1.数据来源官网:Data for: Root cause analysis improved with machine learning for failure analysis in power transformers - Mendeley Data
点Download All 10kb即可下载数据
2.下载下来后是这样

每一列的介绍:
Hydrogen 氢气;
Oxygen 氧气;
Nitrogen 氮气
Methane 甲烷
Carbon Monoxide (CO) 一氧化碳 (CO)
Carbon Dioxide (CO2) 二氧化碳 (CO2)
Ethylene 乙烯
Ethane 乙烷
Acetylene 乙炔
Dissolved Gas Ratio (DBDS) 溶解气体比率
(DBDS) Power Factor 功率因数
Interfacial Voltage (Interfacial V) 界面电压
(Interfacial V) Dielectric Rigidity 介电刚度
Water Content 水分含量
Health Index 健康指数
Life Expectation 寿命预期
3.本次项目的代码流程
-
导入所需的库和模块,包括NumPy、Pandas、Matplotlib、Seaborn等。
-
读取数据:从名为"Health index.csv"的CSV文件中读取数据,并对数据进行基本的信息查看和描述统计分析。
-
定义了一个名为
check的函数,用于检查数据中的缺失值情况,并展示了缺失值的统计信息。 -
使用数据可视化工具绘制了箱线图,以检查数据中的异常值。
-
根据某些特定条件,找到了数据中一些异常值所在的行。
-
绘制了特征之间的相关性热力图,以查看特征之间的线性关系。
-
绘制了数据集中各个特征的直方图,用于查看其分布情况。
-
使用
StandardScaler对数据进行标准化,使特征具有相似的尺度。 -
对特定特征进行散点图的绘制,以查看它们与目标变量的关系。
-
进行线性回归模型的训练和评估,包括训练集和测试集的划分、模型拟合、预测和性能指标的计算。
-
绘制了实际健康指数与预测健康指数的散点图,以可视化模型的性能。
-
定义了一个名为
Model_Input的字典,包含了特定输入值。 -
创建一个包含新输入数据的DataFrame,并将其与原数据合并。
-
使用训练好的线性回归模型对新输入数据进行健康指数的预测。
-
绘制了实际健康指数与预测健康指数的散点图,以展示模型对新输入数据的预测。
代码的主要过程是加载、探索和分析数据,然后使用线性回归模型对健康指数进行预测,并展示结果的可视化。
4.效果视频
变压器寿命预测(python代码,逻辑回归模型预测效果一般,可以做对比实验)_哔哩哔哩_bilibili
测试集预测效果图
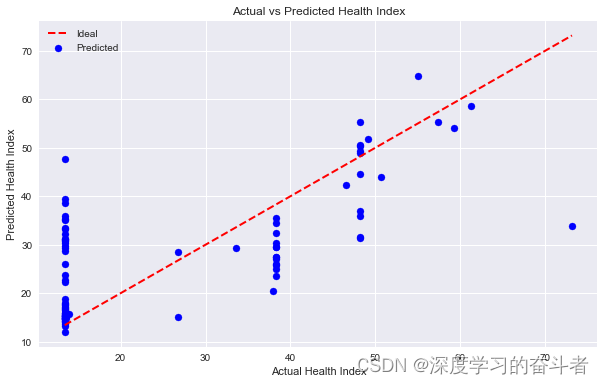
测试集

5.对代码感兴趣的可以关注最后一行
import numpy as np # 导入NumPy库,用于处理数值计算
import pandas as pd # 导入Pandas库,用于数据处理和CSV文件的输入/输出操作
import os # 导入操作系统模块,用于文件路径操作
import pandas as pd # 导入Pandas库
# import pandas_profiling
import numpy as np # 导入NumPy库
import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
import warnings # 导入警告模块,用于警告管理
warnings.simplefilter(action='ignore') # 忽略警告信息
plt.style.use('seaborn') # 设置绘图风格为Seaborn
import seaborn as sns # 导入Seaborn库,用于数据可视化
from sklearn.linear_model import LogisticRegression, LinearRegression # 导入Scikit-Learn中的线性和逻辑回归模型
from sklearn.preprocessing import StandardScaler # 导入数据标准化模块
from sklearn import preprocessing # 导入预处理模块
from sklearn.model_selection import train_test_split # 导入数据集划分模块
from sklearn.linear_model import LinearRegression # 导入线性回归模型
from sklearn import metrics # 导入评价指标模块
from sklearn.model_selection import KFold # 导入K折交叉验证模块
from sklearn.model_selection import cross_val_score # 导入交叉验证模块
#数据集和代码压缩包:https://mbd.pub/o/bread/ZJ6Wkplp