文章目录
- 一、Residual Block
- 二、Bottleneck Residual Block
- 三、Dense Block
- 四、Squeeze-and-Excitation Block
- 五、Inception Module
- 六、Non-Local Block
- 七、Spatial Attention Module
- 八、Spatial Transformer
- 九、ResNeXt Block
- 十、Fire Module
- 十一、Inception-v3 Module
- 十二、PnP
- 十三、Channel Attention Module
- 十四、Wide Residual Block
- 十五、Axial Attention
图像模型块是用于图像模型(例如卷积神经网络)的构建块。 您可以在下面找到不断更新的图像模型块列表。
一、Residual Block
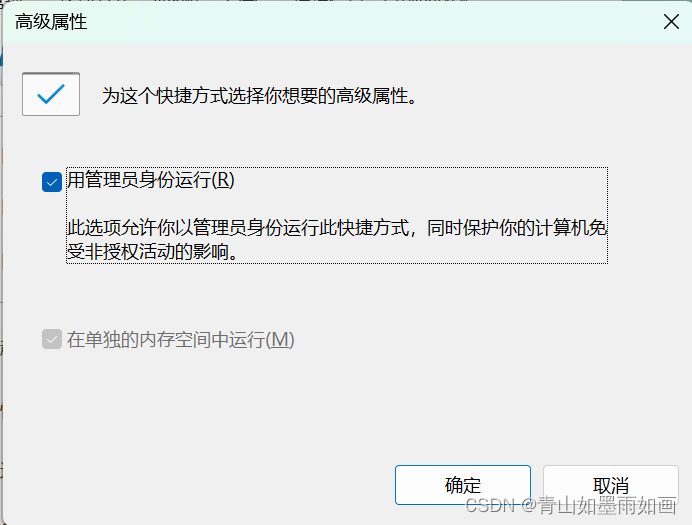
残差块是跳过连接块,它参考层输入学习残差函数,而不是学习未引用的函数。 它们是作为 ResNet 架构的一部分引入的。

直觉是,优化残差映射比优化原始的、未引用的映射更容易。 在极端情况下,如果恒等映射是最优的,则将残差推至零比通过一堆非线性层拟合恒等映射更容易。 跳过连接可以让网络更轻松地学习类似身份的映射。
请注意,在实践中,瓶颈残差块用于更深的 ResNet,例如 ResNet-50 和 ResNet-101,因为这些瓶颈块的计算强度较低。
二、Bottleneck Residual Block
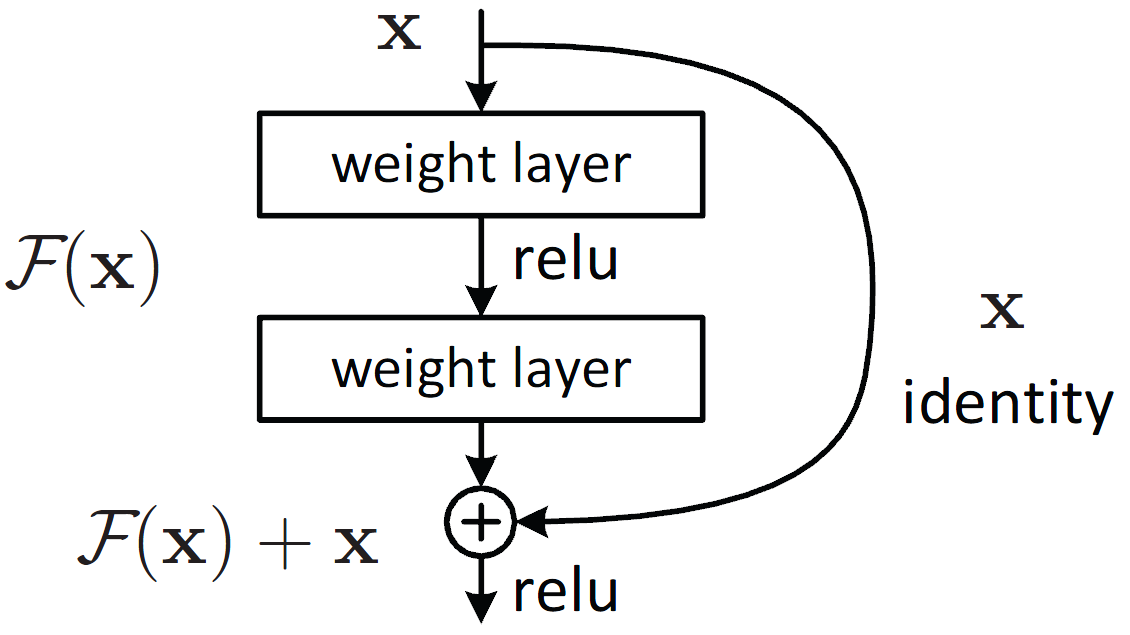
瓶颈残差块是残差块的一种变体,它利用 1x1 卷积来创建瓶颈。 瓶颈的使用减少了参数和矩阵乘法的数量。 这个想法是使残差块尽可能薄以增加深度并具有更少的参数。 它们是作为 ResNet 架构的一部分引入的,并用作更深层次 ResNet(例如 ResNet-50 和 ResNet-101)的一部分。
三、Dense Block
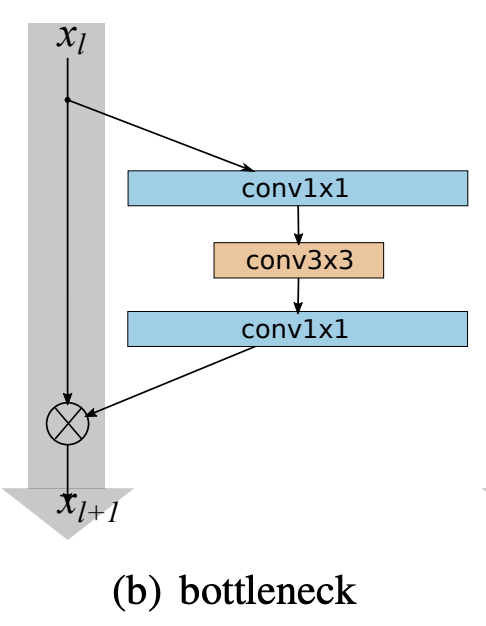
密集块是卷积神经网络中使用的模块,它将所有层(具有匹配的特征图大小)直接相互连接。 它最初被提议作为 DenseNet 架构的一部分。 为了保持前馈性质,每个层从所有前面的层获取额外的输入,并将其自己的特征图传递到所有后续层。 与 ResNet 相比,我们在将特征传递到层之前从不通过求和来组合特征; 相反,我们通过连接特征来组合它们。

四、Squeeze-and-Excitation Block
挤压和激励模块是一个架构单元,旨在通过使其能够执行动态通道特征重新校准来提高网络的表示能力。 其过程是:
该块有一个卷积块作为输入。
使用平均池将每个通道“压缩”为单个数值。
ReLU 后面的密集层增加了非线性,并且输出通道复杂性按比例降低。
另一个密集层后面跟着一个 sigmoid 函数,为每个通道提供平滑的门控函数。
最后,我们基于侧网络对卷积块的每个特征图进行加权; “兴奋”。

五、Inception Module
Inception 模块是一个图像模型块,旨在近似 CNN 中的最佳局部稀疏结构。 简而言之,它允许我们在单个图像块中使用多种类型的滤波器大小,而不是仅限于单个滤波器大小,然后将其连接并传递到下一层。
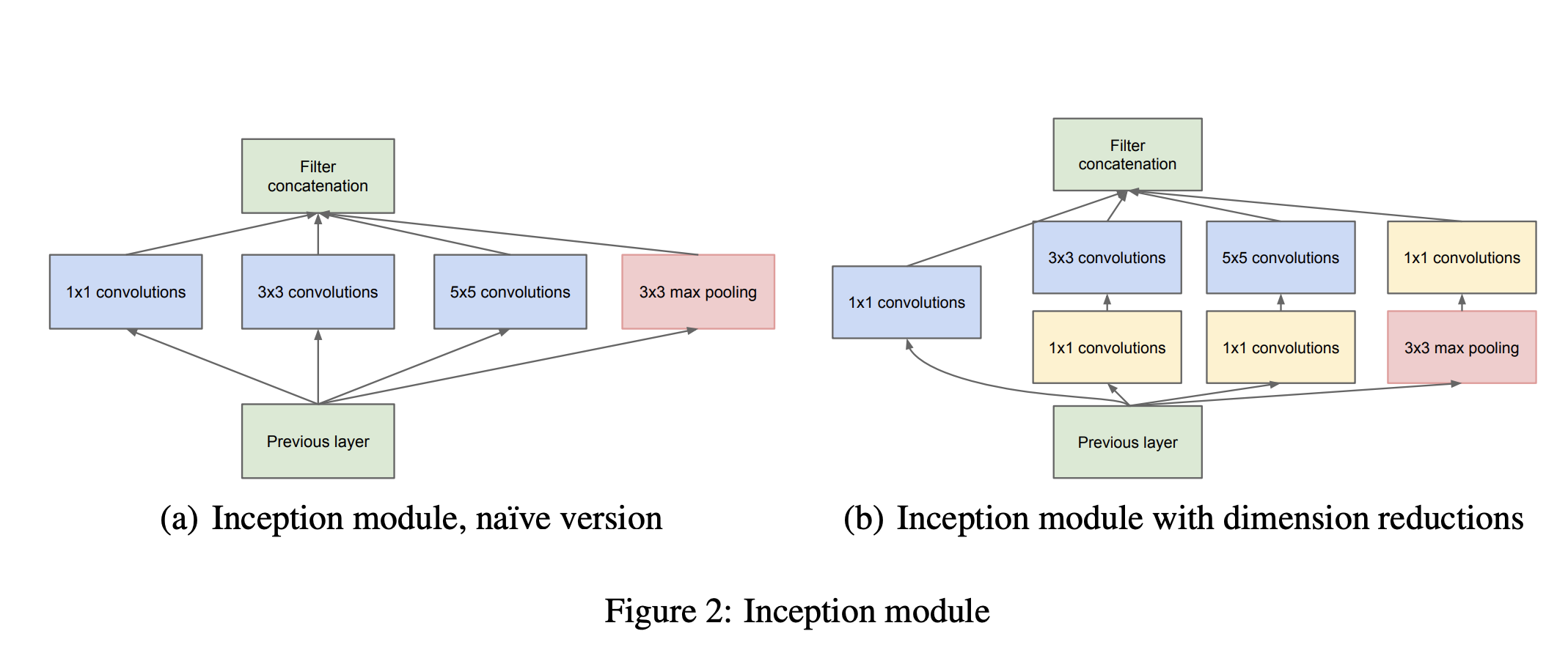
六、Non-Local Block
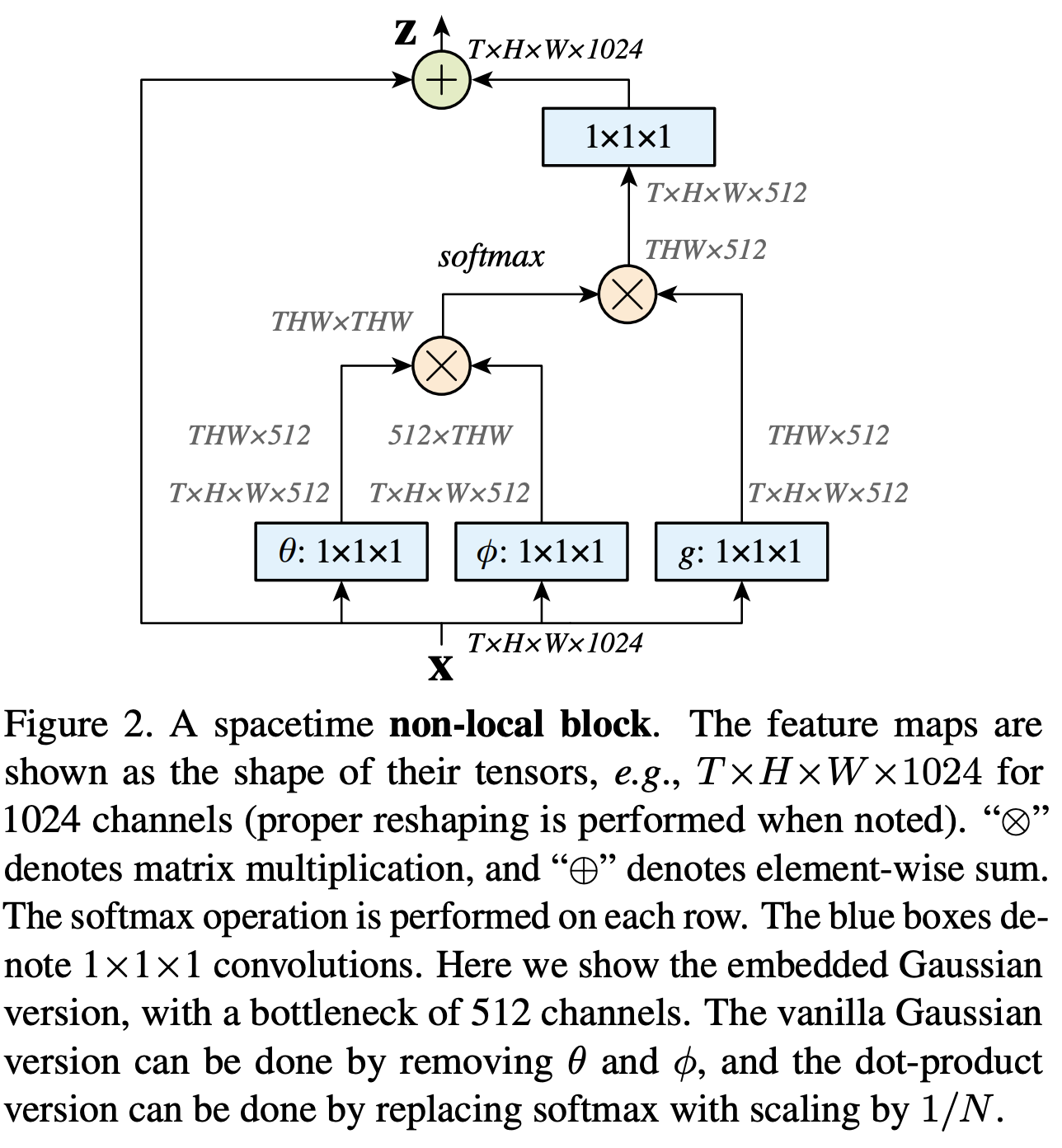
非局部块是神经网络中使用的图像块模块,它包装了非局部操作。 我们可以将非本地块定义为:

七、Spatial Attention Module
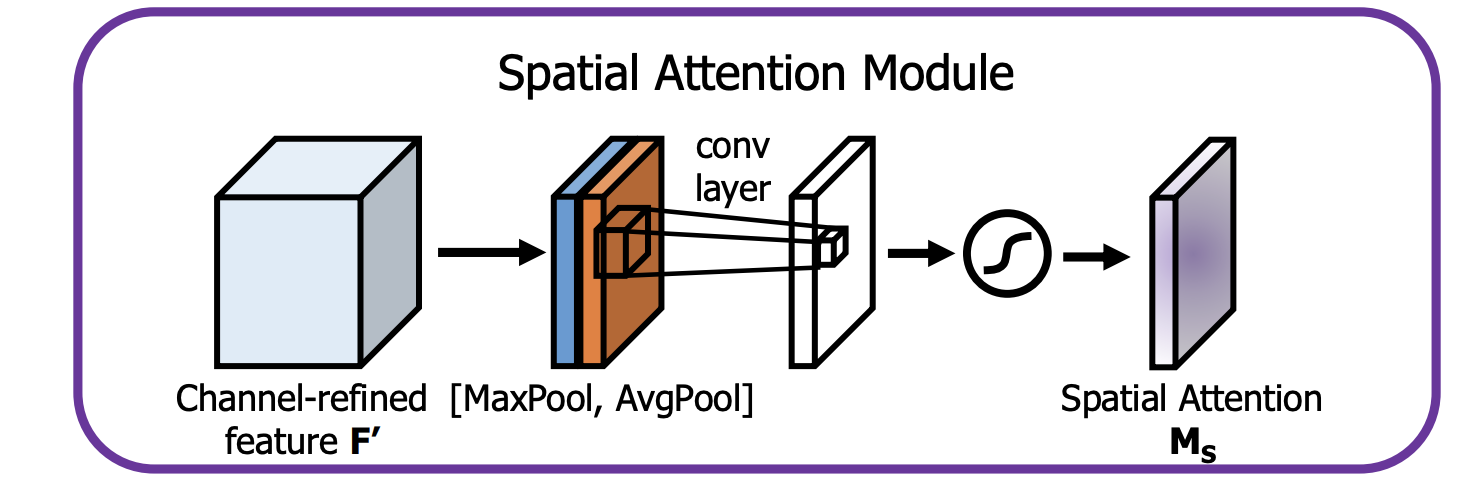
空间注意力模块是卷积神经网络中用于空间注意力的模块。 它利用特征的空间关系生成空间注意力图。 与通道注意力不同,空间注意力关注哪里是信息丰富的部分,这与通道注意力是互补的。 为了计算空间注意力,我们首先沿着通道轴应用平均池化和最大池化操作并将它们连接起来以生成有效的特征描述符。

八、Spatial Transformer
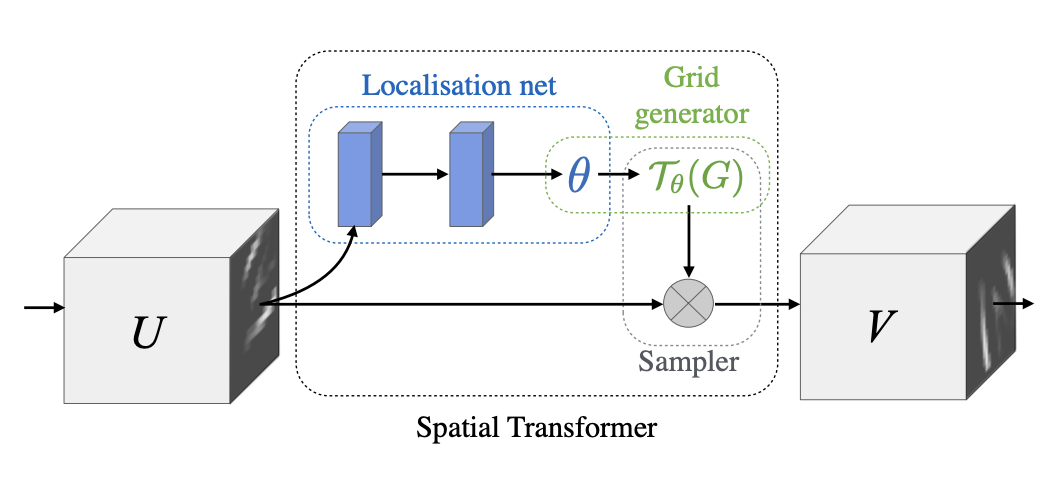
空间变换器是一个图像模型块,它明确允许在卷积神经网络中对数据进行空间操作。 它使 CNN 能够根据特征图本身主动进行空间变换,无需任何额外的训练监督或对优化过程进行修改。 与感受野是固定且局部的池化层不同,空间变换器模块是一种动态机制,可以通过为每个输入样本生成适当的变换来主动对图像(或特征图)进行空间变换。 然后在整个特征图上(非局部)执行变换,并且可以包括缩放、裁剪、旋转以及非刚性变形。

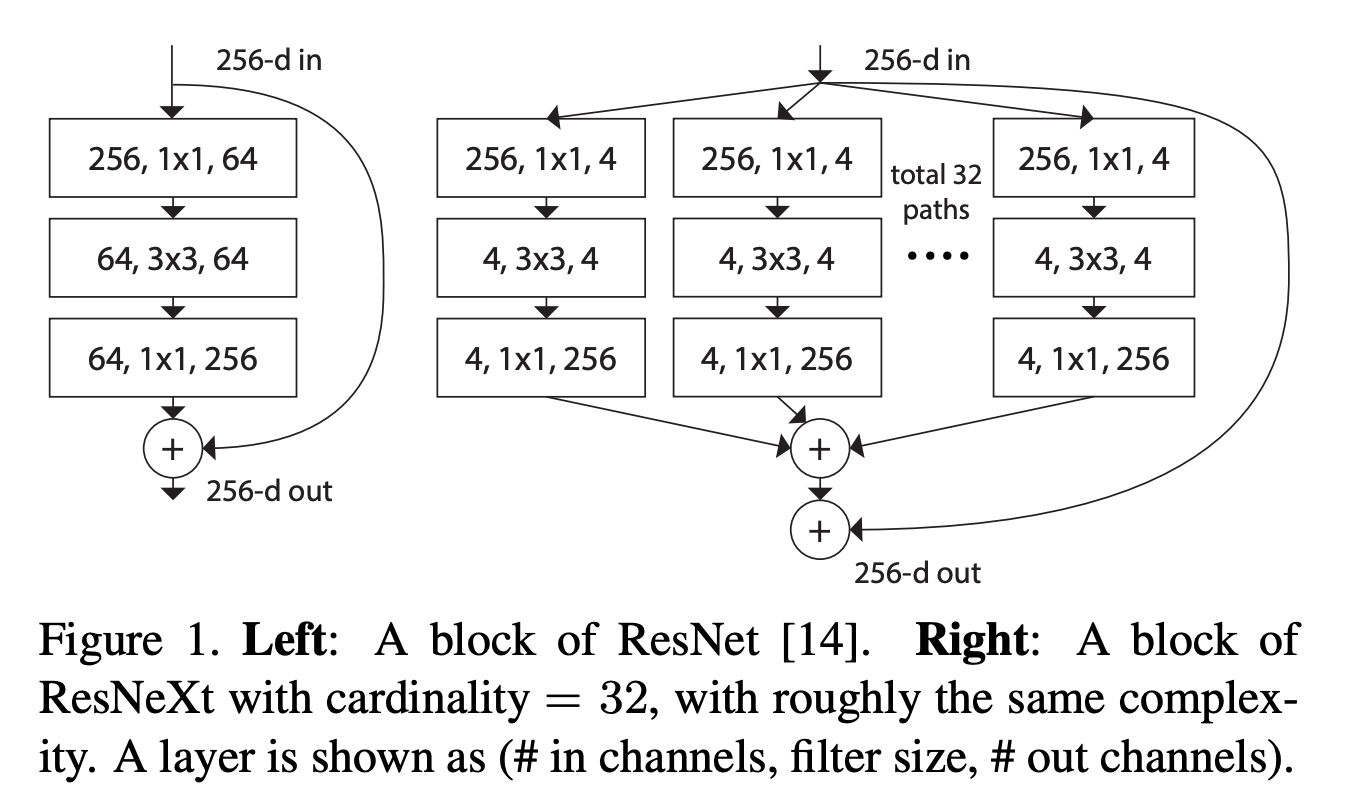
九、ResNeXt Block
ResNeXt 块是一种残差块,用作 ResNeXt CNN 架构的一部分。 它使用类似于 Inception 模块的“拆分-转换-合并”策略(单个模块内的分支路径),即它聚合了一组转换。 与残差块相比,它暴露了一个新的维度,基数(转换集的大小)C,作为深度和宽度之外的一个重要因素。

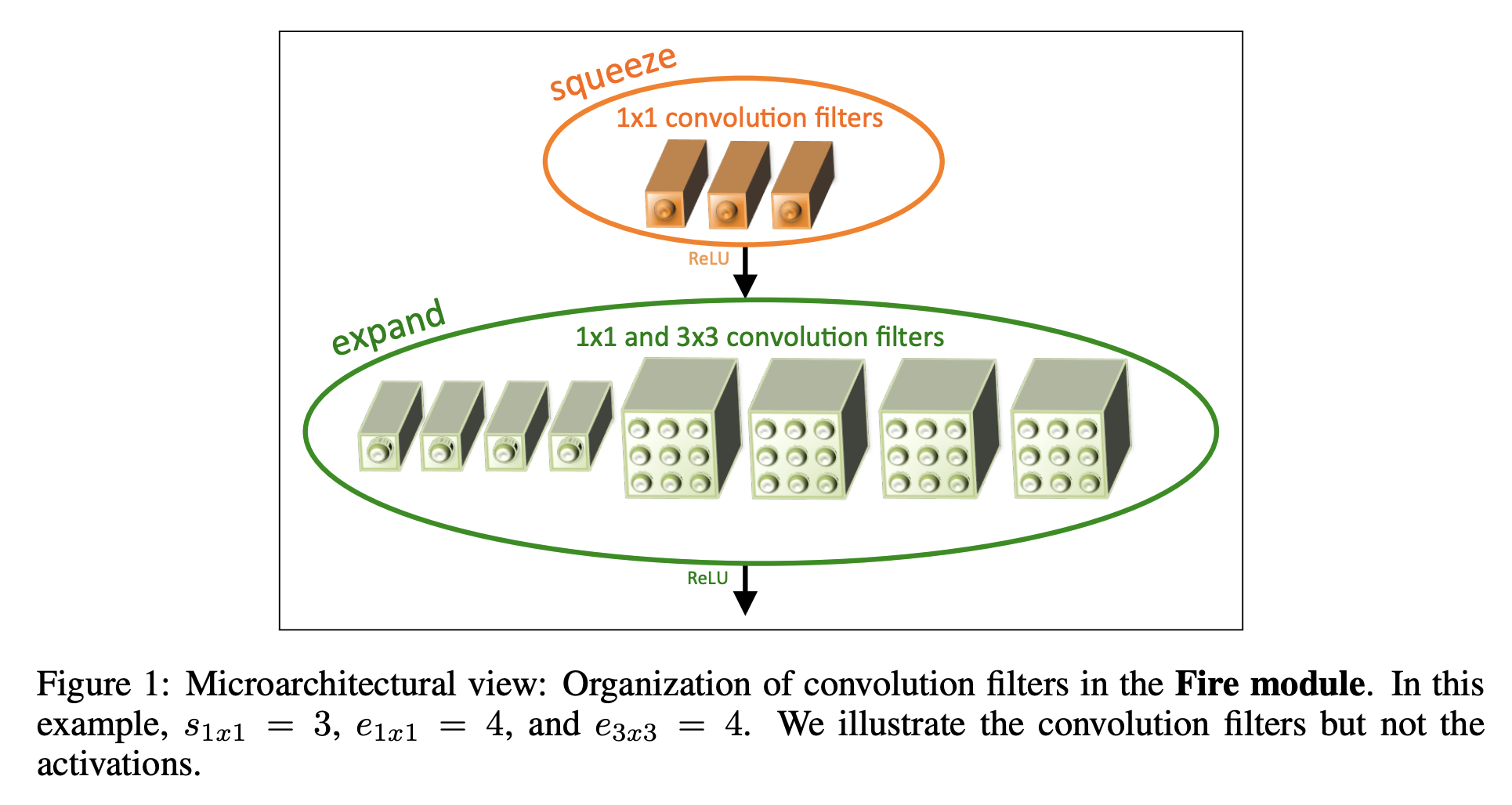
十、Fire Module
Fire 模块是卷积神经网络的构建块,特别是用作 SqueezeNet 的一部分。 Fire 模块由以下部分组成:挤压卷积层(仅具有 1x1 滤波器),输入混合有 1x1 和 3x3 卷积滤波器的扩展层。 我们在 Fire 模块中公开了三个可调维度(超参数):

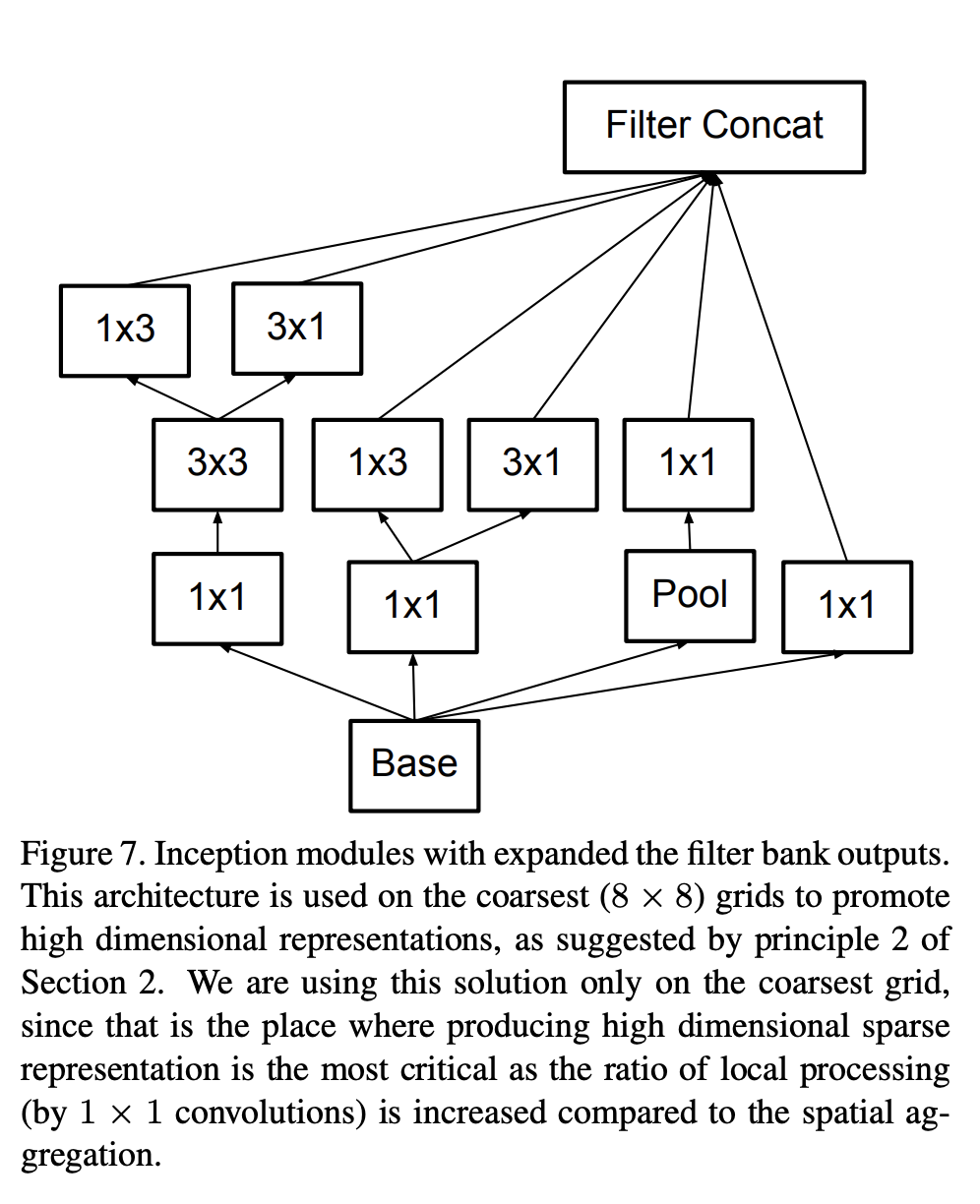
十一、Inception-v3 Module
Inception-v3 Module是Inception-v3架构中使用的图像块。 该架构用于最粗糙的 (8 × 8) 网格,以促进高维表示。
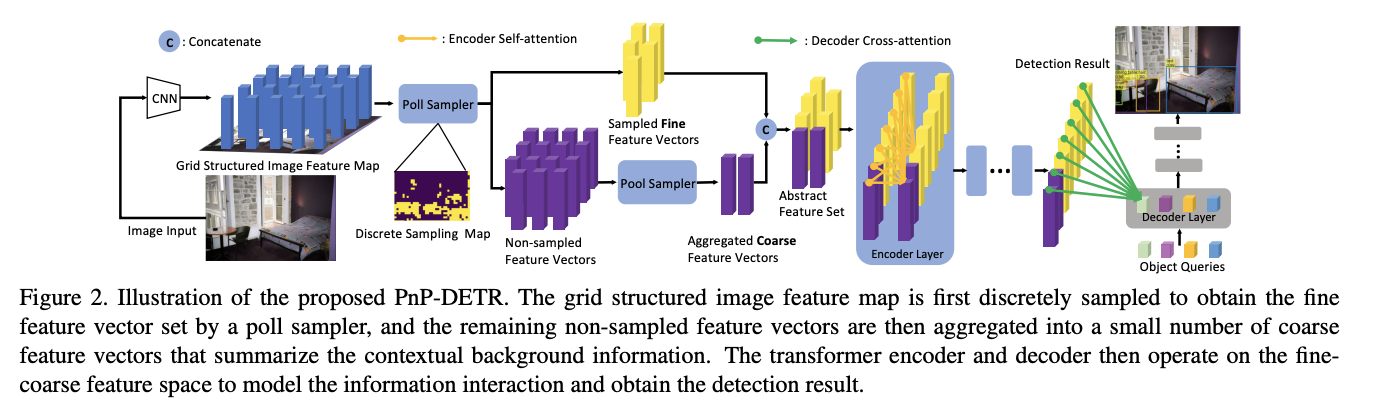
十二、PnP
PnP(或 Poll 和 Pool)是 DETR 类型架构的采样模块扩展,可自适应地分配其计算空间以提高效率。 具体来说,PnP模块将图像特征图抽象为精细的前景对象特征向量和少量的粗略背景上下文特征向量。 转换器对细-粗特征空间内的信息交互进行建模,并将特征转换为检测结果。
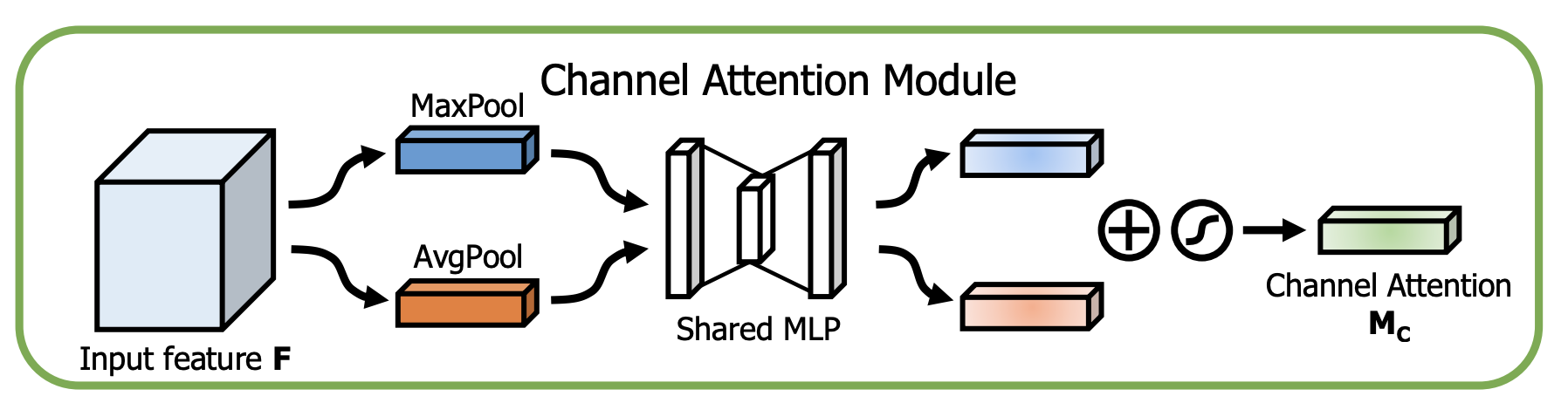
十三、Channel Attention Module
通道注意力模块是卷积神经网络中基于通道的注意力的模块。 我们通过利用特征的通道间关系来生成通道注意力图。 由于特征图的每个通道都被视为特征检测器,因此通道注意力集中在给定输入图像的情况下“什么”是有意义的。 为了有效地计算通道注意力,我们压缩输入特征图的空间维度。

请注意,仅具有平均池化的通道注意模块与挤压和激励模块相同。
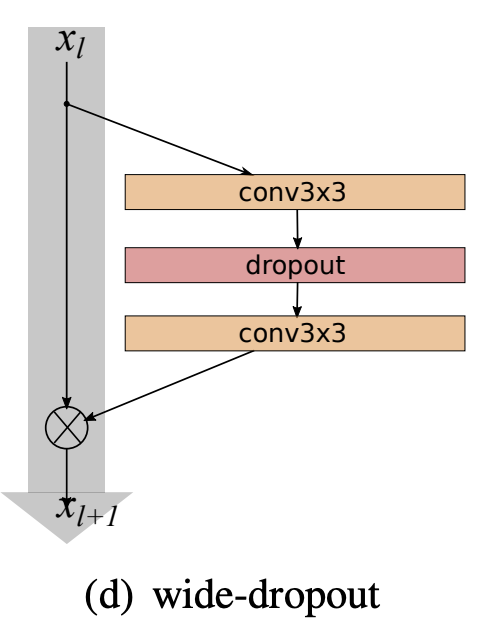
十四、Wide Residual Block
宽残差块是一种残差块,它利用两个 3x3 卷积层(带有 dropout)。 这比残差块的其他变体(例如瓶颈残差块)更宽。 它被提议作为 WideResNet CNN 架构的一部分。
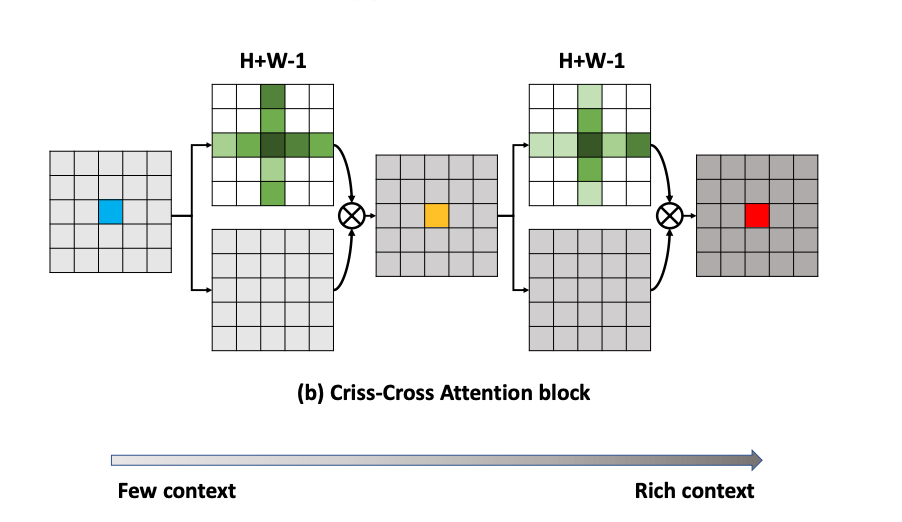
十五、Axial Attention
轴向注意力是自注意力的简单概括,它在编码和解码设置中自然地与张量的多个维度对齐。 它首先在 CCNet [1] 中提出,称为十字注意力,它收集其十字路径上所有像素的上下文信息。 通过进一步的循环操作,每个像素最终可以捕获全图像的依赖关系。 Ho等人[2]扩展了CCNet来处理多维数据。 所提出的层结构允许在解码期间并行计算绝大多数上下文,而无需引入任何独立性假设。 它是为高维数据张量(例如 Axial Transformers)开发基于自注意力的自回归模型的基本构建块。 它已在 AlphaFold [3] 中应用于解释蛋白质序列。
[1] 黄子龙,王兴刚,黄立超,黄昌,魏云超,刘文宇。 CCNet:语义分割的十字交叉注意力。 国际商业CV协会,2019。
[2] 乔纳森·何 (Jonathan Ho)、纳尔·卡尔奇布伦纳 (Nal Kalchbrenner)、德克·韦森博恩 (Dirk Weissenborn)、蒂姆·萨利曼 (Tim Salimans)。 arXiv:1912.12180
[3] Jumper J、Evans R、Pritzel A、Green T、Figurnov M、Ronneberger O、Tunyasuvunakool K、Bates R、Žídek A、Potapenko A、Bridgland A。使用 AlphaFold 进行高精度蛋白质结构预测。 自然。 2021 年 7 月 15:1-1。