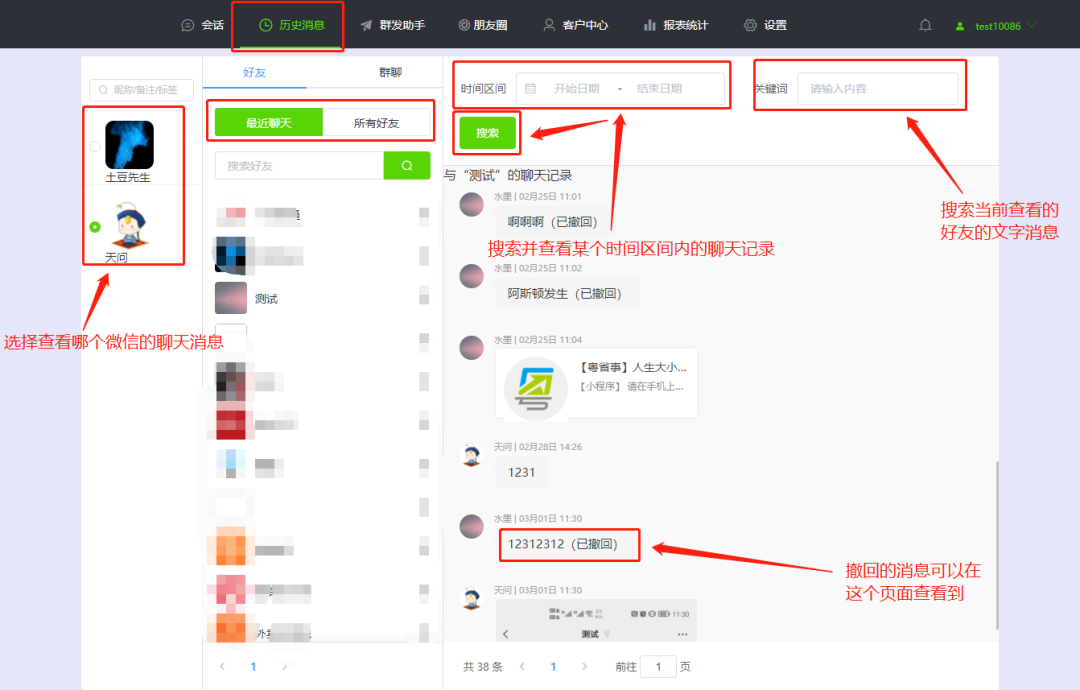
目录
1.事件相互独立
2.链式法则
3.示例
4.语言模型中的链式法则
1.事件相互独立
事件相互独立就是:一个事件的发生与否,不会影响另外一个事件的发生。
当a和b两个事件互相独立时,有:
P(a | b) = P(a)
推广到3个事件就有下面这个公式:
P(a | b, c) = P(a | c)
其中:P(a | b, c)表示在b和c事件都发生的情况下,a事件发生的概率
既然a与b相互独立,那b就不是a是否发生的条件,a就只与c有关
2.链式法则
2个事件同时发生的概率:
P(a, b) = P(a | b) * P(b)
其中:P(a, b)表示 a和b事件同时发生的概率, P(a | b)是一个条件概率,表示在b事件发生的条件下,a发生的概率
3个事件的概率链式法则:
P(a, b, c) = P(a | b, c) * P(b, c) = P(a | b, c) * P(b | c) * P(c)
N个事件的概率链式法则:
P(X1, X2, ... Xn) = P(X1 | X2, X3 ... Xn) * P(X2 | X3, X4 ... Xn) ... P(Xn-1 | Xn) * P(Xn)
3.示例
假设有事件ABCDE,它们之间的关系如下,求ABCDE同时发生的概率 P(A, B, C, D, E) 是多少?

所有的事件,只与它们的父节点有依赖关系,其中,E只和B有关,B只和AC有关,D只与C有关,A和C不依赖其他任何事件
P(A, B, C, D, E) = P(E | B, D, C, A) * P(B, D, C, A)
= P(E | B, D, C, A) * P(B | D, C, A) * P(D, C, A)
= P(E | B, D, C, A) * P(B | D, C, A) * P(D | C, A) * P(C, A)
= P(E | B, D, C, A) * P(B | D, C, A) * P(D | C, A) * P(C | A) * P(A)
我们根据前面说的相互独立的事件关系,来分析下最后那个长长的式子:
E只与B有关,则 P(E | B, D, C, A) = P(E | B)
B只和AC有关,则 P(B | D, C, A) = P(B | C, A)
D只与C有关, 则 P(D | C, A) = P(D | C)
C与A无关,则 P(C | A) = P(C)
所以最后的式子简化成了这样:
P(A, B, C, D, E) = P(E | B) * P(B | C, A) * P(D | C) * P(C) * P(A)
4.语言模型中的链式法则
用概率论来描述语言模型就是,为长度为的字符确定其概率分布,其中各x依次表示文本中的各个词语,一般采用链式法则计算其概率值:
![]()
当序列长度增加时,计算和存储多个词共同出现的概率的复杂度会呈指数级增加。n元语法通过马尔可夫假设(虽然并不一定成立)简化了语言模型的计算。n元模型是在估算条件概率时,忽略距离大于等于n的上文词的影响,因此得以简化。这里的马尔可夫假设是指一个词的出现只与前面n个词相关,即n阶马尔可夫链(Markov chain of order nn)。当n分别等于1,2,3时,分别将其称作一元语法(unigram),二元语法(bigram)和三元语法(trigram)。
通过实例来解释这几种语法,
一元模型意味着各个词之间相互独立,这无疑损失了句中词序信息。
![]()
二元语法
![]()
三元文法
![]()
当n大于等于2时,该模型可以保留一定的词语信息,而且n越大,信息越丰富,但计算成本也呈指数增长。