🐱作者:一只大喵咪1201
🐱专栏:《RTOS学习》
🔥格言:你只管努力,剩下的交给时间!

本喵默认各位小伙伴都会C语言,我们平时学习C语言都是在Windows环境下学习的,对于程序执行的底层逻辑了解的不是非常清楚,本喵在这里给大家介绍一下,C语言在单片机中是如何执行的。
单片机中的C语言
- 🍞CPU与外设
- 🥞Flash
- 🥞SRAM(内存)
- 栈
- 数据段
- 堆
- 🍞变量的初始化
- 🥞局部变量
- 🥞全局变量和静态变量
- 🍞函数
- 🍞指针变量
- 🍞结构体和联合体
- 🍞总结
🍞CPU与外设
我们知道,单片机也是有CPU的,它负责执行代码,运算数据,以及发出控制信号等功能,而与CPU直接相连的设备我们称之为外设(就是集成芯片)。
本喵以STM32F103ZET6为例来讲解,该芯片使用的是ARM架构,该架构采用的是哈弗结构。
- 哈弗结构:内存和外设统一编址。
ARM芯片属于精简指令集计算机(RISC:Reduced Instruction Set Computing),它所用的指令比较简单,有如下特点:
① 对内存只有读、写指令。
② 对于数据的运算是在CPU内部实现。
③ 使用RISC指令的CPU复杂度小一点,易于设计。
比如对于a=a+b这样的算式,需要经过下面4个步骤才可以实现:
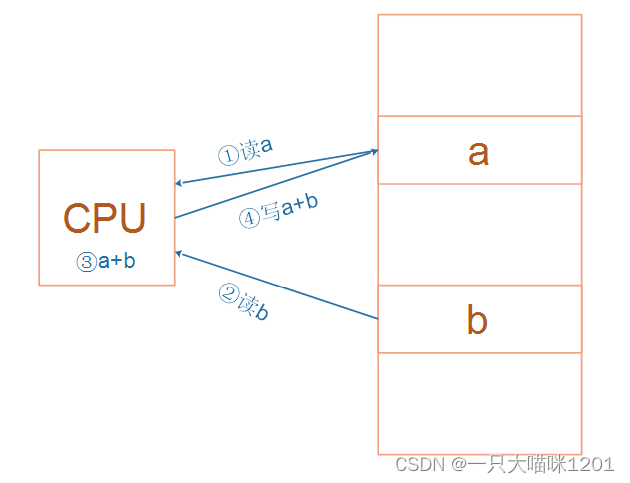
细看这几个步骤,有些疑问,a的值读出来后保存在CPU里面哪里?b的值读出来后保存在CPU里面哪里? a+b的结果又保存在哪里?
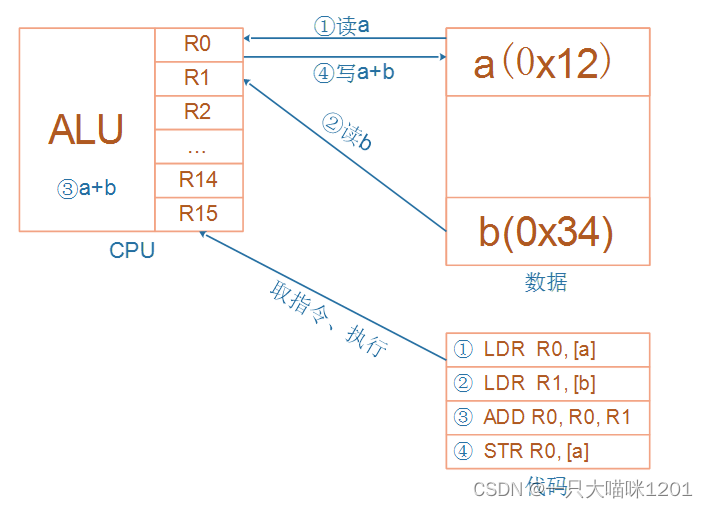
如上图所示,CPU也是有多个部分组成的,包括ALU逻辑运算单元,控制单元,以及多个寄存器等等。
假设变量a的地址是0x12,变量b的地址是0x34,第一步的汇编代码LDR R0, [a]的意思就是将0x12地址中的值读取到R0寄存器中,第二部读取b变量同理。
- LDR + 第一操作数 + 第二操作数:就是将第二操作数的值赋第一操作数。
当变量a和变量b都被读到了CPU的寄存器中后,执行第三步汇编代码ADDR R0, R0, R1,意思是将R0和R1中的值相加,然后将结果保存到R0中。
- ADD:相加的汇编指令,可以有三个操作数也可以有两个操作数,三个操作数则后两个操作数相加,得的结构均保存到第一个操作数。
最后就是将R0中的计算结果再写回到内存中,执行第四步汇编代码STR R0,[a],意思是将R0中的值写入到变量a的地址处0x12。
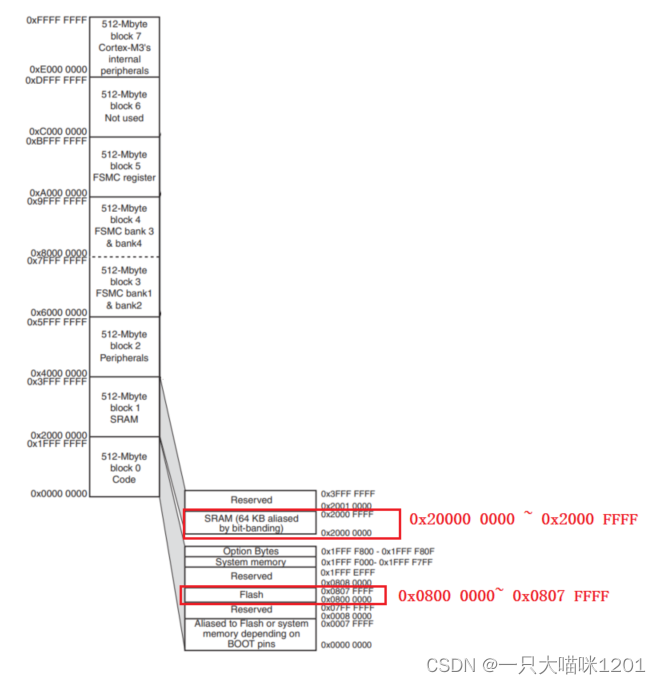
如上图所示,由于有32根地址线,所以CPU可访问的地址范围就是0x0000 0000 ~ 0xFFFF FFFF,就拿我们熟知的Flash和SRAM来说,它两和CPU直接相连,所以也可以看成是外设。
- Flash:用来存放用户烧录的程序,掉电数据不丢失(硬件特性)。
- SRAM:用来存放程序执行过程中的临时数据,掉电数据丢失。
Flash的地址范围是0x0800 0000 ~ 0x0807 FFFF,SRAM的地址范围是0x2000 0000 ~ 0x2000 FFFF,这是我们根据上面的图才知道的。
但是对于CPU而言,它并不知道哪里是FLASH哪里是SRAM,它只是被动的在执行代码。CPU在一上电以后就从0x0000 0000处开始执行代码(可以进行设置,以后再讲解),直到调用了我们C代码中必须有的main函数,然后进入我们自己的逻辑当中。
🥞Flash

如上图启动文件所示,CPU会通过BL汇编语句来调用main函数,但是在这之前,还会执行LDR汇编语句来给栈顶指针SP赋值。
- BL:跳转指令,也就是让程序跳转到指定位置处执行,相当于函数调用。
我们知道,代码最终会被转换成机器码让CPU去执行,而存放这些机器码也需要空间,所以代码也是有地址的。

如上图所示,无论是调用main函数之前的汇编代码,还是main函数的代码,它们的地址都是0x0800 0xxx,距离FLASH的起始地址0x0800 0000不是很远,说明我们烧录到单片机中的代码就是存放在FLASH中的。
- 无论是
main中的代码,还是前面的汇编代码,只要是从FLASH起始处开始的,都属于我们程序员写的代码。- 芯片厂家在
FLASH起始地址之前,固化了一些代码,这个暂不作说明。
🥞SRAM(内存)
栈
当main执行起来以后,运算数据得到的临时结果或者中间数据就都会暂存到SRAM上,也就是我们平常所说的内存中。
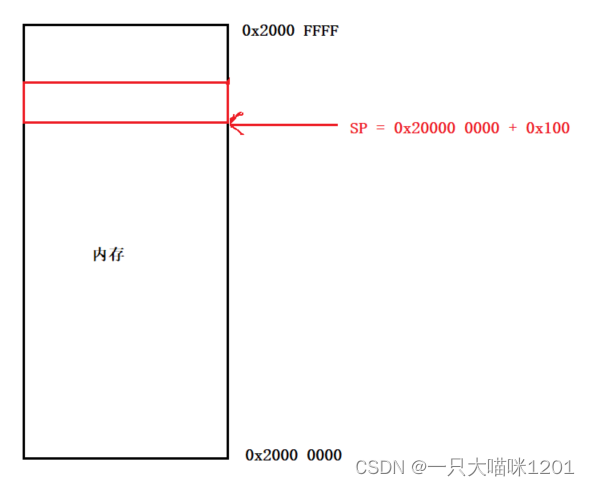
如上图所示,在使用BL调用main函数之前,还使用了LDR给栈顶指针SP赋了初值,红色箭头指向的位置就是栈顶指针指向的位置。
代码中的局部变量,函数栈帧等等数据,全部都存放在SP开始往下的位置,因为栈的开辟是从高地址向低地址。
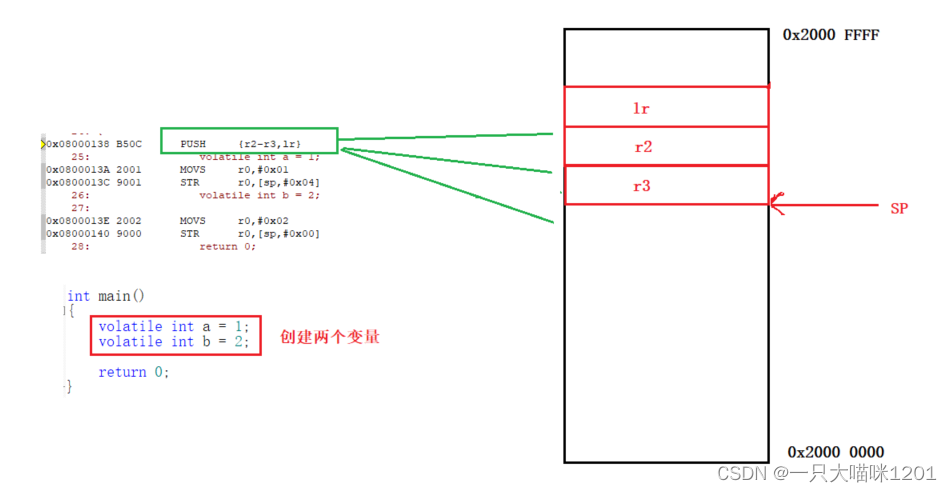
如上图所示,在main函数中创建两个变量a和b,加volatile的作用是防止编译器将这两个变量优化掉导致本喵无法演示现象。
main函数也是被调用的,所以在其内部创建的变量也属于局部变量,局部变量就统统存放在栈上。
汇编代码中,在创建变量a之前先执行了一句PUSH {r2-r3,lr}汇编语句,意思是将寄存器lr,寄存器r2和r3中的值压入栈中。
lr:寄存器存放的是函数的返回地址,其实就是CPU中的r15寄存器。PUSH:执行压栈操作,将数据压入到栈中后,栈顶指针向下移动。
此时向栈中压入了三个个数据,每个数据都是4字节的,所以SP向下移动了12个字节,这12个字节就可以看作当前main函数的栈帧大小。
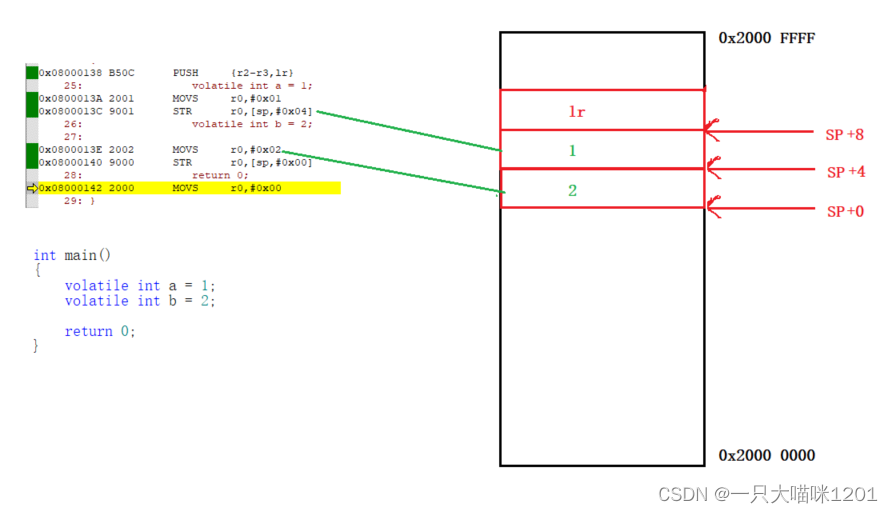
如上图,当执行到给变量a赋值1时,执行了汇编代码MOVS r0,#0x01,表示将数值1赋值给寄存器r0。然后再执行汇编代码STR r0,[sp,#0x04],表示将寄存器r0中的值,写入到sp + 0x04地址处。
- MOVS:将后一个操作数赋值给前一个操作数。
给变量b赋值2的时候,原理同上。所以此时在内存中就存在了1和2两个值,分别存在于sp+4和sp+0的位置处,后面用到变量a和b的时候,也是通过栈顶指针sp来找这两个值。
在这个过程中我们发现,寄存器r2和r3的的作用就是占坑,现在栈中给变量a和b占两个位置,等到STR赋值的时候将这两个位置覆盖即可。
那如果我创建100字节大小的数组呢?难道用100个寄存器来占坑吗?显然不可能,CPU一共也没那么多寄存器。
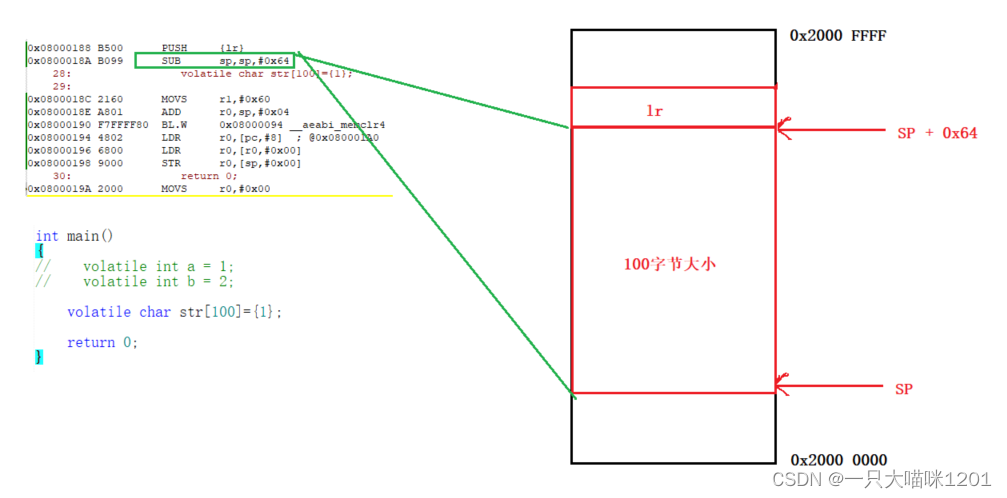
如上图所示,创建100字节大小的数组,先开辟100个字节大小的栈空间,执行汇编语句SUB sp,sp,#0x64,表示用当前的sp值减去0X64(100的16进制),将结果再赋值到sp中。
- SUB:用法和ADD相似,只是作用是后两个操作数做减法,得到的结果赋值给第一个操作数。
此时在SRAM(内存)上就存在一个100字节大小的栈用来存放这个str数组,此时它不使用占坑的方式了,而是直接改变SP的值来改变栈区的大小。
数据段
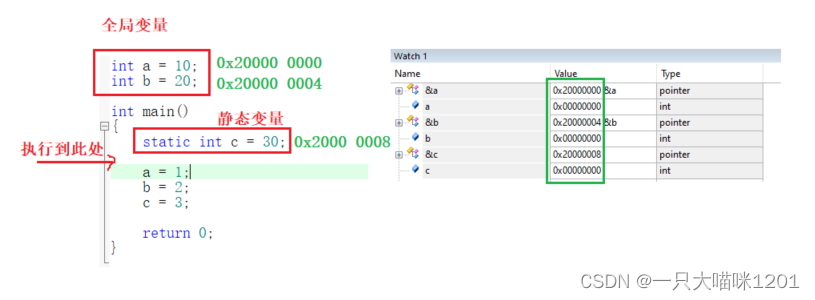
如上图所示,创建两个全局变量a和b,还有一个静态变量c,在调试窗口中可以看到,变量a的地址是0x20000 0000,变量b的地址是0x20000 0004,变量c的地址是0x2000 0008,这三个变量紧挨着。
- 在C语言学习中我们知道,全局变量和静态变量是存放在数据段的。
- 先忽略为什么它们的初始值都是0这个问题。
在最前面本喵放了一张内存地址映射图,其中SRAM的地址范围是0x2000 0000 ~ 0x20000 FFFF,也就是说内存的起始地址就是0x2000 0000,而变量a,b,c从起始位置开始存放,所以说这个位置就是数据段起始位置。
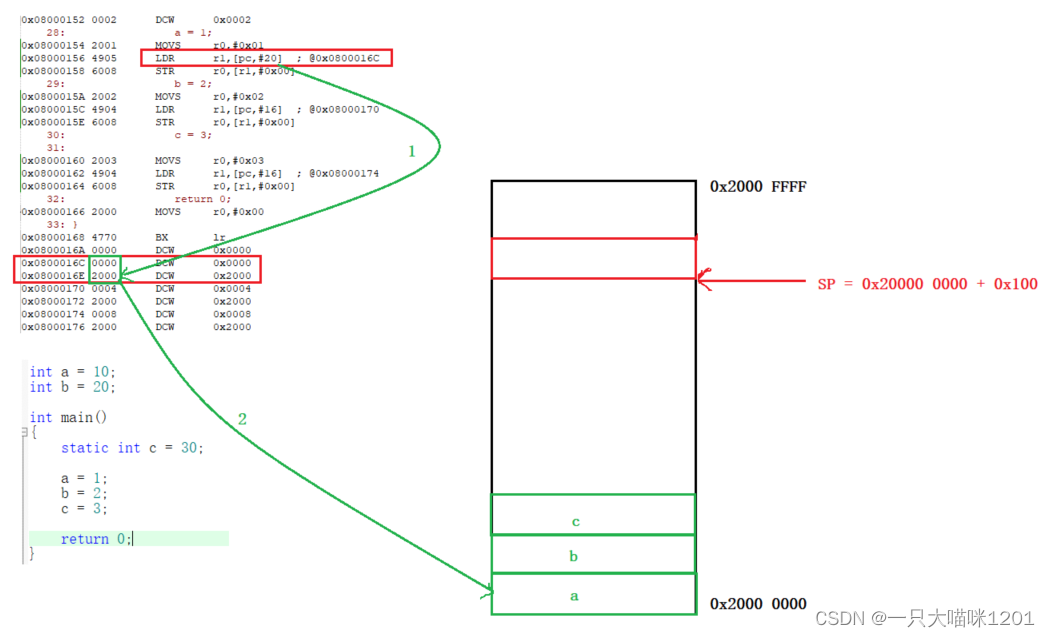
如上图所示,当给变量a赋值时,先执行MOVS r0,#0x01,将数值1赋值给寄存器r0,然后执行LDR r1,[pc,#20]语句,表示从PC + 20的地址处读取数据放入到寄存器r1中。
- PC:程序计数器,实际上就是CPU寄存器中的R15,它存放程序的地址,其值永远是当前语句的下一条语句的地址。
- CPU会根据PC值去执行对应的指令。
PC + 20的值是0x0800 0016C,这是一个Flash处的地址,而该地址处的值是0x0000,由于LDR一次取四个字节的数据,所以要连0x0800 0016E处的值0x2000也要读走,两个值按照大端存储模式复原(高地址存放高字节序),得到的值就是0x2000 0000。
所以此时寄存器r1中的值就是0x2000 0000,再执行STR r0,[r1,#0x00]汇编语句,将r0中的1写入到0x20000 0000处,也就是数据段变量a的地址处,此时就成功改变了它的值。
堆
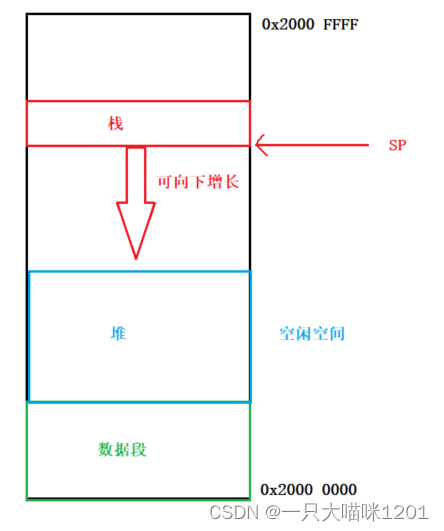
如上图,整个SRAM上,栈占用一部分空间,它的大小随着的SP的变化而变化,数据段占用一部分空间,但是还没有全部使用完毕,还有剩余的空闲空间,堆就建立在这部分空间上。
- 堆空间的大小并不会发生变化,它就是一块固定大小的空间,用户可以去申请使用,用完了还必须归还。
所以可以用一个大的全局数组来管理这块空间,因为全局数组存放在数据段,它的大小并不会随着SP的变化而变化,从而堆空间的大小也不会变化。
- 虽然叫做堆,但是这部分空间仍然属于数据段,只是提供了接操作这部分空间的接口。
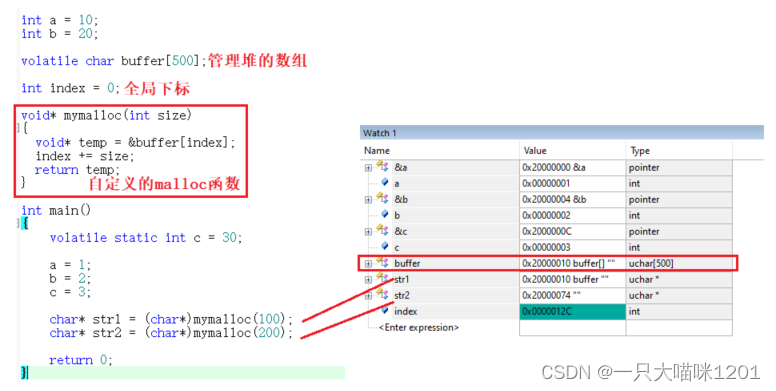
如上图所示,本喵定义了一个全局数组char buffer[500]来充当堆,还有一个全局的index用来记录堆的使用情况,又实现了一个mymalloc用来向堆区申请空间。
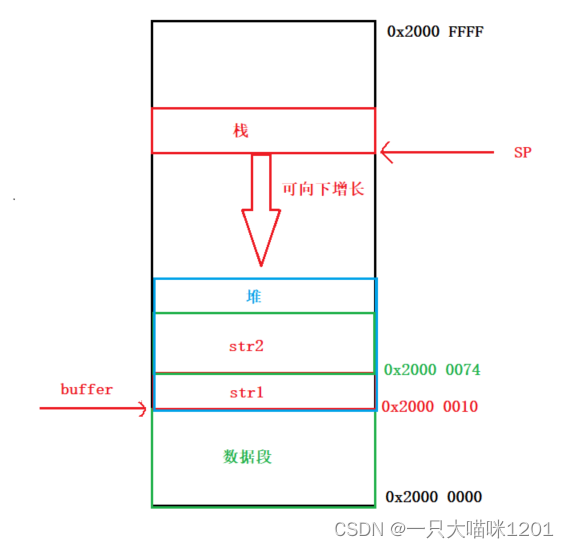
全局数组buffer的地址是0x2000 0010,排在a,b,c,index后面,第一次mymalloc以后,得到的地址是0x2000 0010,大小是100个字节,第二次mymalloc以后,得到的地址是0x2000 0074,地址相差0x64也就是100,说明这是在第一次申请的基础上再次申请的。index的值是0x12C也就是300,说明一共申请了300个字节的空间。
自定义的释放函数myfree本喵就不写了,各位小伙伴可以自行尝试。所以说,堆本质上就是就是一块空闲内存,可以使用malloc/free函数来管理它。
为什么Flash的起始地址就是0x0800 0000,SRAM的起始地址就是0x2000 0000?不能是别的吗?
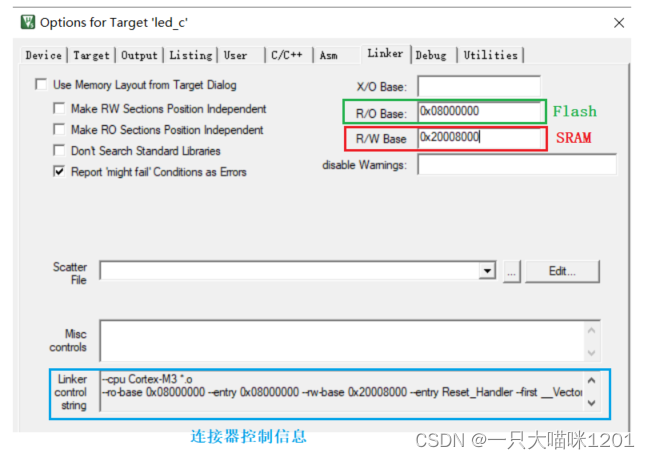
如上图所示,在MDK中,连接器选项中R/O Base是Flash基地址,用来设置Flash的起始地址,R/W Base是SRAM基地址,用来设置SRAM的起始地址。
下面蓝色框中的是连接器控制信息,里面的内容是我们程序员写的,目的是告诉连接器要做什么。
默认情况下,红色框中的SRAM起始地址是0x2000 0000,本喵将其该成了0x2000 8000,来看一下会发生什么?
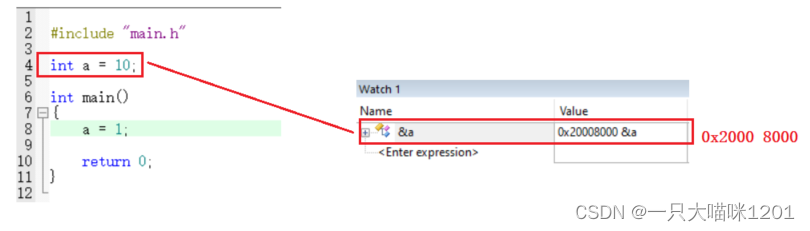
如上图所示,此时代码里只有一个全局变量a,它位于数据段的起始位置,也就是SRAM的起始位置,其地址是0x2000 8000,本喵成功的修改了SRAM的起始地址。
Flash的地址也是同理,也可以通过连接器R/O Base进行修改。
🍞变量的初始化
- 变量:能改变的量,它一定在内存上占据空间,
🥞局部变量

如上图所示,在main函数中创建了局部变量a并赋值0x11223344,创建了局部变量b并赋值0x11。在汇编代码中,首先移动SP,由于只有两个变量,所以压栈r2和r3来占位。
初始化变量a的时候,先执行LDR r0,[pc,#12]汇编语句,取地址为0x0800140的Flash中取值,读取了该地址及下个地址供四个字节数据0x11223344,赋值给寄存器r0。然后再执行STR r0,[sp,#0x04]汇编语句,将r0中的0x11223344赋值给变量a所在处。
初始化变量b的时候,先执行MOVS r0,#0x11汇编语句,直接将立即数#0x11赋值给寄存器r0,然后再执行STR r0,[sp,#0x00]汇编语句,将r0中的0x11赋值给变量b所在处。
- 两个局部变量的初始化过程并不一样,初始值为4字节的变量需要去
Flash中取初值,初始值为1字节的变量,直接就给赋值了。
指令也是有大小的,如0x08000132 4803 LDR r0,[pc,#12]中,0x08000132是代码所在的Flash地址,4803是代码汇编之后的机器码,大小是2字节(CPU执行的是机器码,汇编语句是为了方便我们看的,剩下的就是汇编语句)。
对于初始值为0x#11的初始化,两个字节的指令足够容纳一个字节的初值,所以直接就赋值初始化了。
对于初始值为0x11223344的初始化,两个字节的指令无法容纳四个字节的初值,所以必需取Flash中取初值到寄存器中,然后再进行赋值。
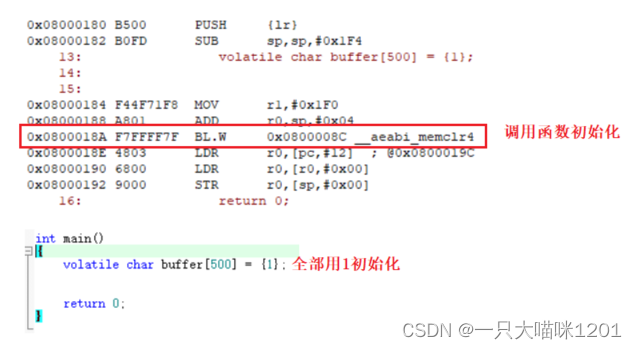
如上图,创建一个char buffer[500]数组全部用1初始化,使用BL.W指令跳转到__aeabi_memclr4处进行初始化,相当于调用了一个函数来初始化这个数组,这个函数是由编译器生成的,也是一堆汇编语句,这里本喵暂不做介绍。
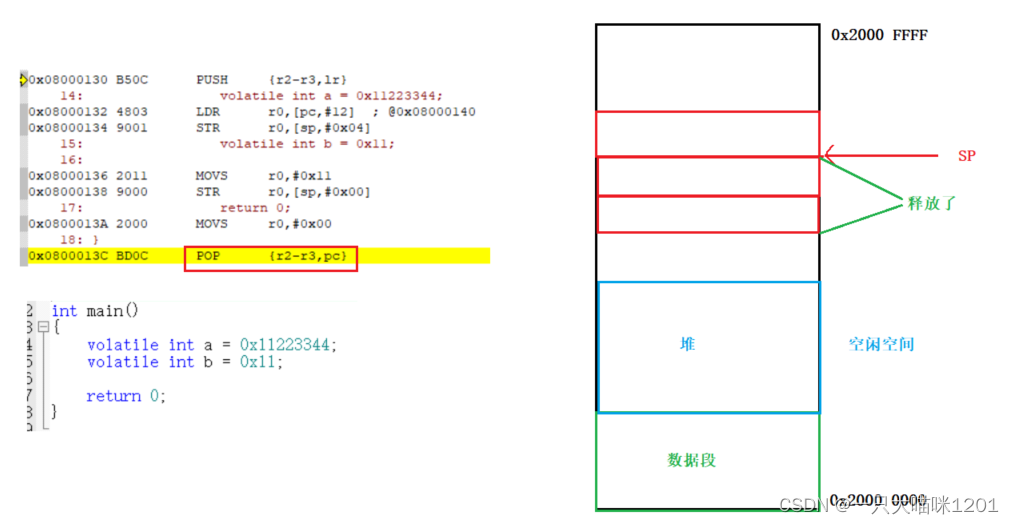
如上图,当main函数执行完,执行了return 0以后,会执行POP {r2-r3,pc}汇编语句,将前面压栈时向下生长的空间回收,也就是SP向上移动。
- POP:出栈操作,将栈中的数据弹出,并且
SP栈顶指针向上移动。
此时原本存放变量a和b的空间就位于栈外面了,原本的值弹出给了r0和r1,PC拿到函数的返回地址lr。
虽然a和b的内存空间还存在,但是已经不再被维护了,当有新的局部变量需要栈的时候,SP会重新向下移动,并且使用新的值覆盖掉这部分空间。
🥞全局变量和静态变量
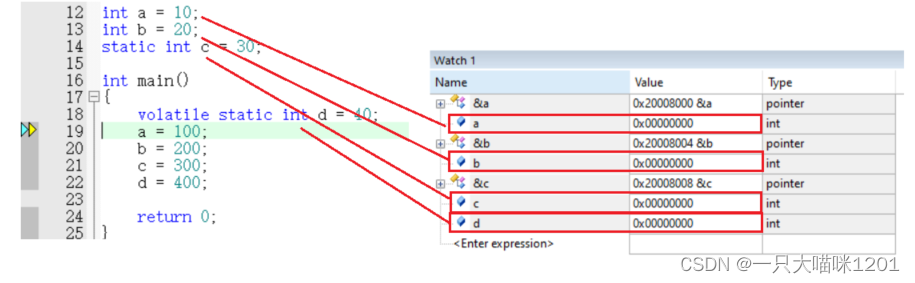
如上图所示,定义两个全局变量a和b,初始值分别为10和20,定义一个全局静态变量,初始值为30,定义一个局部静态变量,初始值为40,当程序执行到main中时,通过调试窗口看到它们的值都是0,并没有被初始化。

如上图,在启动文件中使用BL跳转到main函数之前,需要先跳转到copy函数,将全局变量的初始值全部复制到对应数据段的地址。但是这里本喵并没有实现copy函数,所以全局变量没有被初始化。
- 全局变量的初始值是存放在
Flash中的,注意是只存放初始值,不存放变量名,因为CPU执行的是机器码,机器码中并没有变量名这么一说。
copy函数的实现本喵在以后会详细介绍。
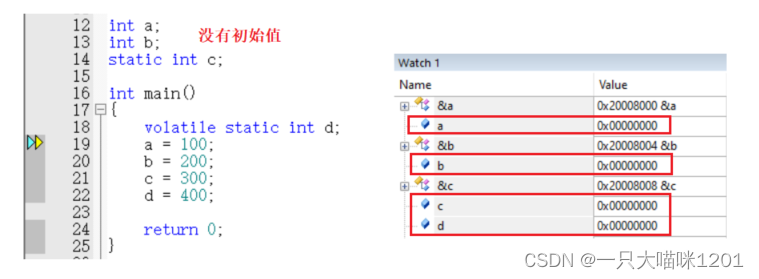
如上图,仍然是这四个变量,但是在定义都是时候都没有给初始值,没有进行初始化,但是在调试窗口看到它们的值仍然是0。
- 对于没有初始值的数据段变量,在编译的时候,编译器会用0将这些变量初始化,也就是将对应地址写0。
相当于会调用一个memset函数将这部分变量全部初始化为0。这些变量处于数据段的未初始化数据段,而前面有初始值的处于已初始化数据段。
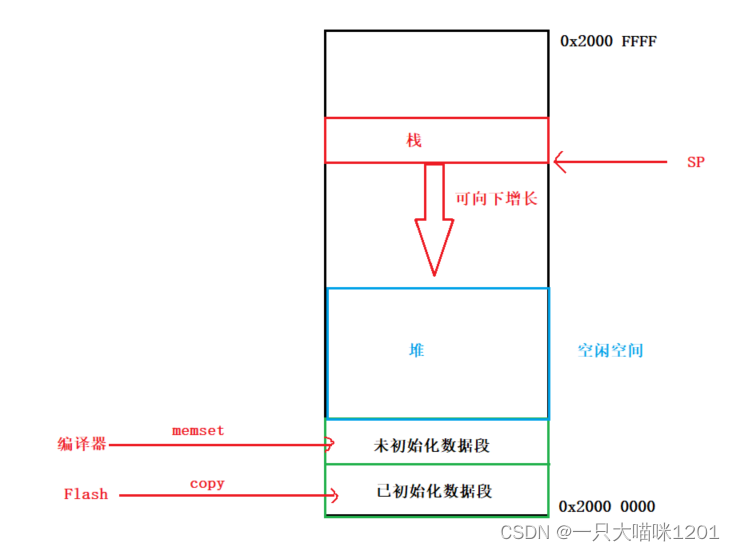
如上图所示,便是整个数据段的内存示意图。
在STM32F103中,代码是在FLASH中运行的,并不会加载到内存中,而且代码和数据段的初始值是混合存放在Flash中的。
🍞函数
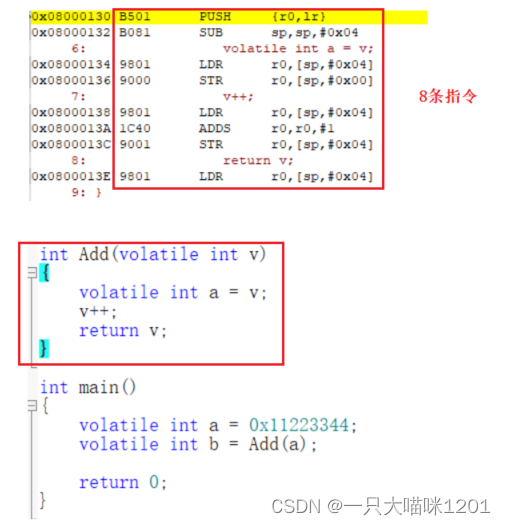
如上图所示,Add函数其实就是8条汇编指令,调用函数就是让CPU的PC寄存器等于8条指令的首地址,也就是函数地址。
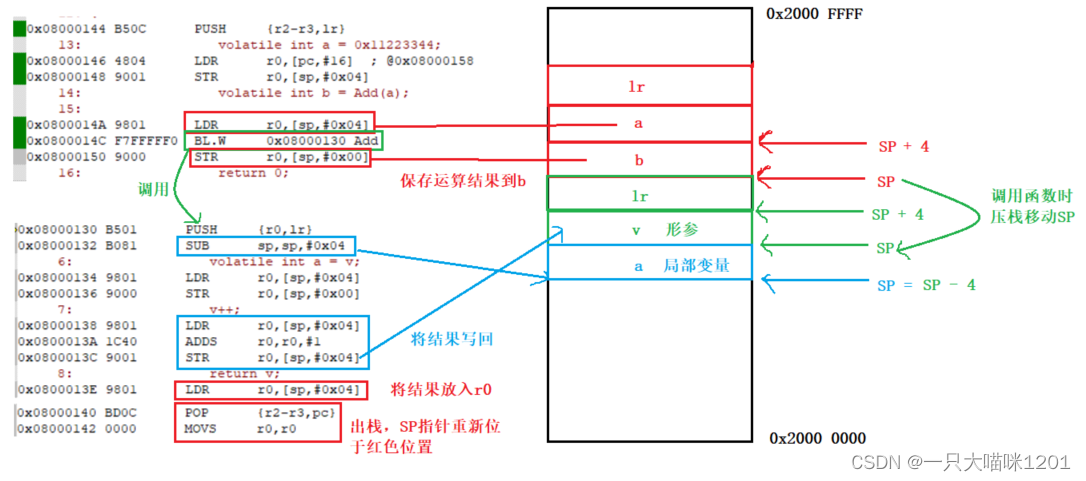
如上图,main函数开辟一次栈,SP位于上图红色位置,栈里有变量a和b以及main函数的返回地址lr。
在调用Add函数的时候,会再压一次栈,SP位于上图绿色位置,这次压入了Add函数的返回地址lr,以及形参v,再执行SUB语句为局部变量a开辟空间,SP位于上图蓝色位置。
- 函数传参通过寄存器
r0实现,在PUSH的时候,r0中已经有了实参,然后将实参压入调用函数的栈中成为形参。
然后执行LDR和STR将形参的值拿到局部变量a中,再进行加一操作,操作完毕后将结果再度写入到形参v的位置,当函数返回时,执行LDR将运算结果存入r0寄存器中,然后POP出栈操作,SP重新位于上图红色位置。
- 函数返回值的时候,同样通过
r0实现,SP虽然向上移动了,但是r0中有返回值。
调用函数结束后,执行STR将r0中的运算结果写入到变量b。

如上图,main函数在调用Add_Sum函数的时候,一次传入了八个变量,赋了初值以后,将其中的四个变量交给了寄存器r3-r7,然后执行STM sp,[r8-r11],将剩下的四个变量继续压栈。
- STM:一次存储多个寄存器中的值到指定位置。
在执行Add_Sum函数的时候,执行LDM r5,[r5-r7,r12],从栈中将后四个变量取出来,再与寄存器r3-r7中的四个值一起求和,最后将结果返回。
- LDM:一次读取多个值到多个寄存器中。
调用函数时,如果传入的变量比较多,或者是数组的话,由于没有那么多的寄存器可以作中间人,所以会将这些变量继续压入调用方的栈中,被调用函数在用的时候从调用方的栈中拿走进行拷贝。
这就是为什么我们在函数中改变形参,并不影响实参的原因,因为在函数中形参是实参的拷贝,它位于函数的栈中,调用方的栈并不受影响。
🍞指针变量

如上图,创建了一个int类型的变量,一个char类型的变量,一个int* 类型的变量,一个char* 类型的变量,从汇编出可以看出,指针变量同样要在栈中占用空间,只是初始化的时候,指针变量赋值的是地址,如ADD r2,sp,#0x04,就是将栈顶指针向上移动4个字节后的地址赋值给为int* pa变量占坑的r2。
- 指针变量仍然是变量,是变量就要占据内存空间,和普通的变量没有区别,只是它的值是地址而已。
在访问这两个指针变量时,*pa = 20,执行了STR r0,[r2,0x00],一次给变量a写入四个字节,*pb = 'B',执行了STRB r0,[r11#0x00],一次给变量b写入一个字节。
- STRB:存储一个字节数据,作用和STR一样,只是写入字节是一个字节。
访问不同类型的指针,底层会有不同的策略,让CPU以对应的视角去操作对应的内存。如*pa,CPU就会认为它现在访问地址处的变量是一个int类型,而不是一个char类型。
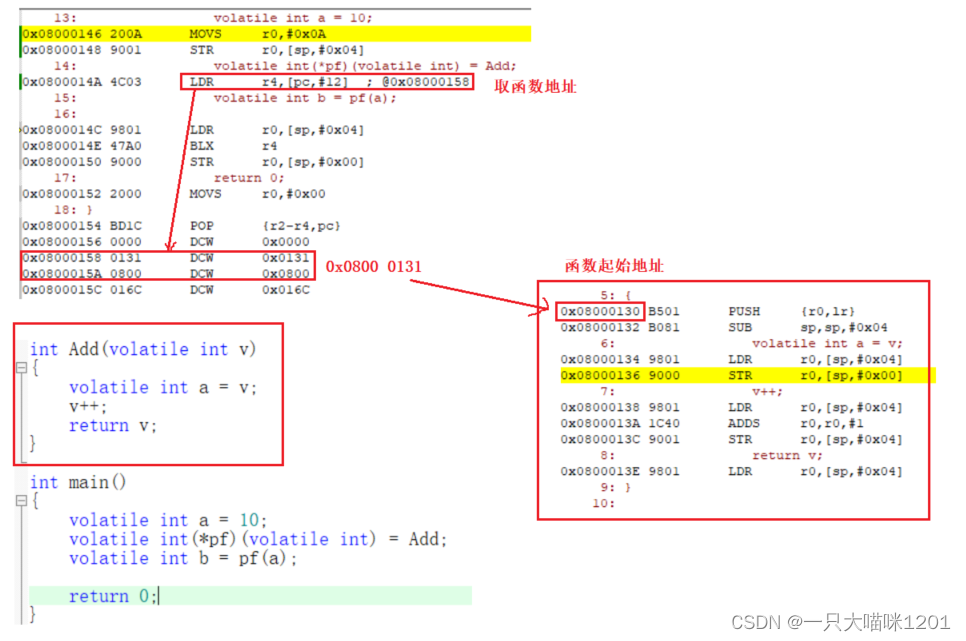
如上图,创建函数指针变量int(*pf)(volatile int),将函数Add地址赋值给变量pf。执行LDR r4,[pc,#12]到Flash的0x0800 0158处取函数地址为0x0800 0131。
但是我们看到函数的8条指令的起始地址是0x0800 0130,与r4中取到的函数地址相差1,这是因为在0x0800 0158处存放的0x0800 0131代表两层意思。
- 函数地址的最低位为1表示该函数使用的是
Thumb指令集,这个1和实际地址没有关系。- 该值减去1才是真正的函数起始地址,也就是
0x0800 0130。
无论什么类型的指针变量,它里面存放的都是相应变量的首地址,包括函数指针变量,再通过策略决定CPU读写该首地址后面几个字节。
🍞结构体和联合体
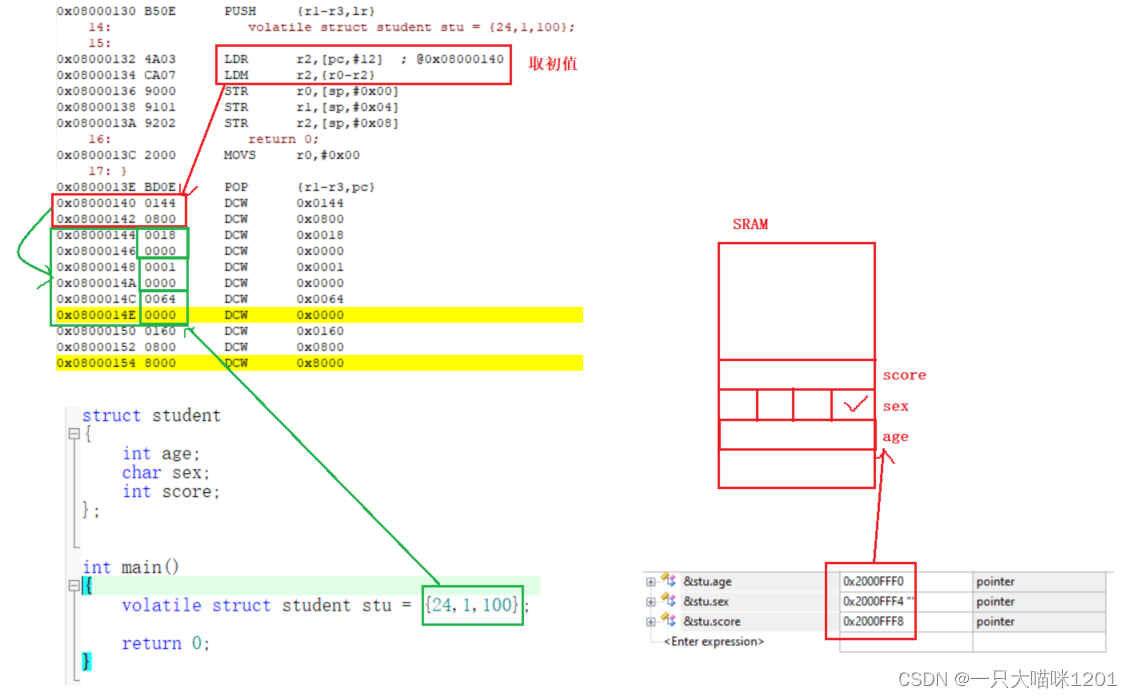
如上图,创建一个局部结构体变量,有三个成员变量int age,char sex,int score,并且给它们初始化。先执行LDR拿到在Flash中存放初始值的地址0x0800 0144到r2中,然后再执行LDM从初值起始地址开始读取初值0x0000 18,0x0000 00001,0x0000 0064,对应着24,1,100。
- 结构体初始化时,初值存放在
Flash中,需要读取到寄存器中,然后再赋值给结构体各个成员。
通过调试窗口查看三个成员的地址,发现成员之间的地址相差4个字节,其中int age和int score是四字节变量占用4个空间,但是char sex是一字节变量也占用四个空间。
如上图中SRAM示意图所示,此时sex的四个字节中只用了一个字节,浪费了三个字节。
- 为了提高结构体的访问效率,结构体变量在存放时会进行内存对齐。
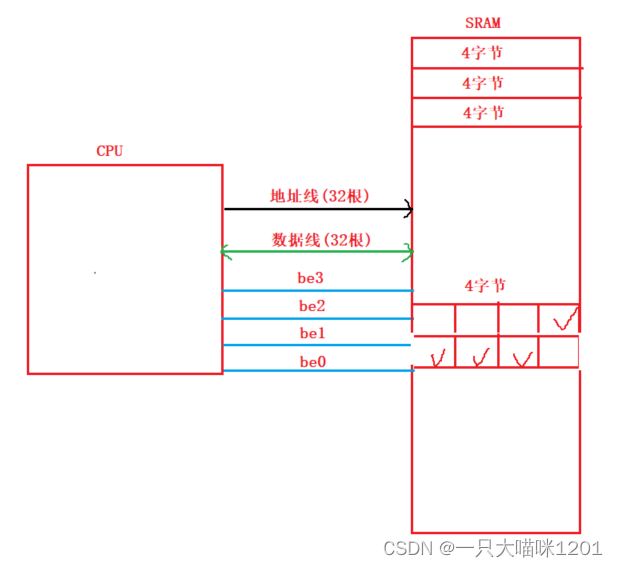
如上图,数据线和地址线都是32位的,也就是4字节,除此之外还有四根控制线be0,be1,be2,be3。无论是访问还是写入,CPU一次操作都是四个字节的内存。
当be0有效时,CPU操作4个字节中第1个字节的空间,be1有效就操作第2个字节的空间,be2有效就操作第3个字节的空间,be3有效就操作第4个字节的空间。
如果操作的是第一个4字节中的3个字节和第二个4字节的1个字节组成的四字节空间,CPU就需要操作两次,第一次操作时be1,be2,be3有效,第二次操作时be0有效,最后组合得到需要的数据。
采用结构体内存对齐方案,虽然char sex浪费了三个字节的空间,但是在操作int score的时候,可以一次性操作完毕,不需要第二次。
- 结构体对齐利用了以空间换时间的思想。
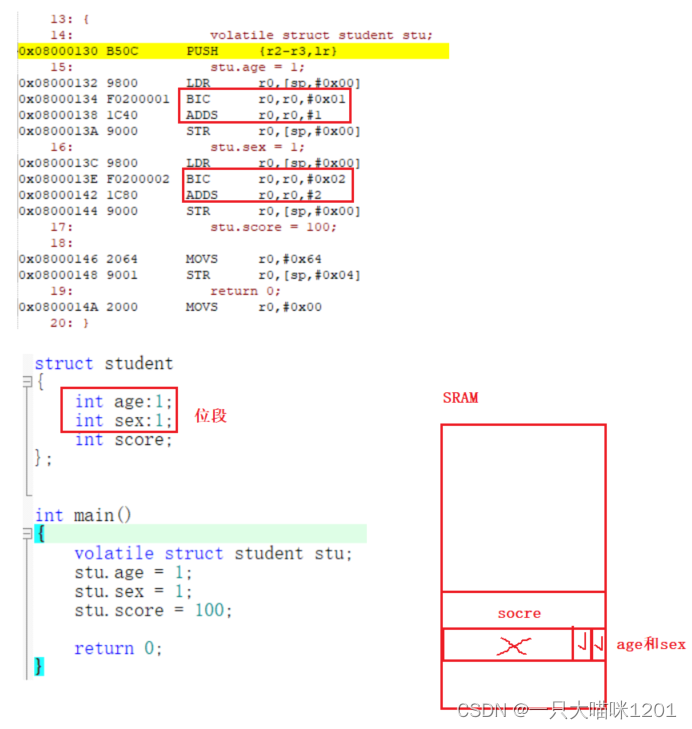
如上图,创建一个位段结构体,成员age和sex都只占用int的32个比特位中的1个比特位,成员score占4个字节32个比特位。
先执行LDR取数据,然后执行BIC r0,r0,#0x01将r0中的32个比特位的第一个比特位清0,然后再执行ADDS r0,r0,#1让第一个比特位的值成为1,此时给int age:1初始化完成。
- BIC:清除指定比特位,让该位为0。
同理,再给int sex:1初始化为1,也就是让32个比特位中的第二个比特位为1。此时还剩下30个比特位被浪费掉了,下一个int score占用完整的32个比特位,同样是为了提高效率。
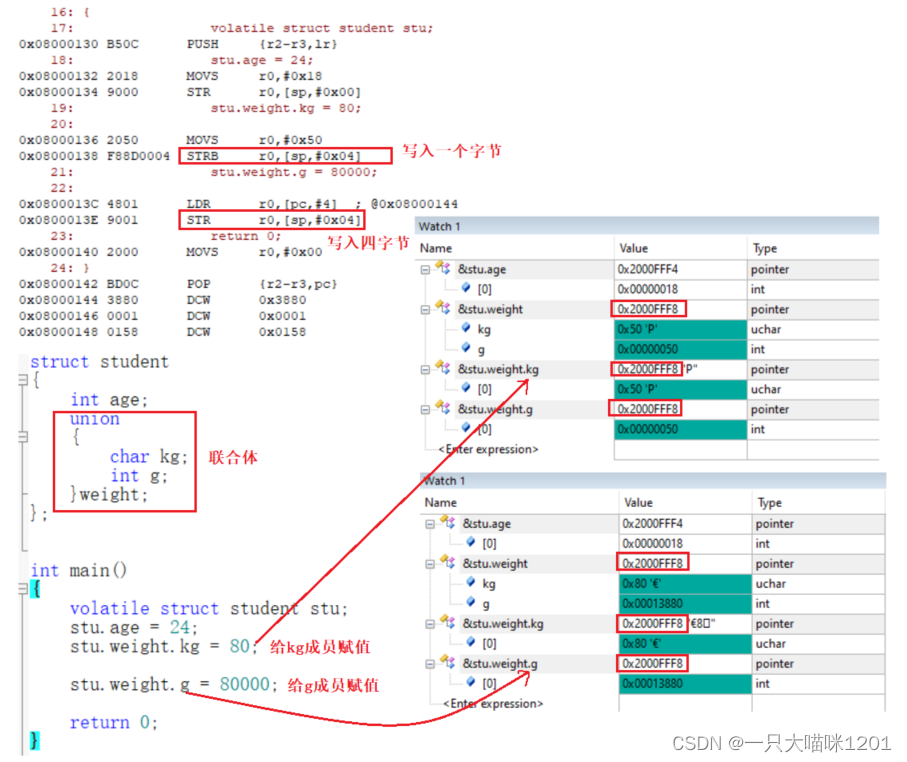
如上图,结构体中又增加了一个联合体成员union weight,char kg和int g两种类型的变量共用这一个空间。而且可以看到,weight,kg,g三者的地址都是0x2000 FFF8。
在给成员kg赋值80的时候,整个weight空间的值是0x0000 0050,在给成员g赋值的时候,整个weight空间的值是0x0001 3880。操作char类型成员,只改变4个字节中的一个字节,操作int类型成员,则4个字节全部改变。
对应的汇编代码中,操作char成员使用的是STRB,操作int成员使用的是STR。
🍞总结
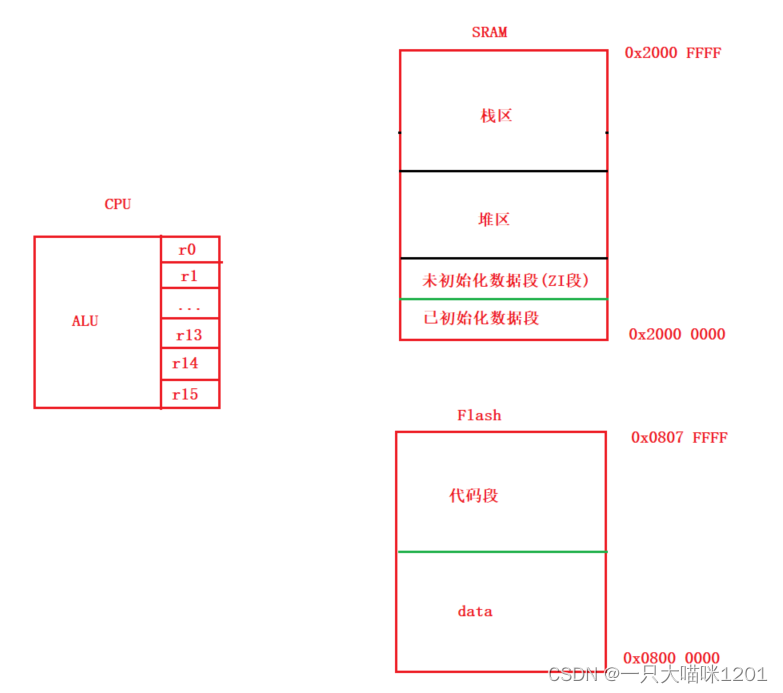
如上图便是本喵在这篇文章中讲解的ARM架构部分模型,以及常用C语言知识在ARM架构中是如何体现的。
程序在经过预处理,编译,汇编,最后再经过连接器分配地址形成.axf,.bin,或者.hex等类型的文件,这几种文件中的内容全部都是机器码。
将最终的机器码烧录到单片机中,单片机一上电就开始执行这些机器码,执行过程中是没有编译器,电脑系统的参与的,无论是变量的定义,初始化,还是内存空间的分配,你还能说是自动完成的吗?
所以说,当程序在单片机中开始运行的时候,它的一切就早被安排好了,就是按照本喵前面所讲述的去安排设计的,CPU只需要按照机器码执行即可。
- 其中地址的分配主要是由连接器完成。

![[Linux入门]---搭建Linux环境](https://img-blog.csdnimg.cn/f939d4c14a184fc0b1a615cb1fe119f4.png)