这⼀部分主要是理解
RocketMQ
⼀些重要的⾼性能核⼼设计。我们知道,在
MQ
这个领域,
RocketMQ
实际上是属于⼀个后起之秀。RocketMQ
除了能够⽀撑
MQ
的业务功能之外,还有更重要的⼀部分就是对于⾼吞吐、⾼性能、⾼可⽤的三⾼架构设计。这些设计的思想,很多都是我们去处理三⾼问题时可以学习借鉴的经验。
另外,与
RabbitMQ
和
Kafka
这些外国的产品不同,
RocketMQ
作为国⼈开发的产品,很多核⼼实现机制其实是⾮常符合我们的思想的。所以,这次,我们直接从源码⼊⼿,来梳理RocketMQ
的⼀些核⼼的三⾼设计。
⼀、源码环境搭建
1
、主要功能模块
RocketMQ
的官⽅
Git
仓库地址:
https://github.com/apache/rocketmq
可以⽤
git
把项⽬
clone
下来或者直接下载代码包。
也可以到
RocketMQ
的官⽅⽹站上下载指定版本的源码:
http://rocketmq.apache.org/dowloading/releases/
源码下很多的功能模块,很容易让⼈迷失⽅向,我们只关注下⼏个最为重要的模块:
· broker: Broker
模块(
broke
启动进程)
· client
:消息客户端,包含消息⽣产者、消息消费者相关类
· example: RocketMQ
例代码
· namesrv
:
NameServer
模块
· store
:消息存储模块
· remoting
:远程访问模块
2
、源码启动服务
将源码导⼊
IDEA
后,需要先对源码进⾏编译。编译指令
clean install -Dmaven.test.skip=true
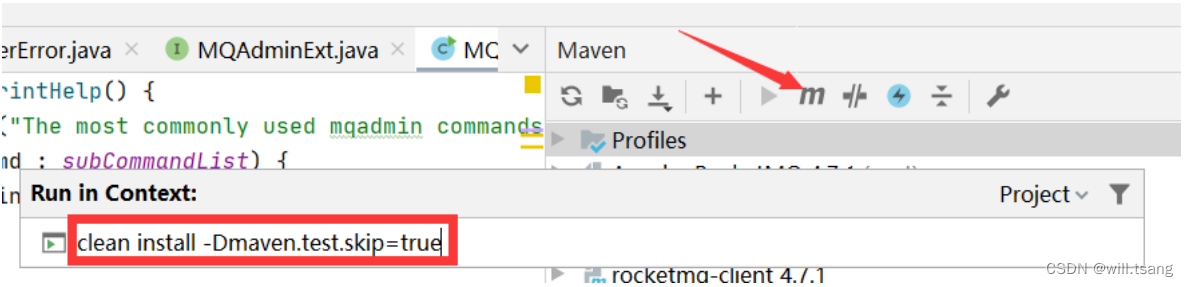
编译完成后就可以开始调试代码了。调试时需要按照以下步骤:
调试时,先在项⽬⽬录下创建⼀个
conf
⽬录,并从
distribution
拷⻉
broker.conf
和
logback_broker.xml和 logback_namesrv.xml

2.1
启动
nameServer
展开
namesrv
模块,运⾏
NamesrvStartup
类即可启动
NameServer
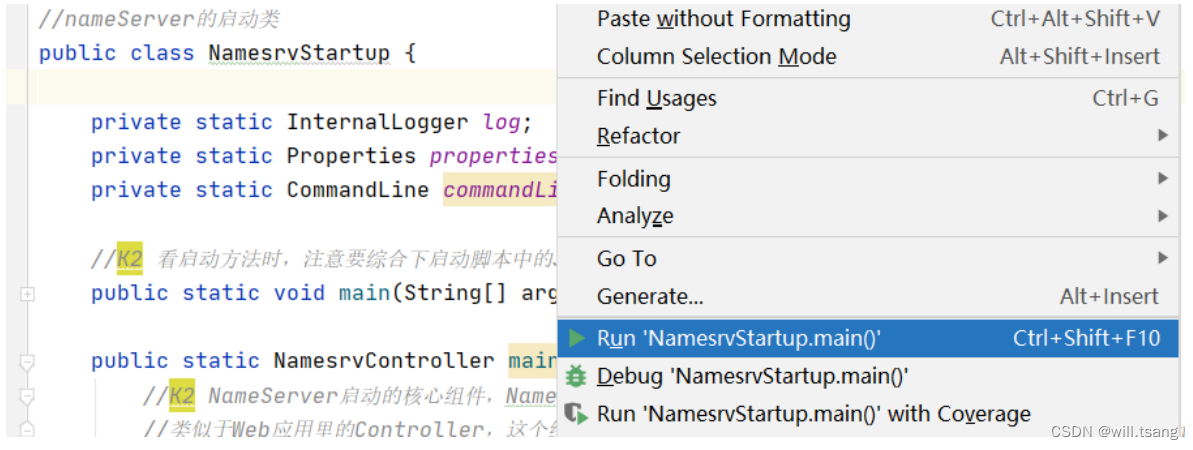
启动时,会报错,提示需要配置⼀个
ROCKETMQ_HOME
环境变量。这个环境变量我们可以在机器上配置,跟配置JAVA_HOME环境变量⼀样。也可以在
IDEA
的运⾏环境中配置。⽬录指向源码⽬录即可。
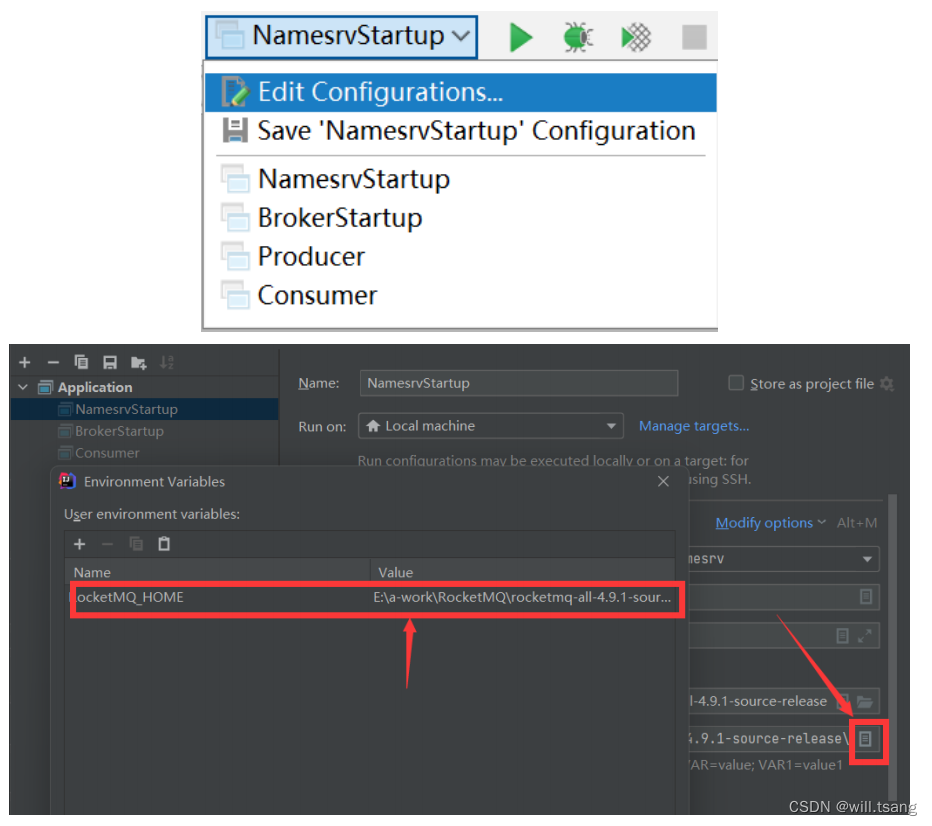
配置完成后,再次执⾏,看到以下⽇志内容,表示
NameServer
启动成功

2.2
启动
Broker
启动
Broker
之前,我们需要先修改之前复制的
broker.conf
⽂件

然后
Broker
的启动类是
broker
模块下的
BrokerStartup
。
启动
Broker
时,同样需要
ROCETMQ_HOME
环境变量,并且还需要配置⼀个
-c
参数,指向
broker.conf
配置⽂件。
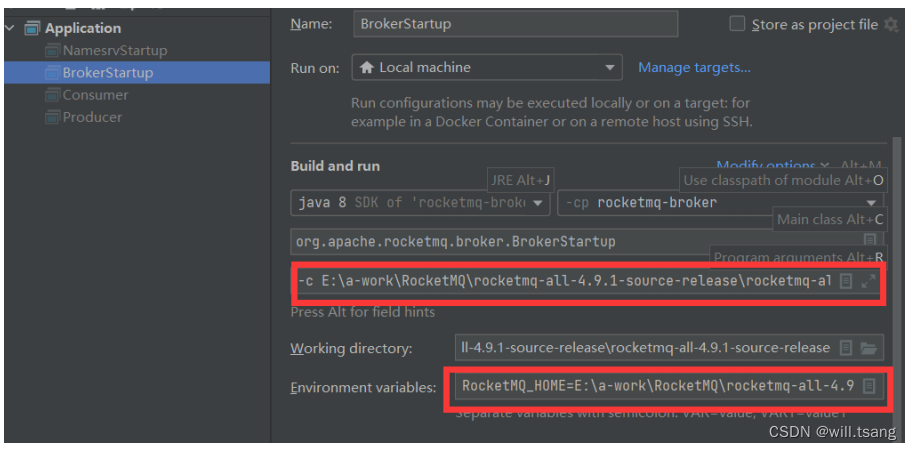
然后重新启动,即可启动
Broker
。
2.3
发送消息
在源码的
example
模块下,提供了⾮常详细的测试代码。例如我们启动
example
模块下的
org.apache.rocketmq.example.quickstart.Producer
类即可发送消息。
但是在测试源码中,需要指定
NameServer
地址。这个
NameServer
地址有两种指定⽅式,⼀种是配置⼀个NAMESRV_ADDR的环境变量。另⼀种是在源码中指定。我们可以在源码中加⼀⾏代码指定
NameServer

然后就可以发送消息了。
2.4
消费消息
我们可以使⽤同⼀模块下的
org.apache.rocketmq.example.quickstart.Consumer
类来消费消息。运⾏时同样需要指定NameServer
地址

这样整个调试环境就搭建好了。
3
、读源码的⽅法
1
、带着问题读源码。如果没有⾃⼰的思考,源码不如不读!!!
2
、⼩步快⾛。不要觉得⼀两遍就能读懂源码。这⾥我会分为三个阶段来带你逐步加深对源码的理解。
3
、分步总结。带上⾃⼰的理解,及时总结。对各种扩展功能,尝试验证。对于
RocketMQ
,试着去理解源码中的各种单元测试。
⼆、源码热身阶段
梳理⼀些重要的服务端核⼼配置,找到⼀点点读源码的感觉。
1
、
NameServer
的启动过程
1
、关注重点
在
RocketMQ
集群中,实际记性消息存储、推送等核⼼功能点额是
Broker
。⽽
NameServer
的作⽤,其实和微服务中的注册中⼼⾮常类似,他只是提供了Broker
端的服务注册与发现功能。
第⼀次看源码,不要太过陷⼊具体的细节,先搞清楚
NameServer
的⼤体结构。
2
、源码重点
NameServer
的启动⼊⼝类是
org.apache.rocketmq.namesrv.NamesrvStartup
。其中的核⼼是构建并启动⼀个NamesrvController。这个
Cotroller
对象就跟
MVC
中的
Controller
是很类似的,都是响应客户端的请求。只不过,他响应的是基于Netty
的客户端请求。
另外,他的实际启动过程,其实可以配合
NameServer
的启动脚本进⾏更深⼊的理解。
从
NameServer
启动和关闭这两个关键步骤,我们可以总结出
NameServer
的组件其实并不是很多,整个NameServer的结构是这样的;
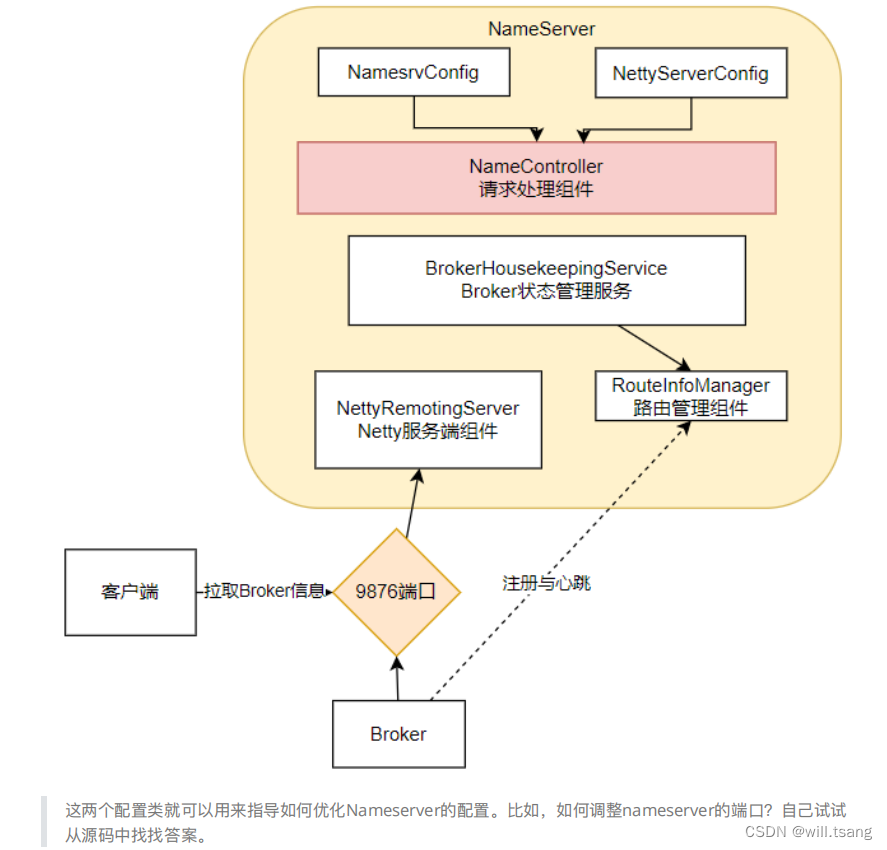
从这⾥也能看出,
RocketMQ
的整体源码⻛格就是典型的
MVC
思想。
Controller
响应请求,
Service
处理业务,各种Table
保存消息。
2
、
Broker
服务启动过程
1
、关注重点
Broker
是整个
RocketMQ
的业务核⼼。所有消息存储、转发这些重要的业务都是
Broker
进⾏处理。
这⾥重点梳理
Broker
有哪些内部服务。这些内部服务将是整理
Broker
核⼼业务流程的起点。
2
、源码重点
Broker
启动的⼊⼝在
BrokerStartup
这个类,可以从他的
main
⽅法开始调试。
启动过程关键点:重点也是围绕⼀个
BrokerController
对象,先创建,然后再启动。
⾸先:
在
BrokerStartup.createBrokerController
⽅法中可以看到
Broker
的⼏个核⼼配置:
· BrokerConfig
:
Broker
服务配置
· MessageStoreConfig
: 消息存储配置。 这两个配置参数都可以在
broker.conf
⽂件中进⾏配置
· NettyServerConfig
:
Netty
服务端占⽤了
10911
端⼝。同样也可以在配置⽂件中覆盖。
· NettyClientConfig
:
Broker
既要作为
Netty
服务端,向客户端提供核⼼业务能⼒,⼜要作为
Netty
客户端,向NameServer
注册⼼跳。
这些配置是我们了解如何优化
RocketMQ
使⽤的关键。
然后:
在
BrokerController.start
⽅法可以看到启动了⼀⼤堆
Broker
的核⼼服务,我们挑⼀些重要的

我们现在不需要了解这些核⼼组件的具体功能,只要有个⼤概,
Broker
中有⼀⼤堆的功能组件负责具体的业务。后⾯等到分析具体业务时再去深⼊每个服务的细节。
我们需要抽象出
Broker
的⼀个整体结构:
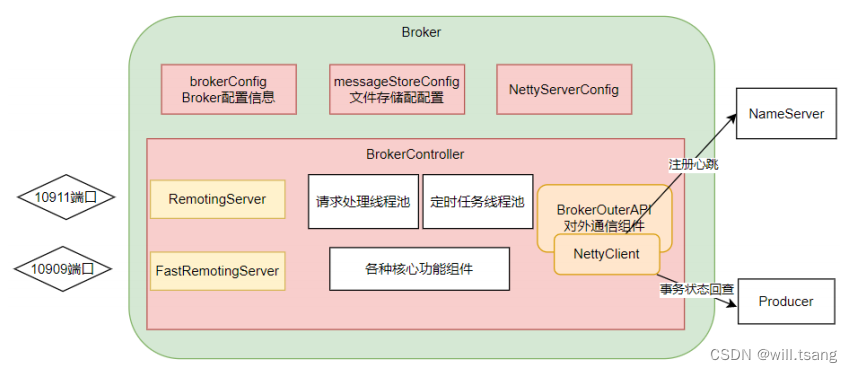
可以看到
Broker
启动了两个
Netty
服务,他们的功能基本差不多。实际上,在应⽤中,可以通过
producer.setSendMessageWithVIPChannel(true)
,让少量⽐较重要的
producer
⾛
VIP
的通道。⽽在消费者端,也可以通过consumer.setVipChannelEnabled(true)
,让消费者⽀持
VIP
通道的数据。
三、⼩试⽜⼑阶段
三
开始理解⼀些⽐较简单的业务逻辑
3
、
Netty
服务注册框架
1
、关注重点
⽹络通信服务是构建分布式应⽤的基础,也是我们去理解
RocketMQ
底层业务的基础。这⾥就重点梳理RocketMQ的这个服务注册框架,理解各个业务进程之间是如何进⾏
RPC
远程通信的。
Netty
的所有远程通信功能都由
remoting
模块实现。
RemotingServer
模块⾥包含了
RPC
的服务端
RemotingServer
以及客户端
RemotingClient
。在
RocketMQ
中,涉及到的远程服务⾮常多,在
RocketMQ
中,NameServer主要是
RPC
的服务端
RemotingServer
,
Broker
对于客户端来说,是
RPC
的服务端
RemotingServer
,⽽对于NameServer
来说,⼜是
RPC
的客户端。各种
Client
是
RPC
的客户端
RemotingClient
。
需要理解的是,
RocketMQ
基于
Netty
保持客户端与服务端的⻓连接
Channel
。只要
Channel
是稳定的,那么即可以从客户端发请求到服务端,同样服务端也可以发请求到客户端。例如在事务消息场景中,就需要Broker
多次主动向Producer
发送请求确认事务的状态。所以,
RemotingServer
和
RemotingClient
都需要注册⾃⼰的服务。
2
、源码重点
1
、哪些组件需要
Netty
服务端?哪些组件需要
Netty
客户端? ⽐较好理解的,
NameServer
需要
NettyServer
。客户端,Producer
和
Consuer
,需要
NettyClient
。
Broker
需要
NettyServer
响应客户端请求,需要
NettyClient
向NameServer注册⼼跳。但是有个问题, 事务消息的
Producer
也需要响应
Broker
的事务状态回查,他需要NettyServer吗?
2
、所有的
RPC
请求数据都封账成
RemotingCommand
对象。⽽每个处理消息的服务逻辑,都会封装成⼀个NettyRequestProcessor对象。
3
、服务端和客户端都维护⼀个
processorTable
,这是个
HashMap
。
key
是服务码
requestCode
,
value
是对应的运⾏单元 Pair<NettyRequestProcessor,ExecutorService>
类型,包含了处理
Processor
和执⾏线程的线程池。具体的Processor
,由业务系统⾃⾏注册。
Broker
服务注册⻅,
BrokerController.registerProcessor()
,客户端的服务注册⻅MQClientAPIImpl
。
NameServer
则会注册⼀个⼤的
DefaultRequestProcessor
,统⼀处理所有服务。
4
、请求类型分为
REQUEST
和
RESPONSE
。这是为了⽀持异步的
RPC
调⽤。
NettyServer
处理完请求后,可以先缓存到responseTable
中,等
NettyClient
下次来获取,这样就不⽤阻塞
Channel了,可以提升请求吞吐量。
5
、重点理解
remoting
包中是如何实现全流程异步化。
整体
RPC
框架流程如下图:
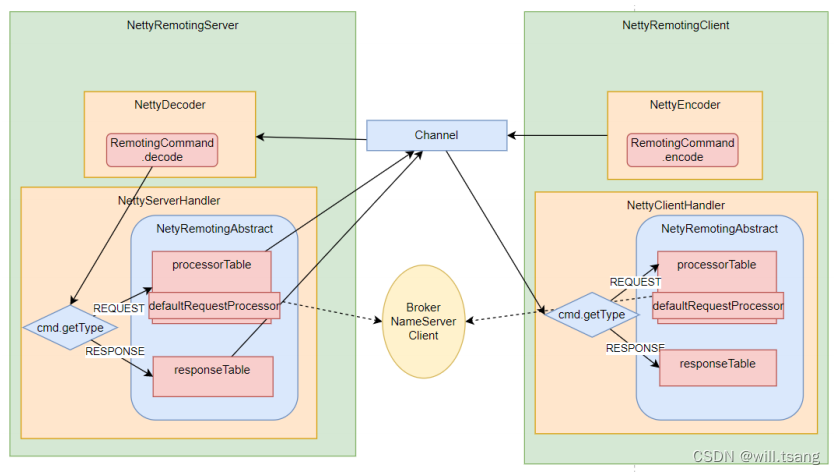
RocketMQ
使⽤
Netty
框架提供了⼀套基于服务码的服务注册机制,让各种不同的组件都可以按照⾃⼰的需求,注册⾃⼰的服务⽅法。RocketMQ
的这⼀套服务注册机制,是⾮常简洁使⽤的。在使⽤
Netty
进⾏其他相关应⽤开发时,都可以借鉴他的这⼀套服务注册机制。例如要开发⼀个⼤型的IM
项⽬,要加减好友、发送⽂本,图⽚,甚⾄红包、维护群聊信息等等各种各样的请求,这些请求如何封装,就可以很好的参考这个框架。
3
、关于
RocketMQ
的同步结果推送与异步结果推送
RocketMQ
的
RemotingServer
服务端,会维护⼀个
responseTable
,这是⼀个线程同步的
Map
结构。
key
为请求的ID
,
value
是异步的消息结果。
ConcurrentMap<Integer /* opaque */, ResponseFuture>
。
处理同步请求
(NettyRemotingAbstract#invokeSyncImpl)
时,处理的结果会存⼊
responseTable
,通过ResponseFuture提供⼀定的服务端异步处理⽀持,提升服务端的吞吐量。 请求返回后,⽴即从
responseTable
中移除请求记录。
实际上,同步也是通过异步实现的。

处理异步请求
(NettyRemotingAbstract#invokeAsyncImpl)
时,处理的结果依然会存⼊
responsTable
,等待客户端后续再来请求结果。但是他保存的依然是⼀个ResponseFuture
,也就是在客户端请求结果时再去获取真正的结果。 另外,在RemotingServer
启动时,会启动⼀个定时的线程任务,不断扫描
responseTable
,将其中过期的response清除掉。

4
、
Broker
⼼跳注册管理
1
、关注重点
之前介绍过,
Broker
会在启动时向所有
NameServer
注册⾃⼰的服务信息,并且会定时往
NameServer
发送⼼跳信息。⽽NameServer
会维护
Broker
的路由列表,并对路由表进⾏实时更新。这⼀轮就重点梳理这个过程。
2
、源码重点
Broker
启动后会⽴即发起向
NameServer
注册⼼跳。⽅法⼊⼝:
BrokerController.this.registerBrokerAll
。 然后启动⼀个定时任务,以10
秒延迟,默认
30
秒的间隔持续向
NameServer
发送⼼跳。
NameServer
内部会通过
RouteInfoManager
组件及时维护
Broker
信息。同时在
NameServer
启动时,会启动定时任务,扫描不活动的Broker
。⽅法⼊⼝:
NamesrvController.initialize
⽅法。
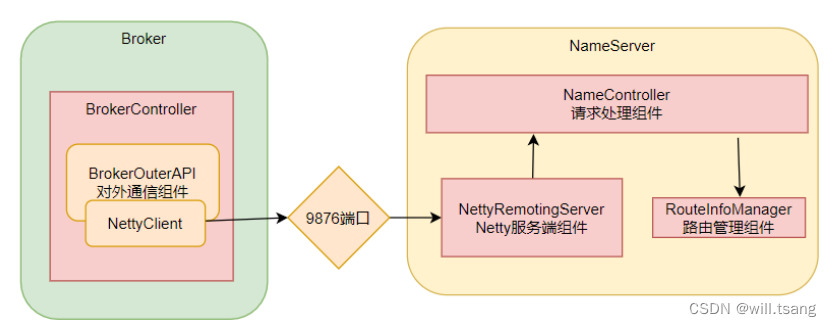
3
、极简化的服务注册发现流程
为什么
RocketMQ
要⾃⼰实现⼀个
NameServer
,⽽不⽤
Zookeeper
、
Nacos
这样现成的注册中⼼?
⾸先,依赖外部组件会对产品的独⽴性形成侵⼊,不利于⾃⼰的版本演进。
Kafka
要抛弃
Zookeeper
就是⼀个先例。
另外,其实更重要的还是对业务的合理设计。
NameServer
之间不进⾏信息同步,⽽是依赖
Broker
端向所有NameServer同时发起注册。这让
NameServer
的服务可以⾮常轻量。如果可能,你可以与
Nacos
或
Zookeeper
的核⼼流程做下对⽐。
但是,要知道,这种极简的设计,其实是以牺牲数据⼀致性为代价的。
Broker
往多个
NameServer
同时发起注册,有可能部分NameServer
注册成功,⽽部分
NameServer
注册失败了。这样,多个
NameServer
之间的数据是不⼀致的。作为注册中⼼,这是不可接受的。但是对于RocketMQ
,这⼜变得可以接受了。因为客户端从NameServer上获得的,只要有⼀个正常运⾏的
Broker
就可以了,并不需要完整的
Broker
列表。
5
、
Producer
发送消息过程
1
、关注重点
⾸先:回顾下我们之前的
Producer
使⽤案例。
Producer
有两种:
· ⼀种是普通发送者:
DefaultMQProducer
。只负责发送消息,发送完消息,就可以停⽌了。
· 另⼀种是事务消息发送者:
TransactionMQProducer
。⽀持事务消息机制。需要在事务消息过程中提供事务状态确认的服务,这就要求事务消息发送者虽然是⼀个客户端,但是也要完成整个事务消息的确认机制后才能退出。
事务消息机制后⾯将结合
Broker
进⾏整理分析。这⼀步暂不关注。我们只关注
DefaultMQProducer
的消息发送过程。
然后:整个
Producer
的使⽤流程,⼤致分为两个步骤:⼀是调⽤
start
⽅法,进⾏⼀⼤堆的准备⼯作。
⼆是各种send⽅法,进⾏消息发送。
那我们重点关注以下⼏个问题:
1
、
Producer
启动过程中启动了哪些服务
2
、
Producer
如何管理
broker
路由信息。 可以设想⼀下,如果
Producer
启动了之后,
NameServer
挂了,那么Producer还能不能发送消息?希望你先从源码中进⾏猜想,然后⾃⼰设计实验进⾏验证。
3
、关于
Producer
的负载均衡。也就是
Producer
到底将消息发到哪个
MessageQueue
中。这⾥可以结合顺序消息机制来理解⼀下。消息中那个莫名奇妙的MessageSelector
到底是如何⼯作的。
2
、源码重点
1
、
Producer
的核⼼启动流程
所有
Producer
的启动过程,最终都会调⽤到
DefaultMQProducerImpl#start
⽅法。在
start
⽅法中的通过⼀个mQClientFactory对象,启动⽣产者的⼀⼤堆重要服务。
这⾥其实就是⼀种设计模式,虽然有很多种不同的客户端,但是这些客户端的启动流程最终都是统⼀的,全是交由mQClientFactory
对象来启动。⽽不同之处在于这些客户端在启动过程中,按照服务端的要求注册不同的信息。
例如⽣产者注册到
producerTable
,消费者注册到
consumerTable
,管理控制端注册到adminExtTable
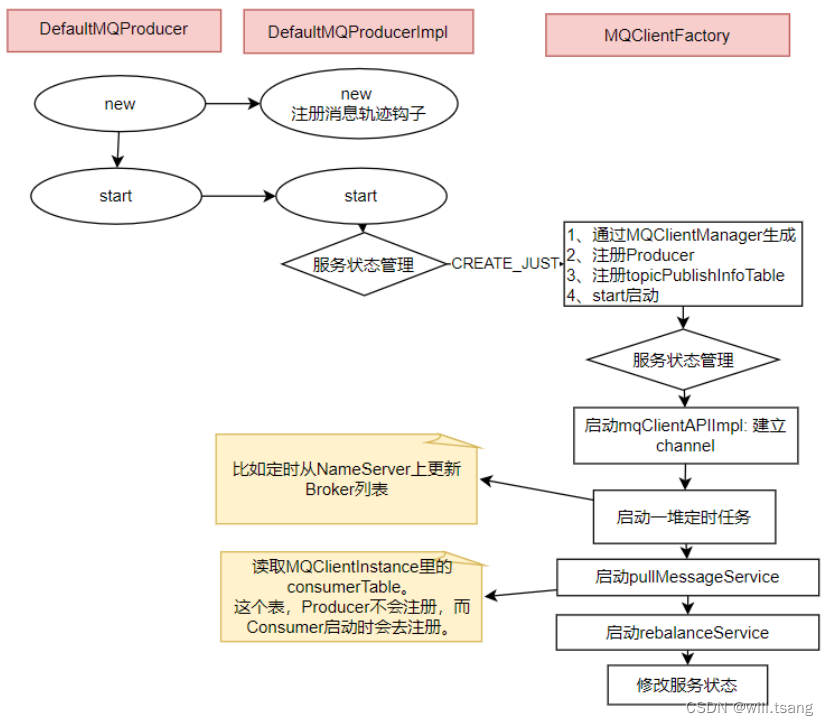
2
、发送消息的核⼼流程
核⼼流程如下:
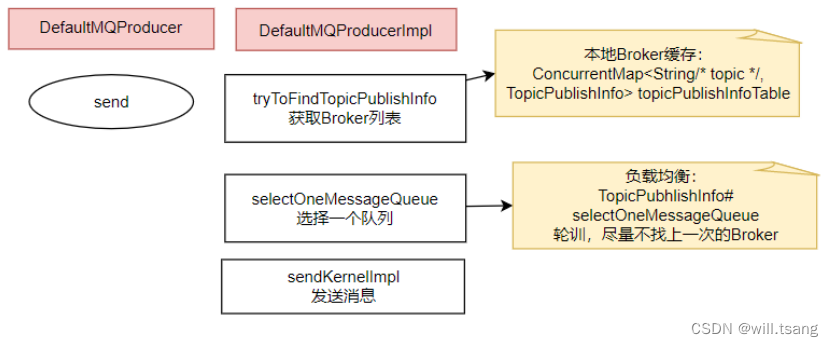
1
、发送消息时,会维护⼀个本地的
topicPublishInfoTable
缓存,
DefaultMQProducer
会尽量保证这个缓存数据是最新的。但是,如果NameServer
挂了,那么
DefaultMQProducer
还是会基于这个本地缓存去找
Broker
。只要能找到Broker
,还是可以正常发送消息到
Broker
的。
--
可以在⽣产者示例中,
start
后打⼀个断点,然后把NameServer停掉,这时,
Producer
还是可以发送消息的。
2
、⽣产者如何找
MessageQueue
: 默认情况下,⽣产者是按照轮训的⽅式,依次轮训各个
MessageQueue
。但是如果某⼀次往⼀个Broker
发送请求失败后,下⼀次就会跳过这个
Broker
。

3
、如果在发送消息时传了
Selector
,那么
Producer
就不会⾛这个负载均衡的逻辑,⽽是会使⽤
Selector
去寻找⼀个队列。 具体参⻅org.apache.rocketmq.client.impl.producer.DefaultMQProducerImpl#sendSelectImpl
⽅法。
6
、
Consumer
拉取消息过程
1
、关注重点
结合我们之前的示例,回顾下消费者这⼀块的⼏个重点问题:
· 消费者也是有两种,推模式消费者和拉模式消费者。优秀的
MQ
产品都会有⼀个⾼级的⽬标,就是要提升整个消息处理的性能。⽽要提升性能,服务端的优化⼿段往往不够直接,最为直接的优化⼿段就是对消费者进⾏优化。所以在RocketMQ
中,整个消费者的业务逻辑是⾮常复杂的,甚⾄某种程度上来说,⽐服务端更复杂,所以,在这⾥我们重点关注⽤得最多的推模式的消费者。
· 消费者组之间有集群模式和⼴播模式两种消费模式。我们就要了解下这两种集群模式是如何做的逻辑封装。
·
然后我们关注下消费者端的负载均衡的原理。即消费者是如何绑定消费队列的,哪些消费策略到底是如何落地的。
· 最后我们来关注下在推模式的消费者中,
MessageListenerConcurrently
和
MessageListenerOrderly
这两种消息监听器的处理逻辑到底有什么不同,为什么后者能保持消息顺序。
2
、源码重点
Consumer
的核⼼启动过程和
Producer
是⼀样的, 最终都是通过
mQClientFactory
对象启动。不过之间添加了⼀些注册信息。整体的启动过程如下:
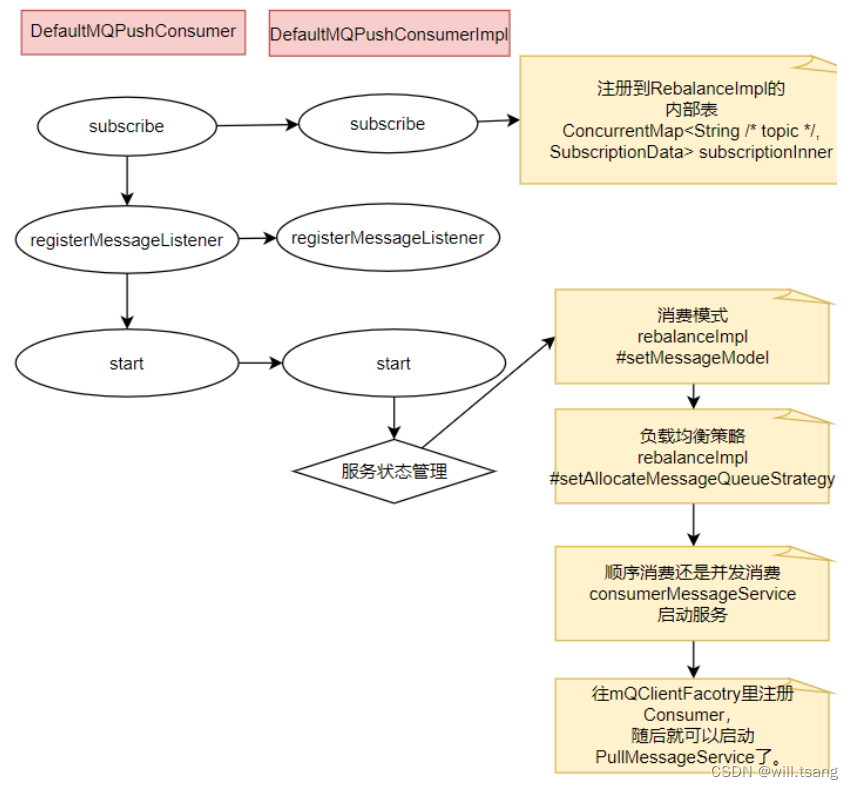
3
、⼴播模式与集群模式的
Offset
处理
在
DefaultMQPushConsumerImpl
的
start
⽅法中,启动了⾮常多的核⼼服务。 ⽐如,对于⼴播模式与集群模式的Offset处理

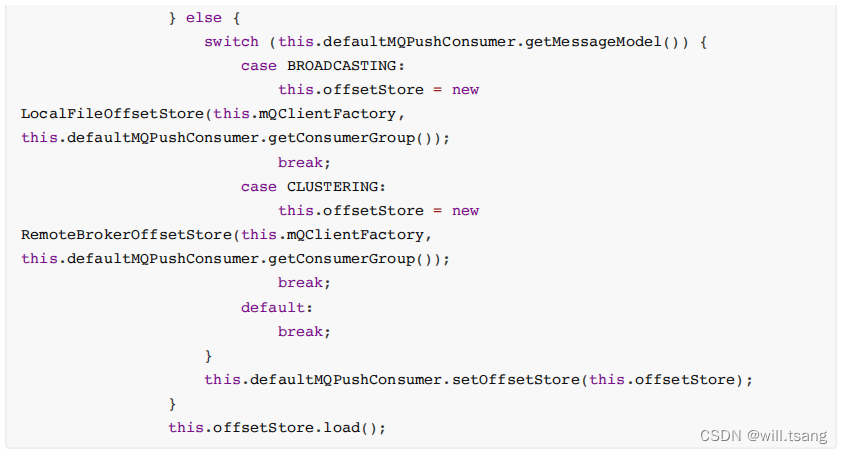
可以看到,⼴播模式是使⽤
LocalFileOffsetStore
,在
Consumer
本地保存
Offset
,⽽集群模式是使⽤RemoteBrokerOffsetStore,在
Broker
端远程保存
offset
。⽽这两种
Offset
的存储⽅式,最终都是通过维护本地的offsetTable缓存来管理
Offset
。
4
、
Consumer
与
MessageQueue
建⽴绑定关系
start
⽅法中还⼀个⽐较重要的东⻄是给
rebalanceImpl
设定了⼀个
AllocateMessageQueueStrategy
,⽤来给Consumer分配
MessageQueue
的。

这个
AllocateMessageQueueStrategy
就是⽤来给
Consumer
和
MessageQueue
之间建⽴⼀种对应关系的。也就是说,只要Topic
当中的
MessageQueue
以及同⼀个
ConsumerGroup
中的
Consumer
实例都没有变动,那么某⼀个Consumer
实例只是消费固定的⼀个或多个
MessageQueue
上的消息,其他
Consumer
不会来抢这个
Consumer对应的MessageQueue
。
关于负载均衡机制,会在后⾯结合
Producer
的发送消息策略⼀起总结。不过这⾥,你可以想⼀下为什么要让⼀个MessageQueue
只能由同⼀个
ConsumerGroup
中的⼀个
Consumer
实例来消费。
其实原因很简单,因为
Broker
需要按照
ConsumerGroup
管理每个
MessageQueue
上的
Offset
,如果⼀个MessageQueue上有多个同属⼀个
ConsumerGroup
的
Consumer
实例,他们的处理进度就会不⼀样。这样的话,Offset就乱套了。
5
、顺序消费与并发消费
同样在
start
⽅法中,启动了
consumerMessageService
线程,进⾏消息拉取。

可以看到,
Consumer
通过
registerMessageListener
⽅法指定的回调函数,都被封装成了
ConsumerMessageService
的⼦实现类。
⽽对于这两个服务实现类的调⽤,会延续到
DefaultMQPushConsumerImpl
的
pullCallback
对象中。也就是Consumer每拉过来⼀批消息后,就向
Broker
提交下⼀个拉取消息的的请求。

⽽这⾥提交的,实际上是⼀个
ConsumeRequest
线程。⽽提交的这个
ConsumeRequest
线程,在两个不同的ConsumerService中有不同的实现。
这其中,两者最为核⼼的区别在于
ConsumerMessageOrderlyService
是锁定了⼀个队列,处理完了之后,再消费下⼀个队列。

为什么给队列加个锁,就能保证顺序消费呢?结合顺序消息的实现机制理解⼀下。
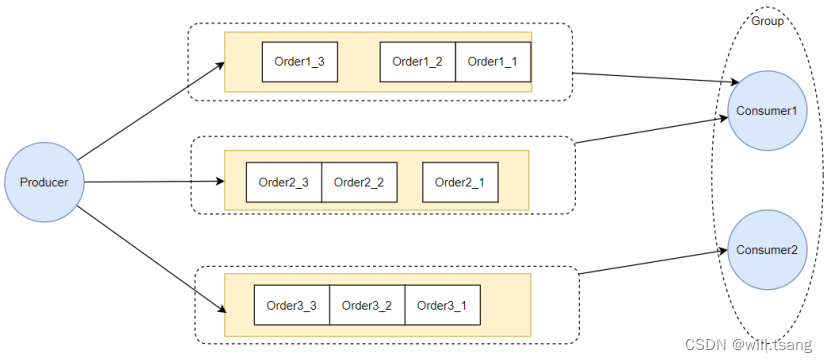
从源码中可以看到,
Consumer
提交请求时,都是往线程池⾥异步提交的请求。如果不加队列锁,那么就算Consumer提交针对同⼀个
MessageQueue
的拉取消息请求,这些请求都是异步执⾏,他们的返回顺序是乱的,⽆法进⾏控制。给队列加个锁之后,就保证了针对同⼀个队列的第⼆个请求,必须等第⼀个请求处理完了之后,释放了锁,才可以提交。这也是在异步情况下保证顺序的基础思路。
6
、实际拉取消息还是通过
PullMessageService
完成的。
start
⽅法中,相当于对很多消费者的服务进⾏初始化,包括指定⼀些服务的实现类,以及启动⼀些定时的任务线程,⽐如清理过期的请求缓存等。最后,会随着mQClientFactory
组件的启动,启动⼀个
PullMessageService
。实际的消息拉取都交由PullMesasgeService
进⾏。
所谓消息推模式,其实还是通过
Consumer
拉消息实现的。

7
、客户端负载均衡管理总结
从之前
Producer
发送消息的过程以及
Conmer
拉取消息的过程,我们可以抽象出
RocketMQ
中⼀个消息分配的管理模型。这个模型是我们在使⽤RocketMQ
时,很重要的进⾏性能优化的依据。
1 Producer
负载均衡
Producer
发送消息时,默认会轮询⽬标
Topic
下的所有
MessageQueue
,并采⽤递增取模的⽅式往不同的MessageQueue上发送消息,以达到让消息平均落在不同的
queue
上的⽬的。⽽由于
MessageQueue
是分布在不同的Broker
上的,所以消息也会发送到不同的
broker
上。
在之前源码中看到过,
Producer
轮训时,如果发现往某⼀个
Broker
上发送消息失败了,那么下⼀次会尽量避免再往同⼀个Broker
上发送消息。但是,如果你的应⽤场景允许发送消息⻓延迟,也可以给
Producer
设定setSendLatencyFaultEnable(true)。这样对于某些
Broker
集群的⽹络不是很好的环境,可以提⾼消息发送成功的⼏率。
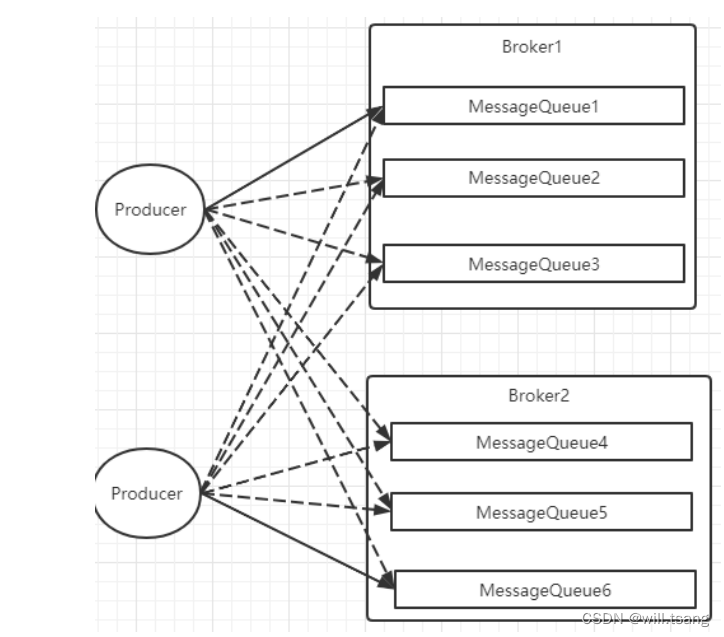
同时⽣产者在发送消息时,可以指定⼀个
MessageQueueSelector
。通过这个对象来将消息发送到⾃⼰指定的MessageQueue上。这样可以保证消息局部有序。
2 Consumer
负载均衡
Consumer
也是以
MessageQueue
为单位来进⾏负载均衡。分为集群模式和⼴播模式。
1
、集群模式
在集群消费模式下,每条消息只需要投递到订阅这个
topic
的
Consumer Group
下的⼀个实例即可。
RocketMQ
采⽤主动拉取的⽅式拉取并消费消息,在拉取的时候需要明确指定拉取哪⼀条message queue
。
⽽每当实例的数量有变更,都会触发⼀次所有实例的负载均衡,这时候会按照
queue
的数量和实例的数量平均分配queue
给每个实例。
每次分配时,都会将
MessageQueue
和消费者
ID
进⾏排序后,再⽤不同的分配算法进⾏分配。内置的分配的算法共有六种,分别对应AllocateMessageQueueStrategy
下的六种实现类,可以在
consumer
中直接
set
来指定。默认情况下使⽤的是最简单的平均分配策略。
· AllocateMachineRoomNearby
: 将同机房的
Consumer
和
Broker
优先分配在⼀起。
这个策略可以通过⼀个
machineRoomResolver
对象来定制
Consumer
和
Broker
的机房解析规则。然后还需要引⼊另外⼀个分配策略来对同机房的Broker
和
Consumer
进⾏分配。⼀般也就⽤简单的平均分配策略或者轮询分配策略。
源码中有测试代码
AllocateMachineRoomNearByTest
。
在示例中:
Broker
的机房指定⽅式:
messageQueue.getBrokerName().split("-")[0]
,⽽
Consumer
的机房指定⽅式:clientID.split("-")[0]
clinetID
的构建⽅式:⻅
ClientConfig.buildMQClientId
⽅法。按他的测试代码应该是要把
clientIP
指定为
IDC1-CID-0这样的形式。
· AllocateMessageQueueAveragely
:平均分配。将所有
MessageQueue
平均分给每⼀个消费者
· AllocateMessageQueueAveragelyByCircle
: 轮询分配。轮流的给⼀个消费者分配⼀个
MessageQueue
。
· AllocateMessageQueueByConfig
: 不分配,直接指定⼀个
messageQueue
列表。类似于⼴播模式,直接指定所有队列。
· AllocateMessageQueueByMachineRoom
:按逻辑机房的概念进⾏分配。⼜是对
BrokerName
和ConsumerIdc有定制化的配置。
· AllocateMessageQueueConsistentHash
。源码中有测试代码
AllocateMessageQueueConsitentHashTest
。
这个⼀致性哈希策略只需要指定⼀个虚拟节点数,是⽤的⼀个哈希环的算法,虚拟节点是为了让
Hash
数据在换上分布更为均匀。
最常⽤的就是平均分配和轮训分配了。例如平均分配时的分配情况是这样的:
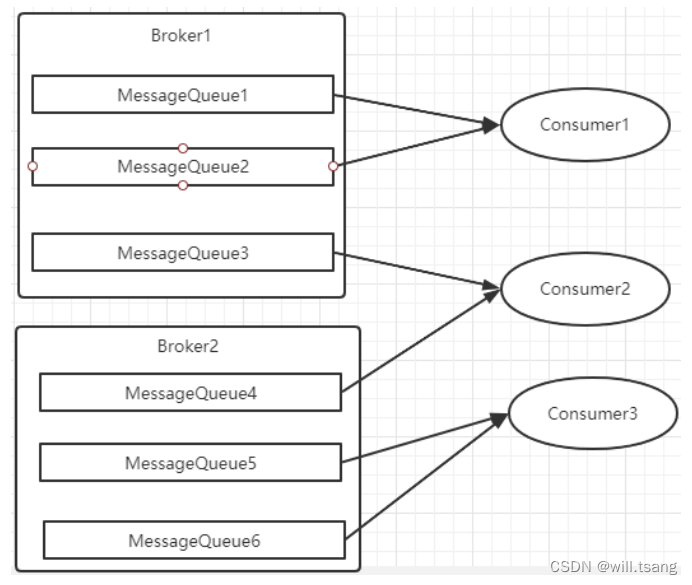
⽽轮训分配就不计算了,每次把⼀个队列分给下⼀个
Consumer
实例。
2
、⼴播模式
⼴播模式下,每⼀条消息都会投递给订阅了
Topic
的所有消费者实例,所以也就没有消息分配这⼀说。⽽在实现上,就是在Consumer
分配
Queue
时,所有
Consumer
都分到所有的
Queue
。
⼴播模式实现的关键是将消费者的消费偏移量不再保存到
broker
当中,⽽是保存到客户端当中,由客户端⾃⾏维护⾃⼰的消费偏移量。



![[NPUCTF2020]ReadlezPHP 反序列化简单反序列](https://img-blog.csdnimg.cn/0928b85ee9b64a3f973d3545c1e80941.png)