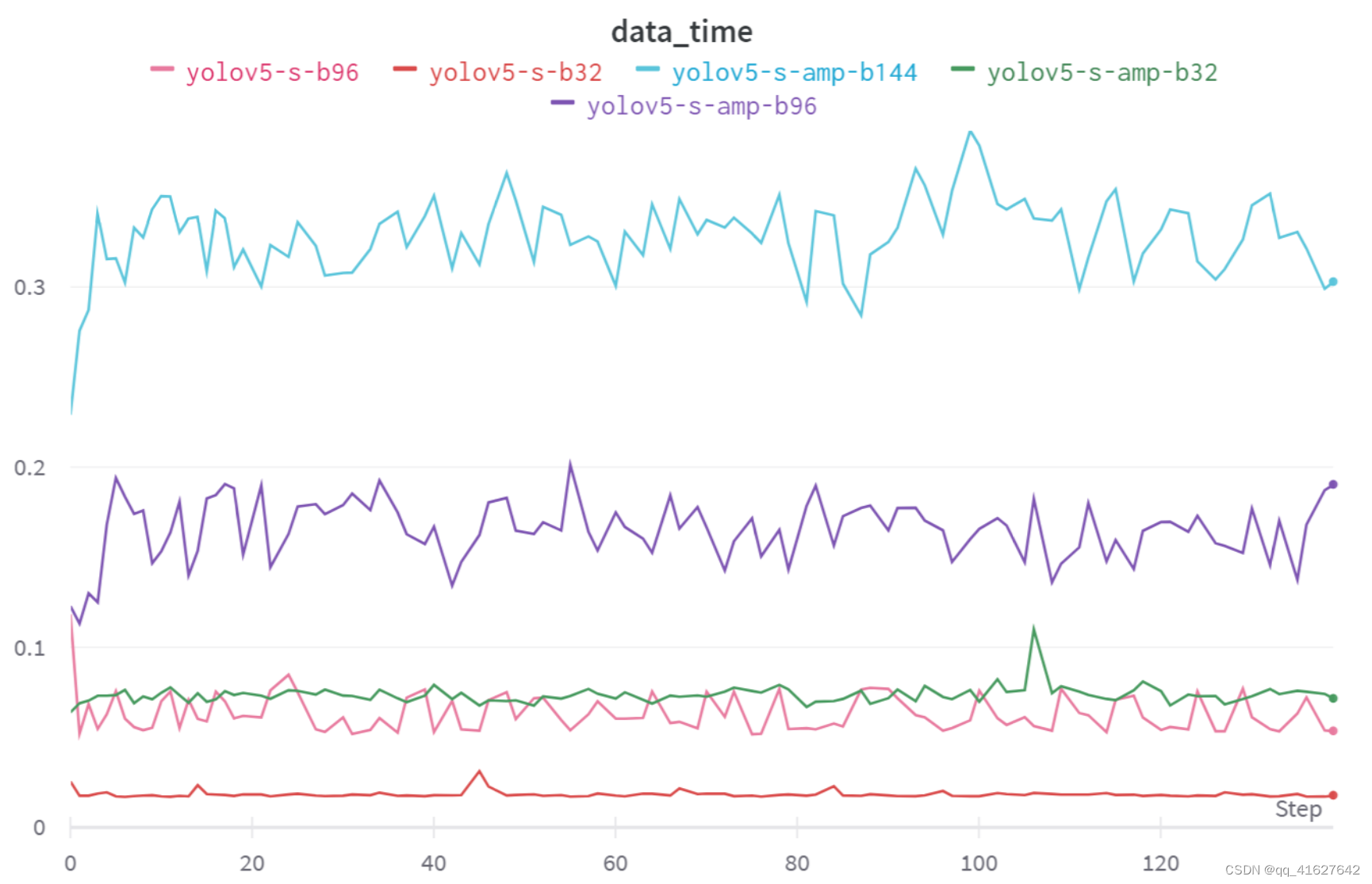
根据以上结果,我们可以得出结论:
AMP 对模型的准确性影响不大,但可以显着减少训练时的内存使用。
将批量大小增加三倍不会将训练时间减少相应的三倍。根据data_time训练过程中的记录,batch size越大, 越大data_time,说明数据加载已经成为限制训练速度的瓶颈。增加num_workers用于加载数据的进程数量,可以加快训练速度。
经常问的问题
1、为什么将YOLOv5主干切换为Swin后性能会大幅下降?
在更换主干网络中,我们提供了很多更换主干模块的教程。然而,一旦更换模块并开始直接训练模型,您可能无法获得想要的结果。这是因为不同的网络具有非常不同的超参数。以Swin和YOLOv5的backbone为例。Swin属于transformer家族,YOLOv5是一个卷积网络。他们的训练优化器、学习率和其他超参数是不同的。如果我们强制使用Swin作为YOLOv5的骨干并试图获得中等的性能,我们必须修改许多参数
2、如何使用所有MM系列存储库中实现的组件
在 OpenMMLab 2.0 中,我们增强了跨 MM 系列库使用不同模块的能力。目前,用户可以通过MM Algorithm Library A. Module Name调用已在MM系列算法库中注册的任意模块。我们演示了在替换主干网络中使用 MMClassification 主干网。其他模块也可以同样的方式使用。
3、MMYOLO中可以添加纯背景图片进行训练吗?
在训练中添加纯背景图像可以抑制大多数场景下的误报率,并且大多数数据集已经支持该功能。举YOLOv5CocoDataset个例子。控制参数为train_dataloader.dataset.filter_cfg.filter_empty_gt。如果filter_empty_gt为True,则纯背景图像将被过滤掉并且不用于训练,反之亦然。MMYOLO中的大部分算法都默认添加了这个功能。
4、MMYOLO 中有计算推理 FPS 的脚本吗
MMYOLO 基于 MMDet 3.x,提供了计算推理 FPS 的基准脚本。我们建议mim直接在库中运行 MMDet 中的脚本,而不是将它们复制到 MMYOLO。有关用法的更多详细信息mim,请参阅使用 mim 从其他 OpenMMLab 存储库运行脚本。
5、 如何查看COCOMetric中各个类别的AP?
只需设置test_evaluator.classwise为 True 或在运行测试脚本时添加–cfg-options test_evaluator.classwise=True即可。
6、为什么MMYOLO不像MMDet那样支持自动学习率缩放功能?
这是因为YOLO系列算法不太适合线性缩放。我们已经在几个数据集上验证了,如果没有基于批量大小的自动缩放,性能会更好。
7、为什么我训练的模型的权重比官方的大
原因是用户训练的权重通常包含额外的数据,例如optimizer、ema_state_dict和message_hub,这些数据在我们发布模型时会被删除。反之则保留用户自己训练的重量。您可以使用publish_model.py删除这些不必要的组件。
8、为什么 RTMDet 在训练过程中比 YOLOv5 消耗更多的显存?
这是由于 RTMDet 中的分配者造成的。YOLOv5 使用简单高效的形状匹配分配器,而 RTMDet 使用动态软标签分配器进行整个批量计算。因此,它在其内部成本矩阵中消耗了更多的内存,特别是当当前批次中有太多标记的bbox时。我们正在考虑尽快解决这个问题
9、修改代码后需要重新安装MMYOLO吗
无需添加任何新的Python代码,并且如果您通过安装了MMYOLO ,任何新的修改都会生效,无需重新安装。但是,如果您添加新的 python 代码并正在使用它们,则需要使用.mim install -v -e .mim install -v -e .
10、如何在训练过程中保存最佳检查点
用户可以通过在配置中设置default_hooks.checkpoint.save_best来选择哪些指标来过滤最佳模型。以COCO数据集检测任务为例。用户可以default_hooks.checkpoint.save_best使用以下参数进行自定义:
auto基于验证集中的第一个评估指标进行工作。
coco/bbox_mAP作品基于bbox_mAP.
coco/bbox_mAP_50作品基于bbox_mAP_50.
coco/bbox_mAP_75作品基于bbox_mAP_75.
coco/bbox_mAP_s作品基于bbox_mAP_s.
coco/bbox_mAP_m作品基于bbox_mAP_m.
coco/bbox_mAP_l作品基于bbox_mAP_l.
另外,用户还可以通过配置中的设置default_hooks.checkpoint.rule来选择过滤逻辑。例如,default_hooks.checkpoint.rule=greater表示该指标越大越好。更多详细信息可以在checkpoint_hook找到。
11、如何使用非方形输入大小进行训练和测试?
YOLO系列算法的默认配置大多是640x640或1280x1280这样的正方形。但是,如果用户想要使用非方形进行训练,可以image_scale在配置中将 修改为所需的值。更详细的示例可以在yolov5_s-v61_fast_1xb12-40e_608x352_cat.py找到。