目录
1. 整数在内存中的存储
1.1 ⼆进制介绍
1.1.1 2进制转10进制
1.1.2 10进制转2进制
1.1.3 2进制转8进制
1.1.4 2进制转16进制
1.2 原码、反码、补码
2. ⼤⼩端字节序和字节序判断
2.1 什么是⼤⼩端?
2.2 为什么有⼤⼩端?
2.3 练习
2.3.1 练习1
2.3.1.1 题目
2.3.1.2 思路
2.3.1.3 方法1
2.3.1.4 方法2(函数实现)
2.3.2 练习2
2.3.2.1 题目
2.3.2.2 思路
2.3.2.3 代码验证
2.3.3 练习3
2.3.3.1 题目
2.3.3.2 思路
2.3.3.3 代码验证
2.3.4 练习4
2.3.4.1 题目
2.3.4.2 思路
2.3.4.3 代码验证
2.3.5 练习5
2.3.5.1 题目
2.3.5.2 思路
2.3.5.3 代码验证
2.3.6 练习6
2.3.6.1 题目
2.3.6.2 思路
2.3.6.3 代码验证
2.3.6.4 为什么x86环境下,结果不同?
3. 浮点数在内存中的存储
3.1 练习
3.2 浮点数的存储
3.2.1 浮点数存的过程
3.2.2 浮点数取的过程
3.3 题⽬解析
1. 整数在内存中的存储
在了解整数在内存中的存储方式之前,我们先要了解二进制。
1.1 ⼆进制介绍
其实我们经常能听到2进制、8进制、10进制、16进制这样的讲法,那是什么意思呢?其实2进制、8进制、10进制、16进制是数值的不同表⽰形式⽽已。
我们重点介绍⼀下⼆进制:
⾸先我们还是得从10进制讲起,其实10进制是我们⽣活中经常使⽤的,我们已经形成了很多尝试:
• 10进制中满10进1
• 10进制的数字每⼀位都是0~9的数字组成
其实⼆进制也是⼀样的
• 2进制中满2进1
• 2进制的数字每⼀位都是0~1的数字组成
例如 1101 就是⼆进制的数字。
1.1.1 2进制转10进制
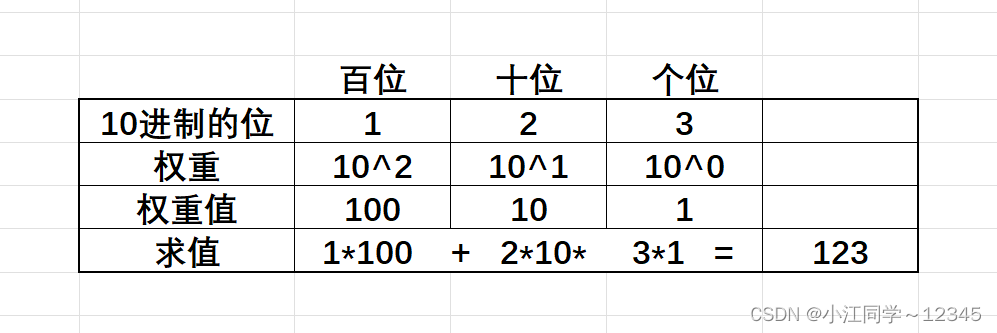
其实10进制的123表⽰的值是⼀百⼆⼗三,为什么是这个值呢?其实10进制的每⼀位是有权重的,10进制的数字从右向左是个位、⼗位、百位....,分别每⼀位的权重是 10^0 , 10^1 , 10^2 ...
如下图:
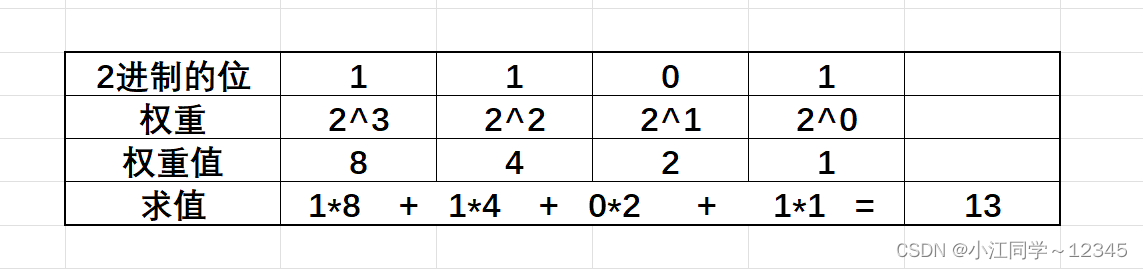
2进制和10进制是类似的,只不过2进制的每⼀位的权重,从右向左是: 2^0 , 2^1 , 2^2 ...
如果是2进制的1101,该怎么理解呢?
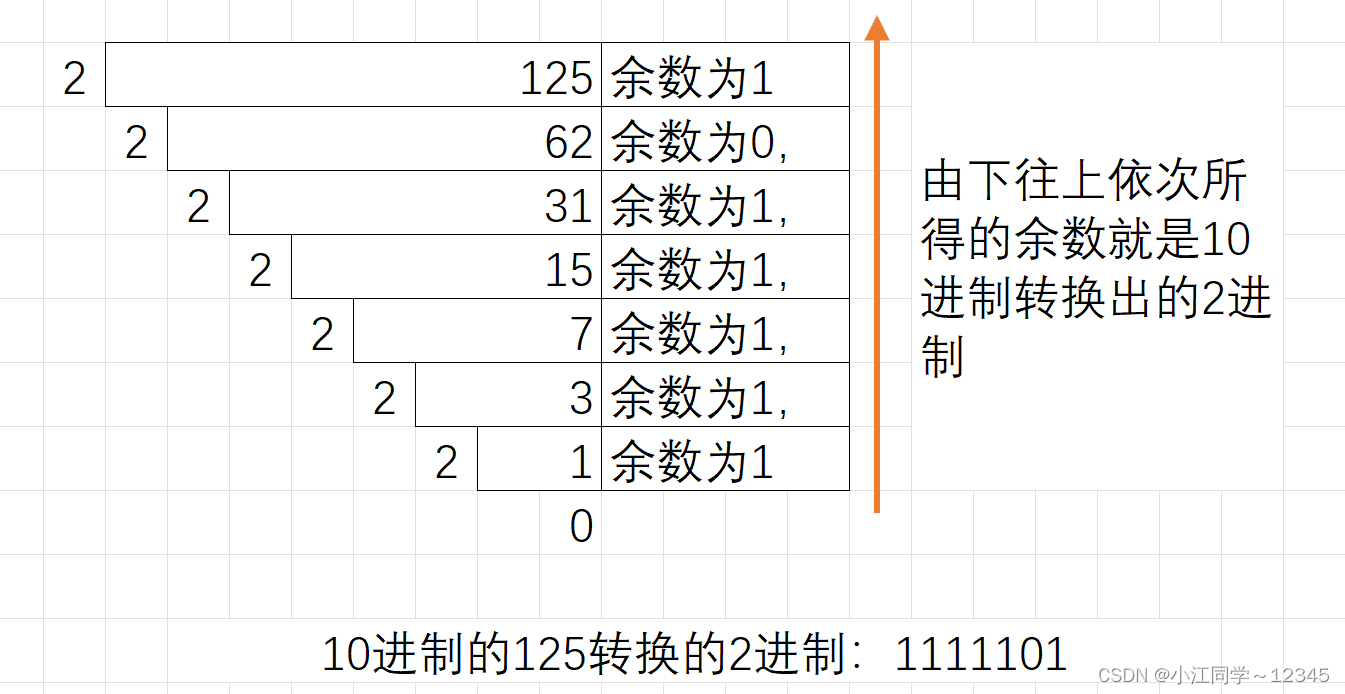
1.1.2 10进制转2进制
1.1.3 2进制转8进制
• 8进制中满8进1
• 8进制的数字每⼀位都是0~7的数字组成
•在2进制转8进制数的时候,从2进制序列中右边低位开始向左每3个2进制位会换算⼀
个8进制位,剩余不够3个2进制位的直接换算
如:2进制的01101011,换成8进制:0153,0开头的数字,会被当做8进制

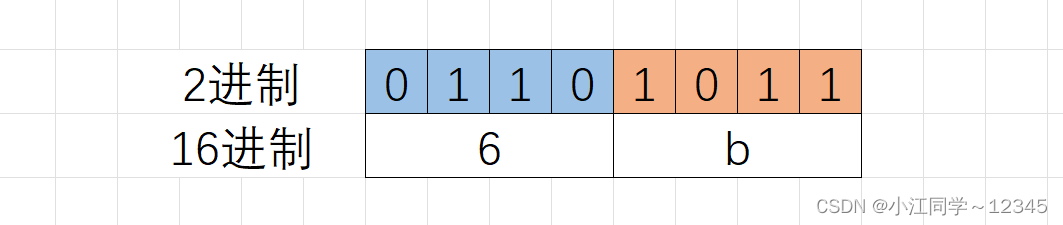
1.1.4 2进制转16进制
↵ ↵
• 16进制中满16进1
• 16进制的数字前10位都是0~9的数字组成,后6位由a~f的字母代替数字组成
• 在2进制转16进制数的时候,从2进制序列中右边低位开始向左每4个2进制位会换算⼀个16进制位,剩余不够4个⼆进制位的直接换算
如:2进制的01101011,换成16进制:0x6b,16进制表⽰的时候前⾯加0x
到这里,二进制就介绍完了
下面,我们来介绍整数的2进制表⽰⽅法
1.2 原码、反码、补码
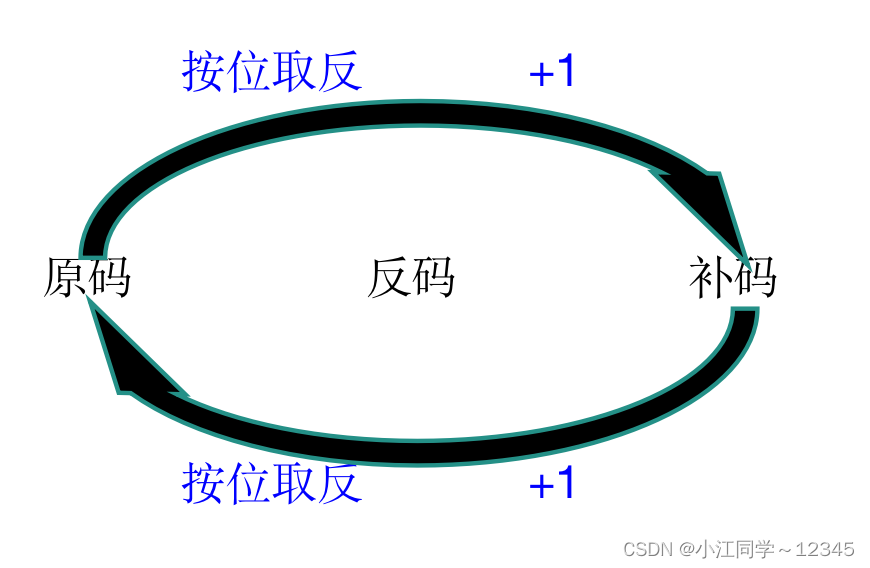
整数的2进制表⽰⽅法有三种,即原码、反码和补码
三种表⽰⽅法均有符号位和数值位两部分,符号位都是⽤0表⽰“正”,⽤1表⽰“负”,⽽数值位最⾼位的⼀位是被当做符号位,剩余的都是数值位。
正整数的原、反、补码都相同。
无符号的整数(>=0),没有符号位;32位都是数值位
负整数的三种表⽰⽅法各不相同。
原码:直接将数值按照正负数的形式翻译成⼆进制得到的就是原码。
反码:将原码的符号位不变,其他位依次按位取反就可以得到反码。
补码:反码+1就得到补码。
对于整形来说:数据存放内存中其实存放的是补码。
为什么呢?
在计算机系统中,数值⼀律⽤补码来表⽰和存储。原因在于,使⽤补码,可以将符号位和数值域统⼀处理;同时,加法和减法也可以统⼀处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
计算的时候按照补码来计算和操作,打印出来的是原码,所以需要补码先取反再+1
2. ⼤⼩端字节序和字节序判断
当我们了解了整数在内存中存储后,我们调试看⼀个细节:
#include <stdio.h>
int main()
{
int a = 0x11223344;
return 0;
}
我们发现,这个数字是按照字节为单位,倒着存储的。这是为什么呢?
2.1 什么是⼤⼩端?
我们存储数据有3种方法:
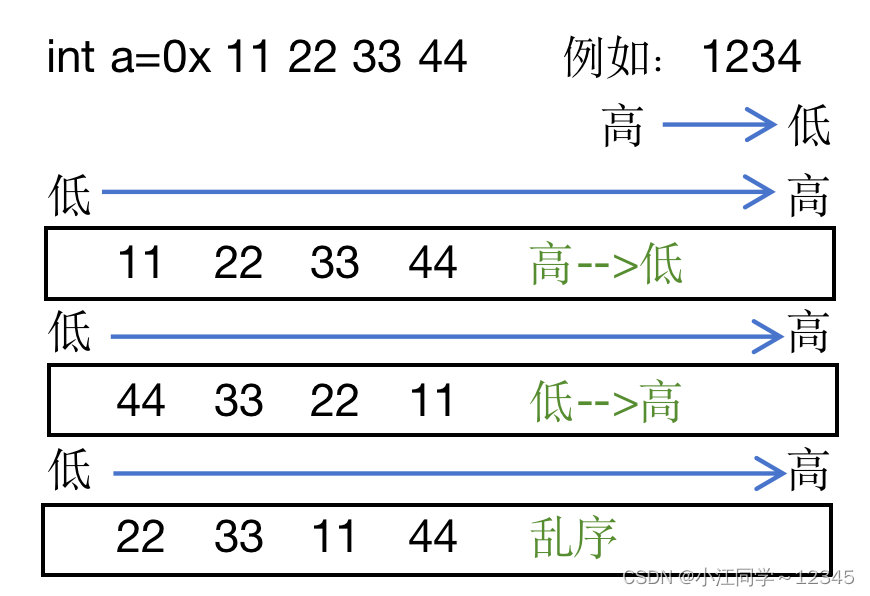
由于我们存进去的,我们就会怎么拿出来,所以乱序存储方法不合适
我们就采用前面2种。
数字是倒置存储的,数据在内存中存储的方式是二进制,但是在vs的内存窗口上展示的是16进制
其实超过⼀个字节的数据在内存中存储的时候,就有存储顺序的问题,按照不同的存储顺序,我们分为⼤端字节序存储和⼩端字节序存储,下⾯是具体的概念:
⼤端(存储)模式:是指数据的低位字节内容保存在内存的⾼地址处,⽽数据的⾼位字节内容,保存在内存的低地址处。
⼩端(存储)模式:是指数据的低位字节内容保存在内存的低地址处,⽽数据的⾼位字节内容,保存在内存的⾼地址处。
2.2 为什么有⼤⼩端?
为什么会有⼤⼩端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着⼀个字节,⼀个字节为8 bit 位,但是在C语⾔中除了8 bit 的 char 之外,还有16 bit 的short 型,32 bit 的 long 型(要看具体的编译器),另外,对于位数⼤于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度⼤于⼀个字节,那么必然存在着⼀个如何将多个字节安排的问题。因此就导致了⼤端存储模式和⼩端存储模式。
例如:⼀个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那0x11 为⾼字节, 0x22 为低字节。对于⼤端模式,就将 0x11 放在低地址中,即 0x0010 中0x22 放在⾼地址中,即 0x0011 中。⼩端模式,刚好相反。我们常⽤的 X86 结构是⼩端模式⽽KEIL C51 则为⼤端模式。很多的ARM,DSP都为⼩端模式。有些ARM处理器还可以由硬件来选择是⼤端模式还是⼩端模式。
2.3 练习
2.3.1 练习1
2.3.1.1 题目
请简述⼤端字节序和⼩端字节序的概念,设计⼀个⼩程序来判断当前机器的字节序。
2.3.1.2 思路
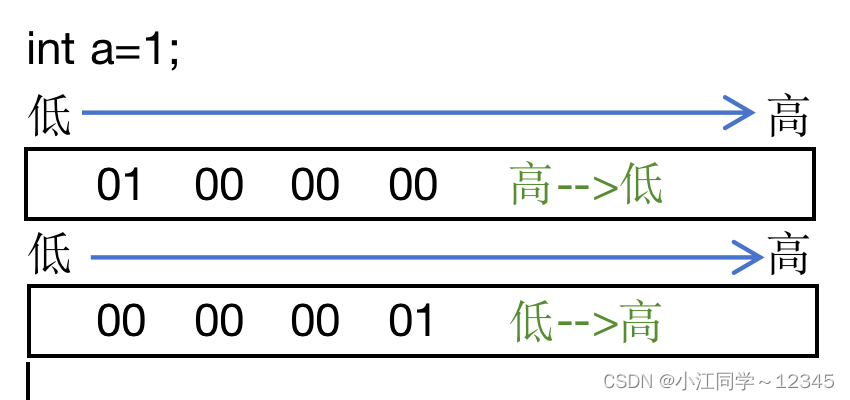
我们以1举例,判断编译器的存储方式(博主的是VS2020),我们只需要知道第一个字节是不是0就可以判断使大端还是小段了。
2.3.1.3 方法1
#include <stdio.h>
int main()
{
int a = 1;
if ((*(char*)&a) == 1)
{
printf("小端\n");
}
else
printf("大端\n");
return 0;
}
2.3.1.4 方法2(函数实现)
#include<stdio.h>
int check_sys()
{
int a = 1;
return (*(char*)&a);
}
int main()
{
int a = 1;
if (check_sys() == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
2.3.2 练习2
2.3.2.1 题目
#include <stdio.h>
int main()
{
char a= -1;
signed char b=-1;
unsigned char c=-1;
printf("a=%d,b=%d,c=%d",a,b,c);
return 0;
}
输出结果是什么?
2.3.2.2 思路
#include <stdio.h>
int main()
{
char a= -1;//char类型8个比特位
//10000000 00000000 00000000 00000001---原码
//11111111 11111111 11111111 11111110---反码
//11111111 11111111 11111111 11111111---补码
//截断--->11111111---a
//整型提升---以符号位为依据进行提升,无符号数,高位补0
//11111111 11111111 11111111 11111111---补码
//10000000 00000000 00000000 00000000---反码
//10000000 00000000 00000000 00000001---原码
//-1---a
signed char b=-1;//有符号整型
//10000000 00000000 00000000 00000001---原码
//11111111 11111111 11111111 11111110---反码
//11111111 11111111 11111111 11111111---补码
//截断--->11111111---b
//11111111 11111111 11111111 11111111---补码
//10000000 00000000 00000000 00000000---反码
//10000000 00000000 00000000 00000001---原码
//-1---b
unsigned char c=-1;
//10000000 00000000 00000000 00000001---原码
//11111111 11111111 11111111 11111110---反码
//11111111 11111111 11111111 11111111---补码
//截断--->11111111---c
//00000000 00000000 00000000 11111111---补码/反码/原码(>0)
//255---c
printf("a=%d,b=%d,c=%d",a,b,c);//%d--打印10进制的有符号整型
return 0;
}2.3.2.3 代码验证

2.3.3 练习3
2.3.3.1 题目
#include <stdio.h>
int main()
{
char a = -128;
printf("%u\n",a);
return 0;
}
#include <stdio.h>
int main()
{
char a = 128;
printf("%u\n",a);
return 0;
}输出分别是什么?
2.3.3.2 思路
#include <stdio.h>
int main()
{
char a = -128;//有符号的char类型,高位是符号位
//10000000 00000000 00000000 10000000---原码
//11111111 11111111 11111111 01111111---反码
//11111111 11111111 11111111 10000000---补码
//截断--->10000000---a
//整型提升
//11111111 11111111 11111111 10000000---原码/反码/补码
//打印无符号整型---> >=0
printf("%u\n",a);//%u打印无符号整型
return 0;
}#include <stdio.h>
int main()
{
char a = 128;//有符号的char类型,高位是符号位
//00000000 00000000 00000000 10000000---原码
//01111111 11111111 11111111 01111111---反码
//01111111 11111111 11111111 10000000---补码
//截断--->10000000---a
//整型提升
//11111111 11111111 11111111 10000000---原码/反码/补码
//打印无符号整型---> >=0
printf("%u\n",a);
return 0;
}2.3.3.3 代码验证

2.3.4 练习4
2.3.4.1 题目
#include <stdio.h>
int main()
{
char a[1000];
int i;
for(i=0; i<1000; i++)
{
a[i] = -1-i;
}
printf("%d",strlen(a));
return 0;
}输出结果是什么?
2.3.4.2 思路
求字符串长度,统计的是\0之前出现的字符个数,\0的ASCLL码值是0,所以只要找到0就好
我们来看看char类型的取值范围:

#include <stdio.h>
int main()
{
char a[1000];
int i;
for(i=0; i<1000; i++)
{
a[i] = -1-i;
//-1,-2,-3......-128,127,126......0
//反着转圈
}
printf("%d",strlen(a));//255
return 0;
}2.3.4.3 代码验证

2.3.5 练习5
2.3.5.1 题目
#include <stdio.h>
unsigned char i = 0;
int main()
{
for(i = 0;i<=255;i++)
{
printf("hello world\n");
}
return 0;
}
#include <stdio.h>
int main()
{
unsigned int i;
for(i = 9; i >= 0;i++)
{
printf("%u\n",i);
}
return 0;
}2.3.5.2 思路

#include <stdio.h>
unsigned char i = 0;//无符号char:0~255
int main()
{
for(i = 0;i<=255;i++)
{
printf("hello world\n");//死循环
}
return 0;
}
#include <stdio.h>
int main()
{
unsigned int I;//无符号char:0~255;>=0恒成立
for(i = 9; i >= 0;i++)
{
printf("%u\n",i);
}
return 0;
}2.3.5.3 代码验证
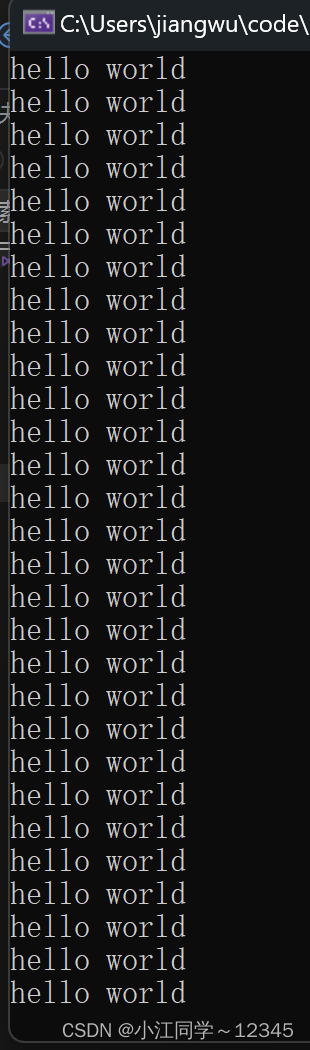
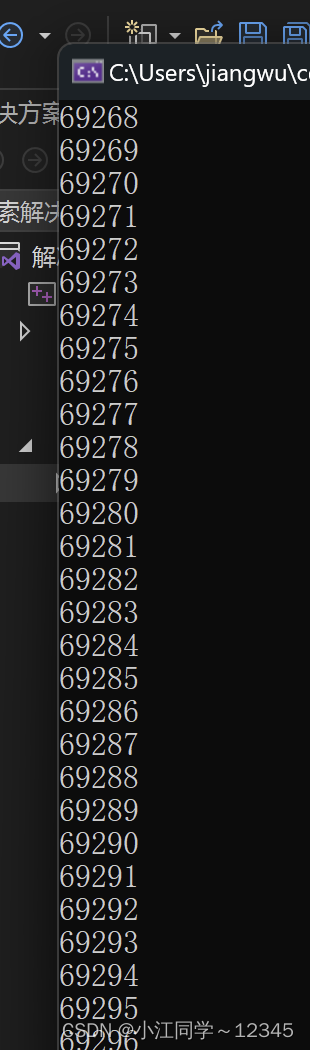
2.3.6 练习6
2.3.6.1 题目
#include <stdio.h>
int main()
{
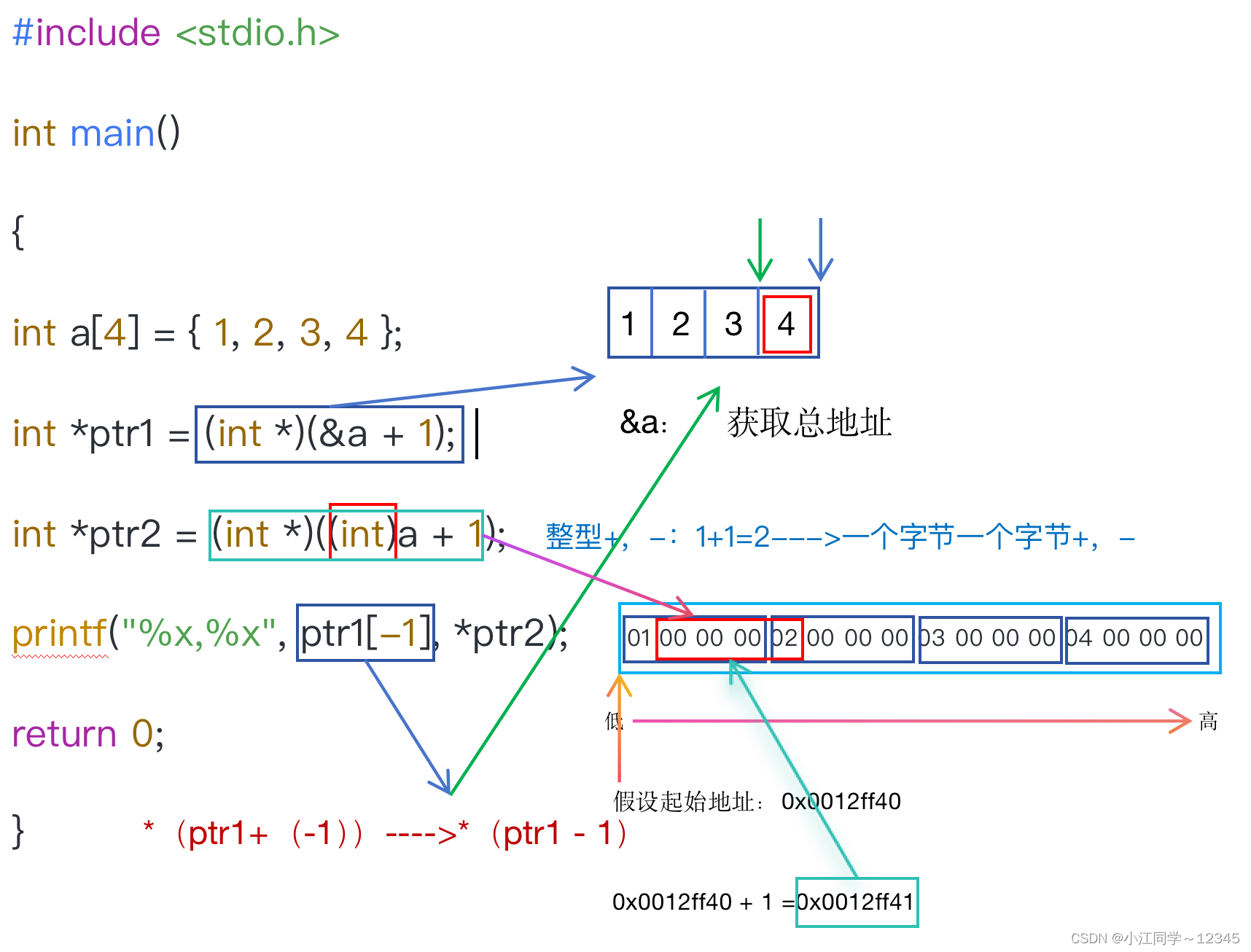
int a[4] = { 1, 2, 3, 4 };
int *ptr1 = (int *)(&a + 1);
int *ptr2 = (int *)((int)a + 1);
printf("%x,%x", ptr1[-1], *ptr2);
return 0;
}
输出结果是什么?
2.3.6.2 思路
2.3.6.3 代码验证
![]() 添加#,打印16进制
添加#,打印16进制 ![]()
2.3.6.4 为什么x86环境下,结果不同?


3. 浮点数在内存中的存储
常⻅的浮点数:3.14159、1E10等,浮点数家族包括: float、double、long double 类型。

3.1 练习
浮点型和整型数据在内存中的存储形式和取出方式都不同
我们可以通过练习来看看:
#include <stdio.h>
int main()
{
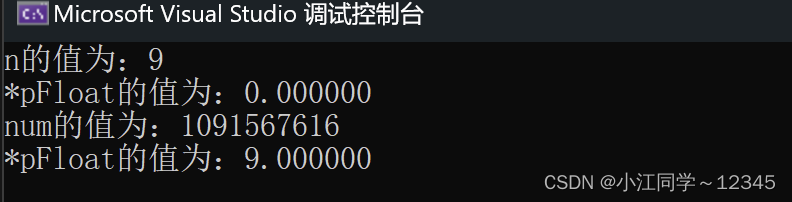
int n = 9;
float *pFloat = (float *)&n;
printf("n的值为:%d\n",n);
printf("*pFloat的值为:%f\n",*pFloat);
*pFloat = 9.0;
printf("num的值为:%d\n",n);
printf("*pFloat的值为:%f\n",*pFloat);
return 0;
}
3.2 浮点数的存储
上⾯的代码中, num 和 *pFloat 在内存中明明是同⼀个数,为什么浮点数和整数的解读结果会差别这么⼤?
根据国际标准IEEE(电⽓和电⼦⼯程协会) 754,任意⼀个⼆进制浮点数V可以表⽰成下⾯的形式:
V = (−1) ^S ∗ M ∗ 2^E
• (−1)S 表⽰符号位,当S=0,V为正数;当S=1,V为负数
• M 表⽰有效数字,M是⼤于等于1,⼩于2的
• 2^E 表⽰指数位

IEEE 754规定:
对于32位的浮点数,最⾼的1位存储符号位S,接着的8位存储指数E,剩下的23位存储有效数字M
对于64位的浮点数,最⾼的1位存储符号位S,接着的11位存储指数E,剩下的52位存储有效数字M

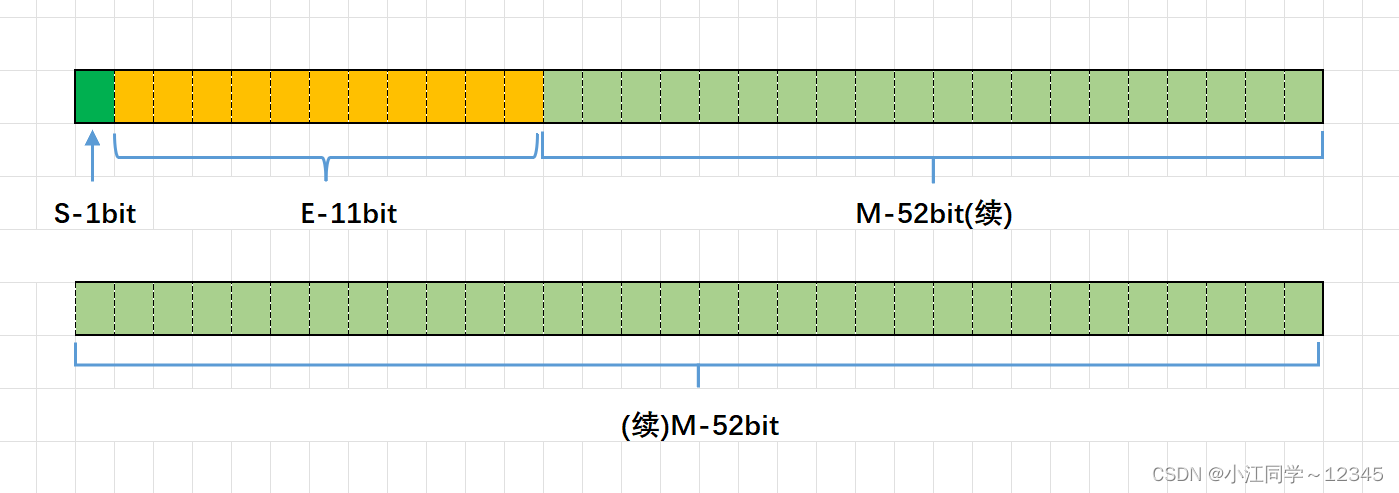
3.2.1 浮点数存的过程
前⾯说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中xxxxxx表⽰⼩数部分。在计算机内部保存M时,默认这个数的第⼀位总是1,因此可以被舍去,只保存后⾯的xxxxxx部分。
E为⼀个⽆符号整数(unsigned int)
这意味着,如果E为8位,它的取值范围为0~255;如果E为11位,它的取值范围0~2047。
科学计数法中的E是可以出现负数的,所以IEEE 754规定,存⼊内存时E的真实值必须再加上⼀个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。

3.2.2 浮点数取的过程
指数E从内存中取出还可以再分成三种情况:
E不全为0或不全为1
这时,浮点数就采⽤下⾯的规则表⽰,即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第⼀位的1。
E全为0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值(E+127(1023)之后为0),有效数字M不再加上第⼀位的1,⽽是还原为0.xxxxxx的⼩数。这样做是为了表⽰±0,以及接近于0的很⼩的数字。
E全为1
这时,如果有效数字M全为0,表⽰±⽆穷⼤(正负取决于符号位s)
3.3 题⽬解析
#include <stdio.h>
int main()
{
int n = 9;//整型存储方式,补码
//00000000 00000000 00000000 00001001---原码/反码/补码
float *pFloat = (float *)&n;
printf("n的值为:%d\n",n);//9
printf("*pFloat的值为:%f\n",*pFloat);
//0 00000000 00000000000000000001001
//E为全0
//(-1)^0 * 0.000000000000000001001 * 2^ -126
//接近0
//%f只打印前6位
//0.000000
*pFloat = 9.0;
//1001.0
//(-1)^0 * 1.001 * 2^ 3
//S=0
//M=1.001
//E=3---->3+127=130
//01000001000100000000000000000000
printf("num的值为:%d\n",n);
printf("*pFloat的值为:%f\n",*pFloat);//9.0
return 0;
}本次的分享到这里就结束了!!!
PS:小江目前只是个新手小白。欢迎大家在评论区讨论哦!有问题也可以讨论的!
如果对你有帮助的话,记得点赞👍+收藏⭐️+关注➕

![[管理与领导-93]:IT基层管理者 - 扩展技能 - 5 - 职场丛林法则 -7- 复杂问题分析能力与复杂问题的解决能力:系统化思维](https://img-blog.csdnimg.cn/78ef0dd73c2d44768520b063eb8fd142.png)